MUDIDI: A Two-Stage Framework for Multilingual Dictionary Digitization with Language Models
Pith reviewed 2026-06-27 16:44 UTC · model grok-4.3
The pith
Large language models outperform OCR systems and vision-language models when digitizing scanned multilingual dictionaries into structured formats.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
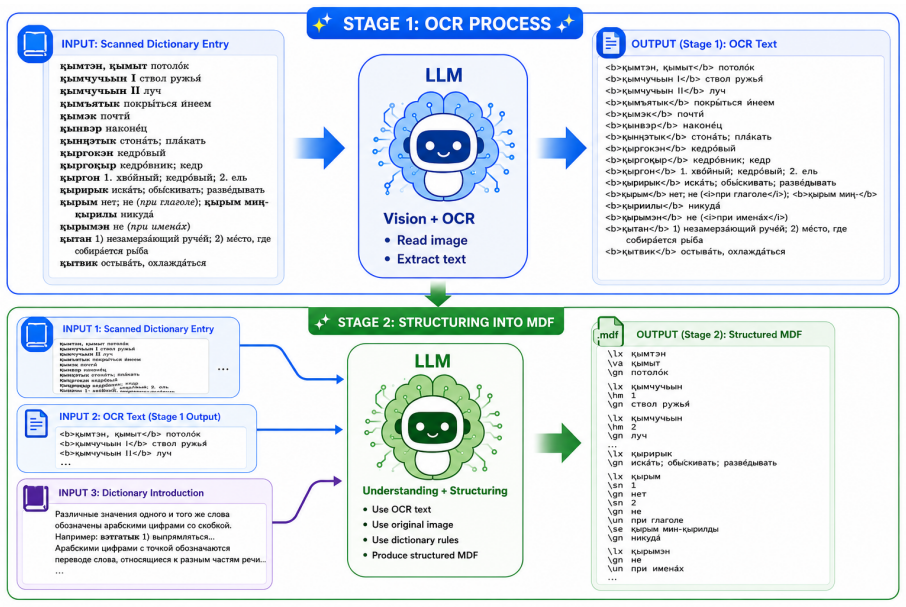
MUDIDI is a two-stage framework for multilingual dictionary digitization. Stage One evaluates the quality of character recognition and markup preservation. Stage Two focuses on dictionary entry segmentation with subsequent mapping into a machine-readable lexicographic schema, SIL's Multi-Dictionary Formatter. A dataset of human-annotated lexicographic entries from 30 public-domain dictionaries featuring diverse writing systems, language families, and formats is released. Benchmarks of OCR systems, general-purpose LLMs, and VLMs demonstrate superior performance of LLMs across most writing systems and languages in both stages. Supplementing additional information such as dictionary introductio
What carries the argument
The MUDIDI two-stage framework, which first assesses recognition quality and markup then performs entry segmentation and schema mapping using language models.
If this is right
- LLMs deliver higher accuracy than OCR systems and VLMs on character recognition, markup preservation, and entry segmentation across most scripts and languages.
- Providing dictionary introductions as additional input improves LLM performance on the digitization task.
- The released dataset enables systematic comparison of future models on lexicographic digitization.
- Practical guidelines derived from the benchmarks can guide model use on difficult dictionary formats.
Where Pith is reading between the lines
- Successful digitization at scale would make previously inaccessible records of endangered languages available for computational analysis and preservation.
- The staged separation of recognition from structural parsing could be adapted to other scanned documents that combine text with complex layouts, such as historical scientific tables.
- Once entries are in the Multi-Dictionary Formatter schema, they become directly usable by existing lexicographic software and downstream language technology pipelines.
Load-bearing premise
The human-annotated entries from the 30 selected public-domain dictionaries form a representative sample of the layout, abbreviation, and script challenges that appear in multilingual lexicographic materials.
What would settle it
If LLMs do not exceed OCR or VLM accuracy on character recognition, markup preservation, or entry segmentation when tested on a fresh collection of dictionaries with comparable diversity, the claim of LLM superiority would be falsified.
Figures
read the original abstract
Multilingual dictionaries are among the most valuable documentary resources for low-resource and endangered languages, yet many remain available only as scans. For many decades, their digitization and conversion into a machine-readable format was nearly impossible due to language-specific scripts, complex multi-column layouts full of entries with abbreviations and cross-references. Recent vision-language models offer a promising solution, but it is unclear how well they preserve characters, markup, and process lexicographic structure. We introduce MUDIDI, a two-stage framework for multi-lingual dictionary digitization. Stage One evaluates the quality of character recognition and markup preservation; Stage Two focuses on dictionary entry segmentation with subsequent mapping into a machine-readable lexicographic schema, SIL's Multi-Dictionary Formatter. We also release a dataset that consists of human-annotated lexicographic entries collected from 30 public-domain dictionaries featuring diverse writing systems, language families, and formats. We benchmark OCR systems, general-purpose Large Language Models (LLMs), and Vision Language Models (VLMs) on the dataset, demonstrating superior performance of LLMs across most writing systems and languages in both stages, and provide practical guidelines on improving the results for more challenging scenarios. Finally, we show that supplementing additional information, such as dictionary introduction, to the LLMs can improve the quality of the digitized dictionary. Github: https://github.com/DavidSamuell/MUDIDI-Pipeline-for-Digitization-of-Multilingual-Dictionary/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MUDIDI, a two-stage framework for digitizing multilingual dictionaries from scans. Stage One evaluates character recognition and markup preservation; Stage Two performs entry segmentation and mapping to SIL's Multi-Dictionary Formatter schema. It releases a human-annotated dataset from 30 public-domain dictionaries spanning diverse writing systems and language families, benchmarks OCR systems, general-purpose LLMs, and VLMs, and claims superior LLM performance across most writing systems and languages in both stages. Additional experiments show that providing dictionary introductions improves results, with code released on GitHub.
Significance. If the benchmarking holds under scrutiny, the work supplies an open dataset and reproducible pipeline that could meaningfully aid preservation of low-resource and endangered-language lexicographic materials. The two-stage design and practical guidelines for challenging cases add applied value in computational linguistics and digital humanities.
major comments (3)
- [Dataset section] Dataset section: No selection criteria, coverage statistics by script family (e.g., abugida, logographic), or layout complexity metrics are supplied for the 30 dictionaries. This directly undermines the abstract's generalization that LLMs are superior 'across most writing systems and languages.'
- [Experiments/Results section] Experiments/Results section: The manuscript supplies no quantitative metrics (e.g., CER, F1 for segmentation), statistical significance tests, or error analysis to support the superiority claims over OCR and VLMs; the reader's note on missing evaluation details remains unaddressed in the full text.
- [Stage Two description] Stage Two description: The prompting strategy and exact mechanism for mapping LLM outputs to the MDF schema are described at too high a level to assess whether the two-stage separation is load-bearing or whether direct prompting would suffice.
minor comments (2)
- [Abstract] Abstract: Lacks any numerical performance deltas or the exact count of scripts/languages evaluated, reducing informativeness.
- [Figures] Figure captions: Some example dictionary pages and model outputs would benefit from clearer labeling of which system produced which result.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below, agreeing where the manuscript requires strengthening and outlining specific revisions to improve clarity, rigor, and support for our claims.
read point-by-point responses
-
Referee: [Dataset section] Dataset section: No selection criteria, coverage statistics by script family (e.g., abugida, logographic), or layout complexity metrics are supplied for the 30 dictionaries. This directly undermines the abstract's generalization that LLMs are superior 'across most writing systems and languages.'
Authors: We agree that the Dataset section lacks sufficient detail on selection criteria and coverage. In the revision, we will add explicit selection criteria (e.g., public-domain status, diversity of scripts and layouts), coverage statistics by script family (abugida, logographic, alphabetic, etc.), and layout complexity metrics (e.g., columns, abbreviations, cross-references). These additions will directly support the generalization in the abstract. revision: yes
-
Referee: [Experiments/Results section] Experiments/Results section: The manuscript supplies no quantitative metrics (e.g., CER, F1 for segmentation), statistical significance tests, or error analysis to support the superiority claims over OCR and VLMs; the reader's note on missing evaluation details remains unaddressed in the full text.
Authors: We acknowledge that the current manuscript relies on qualitative claims without supporting quantitative metrics, tests, or error analysis. We will add Character Error Rate (CER) for Stage One, F1 scores for segmentation in Stage Two, statistical significance tests, and a dedicated error analysis subsection. These will be integrated into the Experiments/Results section to substantiate the superiority claims. revision: yes
-
Referee: [Stage Two description] Stage Two description: The prompting strategy and exact mechanism for mapping LLM outputs to the MDF schema are described at too high a level to assess whether the two-stage separation is load-bearing or whether direct prompting would suffice.
Authors: We will expand the Stage Two description with concrete prompt templates, examples of LLM outputs, and a step-by-step account of the mapping process to the SIL Multi-Dictionary Formatter schema. This will include pseudocode or workflow diagrams to clarify the role of the two-stage design versus direct prompting. revision: yes
Circularity Check
No circularity: empirical benchmarking study
full rationale
The paper introduces MUDIDI as a two-stage framework and releases a human-annotated dataset from 30 dictionaries, then reports direct benchmark results of OCR, LLM, and VLM performance on that dataset. No equations, fitted parameters, derivations, or self-citation chains appear in the abstract or described structure. The central claim (LLM superiority on the released data) is a straightforward empirical measurement and does not reduce to any input by construction. Representativeness concerns affect external validity but are not circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Fu, Ling and Kuang, Zhebin and Song, Jiajun and Huang, Mingxin and Yang, Biao and Li, Yuzhe and Zhu, Linghao and Luo, Qidi and Wang, Xinyu and Lu, Hao and Li, Zhang and Tang, Guozhi and Shan, Bin and Lin, Chunhui and Liu, Qi and Wu, Binghong and Feng, Hao and Liu, Hao and Huang, Can and Tang, Jingqun and Chen, Wei and Jin, Lianwen and Liu, Yuliang and Bai...
-
[2]
Zhou, Changda and Gao, Ziyue and Wang, Xueqing and Gao, Tingquan and Cui, Cheng and Tang, Jing and Liu, Yi , journal=
-
[3]
2024 , eprint =
CC-OCR: A Comprehensive and Challenging OCR Benchmark for Evaluating Large Multimodal Models in Literacy , author =. 2024 , eprint =
2024
-
[4]
2025 , pages =
Ouyang, Linke and Qu, Yuan and Zhou, Hongbin and Zhu, Jiawei and Zhang, Rui and Lin, Qunshu and Wang, Bin and Zhao, Zhiyuan and Jiang, Man and Zhao, Xiaomeng and Shi, Jin and Wu, Fan and Chu, Pei and Liu, Minghao and Li, Zhenxiang and Xu, Chao and Zhang, Bo and Shi, Botian and Tu, Zhongying and He, Conghui , booktitle =. 2025 , pages =
2025
-
[5]
Multimodal
Greif, Gavin and Griesshaber, Niclas and Greif, Robin , journal=. Multimodal
- [6]
-
[7]
The Routledge handbook of language revitalization , pages=
Online dictionaries for language revitalization , author=. The Routledge handbook of language revitalization , pages=. 2018 , publisher=
2018
-
[8]
Language documentation and description , volume=
Dictionary making in endangered speech communities , author=. Language documentation and description , volume=. 2004 , publisher=
2004
-
[9]
The State and Fate of Linguistic Diversity and Inclusion in the NLP World
Joshi, Pratik and Santy, Sebastin and Budhiraja, Amar and Bali, Kalika and Choudhury, Monojit. The State and Fate of Linguistic Diversity and Inclusion in the NLP World. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.560
-
[10]
Duan, Shuaiqi and Xue, Yadong and Wang, Weihan and Su, Zhe and Liu, Huan and Yang, Sheng and Gan, Guobing and Wang, Guo and Wang, Zihan and Yan, Shengdong and others , year =
-
[11]
Tkachenko, Maxim and Malyuk, Mikhail and Holmanyuk, Andrey and Liubimov, Nikolai , year=
-
[12]
Library Resources & Technical Services , volume=
HathiTrust , author=. Library Resources & Technical Services , volume=
-
[13]
2025 , eprint =
Qwen3-VL Technical Report , author =. 2025 , eprint =
2025
-
[14]
International Conference on Learning Representations , volume=
A benchmark for learning to translate a new language from one grammar book , author=. International Conference on Learning Representations , volume=
-
[15]
2026 , howpublished =
Re-OCRing Collections , author =. 2026 , howpublished =
2026
-
[16]
Proceedings of the National Academy of Sciences , volume=
A computational analysis of lexical elaboration across languages , author=. Proceedings of the National Academy of Sciences , volume=. 2025 , publisher=
2025
-
[17]
5: A decoupled vision-language model for efficient high-resolution document parsing , author=
Mineru2. 5: A decoupled vision-language model for efficient high-resolution document parsing , author=. The 64th Annual Meeting of the Association for Computational Linguistics--Industry Track , year=
-
[18]
Cui, Cheng and Sun, Ting and Liang, Suyin and Gao, Tingquan and Zhang, Zelun and Liu, Jiaxuan and Wang, Xueqing and Zhou, Changda and Liu, Hongen and Lin, Manhui and others , journal=
-
[19]
Li, Yumeng and Yang, Guang and Liu, Hao and Wang, Bowen and Zhang, Colin , journal=. dots. ocr:
-
[20]
Bai, Shuai and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Song, Sibo and Dang, Kai and Wang, Peng and Wang, Shijie and Tang, Jun and others , journal=
-
[21]
2026 , url =
Zero-Shot Digitization of Historical Documents with Vision Language Models , author =. 2026 , url =
2026
-
[22]
2025 , doi =
Merx, Raphael and Suominen, Hanna and Hong, Lois Yinghui and Thieberger, Nick and Cohn, Trevor and Vylomova, Ekaterina , booktitle =. 2025 , doi =
2025
-
[23]
2000 , url =
Multi-Dictionary Formatter (. 2000 , url =
2000
-
[24]
2026 , url =
TEI Lex-0: A Baseline Encoding for Lexicographic Data , author =. 2026 , url =
2026
-
[25]
Technology Review , volume =
Whorf, Benjamin Lee , title =. Technology Review , volume =
-
[26]
Proceedings of the 28th International Conference on Computational Linguistics , year =
Decolonising Speech and Language Technology , author =. Proceedings of the 28th International Conference on Computational Linguistics , year =. doi:10.18653/v1/2020.coling-main.313 , url =
-
[27]
Not always about you: Prioritizing community needs when developing endangered language technology , author =. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =. doi:10.18653/v1/2022.acl-long.272 , url =
-
[28]
Participatory Research for Low-resourced Machine Translation: A Case Study in
Nekoto, Wilhelmina and Marivate, Vukosi and others , booktitle =. Participatory Research for Low-resourced Machine Translation: A Case Study in. 2020 , address =. doi:10.18653/v1/2020.findings-emnlp.195 , url =
-
[29]
Low-resource Machine Translation:
Merx, Raphael and Correia, Ad. Low-resource Machine Translation:. Proceedings of the Eighth Workshop on Technologies for Machine Translation of Low-Resource Languages (LoResMT 2025) , url=
2025
-
[30]
Carroll, Stephanie Russo and Garba, Ibrahim and Figueroa-Rodríguez, Oscar L. and Holbrook, Jarita and Lovett, Raymond and Materechera, Simeon and Parsons, Mark and Raseroka, Kay and Rodriguez-Lonebear, Desi and Rowe, Robyn and Sara, Rodrigo and Walker, Jennifer D. and Anderson, Jane and Hudson, Maui , journal =. The. 2020 , doi =
2020
-
[31]
2026 , url =
TEI Guidelines: Dictionaries , author =. 2026 , url =
2026
-
[32]
Research, Records and Responsibility:: Ten years of
Harris, Amanda and Thieberger, Nick and Barwick, Linda , year=. Research, Records and Responsibility:: Ten years of
-
[33]
Literary and Linguistic Computing , volume=
The Open Language Archives Community: An infrastructure for distributed archiving of language resources , author=. Literary and Linguistic Computing , volume=. 2003 , publisher=
2003
-
[34]
Report of the Third Committee , author =
Rights of indigenous peoples. Report of the Third Committee , author =. 2019 , url =
2019
-
[35]
2026 , url =
Copyright for Researchers , author =. 2026 , url =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.