HyPOLE: Hyperproperty-Guided Multi-Agent Reinforcement Learning under Partial Observation
Pith reviewed 2026-07-01 01:19 UTC · model grok-4.3
The pith
HyPOLE uses hyperproperties in HyperLTL to guide policy learning in multi-agent reinforcement learning with only partial observations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
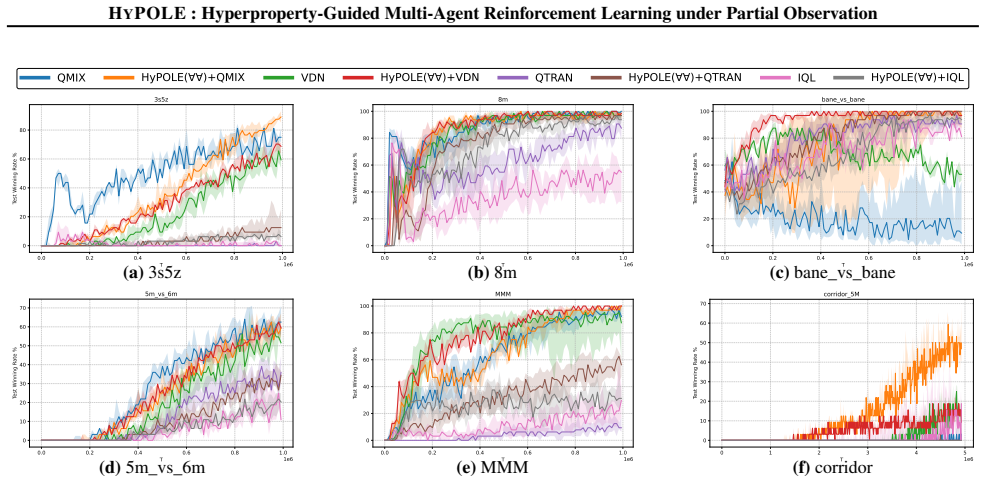
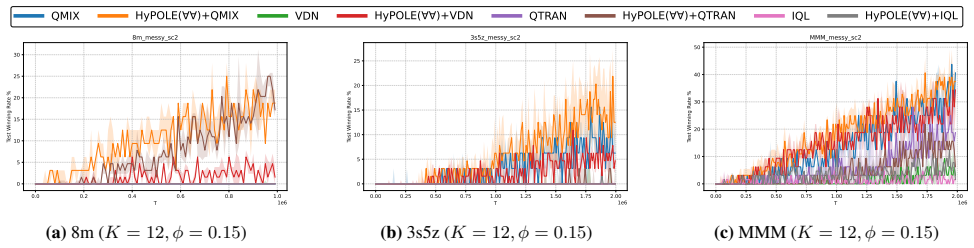
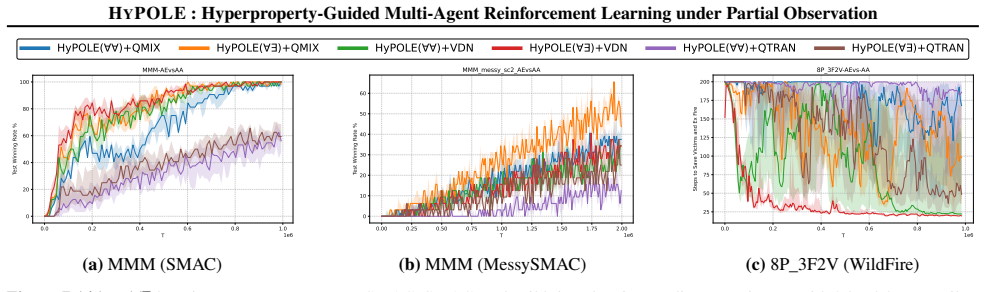
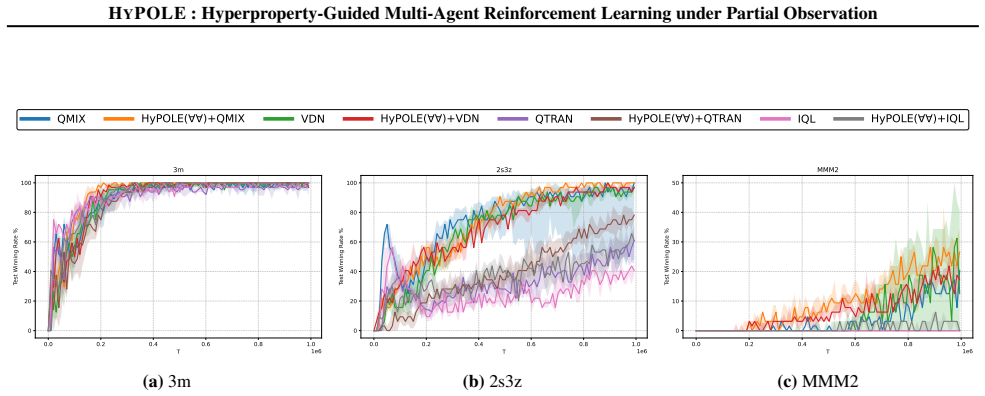
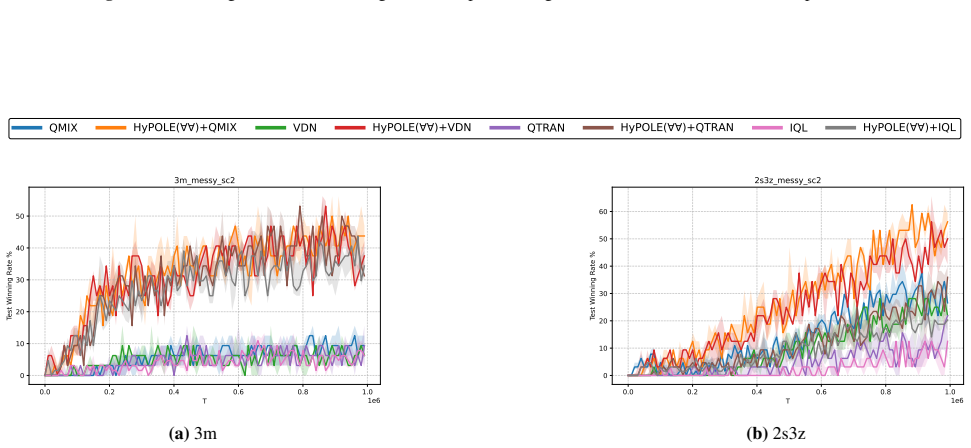
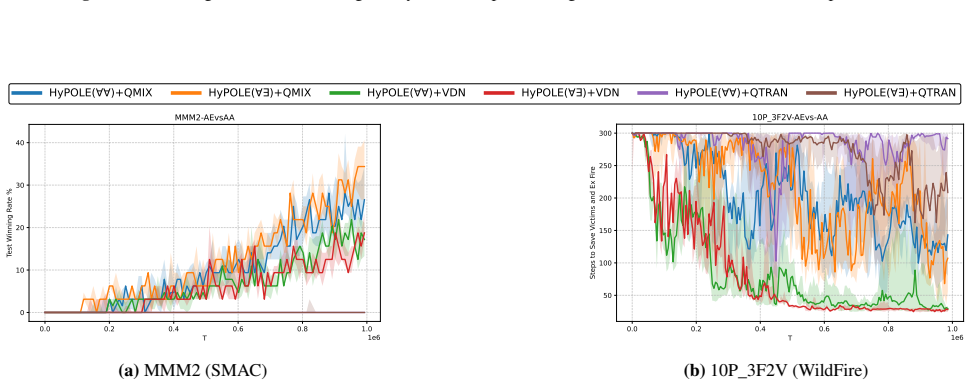
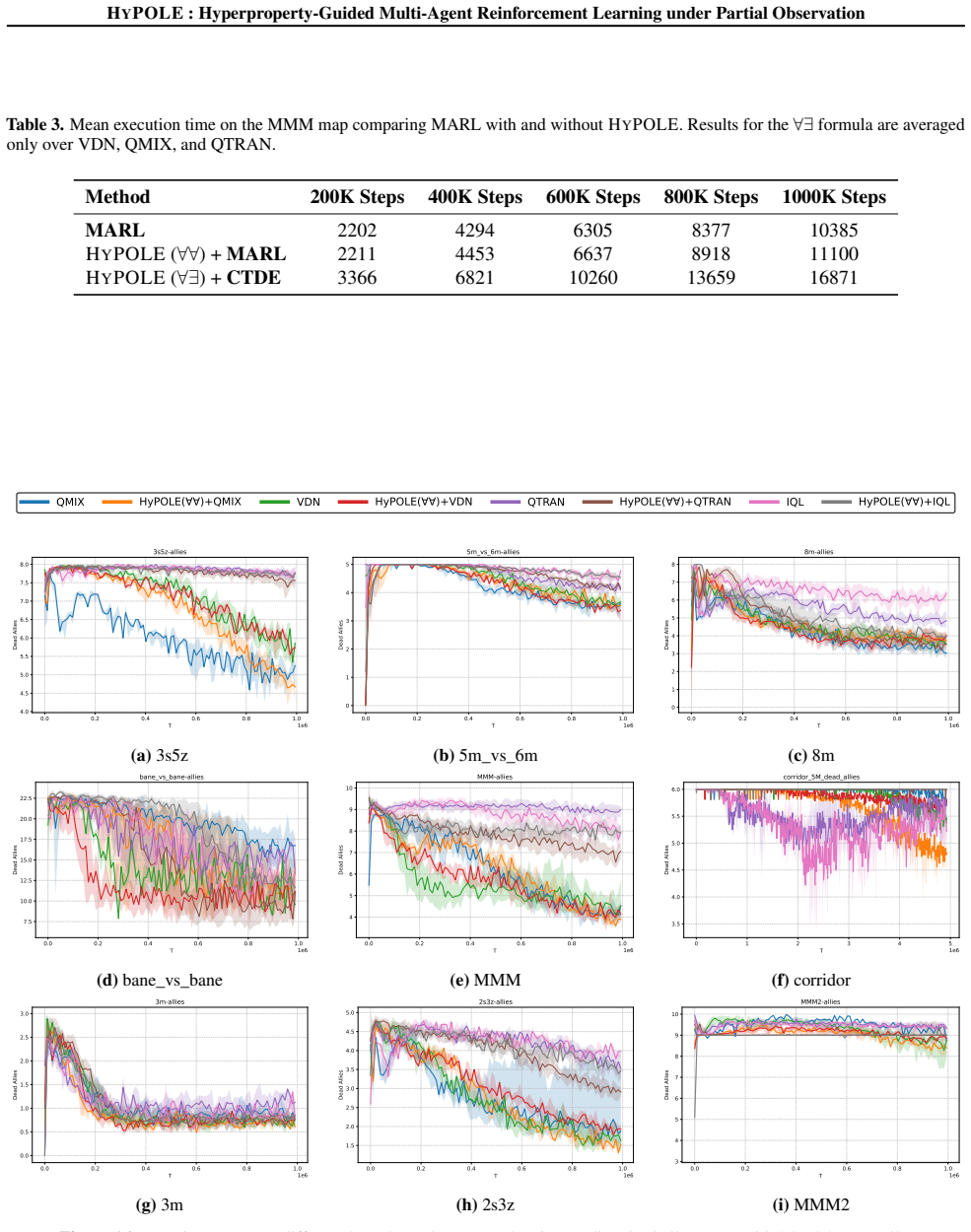
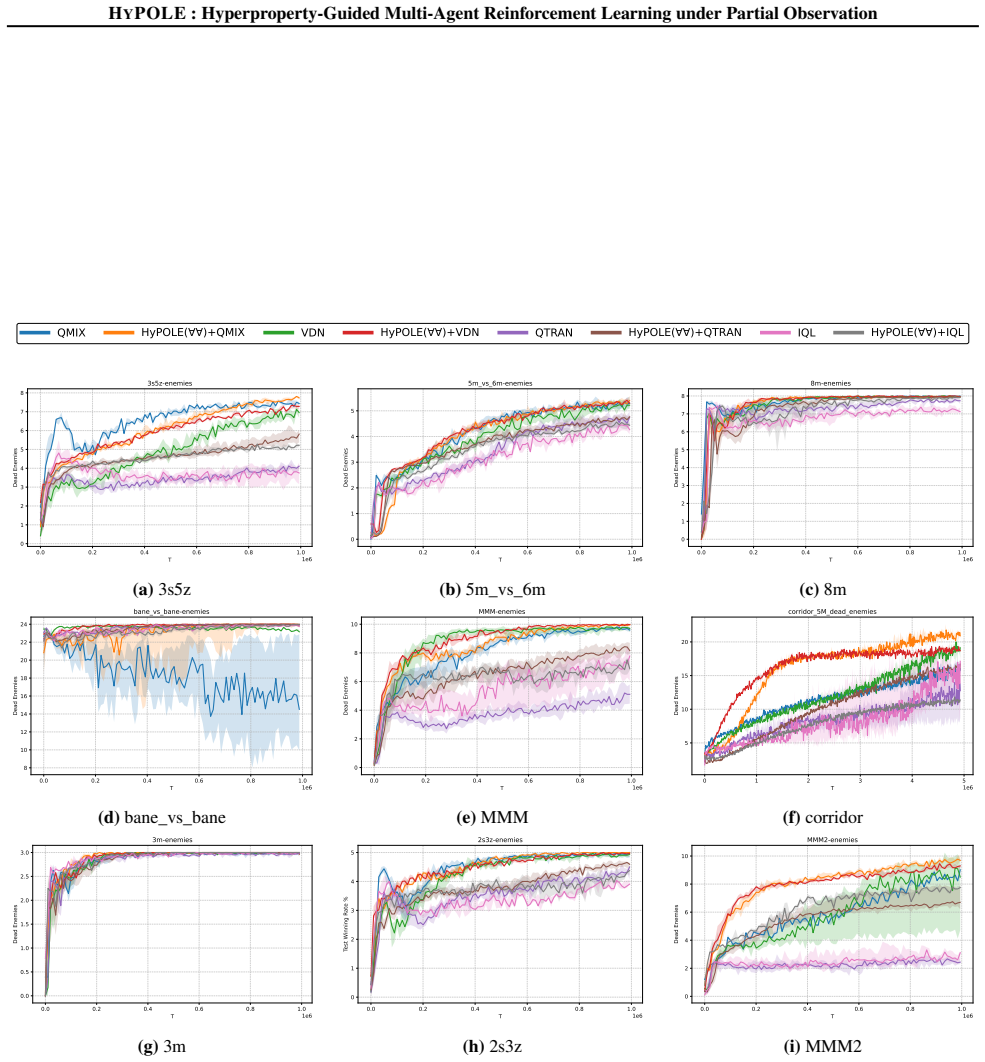
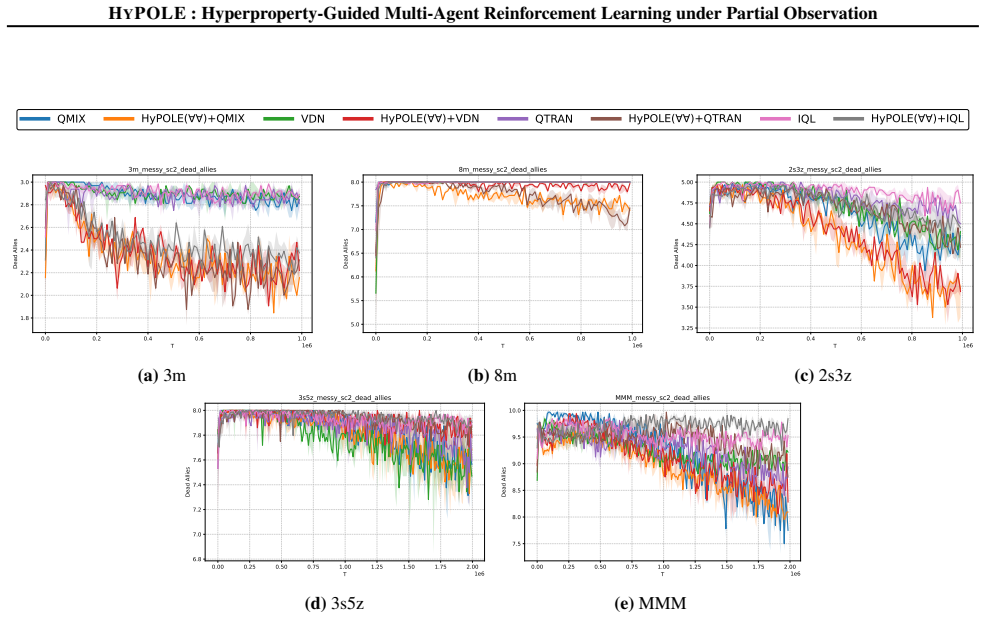
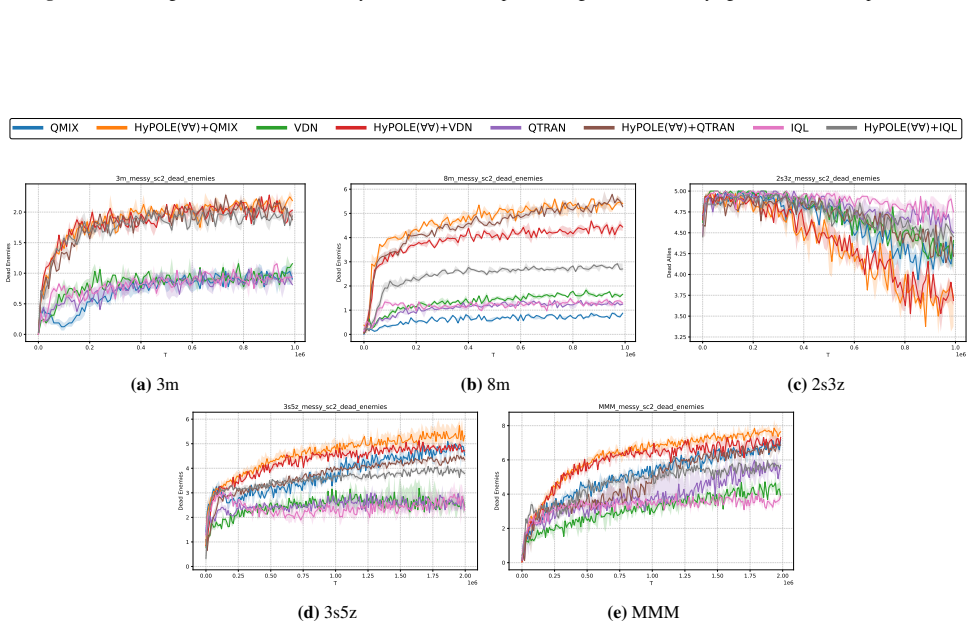
HyPOLE integrates hyperproperties and HyperLTL with CTDE techniques to synthesize decentralized policies for MARL under partial observability and demonstrates clear advantages over baselines on SMAC, MessySMAC, and WildFire.
What carries the argument
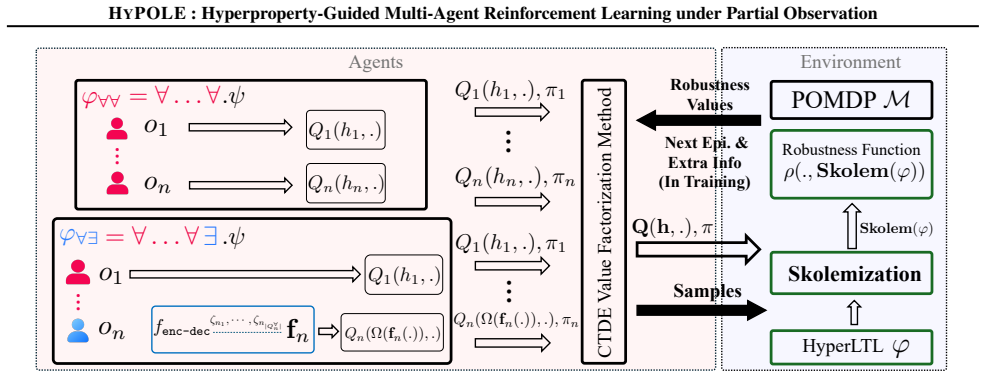
The HyPOLE framework, which translates hyperproperties written in HyperLTL into learning signals that steer centralized training of decentralized execution policies.
If this is right
- Decentralized policies can be trained to satisfy joint temporal objectives even when each agent receives only local observations.
- HyperLTL specifications replace reward engineering for stating coordination goals and safety constraints in multi-agent tasks.
- The same CTDE architecture now supports richer formal objectives without changing the decentralized execution phase.
- Performance gains appear across both grid-based combat and wildfire control benchmarks when hyperproperties are used.
Where Pith is reading between the lines
- The same translation step from HyperLTL to learning signals could be applied to single-agent partially observable problems to reduce reward design effort.
- If the method scales, it opens a route to verified multi-agent policies by combining the learned policies with existing HyperLTL model checkers.
- Future work could test whether the approach remains effective when the HyperLTL formulas themselves must be inferred from demonstration data rather than written by hand.
Load-bearing premise
HyperLTL formulas can be turned into effective learning signals that improve policies under partial observability without extra assumptions about agent communication or environment structure.
What would settle it
Running the same SMAC and WildFire experiments with HyPOLE and finding no consistent improvement over plain CTDE baselines would show that the hyperproperty signals do not deliver the claimed benefit.
Figures



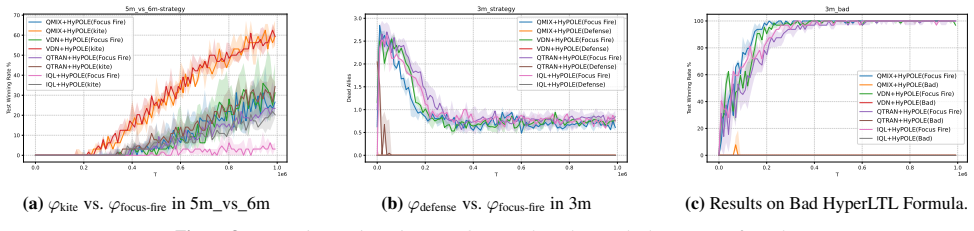

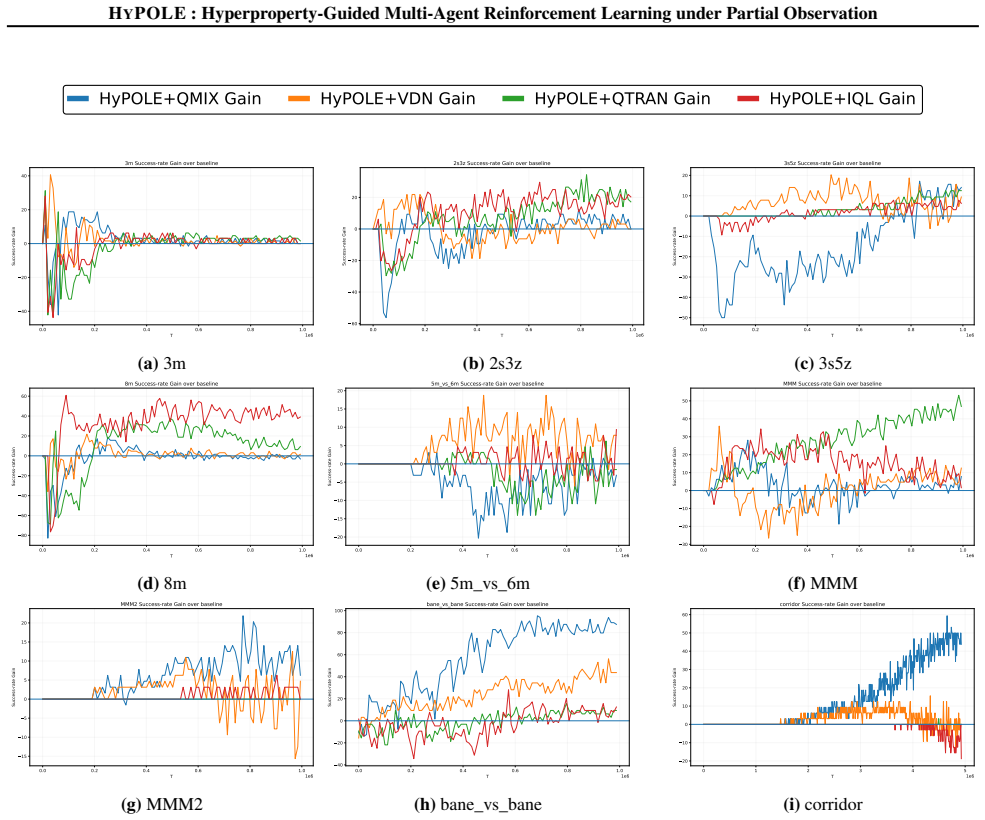
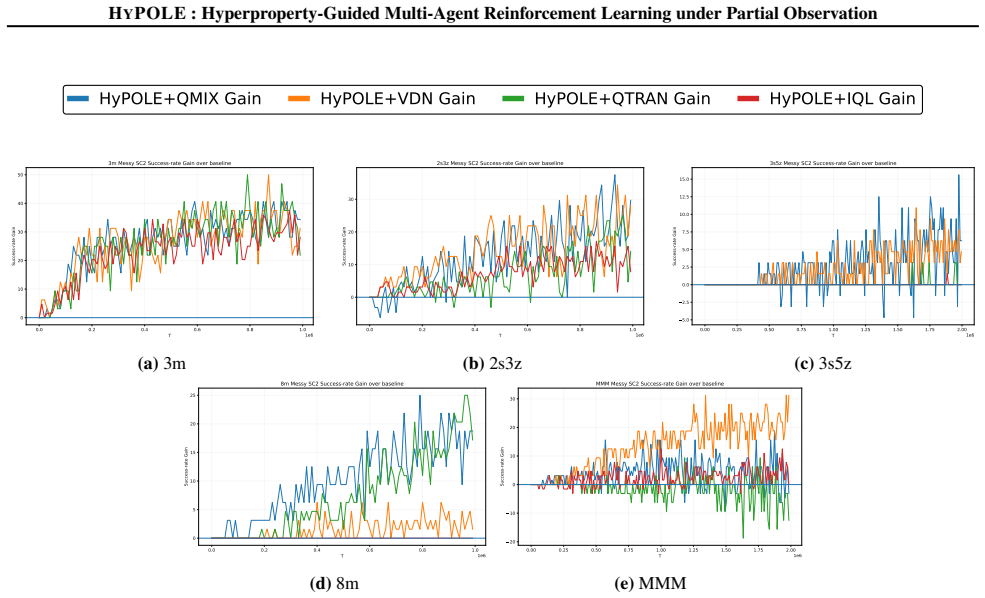
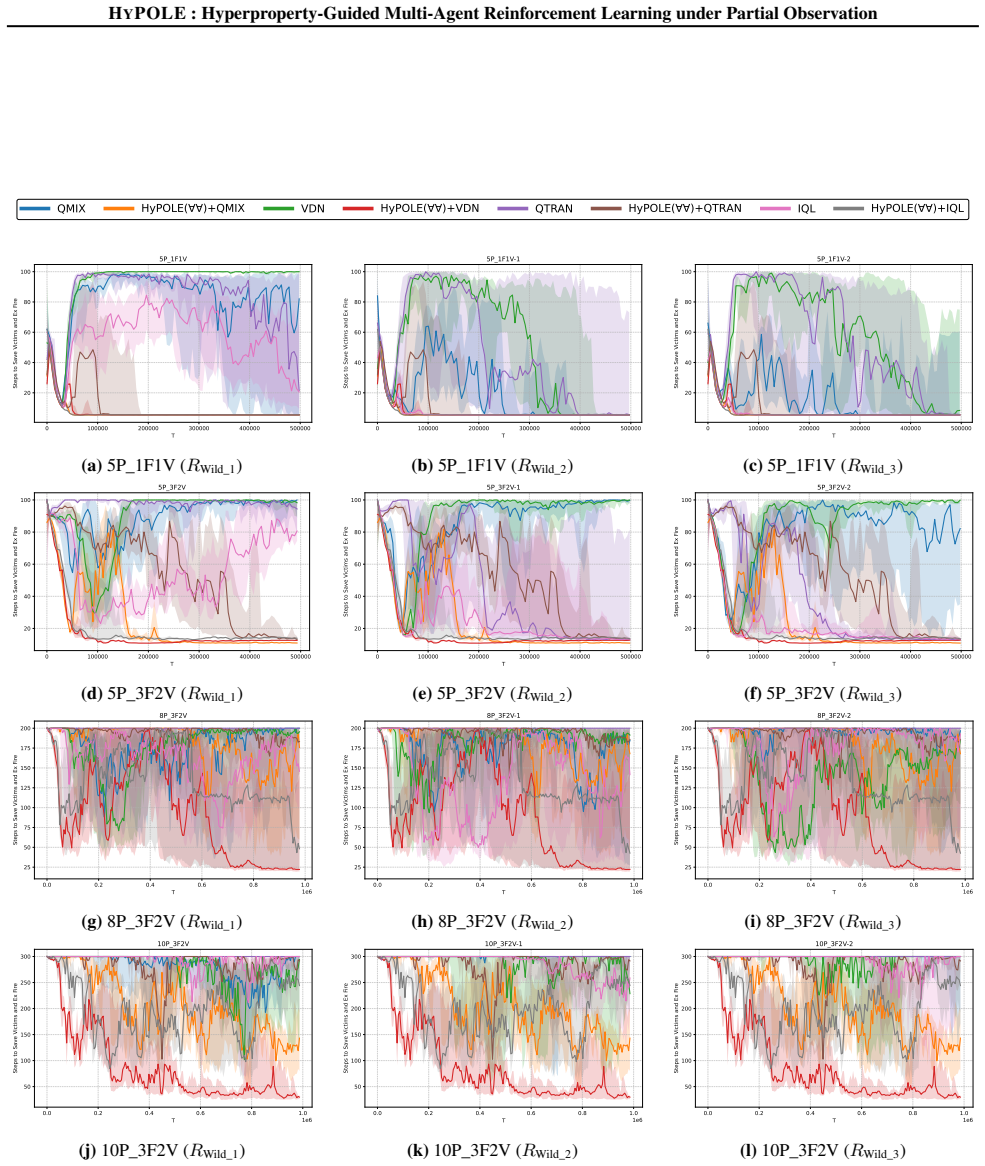

read the original abstract
Formal specification is a powerful tool to guide the learning process and provides significant advantages over reward shaping: (1) mathematical rigor; (2) expressiveness to specify objectives and constraints, and (3) the ability to define tactics to achieve objectives. However, these benefits remain largely unexplored in the context of Multi-Agent Reinforcement Learning (MARL). This paper introduces HyPOLE, a novel framework for MARL under partial observability, where learning is guided by the expressive power of the so-called hyperproperties and, in particular, the temporal logic HyperLTL. We integrate Centralized Training for Decentralized Execution (CTDE) techniques with HyPOLE to synthesize decentralized policies, and our evaluation on SMAC, MessySMAC, and WildFire benchmark demonstrates clear advantages over baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HyPOLE, a framework for multi-agent reinforcement learning under partial observability that guides learning via hyperproperties expressed in HyperLTL. It combines this approach with Centralized Training for Decentralized Execution (CTDE) to produce decentralized policies and reports clear advantages over baselines on the SMAC, MessySMAC, and WildFire benchmarks.
Significance. If the technical claims are substantiated, the work would offer a route to incorporate expressive formal specifications into MARL, moving beyond reward shaping with mathematical rigor and the ability to encode multi-agent objectives and constraints. The combination of HyperLTL hyperproperties with CTDE under partial observability could address a recognized gap, but the manuscript supplies neither the required translation mechanism nor any quantitative evidence, so significance cannot be assessed.
major comments (1)
- Abstract: the central claim requires that HyperLTL hyperproperties can be compiled into effective per-agent learning signals that respect the partial-observability constraint during both training and execution. No mechanism is described for monitoring HyperLTL satisfaction from local histories, shaping rewards or critics, or avoiding implicit centralized access. Without this step the reported gains on SMAC/MessySMAC/WildFire are incomparable to the baselines and the partial-observability guarantee is unverified.
Simulated Author's Rebuttal
We thank the referee for the review and the identification of this important point regarding the central technical claim. We address the major comment below.
read point-by-point responses
-
Referee: [—] Abstract: the central claim requires that HyperLTL hyperproperties can be compiled into effective per-agent learning signals that respect the partial-observability constraint during both training and execution. No mechanism is described for monitoring HyperLTL satisfaction from local histories, shaping rewards or critics, or avoiding implicit centralized access. Without this step the reported gains on SMAC/MessySMAC/WildFire are incomparable to the baselines and the partial-observability guarantee is unverified.
Authors: We agree that the manuscript requires a clearer, explicit description of the compilation mechanism to substantiate the central claim. The integration with CTDE is intended to allow centralized evaluation of HyperLTL formulas during training (using joint information) while restricting execution to local histories, but this is not stated with sufficient precision in the current text. In the revised version we will add a dedicated subsection detailing (i) how HyperLTL satisfaction is monitored and used to shape critics/rewards from the available information at training time, (ii) the restriction to local histories at execution time, and (iii) verification that no implicit centralized access occurs during decentralized execution. This revision will also strengthen the discussion of the partial-observability guarantee and enable direct comparison with the baselines. revision: yes
Circularity Check
No circularity in framework presentation or claims
full rationale
The paper introduces HyPOLE as an integration of HyperLTL hyperproperties with CTDE techniques for decentralized policy synthesis in partially observable MARL, with empirical evaluation on SMAC, MessySMAC, and WildFire. The provided abstract and description contain no equations, parameter-fitting steps, self-referential definitions, or load-bearing self-citations that reduce any prediction or result to its own inputs by construction. Claims rest on the stated advantages of formal specifications and benchmark results rather than any derivational loop. This is a standard framework paper whose central contribution is the proposed integration and evaluation, with no detectable circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the AAAI conference on artificial intelligence , volume=
Safe reinforcement learning via shielding , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[2]
Shield synthesis for reinforcement learning , author=. Leveraging Applications of Formal Methods, Verification and Validation: Verification Principles: 9th International Symposium on Leveraging Applications of Formal Methods, ISoLA 2020, Rhodes, Greece, October 20--30, 2020, Proceedings, Part I 9 , pages=. 2020 , organization=
2020
-
[3]
Innovations in Systems and Software Engineering , volume=
Online shielding for reinforcement learning , author=. Innovations in Systems and Software Engineering , volume=. 2023 , publisher=
2023
-
[4]
Proceedings of the National Academy of Sciences , volume=
Minimax theorems , author=. Proceedings of the National Academy of Sciences , volume=. 1953 , publisher=
1953
-
[5]
science , volume=
Dynamic programming , author=. science , volume=. 1966 , publisher=
1966
-
[6]
Proceedings of the national Academy of Sciences , volume=
On the theory of dynamic programming , author=. Proceedings of the national Academy of Sciences , volume=. 1952 , publisher=
1952
-
[7]
CS Dept., UW Seattle, Seattle, WA, USA, Tech
Reinforcement learning: Theory and algorithms , author=. CS Dept., UW Seattle, Seattle, WA, USA, Tech. Rep , volume=
-
[8]
2019 , eprint=
Modular Deep Reinforcement Learning with Temporal Logic Specifications , author=. 2019 , eprint=
2019
-
[9]
IJCAI: proceedings of the conference , volume=
Transfer of temporal logic formulas in reinforcement learning , author=. IJCAI: proceedings of the conference , volume=. 2019 , url =
2019
-
[10]
2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=
Encoding formulas as deep networks: Reinforcement learning for zero-shot execution of LTL formulas , author=. 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=. 2020 , url =
2020
-
[11]
2019 IEEE 58th conference on decision and control (CDC) , pages=
Reinforcement learning for temporal logic control synthesis with probabilistic satisfaction guarantees , author=. 2019 IEEE 58th conference on decision and control (CDC) , pages=. 2019 , organization=
2019
-
[12]
2019 , eprint=
Logically-Constrained Reinforcement Learning , author=. 2019 , eprint=
2019
-
[13]
Proceedings of the International Conference on Automated Planning and Scheduling , author=
Foundations for Restraining Bolts: Reinforcement Learning with LTLf/LDLf Restraining Specifications , volume=. Proceedings of the International Conference on Automated Planning and Scheduling , author=. 2019 , month=. doi:10.1609/icaps.v29i1.3549 , number=
-
[14]
Proceedings of the AAAI conference on artificial intelligence , volume=
LTLf/LDLf non-markovian rewards , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[15]
Artificial Intelligence , volume=
Certified reinforcement learning with logic guidance , author=. Artificial Intelligence , volume=. 2023 , publisher=
2023
-
[16]
Formal Modeling and Analysis of Timed Systems: 18th International Conference, FORMATS 2020, Vienna, Austria, September 1--3, 2020, Proceedings 18 , pages=
Deep reinforcement learning with temporal logics , author=. Formal Modeling and Analysis of Timed Systems: 18th International Conference, FORMATS 2020, Vienna, Austria, September 1--3, 2020, Proceedings 18 , pages=. 2020 , organization=
2020
-
[17]
16th IEEE Computer Security Foundations Workshop, 2003
Observational determinism for concurrent program security , author=. 16th IEEE Computer Security Foundations Workshop, 2003. Proceedings. , pages=. 2003 , organization=
2003
-
[18]
2016 IEEE 55th Conference on Decision and Control (CDC) , pages=
Q-learning for robust satisfaction of signal temporal logic specifications , author=. 2016 IEEE 55th Conference on Decision and Control (CDC) , pages=. 2016 , organization=
2016
-
[19]
Advances in Neural Information Processing Systems , volume=
A composable specification language for reinforcement learning tasks , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
International Conference on Computer Aided Verification , pages=
Specification-guided learning of nash equilibria with high social welfare , author=. International Conference on Computer Aided Verification , pages=. 2022 , url=
2022
-
[21]
, author=
The Bellman equation for minimizing the maximum cost. , author=. NONLINEAR ANAL. THEORY METHODS APPLIC. , volume=
-
[22]
Mathematical Structures in Computer Science , volume=
Secure information flow by self-composition , author=. Mathematical Structures in Computer Science , volume=. 2011 , publisher=
2011
-
[23]
International Symposium on Automated Technology for Verification and Analysis , pages=
Probabilistic hyperproperties of Markov decision processes , author=. International Symposium on Automated Technology for Verification and Analysis , pages=. 2020 , organization=
2020
-
[24]
International Symposium on Automated Technology for Verification and Analysis , pages=
Probabilistic hyperproperties with nondeterminism , author=. International Symposium on Automated Technology for Verification and Analysis , pages=. 2020 , organization=
2020
-
[25]
arXiv preprint arXiv:2107.02509 , year=
A temporal logic for strategic hyperproperties , author=. arXiv preprint arXiv:2107.02509 , year=
-
[26]
Programmable agents , author=. arXiv preprint arXiv:1706.06383 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Advances in neural information processing systems , volume=
Hierarchical reinforcement learning for zero-shot generalization with subtask dependencies , author=. Advances in neural information processing systems , volume=
-
[28]
International conference on machine learning , pages=
Modular multitask reinforcement learning with policy sketches , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[29]
Journal of Artificial Intelligence Research , volume=
Reward machines: Exploiting reward function structure in reinforcement learning , author=. Journal of Artificial Intelligence Research , volume=
-
[30]
Logico-combinatorial investigations in the satisfiability or provability of mathematical propositions: A simplified proof of a theorem by L
Skolem, Thoralf , journal=. Logico-combinatorial investigations in the satisfiability or provability of mathematical propositions: A simplified proof of a theorem by L. L
-
[31]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Simplifying complex observation models in continuous pomdp planning with probabilistic guarantees and practice , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[32]
Artificial intelligence , volume=
Planning and acting in partially observable stochastic domains , author=. Artificial intelligence , volume=. 1998 , publisher=
1998
-
[33]
2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=
Reinforcement learning with temporal logic rewards , author=. 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=. 2017 , url =
2017
-
[34]
Probably Approximately Correct MDP Learning and Control With Temporal Logic Constraints
Probably approximately correct MDP learning and control with temporal logic constraints , author=. arXiv preprint arXiv:1404.7073 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Mathematics of Operations Research , volume=
Average cost Markov decision processes with weakly continuous transition probabilities , author=. Mathematics of Operations Research , volume=. 2012 , publisher=
2012
-
[36]
Symposium on Principles of Programming Languages,
Minh Ngo and Fabio Massacci and Dimiter Milushev and Frank Piessens , title =. Symposium on Principles of Programming Languages,. 2015 , doi =
2015
-
[37]
International Conference on Software Engineering,
Hoang Duong Thien Nguyen and Dawei Qi and Abhik Roychoudhury and Satish Chandra , title =. International Conference on Software Engineering,. 2013 , doi =
2013
-
[38]
International Symposium on Automated Technology for Verification and Analysis,
Norine Coenen and Bernd Finkbeiner and Christopher Hahn and Jana Hofmann and Yannick Schillo , title =. International Symposium on Automated Technology for Verification and Analysis,. 2021 , doi =
2021
-
[39]
Computer Security Foundations Symposium,
Shreya Agrawal and Borzoo Bonakdarpour , title =. Computer Security Foundations Symposium,. 2016 , doi =
2016
-
[40]
Liquid information flow control , journal =
Nadia Polikarpova and Deian Stefan and Jean Yang and Shachar Itzhaky and Travis Hance and Armando Solar. Liquid information flow control , journal =. 2020 , doi =
2020
-
[41]
International Symposium on Automated Technology for Verification and Analysis,
Borzoo Bonakdarpour and Bernd Finkbeiner , title =. International Symposium on Automated Technology for Verification and Analysis,. 2019 , doi =
2019
-
[42]
Clarkson and Bernd Finkbeiner and Masoud Koleini and Kristopher K
Michael R. Clarkson and Bernd Finkbeiner and Masoud Koleini and Kristopher K. Micinski and Markus N. Rabe and C. Temporal Logics for Hyperproperties , booktitle =. 2014 , doi =
2014
-
[43]
International Conference on Computer Aided Verification,
Raven Beutner and Bernd Finkbeiner , title =. International Conference on Computer Aided Verification,. 2022 , doi =
2022
-
[44]
Cartesian hoare logic for verifying k-safety properties , booktitle =
Marcelo Sousa and Isil Dillig , editor =. Cartesian hoare logic for verifying k-safety properties , booktitle =. 2016 , url =. doi:10.1145/2908080.2908092 , timestamp =
-
[45]
Simple relational correctness proofs for static analyses and program transformations , booktitle =
Nick Benton , editor =. Simple relational correctness proofs for static analyses and program transformations , booktitle =. 2004 , url =. doi:10.1145/964001.964003 , timestamp =
-
[46]
Claire Le Goues and Michael Pradel and Abhik Roychoudhury , title =. Commun. 2019 , doi =
2019
-
[47]
Search-based program synthesis , journal =
Rajeev Alur and Rishabh Singh and Dana Fisman and Armando Solar. Search-based program synthesis , journal =. 2018 , doi =
2018
-
[48]
Combinatorial sketching for finite programs , booktitle =
Armando Solar. Combinatorial sketching for finite programs , booktitle =. 2006 , url =. doi:10.1145/1168857.1168907 , timestamp =
-
[49]
Syntax-guided synthesis , booktitle =
Rajeev Alur and Rastislav Bod. Syntax-guided synthesis , booktitle =
-
[50]
King , title =
James C. King , title =. Commun. 1976 , doi =
1976
-
[51]
Modular and verified automatic program repair , booktitle =
Francesco Logozzo and Thomas Ball , editor =. Modular and verified automatic program repair , booktitle =. 2012 , url =. doi:10.1145/2384616.2384626 , timestamp =
-
[52]
Rinard , title =
Fan Long and Martin C. Rinard , title =. Symposium on Principles of Programming Languages,. 2016 , doi =
2016
-
[53]
SapFix: automated end-to-end repair at scale , booktitle =
Alexandru Marginean and Johannes Bader and Satish Chandra and Mark Harman and Yue Jia and Ke Mao and Alexander Mols and Andrew Scott , editor =. SapFix: automated end-to-end repair at scale , booktitle =. 2019 , url =. doi:10.1109/ICSE-SEIP.2019.00039 , timestamp =
-
[54]
International Conference on Software Engineering,
Sergey Mechtaev and Jooyong Yi and Abhik Roychoudhury , title =. International Conference on Software Engineering,. 2016 , doi =
2016
-
[55]
European Symposium on Programming Languages and Systems,
Shachar Itzhaky and Sharon Shoham and Yakir Vizel , title =. European Symposium on Programming Languages and Systems,. 2024 , doi =
2024
-
[56]
Adrian Nistor and Po. 37th. 2015 , url =. doi:10.1109/ICSE.2015.100 , timestamp =
-
[57]
International Conference on Software Engineering,
Yuhua Qi and Xiaoguang Mao and Yan Lei and Ziying Dai and Chengsong Wang , title =. International Conference on Software Engineering,. 2014 , doi =
2014
-
[58]
Hesam Samimi and Max Sch. Automated repair of. 34th International Conference on Software Engineering,. 2012 , url =. doi:10.1109/ICSE.2012.6227186 , timestamp =
-
[59]
David Shriver and Sebastian G. Elbaum and Kathryn T. Stolee , title =. 39th. 2017 , url =. doi:10.1109/ICSE-NIER.2017.7 , timestamp =
-
[60]
Smith and Earl T
Edward K. Smith and Earl T. Barr and Claire Le Goues and Yuriy Brun , title =. Joint Meeting on Foundations of Software Engineering,. 2015 , doi =
2015
-
[61]
31st International Conference on Software Engineering,
Westley Weimer and ThanhVu Nguyen and Claire Le Goues and Stephanie Forrest , title =. 31st International Conference on Software Engineering,. 2009 , url =. doi:10.1109/ICSE.2009.5070536 , timestamp =
-
[62]
Identifying patch correctness in test-based program repair , booktitle =
Yingfei Xiong and Xinyuan Liu and Muhan Zeng and Lu Zhang and Gang Huang , editor =. Identifying patch correctness in test-based program repair , booktitle =. 2018 , url =. doi:10.1145/3180155.3180182 , timestamp =
-
[63]
A syntax-guided edit decoder for neural program repair , booktitle =
Qihao Zhu and Zeyu Sun and Yuan. A syntax-guided edit decoder for neural program repair , booktitle =. 2021 , doi =
2021
-
[64]
Efficient Loop Conditions for Bounded Model Checking Hyperproperties , booktitle =
Tzu. Efficient Loop Conditions for Bounded Model Checking Hyperproperties , booktitle =. 2023 , doi =
2023
-
[65]
International Symposium on Software Testing and Analysis,
Kui Liu and Anil Koyuncu and Dongsun Kim and Tegawend. International Symposium on Software Testing and Analysis,. 2019 , doi =
2019
-
[66]
Computer Security Foundations Symposium,
Raven Beutner and Bernd Finkbeiner , title =. Computer Security Foundations Symposium,. 2022 , doi =
2022
-
[67]
From Spot 2.0 to Spot 2.10: What's New? , booktitle =
Alexandre Duret. From Spot 2.0 to Spot 2.10: What's New? , booktitle =. 2022 , doi =
2022
-
[68]
Barrett and Martin Brain and Gereon Kremer and Hanna Lachnitt and Makai Mann and Abdalrhman Mohamed and Mudathir Mohamed and Aina Niemetz and Andres N
Haniel Barbosa and Clark W. Barrett and Martin Brain and Gereon Kremer and Hanna Lachnitt and Makai Mann and Abdalrhman Mohamed and Mudathir Mohamed and Aina Niemetz and Andres N. cvc5:. International Conference on Tools and Algorithms for the Construction and Analysis of Systems,. 2022 , doi =
2022
-
[69]
cvc4sy: Smart and Fast Term Enumeration for Syntax-Guided Synthesis , booktitle =
Andrew Reynolds and Haniel Barbosa and Andres N. cvc4sy: Smart and Fast Term Enumeration for Syntax-Guided Synthesis , booktitle =. 2019 , doi =
2019
-
[70]
International Conference on Information Systems Security,
Wilayat Khan and Stefano Calzavara and Michele Bugliesi and Willem De Groef and Frank Piessens , title =. International Conference on Information Systems Security,. 2014 , doi =
2014
-
[71]
2022 IEEE Symposium on Security and Privacy (SP) , pages=
FSAFlow: Lightweight and fast dynamic path tracking and control for privacy protection on Android using hybrid analysis with state-reduction strategy , author=. 2022 IEEE Symposium on Security and Privacy (SP) , pages=. 2022 , organization=
2022
-
[72]
Proceedings of the 25th ACM SIGPLAN-SIGACT symposium on Principles of programming languages , pages=
Secure information flow in a multi-threaded imperative language , author=. Proceedings of the 25th ACM SIGPLAN-SIGACT symposium on Principles of programming languages , pages=
-
[73]
International Conference on Programming Language Design and Implementation,
Kangjing Huang and Xiaokang Qiu and Peiyuan Shen and Yanjun Wang , title =. International Conference on Programming Language Design and Implementation,. 2020 , doi =
2020
-
[74]
International Conference on Tools and Algorithms for the Construction and Analysis of Systems,
Rajeev Alur and Arjun Radhakrishna and Abhishek Udupa , title =. International Conference on Tools and Algorithms for the Construction and Analysis of Systems,. 2017 , doi =
2017
-
[75]
Priyanka Golia and Subhajit Roy and Kuldeep S. Meel , editor =. Program Synthesis as Dependency Quantified Formula Modulo Theory , booktitle =. 2021 , url =. doi:10.24963/IJCAI.2021/261 , timestamp =
-
[76]
Yuantian Ding and Xiaokang Qiu , title =. Proc. 2024 , doi =
2024
-
[77]
Foster and David Van Horn , title =
Sankha Narayan Guria and Jeffrey S. Foster and David Van Horn , title =. Proc. 2023 , url =. doi:10.1145/3591285 , timestamp =
-
[78]
Joint Meeting on Foundations of Software Engineering,
Xuan. Joint Meeting on Foundations of Software Engineering,. 2017 , doi =
2017
-
[79]
Syntax-guided synthesis , booktitle =
Rajeev Alur and Rastislav Bod. Syntax-guided synthesis , booktitle =. 2013 , url =
2013
-
[80]
Vardi , title =
Orna Kupferman and Moshe Y. Vardi , title =. International Conference on Computer Aided Verification,. 1999 , doi =
1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.