Speech-Driven End-to-End Language Discrimination towards Chinese Dialects
Pith reviewed 2026-06-26 21:22 UTC · model grok-4.3
The pith
Speech-driven MFCC features with attention and CNN fusion outperform text methods for Chinese dialect discrimination.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
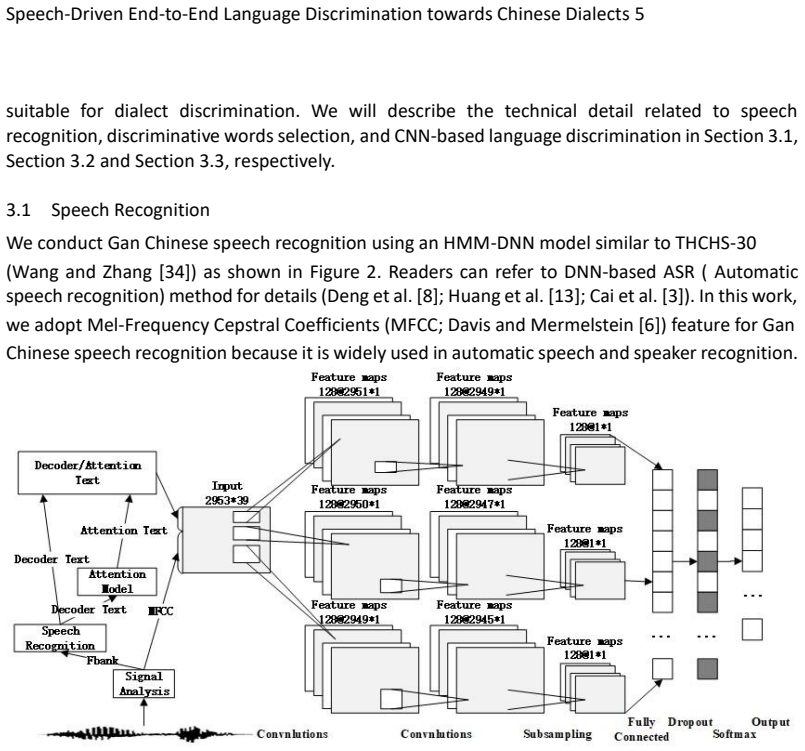
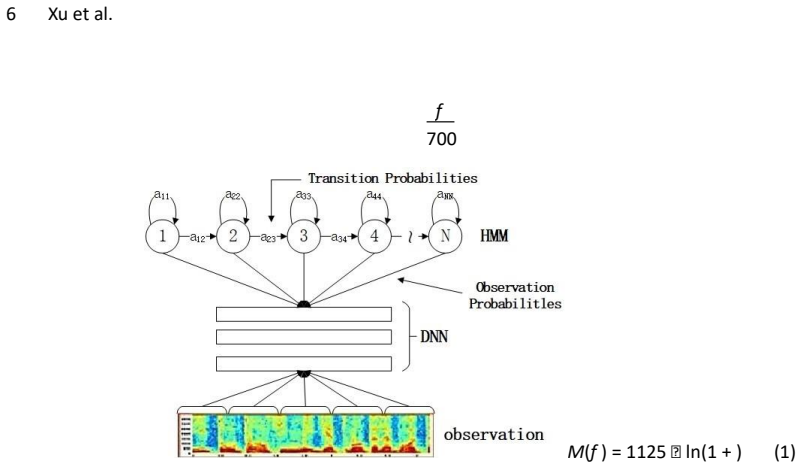
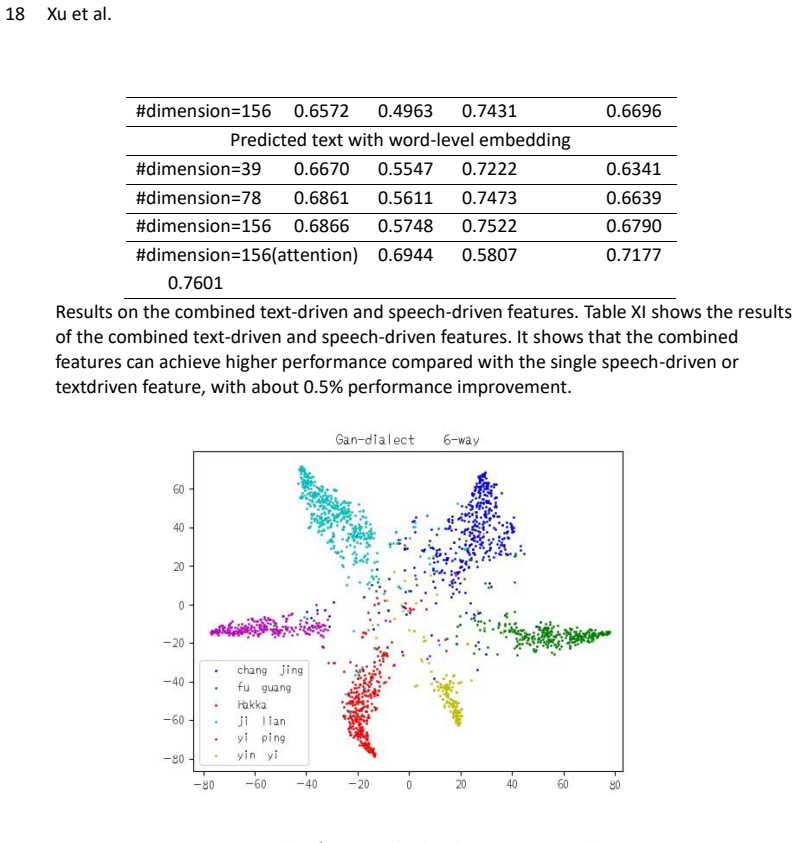
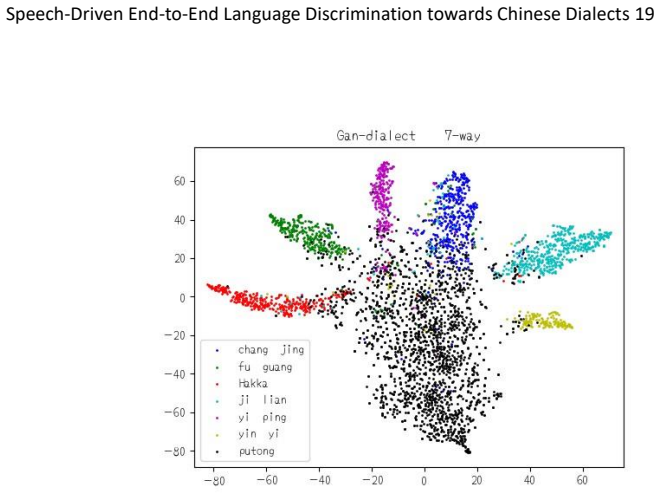
The speech-driven pipeline that extracts MFCC features, predicts words via an HMM-DNN model, selects discriminative words with attention, and fuses the resulting embeddings with the MFCC features inside a CNN is appropriate and effective for fine-grained Chinese dialect discrimination, delivering higher accuracy on two benchmark corpora than existing methods.
What carries the argument
CNN fusion of MFCC speech features with attention-weighted word embeddings produced by an HMM-DNN speech recognizer.
If this is right
- Attention identifies words that are especially useful for separating one Chinese dialect from another.
- MFCC features are shown to be suitable inputs for CNN-based dialect discrimination.
- The end-to-end speech-driven approach exceeds the performance of state-of-the-art methods on the evaluated corpora.
- The same pipeline can be used for discrimination among other groups of closely related language varieties.
Where Pith is reading between the lines
- Voice-based systems such as assistants or transcription tools could become more accurate in dialect-heavy regions if they adopt similar fusion techniques.
- The method may help language identification tasks where code-switching or low-resource dialects make text alone unreliable.
- Testing the same architecture on dialect pairs from other language families would show whether the speech-driven advantage is specific to Chinese or more general.
Load-bearing premise
MFCC speech features combined with HMM-DNN word prediction and attention will reliably pick up dialect distinctions that text-driven methods miss.
What would settle it
On the two benchmark Chinese dialect corpora, the proposed model achieves lower or equal accuracy compared with the strongest existing text-based or other language discrimination systems.
Figures

read the original abstract
Language discrimination among similar languages, varieties, and dialects is a challenging natural language processing task. The traditional text-driven focus leads to poor results. In this paper, we explore the effectiveness of speech-driven features towards language discrimination among Chinese dialects. First, we systematically explore the appropriateness of speech-driven MFCC features towards CNN-based language discrimination. Then, we design an end-to-end speech recognition model based on HMM-DNN to predict Chinese dialect words. We adopt attention to extract the discriminative words related to different Chinese dialects. Finally, through a CNN, we combine the word-level embedding and the MFCC-based features. Evaluation of two benchmark Chinese dialect corpora shows the appropriateness and effectiveness of the proposed speech-driven approach to fine-grained Chinese dialect discrimination compared to the state-of-the-art methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a speech-driven end-to-end approach for fine-grained discrimination among Chinese dialects. It first examines MFCC features for CNN-based discrimination, then builds an HMM-DNN speech recognition model to predict dialect words, applies attention to identify discriminative words, and finally fuses word embeddings with MFCC features inside a CNN. The central claim is that this method is appropriate and effective on two benchmark Chinese dialect corpora relative to state-of-the-art methods.
Significance. If the experimental results were to substantiate the claims, the work would offer a concrete alternative to text-only methods for dialectal language identification, addressing cases where orthographic similarity masks acoustic distinctions. The combination of acoustic features, word-level prediction, and attention could be reusable for other low-resource or closely related language varieties. However, the absence of any quantitative results, baselines, ablation studies, or error analysis in the supplied manuscript prevents any assessment of whether these potential benefits are realized.
major comments (2)
- [Abstract] Abstract: The manuscript asserts that 'Evaluation of two benchmark Chinese dialect corpora shows the appropriateness and effectiveness of the proposed speech-driven approach... compared to the state-of-the-art methods,' yet supplies no metrics, baselines, error analysis, or experimental details. This omission is load-bearing because the evaluation is the sole evidence offered for the central claim.
- [Abstract] Abstract / method description: No equations, feature-extraction steps, model architectures, or training procedures are provided for the HMM-DNN word predictor, the attention mechanism, or the final CNN fusion. Without these, it is impossible to verify whether the claimed speech-driven advantage over text-driven baselines is internally consistent or merely asserted.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract and method descriptions. We agree that the current version lacks sufficient quantitative support and technical specifics to fully substantiate the claims, and we will revise the manuscript to address this.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript asserts that 'Evaluation of two benchmark Chinese dialect corpora shows the appropriateness and effectiveness of the proposed speech-driven approach... compared to the state-of-the-art methods,' yet supplies no metrics, baselines, error analysis, or experimental details. This omission is load-bearing because the evaluation is the sole evidence offered for the central claim.
Authors: We acknowledge that the abstract makes a strong claim without including supporting metrics or details. In the revised manuscript, we will update the abstract to report key quantitative results (e.g., accuracy on the two corpora and gains over text-only baselines) and will ensure the main text includes full experimental details, baselines, and error analysis so the evaluation evidence is explicit. revision: yes
-
Referee: [Abstract] Abstract / method description: No equations, feature-extraction steps, model architectures, or training procedures are provided for the HMM-DNN word predictor, the attention mechanism, or the final CNN fusion. Without these, it is impossible to verify whether the claimed speech-driven advantage over text-driven baselines is internally consistent or merely asserted.
Authors: We agree that the method description is insufficiently detailed. The revision will add the missing equations for the HMM-DNN, explicit MFCC extraction steps, the attention formulation, the CNN fusion architecture, and training hyperparameters/procedures. This will make the speech-driven pipeline reproducible and allow direct comparison to text-driven baselines. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents a methodological pipeline (MFCC feature exploration for CNN, HMM-DNN word prediction with attention, and final CNN fusion) evaluated on external benchmark corpora. No equations, parameter-fitting steps, self-citations, or derivations are described that reduce any claimed result to its own inputs by construction. The central claim of effectiveness rests on comparative evaluation against state-of-the-art methods rather than internal redefinition or fitted renaming.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Necip Fazil Ayan and Bonnie J Dorr . 2006. Going beyond AER: An extensive analysis of word alignments and their impact on MT. In Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics. 9–16
2006
-
[2]
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2014. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473 (2014)
Pith/arXiv arXiv 2014
-
[3]
Chenghao Cai, Yanyan Xu, Dengfeng Ke, and Kaile Su. 2015. A fast learning method for multilayer perceptrons in automatic speech recognition systems. Journal of Robotics 2015 (2015)
2015
-
[4]
Nancy F Chen, Darren Wee, Rong Tong, Bin Ma, and Haizhou Li. 2016. Large-scale characterization of non-native Mandarin Chinese spoken by speakers of European origin: Analysis on iCALL. Speech Communication 84 (2016) , 46– 56
2016
-
[5]
Çağrı Çöltekin and Taraka Rama. 2016. Discriminating similar languages with linear SVMs and neural networks. In Proceedings of the Third Workshop on NLP for Similar Languages, Varieties and Dialects (VarDial3). 15–24
2016
-
[6]
Steven B Davis and Paul Mermelstein. 1990. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. In Readings in speech recognition. Elsevier, 65–74
1990
-
[7]
Najim Dehak, Pedro A Torres-Carrasquillo, Douglas Reynolds, and Reda Dehak. 2011. Language recognition via i- vectors and dimensionality reduction. In Twelfth annual conference of the international speech communication association. 26 Xu et al
2011
-
[8]
Ltsc Deng, Jinyu Li, Jui-Ting Huang, Kaisheng Yao, Dong Yu, Frank Seide, Michael L Seltzer, Geoffrey Zweig, Xiaodong He, Jason D Williams, et al. 2013. Recent advances in deep learning for speech research at Microsoft.. In ICASSP, Vol
2013
-
[9]
Heba Elfardy and Mona Diab. 2013. Sentence level dialect identification in Arabic. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Vol. 2. 456–461
2013
-
[10]
Helena Gomez, Ilia Markov, Jorge Baptista, Grigori Sidorov, and David Pinto. 2017. Discriminating between similar languages using a combination of typed and untyped character n-grams and words. In Proceedings of the Fourth Workshop on NLP for Similar Languages, Varieties and Dialects (VarDial). 137–145
2017
-
[11]
Cyril Goutte, Serge Léger, and Marine Carpuat. 2014. The NRC system for discriminating similar languages. In Proceedings of the first workshop on applying NLP tools to similar languages, varieties and dialects. 139–145
2014
-
[12]
Gregory Grefenstette. 1995. COMPARING TWO LANGUAGE IDENTIFICATION SCHEM ES. In Proceedings of JADT, Vol. 95
1995
-
[13]
Xuedong Huang, James Baker, and Raj Reddy. 2014. A historical perspective of speech recognition. Commun. ACM 57 , 1 (2014), 94–103
2014
-
[14]
IFLYTEK. 2018. IFLYTEK world-wide contest for dialect discrimination:a baseline system. Website. http://challenge. xfyun.cn/aicompetition/mobile/techDetail
2018
-
[15]
Armand Joulin, Edouard Grave, Piotr Bojanowski, and Tomas Mikolov. 2016. Bag of tricks for efficient text classification. arXiv preprint arXiv:1607.01759 (2016)
Pith/arXiv arXiv 2016
-
[16]
Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
Pith/arXiv arXiv 2014
-
[17]
Dietrich Klakow and Jochen Peters. 2002. Testing the correlation of word error rate and perplexity. Speech Communication 38, 1-2 (2002), 19–28
2002
-
[18]
Nikola Ljubešić and Denis Kranjčić. 2015. Discriminating between closely related languages on twitter . Informatica 39 , 1 (2015)
2015
-
[19]
Marco Lui and Paul Cook. 2013. Classifying English documents by national dialect. In Proceedings of the Australasian Language Technology Association Workshop 2013 (ALTA 2013). 5–15
2013
-
[20]
Wolfgang Maier and Carlos Gómez-Rodríguez. 2014. Language variety identification in Spanish tweets. In Proceedings of the EMNLP’2014 Workshop on Language Technology for Closely Related Languages and Language Variants. 25–35
2014
-
[21]
Shervin Malmasi, Mark Dras, et al. 2015. Automatic language identification for Persian and Dari texts. In Proceedings of PACLING. 59–64
2015
-
[22]
Shervin Malmasi, Marcos Zampieri, Nikola Ljubešić, Preslav Nakov, Ahmed Ali, and Jörg Tiedemann. 2016. Discriminating between similar languages and arabic dialect identification: A report on the third dsl shared task. In Proceedings of the Third Workshop on NLP for Similar Languages, Varieties and Dialects (VarDial3). 1–14
2016
-
[23]
Rada Mihalcea and Ted Pedersen. 2003. An evaluation exercise for word alignment. In Proceedings of the HLT-NAACL 2003 Workshop on Building and using parallel texts: data driven machine translation and beyond-Volume 3. Association for Computational Linguistics, 1–10
2003
-
[24]
Kavi Narayana Murthy and G Bharadwaja Kumar . 2006. Language identification from small text samples. Journal of Quantitative Linguistics 13, 01 (2006), 57–80
2006
-
[25]
Bali Ranaivo-Malançon. 2006. Automatic identification of close languages-case study: Malay and Indonesian. ECTI Transactions on Computer and Information Technology (ECTI-CIT) 2, 2 (2006), 126–134
2006
-
[26]
Wael Salloum, Heba Elfardy, Linda Alamir-Salloum, Nizar Habash, and Mona Diab. 2014. Sentence level dialect identification for machine translation system selection. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Vol. 2. 772–778
2014
-
[27]
Alberto Simões, José João Almeida, and Simon D Byers. 2014. Language identification: a neural network approach. In 3rd Symposium on Languages, Applications and Technologies. Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik
2014
-
[28]
David Snyder, Daniel Garcia-Romero, Alan McCree, Gregory Sell, Daniel Povey, and Sanjeev Khudanpur . 2018. Spoken Language Recognition using X-vectors.. In Odyssey. 105–111
2018
-
[29]
Andreas Stolcke. 2002. SRILM-an extensible language modeling toolkit. In Seventh international conference on spoken language processing
2002
-
[30]
Toshiyuki Takezawa, Eiichiro Sumita, Fumiaki Sugaya, Hirofumi Yamamoto, and Seiichi Yamamoto. 2002. Toward a Broad-coverage Bilingual Corpus for Speech Translation of Travel Conversations in the Real World.. In LREC. 147–152. Speech-Driven End-to-End Language Discrimination towards Chinese Dialects 27
2002
-
[31]
Jörg Tiedemann and Nikola Ljubešić. 2012. Efficient discrimination between closely related languages. In Proceedings of COLING 2012. 2619–2634
2012
-
[32]
Christoph Tillmann, Saab Mansour, and Yaser Al-Onaizan. 2014. Improved sentence-level Arabic dialect classification. In Proceedings of the First Workshop on Applying NLP Tools to Similar Languages, Varieties and Dialects. 110–119
2014
-
[33]
Dong Wang, Lantian Li, Difei Tang, and Qing Chen. 2016. Ap16-ol7: A multilingual database for oriental languages and a language recognition baseline. In 2016 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA). IEEE, 1 – 5
2016
-
[34]
Dong Wang and Xuewei Zhang. 2015. Thchs-30: A free chinese speech corpus. arXiv preprint arXiv:1512.01882 (2015)
Pith/arXiv arXiv 2015
-
[35]
Fan Xu, Mingwen Wang, and Maoxi Li. 2018. Building Parallel Monolingual Gan Chinese Dialects Corpus.. In LREC. 244–249
2018
-
[36]
Fan Xu, Xiongfei Xu, Mingwen Wang, and Maoxi Li. 2015. Building Monolingual Word Alignment Corpus for the Greater China Region. In Proceedings of the Joint Workshop on Language Technology for Closely Related Languages, Varieties and Dialects. 85–94
2015
-
[37]
Omar F Zaidan and Chris Callison-Burch. 2014. Arabic dialect identification. Computational Linguistics 40, 1 (2014) , 171–202
2014
-
[38]
Marcos Zampieri and Binyam Gebrekidan Gebre. 2012. Automatic identification of language varieties: The case of Portuguese. In KONVENS2012-The 11th Conference on Natural Language Processing. Österreichischen Gesellschaft für Artificial Intelligende (ÖGAI), 233–237
2012
-
[39]
Marcos Zampieri, Shervin Malmasi, Nikola Ljubešić, Preslav Nakov, Ahmed Ali, Jörg Tiedemann, Yves Scherrer, and Noëmi Aepli. 2017. Findings of the VarDial evaluation campaign 2017. (2017)
2017
-
[40]
Marcos Zampieri, Liling Tan, Nikola Ljubešić, and Jörg Tiedemann. 2014. A report on the DSL shared task 2014. In Proceedings of the first workshop on applying NLP tools to similar languages, varieties and dialects. 58–67
2014
-
[41]
Marcos Zampieri, Liling Tan, Nikola Ljubešić, Jörg Tiedemann, and Preslav Nakov. 2015. Overview of the dsl shared task 2015. In Proceedings of the Joint Workshop on Language Technology for Closely Related Languages, Varieties and Dialects. 1 – 9
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.