FlashEdit: Decoupling Speed, Structure, and Semantics for Precise Image Editing
Pith reviewed 2026-05-21 22:21 UTC · model grok-4.3
The pith
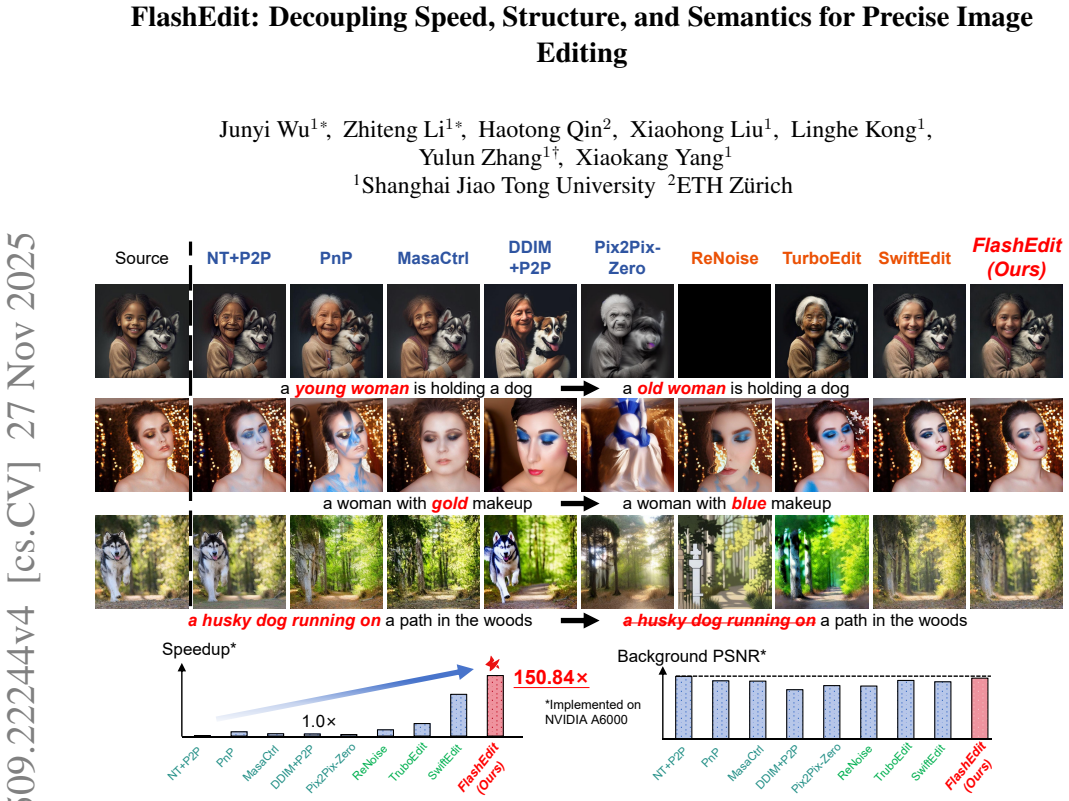
FlashEdit achieves precise text-guided image editing in under 0.2 seconds by using one-step inversion with cycle consistency and attention controls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The method combines Cycle-Consistent One-Step Inversion to align latents on the manifold in a single step, Background Shield to intervene in structural self-attention for non-edited region preservation, and Sparsified Spatial Cross-Attention to limit semantic leakage, delivering edits in under 0.2 seconds with over 150 times speedup versus multi-step DDIM inversion on PIE-Bench.
What carries the argument
Cycle-Consistent One-Step Inversion (COSI) pipeline that enforces manifold alignment via cycle consistency, together with Background Shield for structural self-attention intervention and Sparsified Spatial Cross-Attention for semantic focus.
If this is right
- Editing latency drops enough to support interactive applications such as live photo retouching.
- Non-edited image regions retain structural details more reliably through the self-attention shield.
- Semantic leakage is reduced so that text instructions affect only the targeted object or region.
- The overall pipeline runs on consumer hardware without specialized accelerators.
Where Pith is reading between the lines
- The same one-step inversion idea could be tested on video sequences to enable frame-by-frame editing without accumulating drift.
- The three components might be combined with other inversion-free editing methods to further cut compute.
- If the speed holds on larger models, it could change the cost structure of batch image editing services.
Load-bearing premise
The one-step cycle-consistent inversion produces latents close enough to the data manifold that no further multi-step refinement is needed for good edit quality.
What would settle it
Direct comparison on PIE-Bench showing that the one-step COSI version produces visibly lower edit accuracy or background preservation than standard multi-step DDIM inversion under identical prompts and masks.
Figures




read the original abstract
Text-guided image editing with diffusion models has achieved remarkable quality but often suffers from prohibitive latency. We introduce \textbf{FlashEdit}, a real-time localized image editing framework for the standard inversion-based editing setting. Its efficiency and precision stem from three key innovations: (1) a \textbf{Cycle-Consistent One-Step Inversion (COSI)} pipeline that encourages manifold-aligned one-step inversion through cycle consistency; (2) a \textbf{Background Shield (BG-Shield)} technique that improves preservation of non-edited regions via structural self-attention intervention; and (3) a \textbf{Sparsified Spatial Cross-Attention (SSCA)} mechanism that promotes precise edits by suppressing semantic leakage. Experiments on PIE-Bench demonstrate a strong preservation-efficiency trade-off, with edits completed in under 0.2 seconds and an over 150$\times$ speedup over DDIM-based multi-step editing. Our code will be made publicly available at \url{https://github.com/JunyiWuCode/FlashEdit}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FlashEdit, a real-time framework for localized text-guided image editing using diffusion models in the inversion-based setting. The approach decouples speed, structure, and semantics through three innovations: (1) Cycle-Consistent One-Step Inversion (COSI) that uses cycle consistency to encourage manifold-aligned latents for fast inversion; (2) Background Shield (BG-Shield) that uses structural self-attention intervention to preserve non-edited regions; and (3) Sparsified Spatial Cross-Attention (SSCA) that suppresses semantic leakage for precise localized edits. On the PIE-Bench dataset, the method achieves edits in under 0.2 seconds, representing a 150× speedup over standard DDIM-based multi-step editing while maintaining a strong preservation-efficiency trade-off.
Significance. If the central claims hold, particularly that COSI enables quality-preserving one-step edits, this would be a significant contribution toward practical real-time diffusion-based image editing. The planned public code release supports reproducibility and is a strength.
major comments (2)
- [Methods (COSI pipeline description)] The justification for COSI (described in the methods as the source of both speed and precision) relies on the assumption that cycle consistency produces manifold-aligned latents suitable for accurate text-conditioned localized editing. Cycle consistency enforces reconstruction fidelity but does not automatically guarantee the latent properties needed to avoid quality degradation in editing without multi-step refinement; this is load-bearing for the 150× speedup claim without unacknowledged quality cost.
- [Experiments and results section] The PIE-Bench experiments report strong preservation-efficiency results but omit error bars, full baseline implementation details, and ablations on free parameters (attention suppression threshold in SSCA, cycle-consistency loss weight). Without these, the robustness of the reported trade-off cannot be fully assessed.
minor comments (1)
- Notation for attention mechanisms in BG-Shield and SSCA could be made more explicit to aid readers not deeply familiar with inversion-based editing pipelines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, providing our response and indicating planned revisions to strengthen the paper.
read point-by-point responses
-
Referee: The justification for COSI (described in the methods as the source of both speed and precision) relies on the assumption that cycle consistency produces manifold-aligned latents suitable for accurate text-conditioned localized editing. Cycle consistency enforces reconstruction fidelity but does not automatically guarantee the latent properties needed to avoid quality degradation in editing without multi-step refinement; this is load-bearing for the 150× speedup claim without unacknowledged quality cost.
Authors: We thank the referee for this observation. Cycle consistency is used in COSI to encourage latents that remain close to the data manifold after one-step inversion, which our empirical results on PIE-Bench support through strong preservation metrics and visual quality comparable to multi-step baselines. However, we acknowledge that the current manuscript provides primarily empirical justification rather than a deeper theoretical analysis of the latent properties. In the revised version, we will expand the methods section with additional discussion on the role of cycle consistency in promoting manifold alignment, including references to related analyses of diffusion latent spaces, and add an ablation study isolating the effect of the cycle-consistency term on editing quality and speed. revision: partial
-
Referee: The PIE-Bench experiments report strong preservation-efficiency results but omit error bars, full baseline implementation details, and ablations on free parameters (attention suppression threshold in SSCA, cycle-consistency loss weight). Without these, the robustness of the reported trade-off cannot be fully assessed.
Authors: We agree that these elements are necessary for a complete evaluation of robustness. In the revised manuscript, we will add error bars (computed over multiple random seeds) to all quantitative results in the experiments section. We will also include detailed implementation specifications for all baselines and introduce new ablation studies on the attention suppression threshold in SSCA and the cycle-consistency loss weight. These additions will appear in the main paper or supplementary material to allow readers to assess the sensitivity of the reported trade-off. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The paper frames FlashEdit as a set of extensions to existing inversion-based diffusion editing pipelines, with COSI, BG-Shield, and SSCA introduced as concrete algorithmic interventions whose effects are then measured on PIE-Bench. The reported 150× speedup and sub-0.2 s latency are empirical outcomes of these interventions rather than quantities derived by construction from fitted hyperparameters or self-referential definitions. Cycle consistency is presented as a training objective that encourages (not defines) manifold alignment; the alignment claim is not used to tautologically justify the speed or precision results. No equation or self-citation chain reduces the central performance claims to the inputs by construction, satisfying the criteria for a non-circular derivation.
Axiom & Free-Parameter Ledger
free parameters (2)
- attention suppression threshold in SSCA
- cycle-consistency loss weight
axioms (2)
- domain assumption One-step inversion can be made manifold-aligned via cycle consistency
- domain assumption Structural self-attention intervention leaves non-edited regions unchanged
Forward citations
Cited by 1 Pith paper
-
GHOST: Geometry-Hierarchical Online Streaming Token Eviction for Efficient 3D Reconstruction
GHOST applies geometry-hierarchical online token eviction with hierarchical scoring, privilege protection, and layer-wise budget allocation to halve KV cache size while maintaining reconstruction quality and achieving...
Reference graph
Works this paper leans on
-
[1]
In- structpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. In- structpix2pix: Learning to follow image editing instructions. InCVPR, 2023. 1
work page 2023
-
[2]
Masactrl: Tuning-free mu- tual self-attention control for consistent image synthesis and editing
Mingdeng Cao, Xintao Wang, Zhongang Qi, Ying Shan, Xi- aohu Qie, and Yinqiang Zheng. Masactrl: Tuning-free mu- tual self-attention control for consistent image synthesis and editing. InICCV, 2023. 2, 7, 8
work page 2023
-
[3]
Dove: Efficient one- step diffusion model for real-world video super-resolution
Zheng Chen, Zichen Zou, Kewei Zhang, Xiongfei Su, Xin Yuan, Yong Guo, and Yulun Zhang. Dove: Efficient one- step diffusion model for real-world video super-resolution. InNeurIPS, 2025. 4, 7
work page 2025
-
[4]
Diffedit: Diffusion-based semantic image editing with mask guidance,
Guillaume Couairon, Jakob Verbeek, Holger Schwenk, and Matthieu Cord. Diffedit: Diffusion-based seman- tic image editing with mask guidance.arXiv preprint arXiv:2210.11427, 2022. 3
-
[5]
Turboedit: Text-based image editing using few-step diffusion models
Gilad Deutch, Rinon Gal, Daniel Garibi, Or Patashnik, and Daniel Cohen-Or. Turboedit: Text-based image editing using few-step diffusion models. InSIGGRAPH Asia, 2024. 2, 7, 8
work page 2024
-
[6]
Prompt tuning inversion for text-driven image editing using diffusion models
Wenkai Dong, Song Xue, Xiaoyue Duan, and Shumin Han. Prompt tuning inversion for text-driven image editing using diffusion models. InICCV, 2023. 1
work page 2023
-
[7]
Alphaedit: Null-space constrained knowledge editing for language models
Junfeng Fang, Houcheng Jiang, Kun Wang, Yunshan Ma, Shi Jie, Xiang Wang, Xiangnan He, and Tat-Seng Chua. Al- phaedit: Null-space constrained knowledge editing for lan- guage models.arXiv preprint arXiv:2410.02355, 2024. 2
-
[8]
Renoise: Real image inversion through iterative noising
Daniel Garibi, Or Patashnik, Andrey V oynov, Hadar Averbuch-Elor, and Daniel Cohen-Or. Renoise: Real image inversion through iterative noising. InECCV, 2024. 7, 8
work page 2024
-
[9]
Common- canvas: Open diffusion models trained on creative-commons images
Aaron Gokaslan, A Feder Cooper, Jasmine Collins, Lan- dan Seguin, Austin Jacobson, Mihir Patel, Jonathan Fran- kle, Cory Stephenson, and V olodymyr Kuleshov. Common- canvas: Open diffusion models trained on creative-commons images. InCVPR, 2024. 7
work page 2024
-
[10]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt im- age editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022. 1, 3, 7, 8
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distill- ing the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015. 2
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[12]
Q. Huynh-Thu and M. Ghanbari. Scope of validity of psnr in image/video quality assessment.Electronics Letters, 2008. 7
work page 2008
-
[13]
Xuan Ju, Ailing Zeng, Yuxuan Bian, Shaoteng Liu, and Qiang Xu. Direct inversion: Boosting diffusion-based edit- ing with 3 lines of code.arXiv preprint arXiv:2310.01506,
-
[14]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Vladimir Kulikov, Matan Kleiner, Inbar Huberman- Spiegelglas, and Tomer Michaeli. Flowedit: Inversion-free text-based editing using pre-trained flow models.arXiv preprint arXiv:2412.08629, 2024. 2
-
[16]
Flux.https://github.com/ black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/ black-forest-labs/flux, 2024. 2
work page 2024
-
[17]
Jinhao Li, Jiaming Xu, Shan Huang, Yonghua Chen, Wen Li, Jun Liu, Yaoxiu Lian, Jiayi Pan, Li Ding, Hao Zhou, et al. Large language model inference acceleration: A comprehen- sive hardware perspective.arXiv preprint arXiv:2410.04466,
-
[18]
Jinhao Li, Jiaming Xu, Shiyao Li, Shan Huang, Jun Liu, Yaoxiu Lian, and Guohao Dai. Fast and efficient 2-bit llm inference on gpu: 2/4/16-bit in a weight matrix with asyn- chronous dequantization. InICCAD, 2024. 2
work page 2024
-
[19]
Xingyang Li*, Muyang Li*, Tianle Cai, Haocheng Xi, Shuo Yang, Yujun Lin, Lvmin Zhang, Songlin Yang, Jinbo Hu, Kelly Peng, Maneesh Agrawala, Ion Stoica, Kurt Keutzer, and Song Han. Radial attention:O(nlogn)sparse attention with energy decay for long video generation.arXiv preprint arXiv:2506.19852, 2025. 2
-
[20]
Dvd-quant: Data-free video diffusion transformers quantization.arXiv preprint arXiv:2505.18663, 2025
Zhiteng Li, Hanxuan Li, Junyi Wu, Kai Liu, Linghe Kong, Guihai Chen, Yulun Zhang, and Xiaokang Yang. Dvd-quant: Data-free video diffusion transformers quantization.arXiv preprint arXiv:2505.18663, 2025. 3
-
[21]
Arb-llm: Alternating refined binarizations for large language models
Zhiteng Li, Xianglong Yan, Tianao Zhang, Haotong Qin, Dong Xie, Jiang Tian, zhongchao shi, Linghe Kong, Yulun Zhang, and Xiaokang Yang. Arb-llm: Alternating refined binarizations for large language models. InICLR, 2025. 2
work page 2025
-
[23]
Jiacheng Liu, Chang Zou, Yuanhuiyi Lyu, Junjie Chen, and Linfeng Zhang. From reusing to forecasting: Accel- erating diffusion models with taylorseers.arXiv preprint arXiv:2503.06923, 2025
-
[24]
Deepcache: Accelerating diffusion models for free
Xinyin Ma, Gongfan Fang, and Xinchao Wang. Deepcache: Accelerating diffusion models for free. InCVPR, 2024. 3
work page 2024
-
[25]
Negative-prompt inversion: Fast image inversion for editing with text-guided diffusion models
Daiki Miyake, Akihiro Iohara, Yu Saito, and Toshiyuki Tanaka. Negative-prompt inversion: Fast image inversion for editing with text-guided diffusion models. InWACV, 2025. 2
work page 2025
-
[26]
Null-text inversion for editing real images using guided diffusion models
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real images using guided diffusion models. InCVPR, 2023. 7, 8
work page 2023
-
[27]
Null-text inversion for editing real images using guided diffusion models
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real images using guided diffusion models. InCVPR, 2023. 2
work page 2023
-
[28]
Swiftedit: Lightning fast text-guided image editing via one-step diffusion
Trong-Tung Nguyen, Quang Nguyen, Khoi Nguyen, Anh Tran, and Cuong Pham. Swiftedit: Lightning fast text-guided image editing via one-step diffusion. InCVPR, 2025. 2, 4, 7, 8
work page 2025
-
[29]
Jiayi Pan, Jiaming Xu, Yongkang Zhou, and Guohao Dai. Specdiff: Accelerating diffusion model inference with self- speculation.arxiv preprint 2509.13848, 2025. 2
-
[30]
Zero-shot image-to-image translation
Gaurav Parmar, Krishna Kumar Singh, Richard Zhang, Yijun Li, Jingwan Lu, and Jun-Yan Zhu. Zero-shot image-to-image translation. InSIGGRAPH, 2023. 7, 8
work page 2023
-
[31]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, 2023. 2 9
work page 2023
-
[32]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InICML, 2021. 7
work page 2021
-
[33]
High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution im- age synthesis with latent diffusion models.arXiv preprint arXiv:2112.10752, 2021. 2
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[34]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InCVPR, 2022. 2
work page 2022
-
[36]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[37]
Moma: Multimodal llm adapter for fast personalized image generation
Kunpeng Song, Yizhe Zhu, Bingchen Liu, Qing Yan, Ahmed Elgammal, and Xiao Yang. Moma: Multimodal llm adapter for fast personalized image generation. InECCV, 2024. 7
work page 2024
-
[38]
Journeydb: A benchmark for generative im- age understanding.NeurIPS, 2023
Keqiang Sun, Junting Pan, Yuying Ge, Hao Li, Haodong Duan, Xiaoshi Wu, Renrui Zhang, Aojun Zhou, Zipeng Qin, Yi Wang, et al. Journeydb: A benchmark for generative im- age understanding.NeurIPS, 2023. 7
work page 2023
-
[39]
Specprune-vla: Accelerating vision-language- action models via action-aware self-speculative pruning
Hanzhen Wang, Jiaming Xu, Jiayi Pan, Yongkang Zhou, and Guohao Dai. Specprune-vla: Accelerating vision-language- action models via action-aware self-speculative pruning. arxiv preprint 2509.05614, 2025. 2
-
[40]
OSDFace: One-step diffusion model for face restoration
Jingkai Wang, Jue Gong, Lin Zhang, Zheng Chen, Xing Liu, Hong Gu, Yutong Liu, Yulun Zhang, and Xiaokang Yang. OSDFace: One-step diffusion model for face restoration. In CVPR, 2025. 7
work page 2025
-
[41]
Image editing with diffusion models: A sur- vey.arXiv preprint arXiv:2504.13226, 2025
Jia Wang, Jie Hu, Xiaoqi Ma, Hanghang Ma, Xiaoming Wei, and Enhua Wu. Image editing with diffusion models: A sur- vey.arXiv preprint arXiv:2504.13226, 2025. 2
-
[42]
High-fidelity gan inversion for image attribute editing
Tengfei Wang, Yong Zhang, Yanbo Fan, Jue Wang, and Qifeng Chen. High-fidelity gan inversion for image attribute editing. InCVPR, 2022. 3
work page 2022
-
[43]
Zhou Wang, A.C. Bovik, H.R. Sheikh, and E.P. Simoncelli. Image quality assessment: from error visibility to structural similarity.TIP, 2004. 7
work page 2004
-
[44]
Junyi Wu, Zhiteng Li, Zheng Hui, Yulun Zhang, Linghe Kong, and Xiaokang Yang. Quantcache: Adaptive importance-guided quantization with hierarchical latent and layer caching for video generation. InICCV, 2025. 3
work page 2025
-
[45]
Specee: Accelerating large language model inference with specula- tive early exiting
Jiaming Xu, Jiayi Pan, Yongkang Zhou, Siming Chen, Jin- hao Li, Yaoxiu Lian, Junyi Wu, and Guohao Dai. Specee: Accelerating large language model inference with specula- tive early exiting. InISCA, 2025. 2
work page 2025
-
[46]
Yu Xu, Fan Tang, Juan Cao, Yuxin Zhang, Xiaoyu Kong, Jintao Li, Oliver Deussen, and Tong-Yee Lee. Head- router: A training-free image editing framework for mm- dits by adaptively routing attention heads.arXiv preprint arXiv:2411.15034, 2024. 2
-
[47]
Xianglong Yan, Zhiteng Li, Tianao Zhang, Linghe Kong, Yulun Zhang, and Xiaokang Yang. Recalkv: Low-rank kv cache compression via head reordering and offline calibra- tion.arXiv preprint arXiv:2505.24357, 2025. 2
-
[48]
Progressive binarization with semi-structured pruning for llms.arXiv preprint arXiv:2502.01705, 2025
Xianglong Yan, Tianao Zhang, Zhiteng Li, and Yulun Zhang. Progressive binarization with semi-structured pruning for llms.arXiv preprint arXiv:2502.01705, 2025. 2
-
[49]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip- adapter: Text compatible image prompt adapter for text-to- image diffusion models.arXiv preprint arxiv:2308.06721,
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
One-step diffusion with distribution matching distillation
Tianwei Yin, Micha ¨el Gharbi, Richard Zhang, Eli Shecht- man, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In CVPR, 2024. 4
work page 2024
-
[51]
Plug-and-play image restora- tion with deep denoiser prior.TPAMI, 2021
Kai Zhang, Yawei Li, Wangmeng Zuo, Lei Zhang, Luc Van Gool, and Radu Timofte. Plug-and-play image restora- tion with deep denoiser prior.TPAMI, 2021. 3, 7, 8
work page 2021
-
[52]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In ICCV, 2023. 7
work page 2023
-
[53]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, 2018. 7
work page 2018
-
[54]
In- domain gan inversion for real image editing
Jiapeng Zhu, Yujun Shen, Deli Zhao, and Bolei Zhou. In- domain gan inversion for real image editing. InECCV, 2020. 3
work page 2020
-
[55]
Generative visual manipulation on the natu- ral image manifold
Jun-Yan Zhu, Philipp Kr ¨ahenb¨uhl, Eli Shechtman, and Alexei A Efros. Generative visual manipulation on the natu- ral image manifold. InECCV, 2016. 3 10
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.