GeoCFNet: Geometry-Aware Confidence Field Network for Robot-Assisted Endoscopic Submucosal Dissection
Pith reviewed 2026-06-27 07:39 UTC · model grok-4.3
The pith
GeoCFNet estimates geometrically stable confidence fields for guiding robot-assisted endoscopic submucosal dissection using a DINOv3 backbone with specialized fusion and regularization modules.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
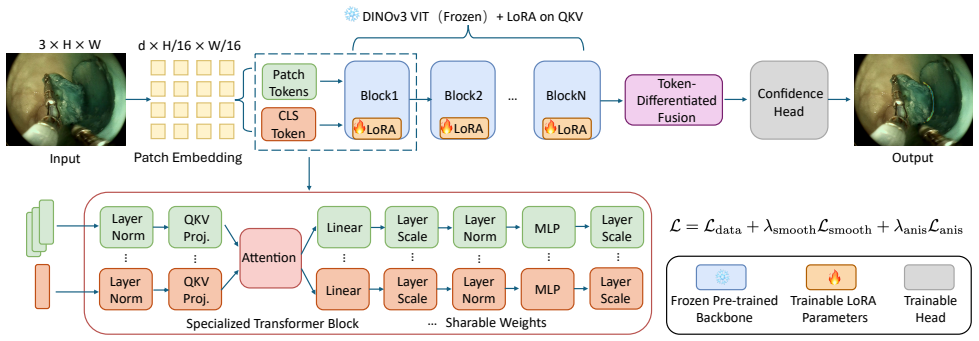
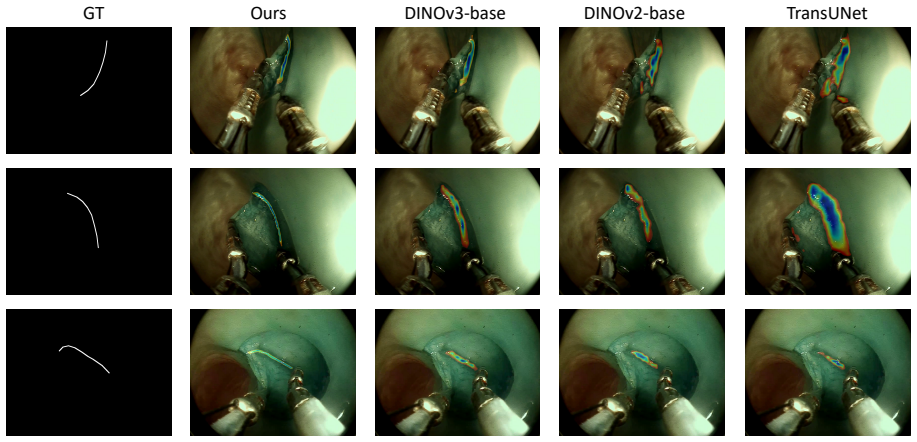
We formulate dissection guidance as a geometry-aware confidence field estimation problem and propose GeoCFNet, a geometry-aware confidence field network built on a pretrained DINOv3 backbone. GeoCFNet integrates a Token-Differentiated Fusion module to aggregate class-token context with dense patch representations, a SegFormer decoder for confidence regression, and Geometry-Aware Spatial Regularization (GASR) to preserve spatial coherence and local geometric transitions. Experimental results show that GeoCFNet achieves RMSE 0.0480, PSNR 27.1995, SSIM 0.3397, and CC 0.2466, indicating accurate and geometrically stable confidence field estimation for robot-assisted ESD guidance.
What carries the argument
Geometry-Aware Spatial Regularization (GASR) applied during confidence regression to enforce spatial coherence and preserve local geometric transitions in the output field.
If this is right
- Stable confidence fields enable maintenance of an accurate dissection corridor during en-bloc lesion resection.
- The fields support definition of safe tissue margins that reduce risk of complications.
- Geometry-aware regularization improves handling of dynamic scenes that include smoke and specular highlights.
- The approach supplies a continuous spatial representation usable for real-time visual guidance.
Where Pith is reading between the lines
- The same backbone-plus-regularization pattern could be tested on other endoscopic tasks that require boundary-aware guidance.
- Pairing the output fields with robotic trajectory planners might allow automatic correction of dissection paths when confidence drops.
- Performance on thin structures suggests the regularization could help in procedures involving vessels or nerves near the target.
Load-bearing premise
The Token-Differentiated Fusion module, SegFormer decoder, and Geometry-Aware Spatial Regularization on a DINOv3 backbone will reliably preserve spatial coherence and local geometric transitions despite smoke, specular highlights, tissue deformation, weak texture, and thin structures.
What would settle it
Evaluating the network on a new set of endoscopic sequences that contain heavier smoke or more rapid tissue deformation and checking whether the RMSE remains near or below 0.0480.
Figures

read the original abstract
Advanced surgical robotics has made robot-assisted endoscopic submucosal dissection (ESD) a promising approach for the en-bloc resection of large lesions, with the potential to reduce recurrence and improve long-term outcomes. However, the technical complexity and risk of complications in ESD demand stable and precise visual guidance to maintain an accurate dissection corridor and a safe tissue margin. Dense confidence fields provide an effective representation for this purpose by describing both the preferred dissection region and its spatial transition to surrounding tissue. However, reliable confidence field estimation remains challenging in dynamic endoscopic scenes due to smoke, specular highlights, tissue deformation, weak texture, and the thin geometric structure of the target region. To address these challenges, we formulate dissection guidance as a geometry-aware confidence field estimation problem and propose GeoCFNet, a geometry-aware confidence field network built on a pretrained DINOv3 backbone. GeoCFNet integrates a Token-Differentiated Fusion module to aggregate class-token context with dense patch representations, a SegFormer decoder for confidence regression, and Geometry-Aware Spatial Regularization (GASR) to preserve spatial coherence and local geometric transitions. Experimental results show that GeoCFNet achieves RMSE 0.0480, PSNR 27.1995, SSIM 0.3397, and CC 0.2466, indicating accurate and geometrically stable confidence field estimation for robot-assisted ESD guidance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GeoCFNet, a geometry-aware confidence field network for robot-assisted endoscopic submucosal dissection (ESD). Built on a pretrained DINOv3 backbone, it incorporates a Token-Differentiated Fusion module, a SegFormer decoder, and Geometry-Aware Spatial Regularization (GASR) to estimate dense confidence fields that guide dissection while handling challenges like smoke, specular highlights, tissue deformation, weak texture, and thin structures. The central claim is that the method achieves accurate and geometrically stable estimation, demonstrated by reported metrics of RMSE 0.0480, PSNR 27.1995, SSIM 0.3397, and CC 0.2466.
Significance. If substantiated, the approach could advance visual guidance systems in surgical robotics by supplying spatially coherent confidence maps that help maintain safe dissection corridors under challenging endoscopic conditions. The geometry-aware regularization component offers a targeted mechanism for preserving local transitions, which may generalize to other medical imaging domains involving deformable tissues and adverse lighting. The reliance on a pretrained foundation model backbone is a constructive choice for feature extraction in data-scarce surgical settings.
major comments (1)
- [Abstract] Abstract (experimental results paragraph): The claim that RMSE 0.0480, PSNR 27.1995, SSIM 0.3397, and CC 0.2466 demonstrate 'accurate and geometrically stable' estimation is not supported by the data; SSIM of 0.3397 indicates weak structural fidelity and CC of 0.2466 indicates only marginal correlation, directly conflicting with assertions of spatial coherence and geometric stability in the presence of smoke, specular highlights, deformation, weak texture, and thin structures. No baselines, ablations, or error maps are referenced to contextualize these values.
minor comments (1)
- The abstract provides no information on the dataset (size, source, annotation protocol), training details, or comparison methods, which are required to evaluate whether the reported metrics are meaningful.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below and will revise the manuscript to align claims with the reported metrics.
read point-by-point responses
-
Referee: [Abstract] Abstract (experimental results paragraph): The claim that RMSE 0.0480, PSNR 27.1995, SSIM 0.3397, and CC 0.2466 demonstrate 'accurate and geometrically stable' estimation is not supported by the data; SSIM of 0.3397 indicates weak structural fidelity and CC of 0.2466 indicates only marginal correlation, directly conflicting with assertions of spatial coherence and geometric stability in the presence of smoke, specular highlights, deformation, weak texture, and thin structures. No baselines, ablations, or error maps are referenced to contextualize these values.
Authors: We agree that the abstract's phrasing overstates the results. The modest SSIM (0.3397) and CC (0.2466) values do not robustly support claims of 'accurate and geometrically stable' estimation or strong spatial coherence under the listed challenges. We will revise the abstract to report the metrics factually and remove the interpretive claim. The full manuscript contains baseline comparisons and ablation studies (Experiments section) that contextualize the numbers; we will add a brief reference to these in the abstract if length allows. Error visualization can be included in the revision. revision: yes
Circularity Check
No circularity: empirical architecture with reported metrics only
full rationale
The paper describes a neural network architecture (DINOv3 backbone + Token-Differentiated Fusion + SegFormer decoder + GASR) and reports empirical performance metrics (RMSE, PSNR, SSIM, CC) on endoscopic data. No derivation chain, equations, parameter fitting presented as predictions, or self-citation load-bearing steps appear in the provided text. The central claim rests on experimental results rather than any reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ai-endo: a computer-aided endoscopic surgery system with intelligent surgical workflow recognition for robotic submucosal dissection,
S. Cao, G. Wang, N. Zhong, H. Renet al., “Ai-endo: a computer-aided endoscopic surgery system with intelligent surgical workflow recognition for robotic submucosal dissection,”Nature Communications, vol. 14, no. 1, p. 7722, 2023
2023
-
[2]
Robotic-assisted vs non-robotic traction techniques in endoscopic submucosal dissection for malignant gastrointestinal lesions: a systematic review and meta-analysis,
F. Meng, M. Li, M. Caiet al., “Robotic-assisted vs non-robotic traction techniques in endoscopic submucosal dissection for malignant gastrointestinal lesions: a systematic review and meta-analysis,”Surgical Endoscopy, vol. 36, no. 12, pp. 9201–9214, 2022
2022
-
[3]
Geo-repnet: Geometry-aware representation learning for surgical phase recognition in endoscopic submucosal dissection,
R. Tang, H. Yin, G. Wang, L. Bai, A. Wang, H. Gao, J. Wang, and H. Ren, “Geo-repnet: Geometry-aware representation learning for surgical phase recognition in endoscopic submucosal dissection,” in 2025 International Conference on Information and Automation (ICIA). IEEE, 2025, pp. 359–364
2025
-
[4]
Endoarss: Adapting spatially aware foundation model for efficient activity recog- nition and semantic segmentation in endoscopic surgery,
G. Wang, R. Tang, M. Xu, L. Bai, H. Gao, and H. Ren, “Endoarss: Adapting spatially aware foundation model for efficient activity recog- nition and semantic segmentation in endoscopic surgery,”Advanced Intelligent Systems, vol. 7, no. 12, p. e202500288, 2025
2025
-
[5]
Copesd: A multi-level surgical motion dataset for training large vision-language models to co-pilot endoscopic submucosal dissection,
G. Wang, H. Xiao, R. Zhang, H. Gao, L. Bai, X. Yang, Z. Li, H. Li, and H. Ren, “Copesd: A multi-level surgical motion dataset for training large vision-language models to co-pilot endoscopic submucosal dissection,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 12 636–12 643
2025
-
[6]
Endoscopic mucosal resection and endo- scopic submucosal dissection,
S. Yilmaz and E. Gorgun, “Endoscopic mucosal resection and endo- scopic submucosal dissection,”Clinics in Colon and Rectal Surgery, vol. 37, no. 5, pp. 277–288, 2023
2023
-
[7]
Efficacy of robot arm-assisted endoscopic submucosal dissection in live porcine stomach,
J. Kimet al., “Efficacy of robot arm-assisted endoscopic submucosal dissection in live porcine stomach,”Scientific Reports, vol. 14, p. 17367, 2024
2024
-
[8]
Video-based surgical skills assessment using long term tool tracking,
M. Fathollahi, M. H. Sarhan, R. Pena, L. DiMonte, A. Gupta, A. Atali- wala, and J. Barker, “Video-based surgical skills assessment using long term tool tracking,” inInternational Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2022, pp. 541–550
2022
-
[9]
Imitation learning from expert video data for dissection trajectory prediction in endoscopic surgical procedure,
J. Li, Y . Jin, Y . Chen, H.-C. Yip, M. Scheppach, P. W.-Y . Chiu, Y . Yam, H. M.-L. Meng, and Q. Dou, “Imitation learning from expert video data for dissection trajectory prediction in endoscopic surgical procedure,” in International Conference on Medical Image Computing and Computer- Assisted Intervention. Springer, 2023, pp. 494–504
2023
-
[10]
Ds-transunet: Dual swin transformer u-net for medical image segmentation,
A. Lin, B. Chen, J. Xu, Z. Zhang, G. Lu, and D. Zhang, “Ds-transunet: Dual swin transformer u-net for medical image segmentation,”IEEE Transactions on Instrumentation and Measurement, vol. 71, pp. 1–15, 2022
2022
-
[11]
Etsm: Automating dissection trajectory suggestion and confidence map-based safety margin prediction for robot-assisted endoscopic submucosal dissection,
M. Xu, W. Mo, G. Wang, H. Gao, A. Wang, L. Bai, C. Lyu, X. Yang, Z. Li, and H. Ren, “Etsm: Automating dissection trajectory suggestion and confidence map-based safety margin prediction for robot-assisted endoscopic submucosal dissection,” in2025 IEEE International Confer- ence on Robotics and Automation (ICRA). IEEE, 2025, pp. 4513–4519
2025
-
[12]
Dense depth estimation in monocular endoscopy with self-supervised learning methods,
X. Liu, A. Sinha, M. Ishii, G. D. Hager, A. Reiter, R. H. Taylor, and M. Unberath, “Dense depth estimation in monocular endoscopy with self-supervised learning methods,”IEEE transactions on medical imaging, vol. 39, no. 5, pp. 1438–1447, 2019
2019
-
[13]
Surgical-dino: adapter learning of foundation models for depth estimation in endoscopic surgery,
B. Cui, M. Islam, L. Bai, and H. Ren, “Surgical-dino: adapter learning of foundation models for depth estimation in endoscopic surgery,” International Journal of Computer Assisted Radiology and Surgery, vol. 19, no. 6, pp. 1013–1020, 2024
2024
-
[14]
Endodac: Efficient adapting foundation model for self-supervised depth estimation from any endoscopic camera,
B. Cui, M. Islam, L. Bai, A. Wang, and H. Ren, “Endodac: Efficient adapting foundation model for self-supervised depth estimation from any endoscopic camera,” inInternational Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2024, pp. 208–218
2024
-
[15]
Pdzseg: adapting the foundation model for dissection zone segmentation with visual prompts in robot-assisted endoscopic submucosal dissection,
M. Xu, W. Mo, G. Wang, H. Gao, A. Wang, N. Zhong, Z. Li, X. Yang, and H. Ren, “Pdzseg: adapting the foundation model for dissection zone segmentation with visual prompts in robot-assisted endoscopic submucosal dissection,”International Journal of Computer Assisted Radiology and Surgery, vol. 20, pp. 2335–2344, 2025
2025
-
[16]
Modeling and segmentation of sur- gical workflow from laparoscopic video,
T. Blum, H. Feußner, and N. Navab, “Modeling and segmentation of sur- gical workflow from laparoscopic video,” inMedical Image Computing and Computer-Assisted Intervention–MICCAI 2010: 13th International Conference, Beijing, China, September 20-24, 2010, Proceedings, Part III 13. Springer, 2010, pp. 400–407
2010
-
[17]
Statistical modeling and recognition of surgical workflow,
N. Padoy, T. Blum, S.-A. Ahmadi, H. Feussner, M.-O. Berger, and N. Navab, “Statistical modeling and recognition of surgical workflow,” Medical image analysis, vol. 16, no. 3, pp. 632–641, 2012
2012
-
[18]
Endonet: a deep architecture for recognition tasks on laparoscopic videos,
A. P. Twinanda, S. Shehata, D. Mutter, J. Marescaux, M. De Mathelin, and N. Padoy, “Endonet: a deep architecture for recognition tasks on laparoscopic videos,”IEEE transactions on medical imaging, vol. 36, no. 1, pp. 86–97, 2016
2016
-
[19]
Sv-rcnet: workflow recognition from surgical videos using recurrent convolutional network,
Y . Jin, Q. Dou, H. Chen, L. Yu, J. Qin, C.-W. Fu, and P.-A. Heng, “Sv-rcnet: workflow recognition from surgical videos using recurrent convolutional network,”IEEE transactions on medical imaging, vol. 37, no. 5, pp. 1114–1126, 2017
2017
-
[20]
Tecno: Surgical phase recognition with multi- stage temporal convolutional networks,
T. Czempiel, M. Paschali, M. Keicher, W. Simson, H. Feussner, S. T. Kim, and N. Navab, “Tecno: Surgical phase recognition with multi- stage temporal convolutional networks,” inMedical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, October 4–8, 2020, Proceedings, Part III 23. Springer, 2020, pp. 343–352
2020
-
[21]
Trans-svnet: Accurate phase recognition from surgical videos via hybrid embedding aggregation transformer,
X. Gao, Y . Jin, Y . Long, Q. Dou, and P.-A. Heng, “Trans-svnet: Accurate phase recognition from surgical videos via hybrid embedding aggregation transformer,” inMedical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, September 27–October 1, 2021, Proceedings, Part IV 24. Springer, 2021, p...
2021
-
[22]
U-net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” inMedical Image Computing and Computer-Assisted Intervention (MICCAI). Springer, 2015, pp. 234– 241
2015
-
[23]
Transunet: Rethinking the u-net architecture design for medical image segmentation through the lens of transformers,
J. Chen, J. Mei, X. Li, Y . Lu, Q. Yu, Q. Wei, X. Luo, Y . Xie, E. Adeli, Y . Wanget al., “Transunet: Rethinking the u-net architecture design for medical image segmentation through the lens of transformers,”Medical Image Analysis, vol. 97, p. 103280, 2024
2024
-
[24]
Dinov2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V . V o, M. Szafraniec, V . Khali- dov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski, “Dinov2: Learning robust visual features withou...
Pith/arXiv arXiv 2023
-
[25]
O. Sim ´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, F. Massa, D. Haz- iza, T. Moutakanni, R. Howes, R. Hallade, A. El-Nouby, M. Assran, M. Caron, P. Bojanowski, G. Synnaeve, M. Rabbat, P. Labatut, and A. Joulin, “Dinov3,”arXiv preprint arXiv:2508.10104, 2025
Pith/arXiv arXiv 2025
-
[26]
Revisiting [CLS] and patch token interaction in vision transformers,
A. Marouani, O. Sim ´eoni, H. J ´egou, P. Bojanowski, and H. V . V o, “Revisiting [CLS] and patch token interaction in vision transformers,” arXiv preprint arXiv:2602.08626, 2026
arXiv 2026
-
[27]
An efficient anisotropic diffusion model for image denoising with edge preservation,
B. Gupta, S. S. Lambaet al., “An efficient anisotropic diffusion model for image denoising with edge preservation,”Computers & Mathematics with Applications, vol. 93, pp. 106–119, 2021
2021
-
[28]
Segformer: Simple and efficient design for semantic segmentation with transformers,
E. Xie, W. Wang, Z. Yu, A. Anandkumar, J. M. Alvarez, and P. Luo, “Segformer: Simple and efficient design for semantic segmentation with transformers,”Advances in Neural Information Processing Systems, vol. 34, pp. 12 077–12 090, 2021
2021
-
[29]
Root mean square error (RMSE) or mean absolute error (MAE)? – arguments against avoiding RMSE in the literature,
T. Chai and R. R. Draxler, “Root mean square error (RMSE) or mean absolute error (MAE)? – arguments against avoiding RMSE in the literature,”Geoscientific Model Development, vol. 7, no. 3, pp. 1247– 1250, 2014
2014
-
[30]
Scope of validity of psnr in im- age/video quality assessment,
Q. Huynh-Thu and M. Ghanbari, “Scope of validity of psnr in im- age/video quality assessment,”Electronics Letters, vol. 44, no. 13, pp. 800–801, 2008
2008
-
[31]
Image quality assessment: From error visibility to structural similarity,
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: From error visibility to structural similarity,”IEEE Transactions on Image Processing, vol. 13, no. 4, pp. 600–612, 2004
2004
-
[32]
Note on regression and inheritance in the case of two parents,
K. Pearson, “Note on regression and inheritance in the case of two parents,”Proceedings of the Royal Society of London, vol. 58, pp. 240– 242, 1895
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.