Data-Adaptive Learning of Dynamical Systems by Matching Transfer Operators and Invariant Measures
Pith reviewed 2026-07-02 08:18 UTC · model grok-4.3
The pith
Matching transfer operators on data-adaptive meshes learns dynamical systems that preserve long-time statistics better than pointwise trajectory matching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
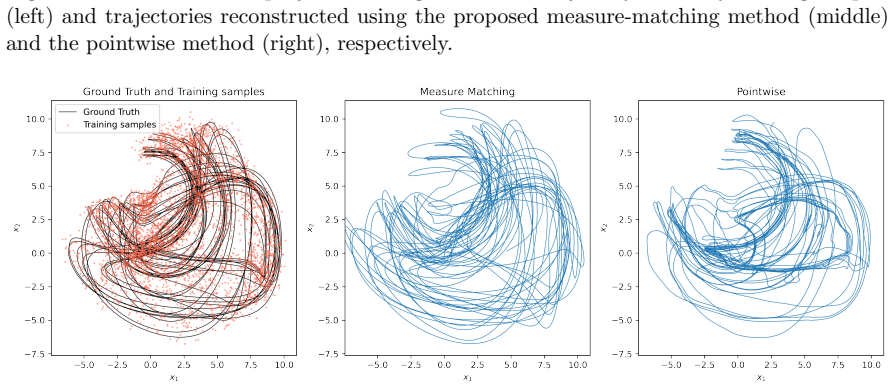
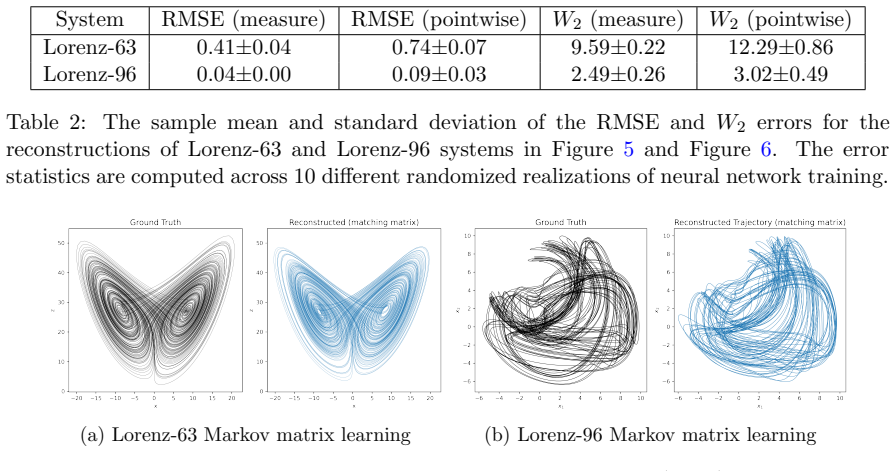
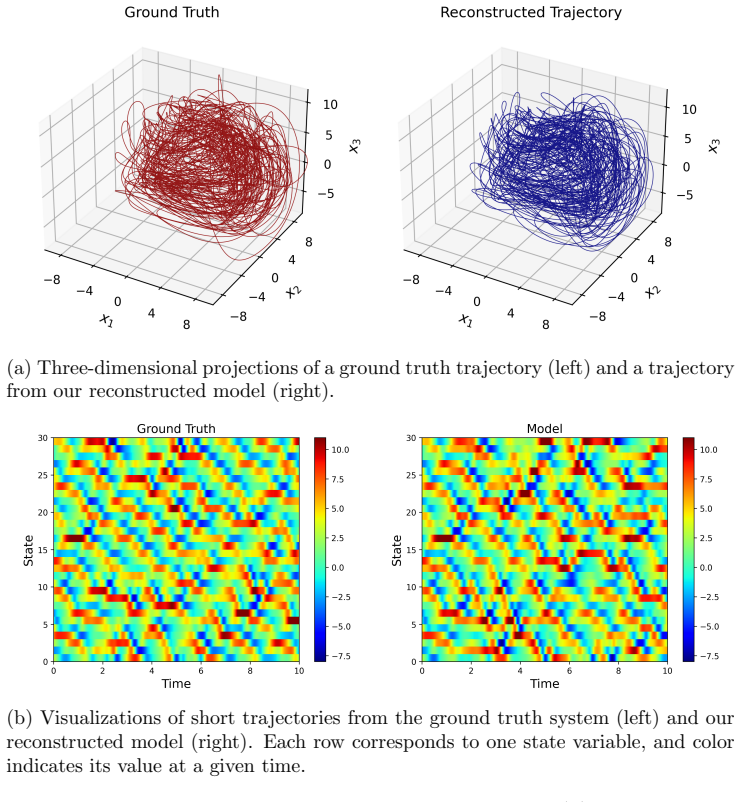
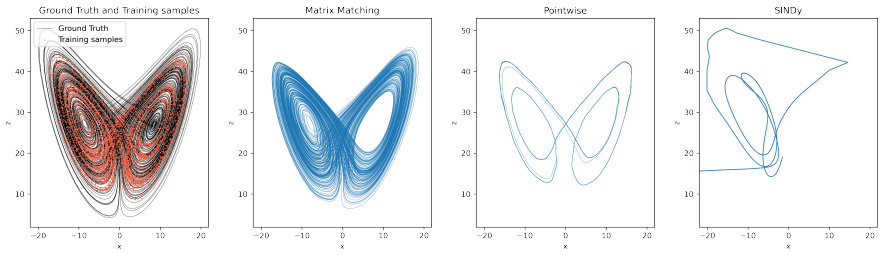
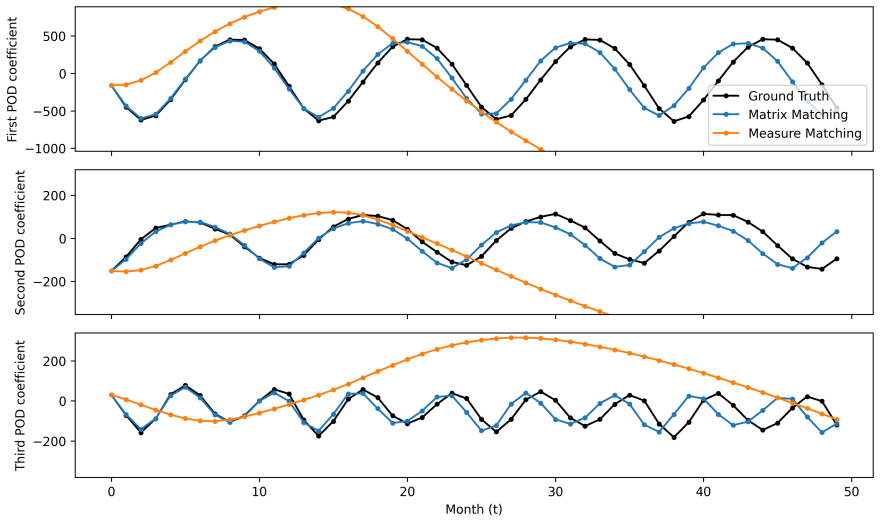
The authors establish that approximating the Perron-Frobenius operator via a regularized Ulam transition matrix built on a data-adaptive unstructured partition with continuous piecewise-smooth partition-of-unity weights enables optimization objectives that match either the full transition matrices or their stationary eigenvectors, yielding learned dynamics with superior long-time behavior compared to pointwise losses, as demonstrated on Lorenz-63, Lorenz-96, and NOAA sea surface temperature data.
What carries the argument
The regularized Ulam transition matrix with continuous piecewise-smooth partition-of-unity weights on a data-adaptive unstructured partition, which approximates the Perron-Frobenius operator to support gradient-based matching of transition statistics.
If this is right
- The learned vector field induces dynamics whose probability mass motion matches the data's transition statistics.
- Matching invariant measures ensures the model reproduces the correct long-term distribution.
- The method remains effective under measurement noise and sparse sampling where trajectory matching degrades.
- Gradient-based optimization is enabled by the differentiable Markov matrix approximation.
Where Pith is reading between the lines
- This approach may generalize to learning from partially observed or high-dimensional data by focusing on coarse-grained statistics.
- Combining operator matching with other regularization could further stabilize learning in very chaotic regimes.
- Testing on systems with known bifurcations could reveal if the method captures parameter-dependent transitions accurately.
Load-bearing premise
The regularized Ulam transition matrix with continuous piecewise-smooth partition-of-unity weights provides a sufficiently accurate and differentiable approximation to the true Perron-Frobenius operator of the learned vector field.
What would settle it
Observing that a model trained to match transition matrices produces trajectories whose empirical invariant measure deviates significantly from the data's on a test set of Lorenz-63 trajectories would falsify the reliability claim.
Figures

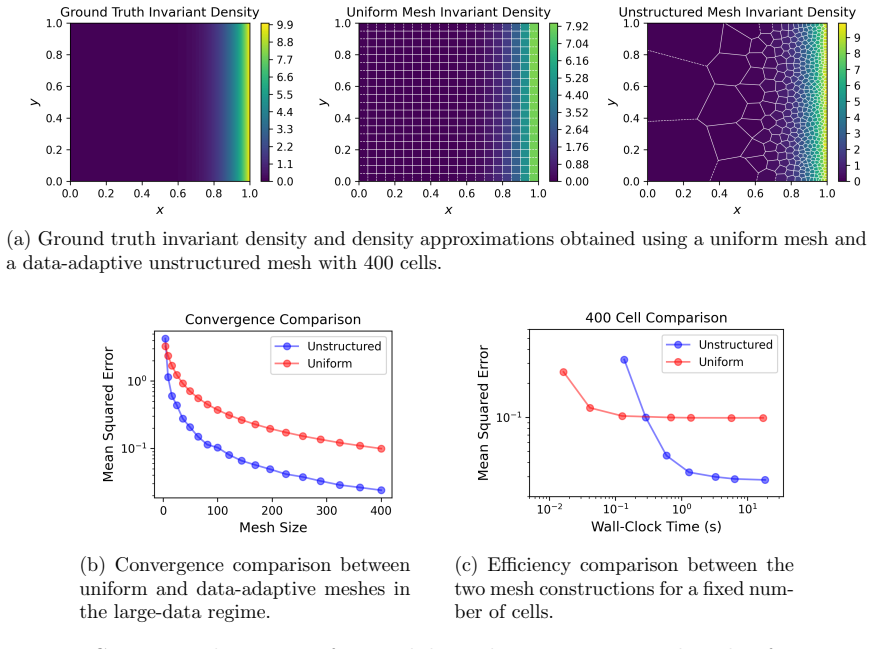
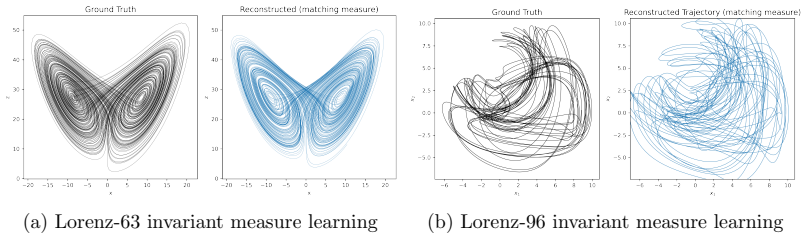
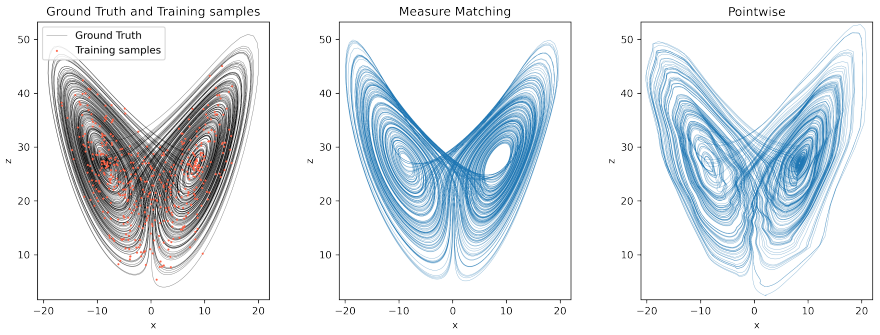
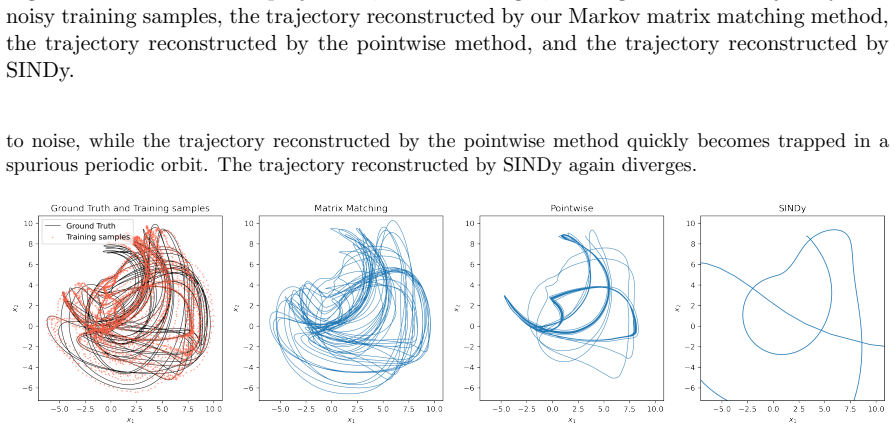
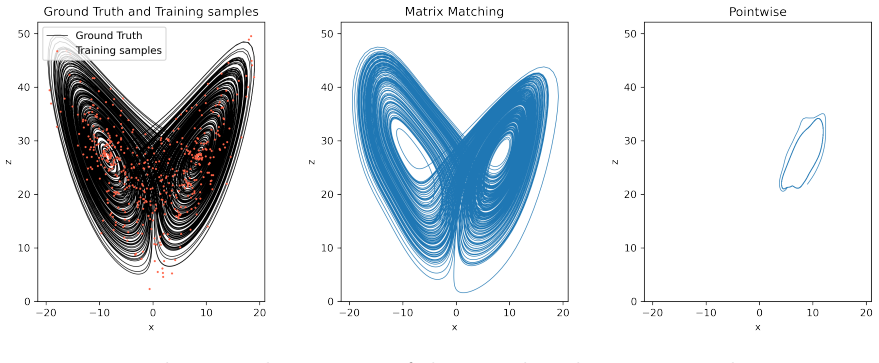
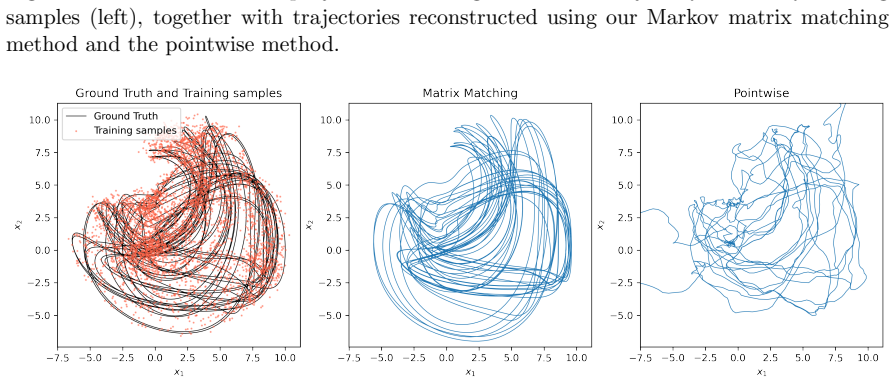
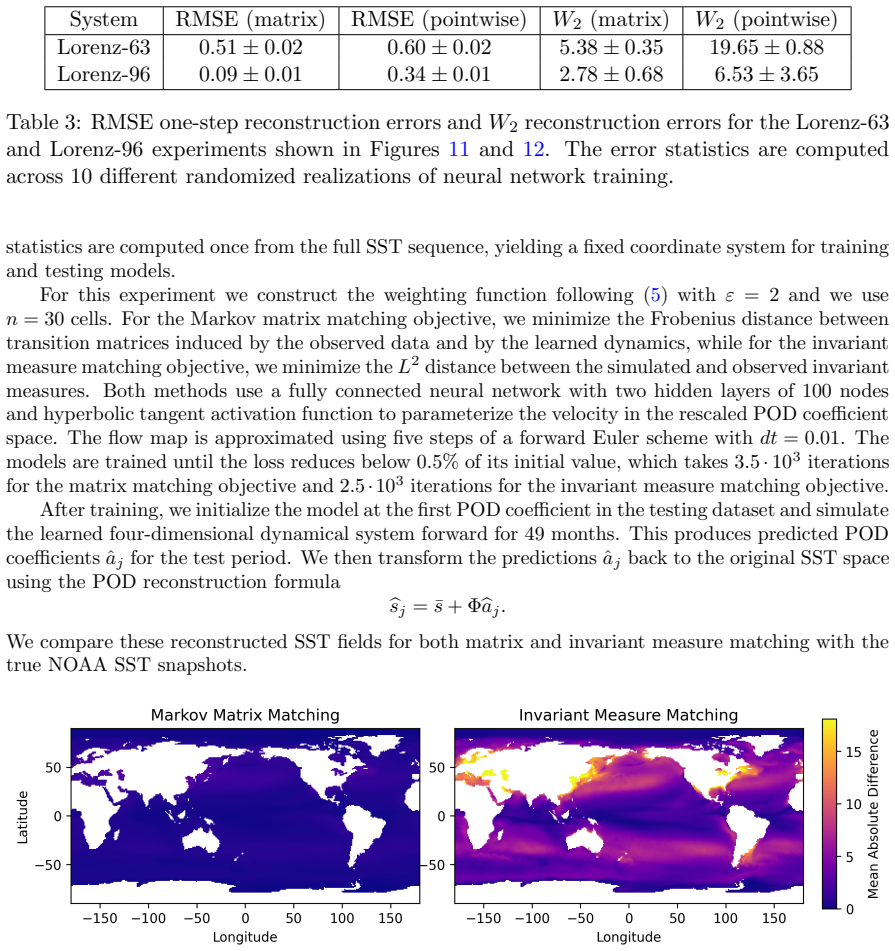
read the original abstract
Trajectory-based learning of dynamical systems is often fragile in the presence of noise, chaos, or sparse observations, as small pointwise errors can rapidly amplify. We introduce a transition-statistics approach to system identification that learns dynamics by matching the induced motion of probability mass across a data-adaptive mesh. Given trajectory data, we build an unstructured partition of state space and approximate the Perron--Frobenius operator with a regularized Ulam transition matrix. We replace hard cell indicators with continuous, piecewise-smooth partition-of-unity weights, yielding a Markov matrix supporting gradient-based optimization with respect to the parameters of a learned vector field. This enables two related training objectives: matching invariant measures through the stationary eigenvectors of the transition matrices, and matching the full transition matrices to capture transport between regions of state space. Numerical experiments on Lorenz-63, Lorenz-96, and a reduced-order NOAA sea surface temperature forecasting problem show that transition-statistics matching gives more reliable long-time dynamics than pointwise trajectory matching, particularly under measurement noise and sparse sampling. The approach provides a robust operator-theoretic alternative to trajectory-level losses for learning chaotic and partially observed dynamical systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes learning dynamical systems from trajectory data by constructing a data-adaptive unstructured partition, approximating the Perron-Frobenius operator via a regularized Ulam transition matrix that employs continuous piecewise-smooth partition-of-unity weights, and optimizing a learned vector field to match either the stationary eigenvectors (invariant measures) or the full transition matrices. Numerical experiments on Lorenz-63, Lorenz-96, and a reduced-order NOAA sea-surface-temperature problem are reported to show that this transition-statistics matching yields more reliable long-time dynamics than pointwise trajectory matching, especially under measurement noise and sparse sampling.
Significance. If the central claims hold, the work supplies a differentiable operator-theoretic alternative to trajectory losses that may improve robustness for chaotic and partially observed systems. The technical device of replacing hard indicators with continuous partition-of-unity weights to obtain a gradient-compatible Markov matrix is a concrete contribution that enables the proposed objectives.
major comments (2)
- [Abstract (and the numerical-experiments section)] The central claim that matching the approximate transition matrices produces a vector field whose true long-time statistics match the data rests on the regularized Ulam construction being a sufficiently faithful proxy for the true Perron-Frobenius operator. No a priori error bound, convergence rate, or stability analysis for the data-adaptive unstructured partition under noise or sparse sampling is supplied; this approximation quality is load-bearing for the superiority result.
- [Abstract] The abstract asserts superior long-time behavior on Lorenz-63, Lorenz-96, and the NOAA SST problem, yet supplies no quantitative metrics (e.g., integrated autocorrelation times, Wasserstein distances on invariant measures, or prediction horizons with error bars) or explicit baseline comparisons; without these, the experimental support for the operator-matching advantage cannot be assessed.
minor comments (1)
- Clarify the precise definition of the regularization parameter and the construction of the data-adaptive partition (including how cell boundaries are determined from noisy trajectories) so that the method can be reproduced.
Simulated Author's Rebuttal
We thank the referee for the careful reading, positive assessment of significance, and constructive suggestions. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Abstract (and the numerical-experiments section)] The central claim that matching the approximate transition matrices produces a vector field whose true long-time statistics match the data rests on the regularized Ulam construction being a sufficiently faithful proxy for the true Perron-Frobenius operator. No a priori error bound, convergence rate, or stability analysis for the data-adaptive unstructured partition under noise or sparse sampling is supplied; this approximation quality is load-bearing for the superiority result.
Authors: We agree that the manuscript supplies no a priori error bounds, convergence rates, or stability analysis for the data-adaptive partition. The contribution is primarily empirical and algorithmic. In revision we will add a dedicated discussion paragraph on the approximation properties of the regularized Ulam matrix with continuous partition-of-unity weights, together with references to existing analyses of Ulam-type methods, to clarify the scope of the claims. revision: partial
-
Referee: [Abstract] The abstract asserts superior long-time behavior on Lorenz-63, Lorenz-96, and the NOAA SST problem, yet supplies no quantitative metrics (e.g., integrated autocorrelation times, Wasserstein distances on invariant measures, or prediction horizons with error bars) or explicit baseline comparisons; without these, the experimental support for the operator-matching advantage cannot be assessed.
Authors: We accept that the current presentation lacks explicit quantitative metrics and baseline comparisons. In the revised manuscript we will augment the numerical-experiments section with Wasserstein distances between learned and data-derived invariant measures, integrated autocorrelation times, and long-term prediction horizons (with error bars from repeated trials). The abstract will be updated to reference these metrics, and direct comparisons to the pointwise baseline will be highlighted throughout. revision: yes
Circularity Check
No circularity; objectives and validation are independent of fitted inputs
full rationale
The paper constructs a data-derived regularized Ulam matrix from trajectories using a data-adaptive partition and partition-of-unity weights, then defines independent training objectives that optimize a vector field to match either the full transition matrix or its stationary eigenvector. These objectives are not defined in terms of the learned parameters themselves, nor do any 'predictions' reduce by construction to a prior fit. Numerical experiments on Lorenz systems and NOAA data provide external validation of long-time behavior, with no load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A regularized Ulam transition matrix on a data-adaptive partition with continuous piecewise-smooth weights approximates the Perron-Frobenius operator sufficiently well for optimization.
Reference graph
Works this paper leans on
-
[1]
Discovering governing equations from data by sparse identification of nonlinear dynamical systems.Proceedings of the National Academy of Sciences, 113(15):3932–3937, 2016
Steven L Brunton, Joshua L Proctor, and J Nathan Kutz. Discovering governing equations from data by sparse identification of nonlinear dynamical systems.Proceedings of the National Academy of Sciences, 113(15):3932–3937, 2016
2016
-
[2]
Neural ordinary differential equations.Advances in Neural Information Processing Systems, 31, 2018
Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, and David K Duvenaud. Neural ordinary differential equations.Advances in Neural Information Processing Systems, 31, 2018
2018
-
[3]
Stabilized neural ordinary differential equations for long-time forecasting of dynamical systems.Journal of Computational Physics, 474:111838, 2023
Alec J Linot, Joshua W Burby, Qi Tang, Prasanna Balaprakash, Michael D Graham, and Romit Maulik. Stabilized neural ordinary differential equations for long-time forecasting of dynamical systems.Journal of Computational Physics, 474:111838, 2023
2023
-
[4]
Training neural operators to preserve invariant measures of chaotic attractors.Advances in Neural Information Processing Systems, 36, 2024
Ruoxi Jiang, Peter Y Lu, Elena Orlova, and Rebecca Willett. Training neural operators to preserve invariant measures of chaotic attractors.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[5]
Parker, Stephan Hoyer, Volodymyr Kuleshov, Fei Sha, and Leonardo Zepeda-N´ u˜ nez
Yair Schiff, Zhong Yi Wan, Jeffrey B. Parker, Stephan Hoyer, Volodymyr Kuleshov, Fei Sha, and Leonardo Zepeda-N´ u˜ nez. DySLIM: Dynamics stable learning by invariant measure for chaotic systems. InForty-first International Conference on Machine Learning, 2024
2024
-
[6]
Invariant measures in time-delay coordinates for unique dynamical system identification.Physical Review Letters, 135(16):167202, 2025
Jonah Botvinick-Greenhouse, Robert Martin, and Yunan Yang. Invariant measures in time-delay coordinates for unique dynamical system identification.Physical Review Letters, 135(16):167202, 2025
2025
-
[7]
Conditional Score-Based Modeling of Effective Langevin Dynamics
Ludovico T Giorgini. Conditional score-based modeling of effective langevin dynamics.arXiv preprint arXiv:2604.23952, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Learning to Emulate Chaos: Adversarial Optimal Transport Regularization
Gabriel Melo, Leonardo Santiago, and Peter Y Lu. Learning to emulate chaos: Adversarial optimal transport regularization.arXiv preprint arXiv:2604.21097, 2026. 25
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
A data-driven approach to model calibration for nonlinear dynamical systems.Journal of Applied physics, 125(24):244901, 2019
CM Greve, K Hara, RS Martin, DQ Eckhardt, and JW Koo. A data-driven approach to model calibration for nonlinear dynamical systems.Journal of Applied physics, 125(24):244901, 2019
2019
-
[10]
An adaptive subdivision technique for the approximation of attractors and invariant measures.Computing and Visualization in Science, 1(2):63–68, 1998
Michael Dellnitz and Oliver Junge. An adaptive subdivision technique for the approximation of attractors and invariant measures.Computing and Visualization in Science, 1(2):63–68, 1998
1998
-
[11]
Optimal partition choice for invariant measure approximation for one-dimensional maps.Nonlinearity, 17(5):1623, 2004
Rua Murray. Optimal partition choice for invariant measure approximation for one-dimensional maps.Nonlinearity, 17(5):1623, 2004
2004
-
[12]
Data-driven Reduction of Transfer Operators for Particle Clustering Dynamics
Nathalie Wehlitz, Grigorios A Pavliotis, Christof Sch¨ utte, and Stefanie Winkelmann. Data-driven reduction of transfer operators for particle clustering dynamics.arXiv preprint arXiv:2601.02932, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Data-driven computation of molecular reaction coordinates.The Journal of Chemical Physics, 149(15), 2018
Andreas Bittracher, Ralf Banisch, and Christof Sch¨ utte. Data-driven computation of molecular reaction coordinates.The Journal of Chemical Physics, 149(15), 2018
2018
-
[14]
Improving the stability of temporal statistics in transition path theory with sparse data.Chaos: An Interdisciplinary Journal of Nonlinear Science, 33(6), 2023
Gage Bonner, FJ Beron-Vera, and MJ Olascoaga. Improving the stability of temporal statistics in transition path theory with sparse data.Chaos: An Interdisciplinary Journal of Nonlinear Science, 33(6), 2023
2023
-
[15]
Optimal transport for parameter identification of chaotic dynamics via invariant measures.SIAM Journal on Applied Dynamical Systems, 22(1):269–310, 2023
Yunan Yang, Levon Nurbekyan, Elisa Negrini, Robert Martin, and Mirjeta Pasha. Optimal transport for parameter identification of chaotic dynamics via invariant measures.SIAM Journal on Applied Dynamical Systems, 22(1):269–310, 2023
2023
-
[16]
Learning dynamics on invariant measures using PDE-constrained optimization.Chaos: An Interdisciplinary Journal of Nonlinear Science, 33(6), 2023
Jonah Botvinick-Greenhouse, Robert Martin, and Yunan Yang. Learning dynamics on invariant measures using PDE-constrained optimization.Chaos: An Interdisciplinary Journal of Nonlinear Science, 33(6), 2023
2023
-
[17]
Invariant Measures for Data-Driven Dynamical System Identifica- tion: Analysis and Application, 2025
Jonah Botvinick-Greenhouse. Invariant Measures for Data-Driven Dynamical System Identifica- tion: Analysis and Application, 2025
2025
-
[18]
Springer Science & Business Media, 2013
Andrzej Lasota and Michael C Mackey.Chaos, fractals, and noise: stochastic aspects of dynamics, volume 97. Springer Science & Business Media, 2013
2013
-
[19]
Score-based modeling of effective langevin dynamics.arXiv preprint arXiv:2505.01895, 2025
Ludovico Theo Giorgini. Score-based modeling of effective langevin dynamics.arXiv preprint arXiv:2505.01895, 2025
-
[20]
Finite approximations of frobenius-perron operators
Jiu Ding and Aihui Zhou. Finite approximations of frobenius-perron operators. a solution of ulam’s conjecture to multi-dimensional transformations.Physica D: Nonlinear Phenomena, 92(1- 2):61–68, 1996
1996
-
[21]
On the numerical approximation of the Perron- Frobenius and Koopman operator.Journal of Computational Dynamics, 3(1):51–77, 2016
Stefan Klus, Peter Koltai, and Christof Sch¨ utte. On the numerical approximation of the Perron- Frobenius and Koopman operator.Journal of Computational Dynamics, 3(1):51–77, 2016
2016
-
[22]
Detection of coherent oceanic structures via transfer operators.Physical review letters, 98(22):224503, 2007
Gary Froyland, Kathrin Padberg, Matthew H England, and Anne Marie Treguier. Detection of coherent oceanic structures via transfer operators.Physical review letters, 98(22):224503, 2007
2007
-
[23]
Finite approximation for the frobenius-perron operator
Tien-Yien Li. Finite approximation for the frobenius-perron operator. a solution to ulam’s con- jecture.Journal of Approximation theory, 17(2):177–186, 1976
1976
-
[24]
PhD thesis, University of Western Australia, 1996
Gary Froyland.Estimating physical invariant measures and space averages of dynamical systems indicators. PhD thesis, University of Western Australia, 1996
1996
-
[25]
Constrained k-means clustering.Microsoft Research, Redmond, 20(0):0, 2000
Paul S Bradley, Kristin P Bennett, and Ayhan Demiriz. Constrained k-means clustering.Microsoft Research, Redmond, 20(0):0, 2000
2000
-
[26]
American Mathematical Soc., 2021
C´ edric Villani.Topics in optimal transportation, volume 58. American Mathematical Soc., 2021
2021
-
[27]
Pagerank beyond the web.SIAM Review, 57(3):321–363, 2015
David F Gleich. Pagerank beyond the web.SIAM Review, 57(3):321–363, 2015
2015
-
[28]
Caflisch
Russel E. Caflisch. Monte carlo and quasi-monte carlo methods.Acta Numerica, 7:1–49, 1998. 26
1998
-
[29]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InICLR (Poster), 2015
2015
-
[30]
An improved in situ and satellite sst analysis for climate.Journal of climate, 15(13):1609–1625, 2002
Richard W Reynolds, Nick A Rayner, Thomas M Smith, Diane C Stokes, and Wanqiu Wang. An improved in situ and satellite sst analysis for climate.Journal of climate, 15(13):1609–1625, 2002. 27
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.