Skip a Layer or Loop It? Learning Program-of-Layers in LLMs
Pith reviewed 2026-06-28 01:53 UTC · model grok-4.3
The pith
LLMs contain multiple valid layer execution programs that can skip or loop layers per input to match or exceed fixed-depth accuracy, often with fewer layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
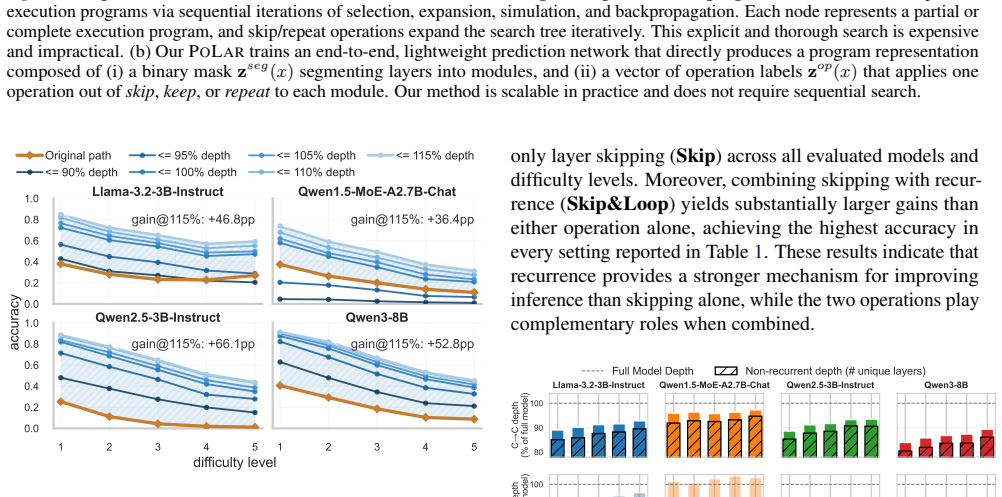
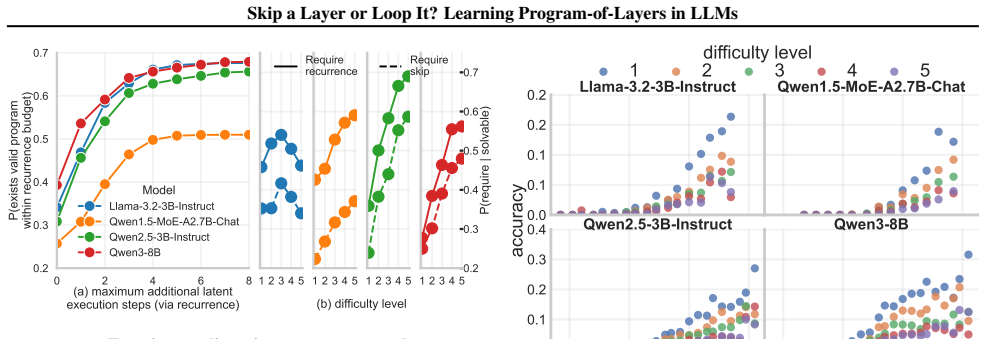
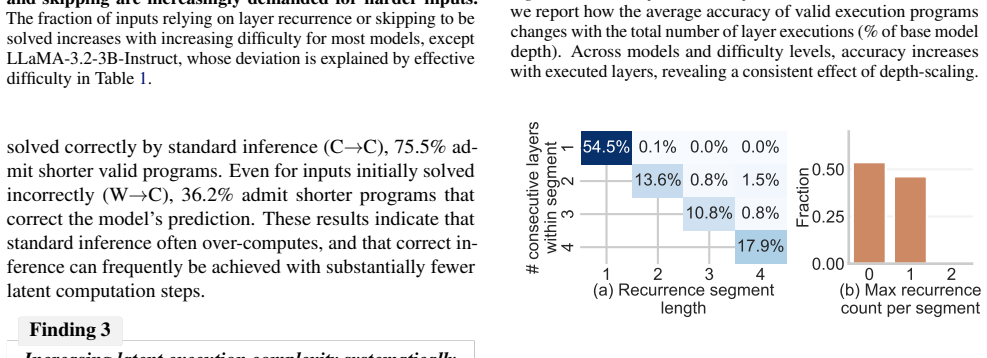
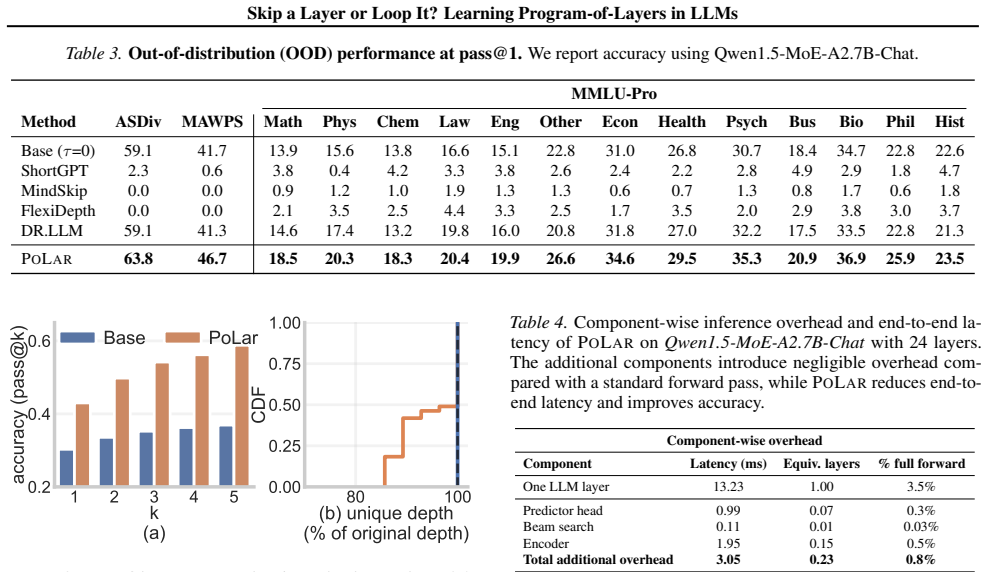
Pretrained layers can be packed as modules and then skipped or looped to form a customized program for each input. For most inputs, substantially shorter program executions achieve the same or better accuracy than the standard forward pass, while incorrect predictions of the original LLM can be corrected by alternative programs with fewer layers. These observations indicate that inference admits multiple valid latent computations beyond the standard forward pass.
What carries the argument
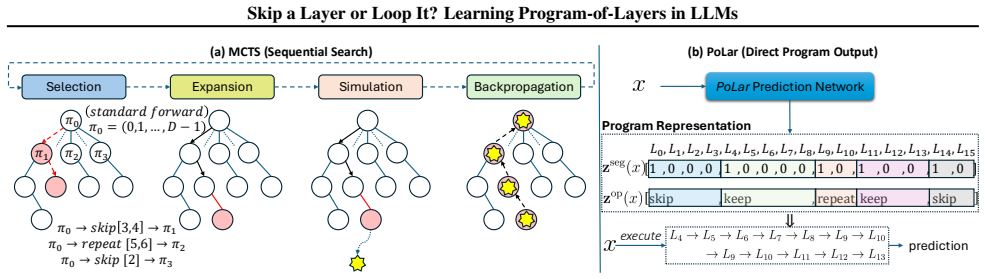
The PoLar (program-of-layers) prediction network, a lightweight model trained to output per-input execution programs that dynamically skip or repeat pretrained layers.
If this is right
- Accuracy on mathematical reasoning benchmarks rises above both standard inference and prior dynamic-depth methods.
- The number of layers executed drops for many inputs while accuracy holds or improves.
- Performance gains remain when the inputs come from a distribution different from training data.
- Fixed-depth execution uses only a narrow subset of the LLM's latent reasoning capacity.
Where Pith is reading between the lines
- If programs of layers can be discovered cheaply, training procedures might be redesigned to encourage more reusable or composable layer modules from the start.
- The same idea could be tested on non-transformer architectures to see whether dynamic layer programs are a general property of deep networks.
- Inference-time cost could be budgeted per example by training the prediction network to favor shorter programs when accuracy targets are met.
Load-bearing premise
A small auxiliary network can be trained to pick effective skip-or-loop programs for new inputs without adding much cost or losing performance across different models and tasks.
What would settle it
Running the PoLar network on a new math-reasoning benchmark where the generated programs never match or exceed the original model's accuracy and never use fewer layers on average.
Figures

read the original abstract
Large language models (LLMs) perform inference by following a fixed depth and order, non-recurrent execution of all layers. We reveal the wide existence of training-free, flexible, dynamic program-of-layers (PoLar), where pretrained layers can be packed as modules and then skipped or looped to form a customized program for each input. For most inputs, substantially shorter program executions can achieve the same or better accuracy, while incorrect predictions of the original LLM can be corrected by alternative programs with fewer layers. These observations indicate that inference admits multiple valid latent computations beyond the standard forward pass. To efficiently achieve PoLar in practice, we propose a lightweight PoLar prediction network, which learns to generate execution programs that dynamically skip or repeat pretrained layers for each input. Experiments on mathematical reasoning benchmarks demonstrate that PoLar consistently improves accuracy over standard inference and prior dynamic-depth methods, often while executing fewer layers, and that these gains persist under out-of-distribution evaluation. Our results suggest that fixed-depth execution captures only a narrow subset of an LLM's latent reasoning capacity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that pretrained LLMs admit multiple valid latent layer-execution programs (PoLar) beyond the fixed forward pass; these can be discovered in a training-free manner by skipping or looping layers, often matching or exceeding standard accuracy (including error correction) with fewer layers on mathematical reasoning benchmarks, and that such programs persist OOD. It further introduces a lightweight PoLar prediction network that learns to generate input-specific skip/loop programs, reporting consistent accuracy gains over standard inference and prior dynamic-depth methods while frequently executing fewer layers.
Significance. If the training-free observations are reproducible and the prediction network proves efficient and general, the work would demonstrate that fixed-depth execution captures only a narrow subset of an LLM's latent reasoning capacity, with direct implications for dynamic inference and model understanding. The emphasis on training-free discovery and OOD persistence are notable strengths if quantitatively supported.
major comments (2)
- [Abstract] Abstract: the central practical claim that the lightweight PoLar prediction network 'learns to generate execution programs' and yields gains 'often while executing fewer layers' is load-bearing for moving from the training-free observations to deployable inference; the abstract provides no information on network size/FLOPs relative to layer savings, training-data construction, or overhead, leaving the efficiency assertion unassessable.
- [Abstract] Abstract: the assertion that alternative programs 'correct' incorrect predictions of the original LLM with fewer layers is presented as evidence for multiple valid computations, yet no quantitative breakdown (e.g., fraction of errors corrected, average layer reduction on those cases) is supplied, which is required to evaluate whether this supports the broader inference claim.
Simulated Author's Rebuttal
We thank the referee for these focused comments on the abstract. Both points identify areas where additional detail would strengthen the presentation of the efficiency and error-correction claims. We will revise the abstract to incorporate the requested information drawn from the body of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central practical claim that the lightweight PoLar prediction network 'learns to generate execution programs' and yields gains 'often while executing fewer layers' is load-bearing for moving from the training-free observations to deployable inference; the abstract provides no information on network size/FLOPs relative to layer savings, training-data construction, or overhead, leaving the efficiency assertion unassessable.
Authors: We agree that the abstract should make the efficiency claims assessable without requiring the reader to consult the main text. The manuscript (Section 4.2) specifies that the PoLar predictor is a two-layer MLP with hidden dimension 256, trained on programs discovered via the training-free search on the training split; it reports that the predictor adds <0.1% FLOPs relative to a single LLM layer while achieving average layer reductions of 15-25% on the evaluated benchmarks. We will add a concise clause to the abstract stating the predictor size, training-data source, and net layer savings. revision: yes
-
Referee: [Abstract] Abstract: the assertion that alternative programs 'correct' incorrect predictions of the original LLM with fewer layers is presented as evidence for multiple valid computations, yet no quantitative breakdown (e.g., fraction of errors corrected, average layer reduction on those cases) is supplied, which is required to evaluate whether this supports the broader inference claim.
Authors: The manuscript (Section 5.3 and Table 3) already contains the quantitative breakdown: on GSM8K, alternative programs correct 12.4% of the original errors while using 18% fewer layers on average; similar figures are reported for MATH and AQuA. We acknowledge that these numbers are absent from the abstract. We will revise the abstract to include a short quantitative statement of the error-correction rate and associated layer reduction. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper's central claims rest on empirical observations that alternative skip/loop programs match or exceed standard LLM accuracy on math benchmarks (including error correction) and persist OOD, plus a separately trained lightweight prediction network. No step reduces by construction to fitted inputs, self-definitions, or self-citation chains; the existence of latent computations is presented as falsifiable via direct experimentation rather than presupposed by the method itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bae, S., Kim, Y ., Bayat, R., Kim, S., Ha, J., Schuster, T., Fisch, A., Harutyunyan, H., Ji, Z., Courville, A., et al. Mixture-of-recursions: Learning dynamic recur- sive depths for adaptive token-level computation.arXiv preprint arXiv:2507.10524,
-
[2]
Chen, Y ., Shang, J., Zhang, Z., Xie, Y ., Sheng, J., Liu, T., Wang, S., Sun, Y ., Wu, H., and Wang, H. Inner thinking transformer: Leveraging dynamic depth scal- ing to foster adaptive internal thinking.arXiv preprint arXiv:2502.13842,
-
[3]
Dehghani, M., Gouws, S., Vinyals, O., Uszkoreit, J., and Kaiser, Ł. Universal transformers.arXiv preprint arXiv:1807.03819,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Reducing transformer depth on demand with structured dropout.arXiv preprint arXiv:1909.11556,
Fan, A., Grave, E., and Joulin, A. Reducing transformer depth on demand with structured dropout.arXiv preprint arXiv:1909.11556,
-
[5]
Looped transformers for length generalization.arXiv preprint arXiv:2409.15647,
Fan, Y ., Du, Y ., Ramchandran, K., and Lee, K. Looped transformers for length generalization.arXiv preprint arXiv:2409.15647,
-
[6]
He, S., Ge, T., Sun, G., Tian, B., Wang, X., and Yu, D. Router-tuning: A simple and effective approach for en- abling dynamic-depth in transformers.arXiv preprint arXiv:2410.13184,
-
[7]
Heakl, A., Gubri, M., Khan, S., Yun, S., and Oh, S. J. Dr. llm: Dynamic layer routing in llms.arXiv preprint arXiv:2510.12773,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Calc-x and calcformers: Empowering arithmetical chain- of-thought through interaction with symbolic systems
Kadlˇc´ık, M., ˇStef´anik, M., Sotol ´ar, O., and Martinek, V . Calc-x and calcformers: Empowering arithmetical chain- of-thought through interaction with symbolic systems. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 12101– 12108,
2023
-
[9]
Li, Z., Li, Y ., and Zhou, T. Skip a layer or loop it? test- time depth adaptation of pretrained llms.arXiv preprint arXiv:2507.07996,
-
[10]
Faster depth- adaptive transformers
Liu, Y ., Meng, F., Zhou, J., Chen, Y ., and Xu, J. Faster depth- adaptive transformers. InProceedings of the AAAI Con- ference on Artificial Intelligence, volume 35, pp. 13424– 13432, 2021a. Liu, Z., Li, F., Li, G., and Cheng, J. Ebert: Efficient bert inference with dynamic structured pruning. InFindings of the Association for Computational Linguistics: ...
-
[11]
Shortgpt: Layers in large language models are more redundant than you expect
Men, X., Xu, M., Zhang, Q., Yuan, Q., Wang, B., Lin, H., Lu, Y ., Han, X., and Chen, W. Shortgpt: Layers in large language models are more redundant than you expect. InFindings of the Association for Computational Linguistics: ACL 2025, pp. 20192–20204,
2025
-
[12]
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
Raposo, D., Ritter, S., Richards, B., Lillicrap, T., Humphreys, P. C., and Santoro, A. Mixture-of-depths: Dynamically allocating compute in transformer-based lan- guage models.arXiv preprint arXiv:2404.02258,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Wu, Q., Ke, Z., Zhou, Y ., Sun, X., and Ji, R. Routing ex- perts: Learning to route dynamic experts in multi-modal large language models.arXiv preprint arXiv:2407.14093,
-
[14]
Deebert: Dynamic early exiting for accelerating bert inference
Xin, J., Tang, R., Lee, J., Yu, Y ., and Lin, J. Deebert: Dynamic early exiting for accelerating bert inference. arXiv preprint arXiv:2004.12993,
-
[15]
Looped transformers are better at learning learning al- gorithms.arXiv preprint arXiv:2311.12424,
Yang, L., Lee, K., Nowak, R., and Papailiopoulos, D. Looped transformers are better at learning learning al- gorithms.arXiv preprint arXiv:2311.12424,
-
[16]
Laco: Large lan- guage model pruning via layer collapse.arXiv preprint arXiv:2402.11187,
Yang, Y ., Cao, Z., and Zhao, H. Laco: Large lan- guage model pruning via layer collapse.arXiv preprint arXiv:2402.11187,
-
[17]
Related Work Layer Pruning and Early-Exit Neural NetworksMany works aim to accelerate large Transformers by statically pruning weights or dynamically halting computation
12 Skip a Layer or Loop It? Learning Program-of-Layers in LLMs A. Related Work Layer Pruning and Early-Exit Neural NetworksMany works aim to accelerate large Transformers by statically pruning weights or dynamically halting computation. Static pruning typically removes redundant neurons, heads, or layers after training. For example, Liu et al. (2021b) dem...
2020
-
[18]
PABEE (Zhou et al.,
and DeeBERT (Xin et al., 2020), which insert classifiers after each block and use confidence or entropy metrics to decide when to stop. PABEE (Zhou et al.,
2020
-
[19]
Multiple Exiting
adopts a differentiable Adaptive Computation Time mechanism to learn how many Transformer layers to run for each example. Liu et al. (2021a) estimate input ”hardness” via mutual information or reconstruction error to pre-determine the number of Transformer layers to use. These early-exit networks achieve significant speedups on NLP tasks by adaptively red...
2023
-
[20]
thinking
was an early example: it applies the same self-attention block recurrently and uses a halting mechanism to determine when each position is “done” (adapting depth per token). Building on these ideas, recent work explicitly introduces loops in model architectures. Fan et al. (2024) demonstrate that a Looped Transformer – a single Transformer block applied r...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.