Still: Amortized KV Cache Compaction in a Single Forward Pass
Pith reviewed 2026-06-27 22:19 UTC · model grok-4.3
The pith
A single Perceiver trained once produces compact KV caches in one forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
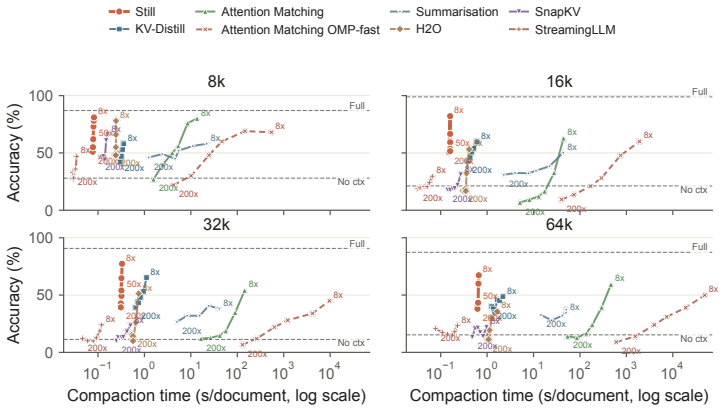
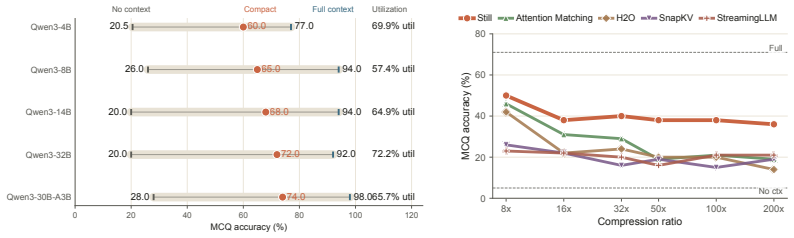
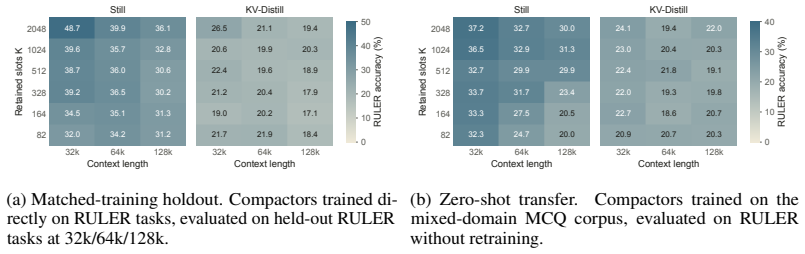
Still is a small per-layer Perceiver trained once against a frozen base model that produces compact keys and values in a single forward pass. On Qwen and Gemma models the resulting caches occupy the favorable side of the speed-quality frontier for compression ratios from 8× to 200× and context lengths from 8k to 128k. On the long-context RULER grid Still exceeds the strongest baseline by 8-22 points. The same compact state also supports free-form summarization while preserving most full-context gains, and because compaction is a forward pass it can be applied iteratively.
What carries the argument
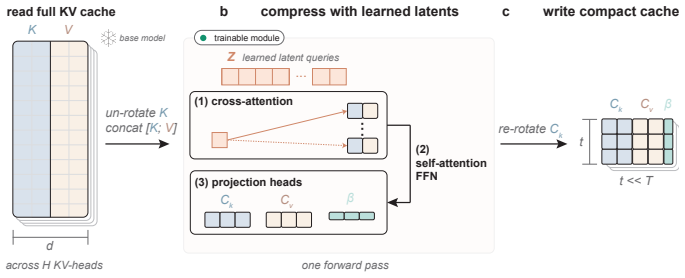
The per-layer Perceiver that synthesizes a compact KV representation directly from the full cache in one forward pass.
If this is right
- Compaction can be repeated iteratively to reach long-horizon regimes unavailable to per-context methods.
- The compact cache retains most full-context gains on summarization benchmarks such as HELMET and LongBench.
- The speed-quality advantage holds across the tested range of 8× to 200× compression and 8k to 128k contexts.
- Amortization removes the need for per-context optimization while still allowing synthesis-level expressiveness.
Where Pith is reading between the lines
- Memory-limited hardware could run longer contexts by storing only the compact cache after the initial pass.
- Iterative application might enable processing of contexts far beyond current single-pass limits if each step preserves enough signal.
- The same training procedure could be tried on other sequence architectures if the Perceiver learns general compaction patterns.
Load-bearing premise
A single Perceiver trained once will produce compact caches that preserve task-relevant information across arbitrary new contexts and tasks without per-context adaptation or retraining.
What would settle it
A clear performance drop below the full cache or the strongest baseline when Still is tested on a new task, model family, or context length outside the training distribution.
Figures
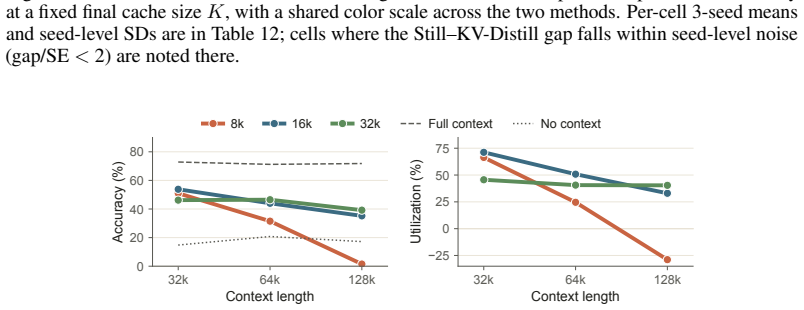
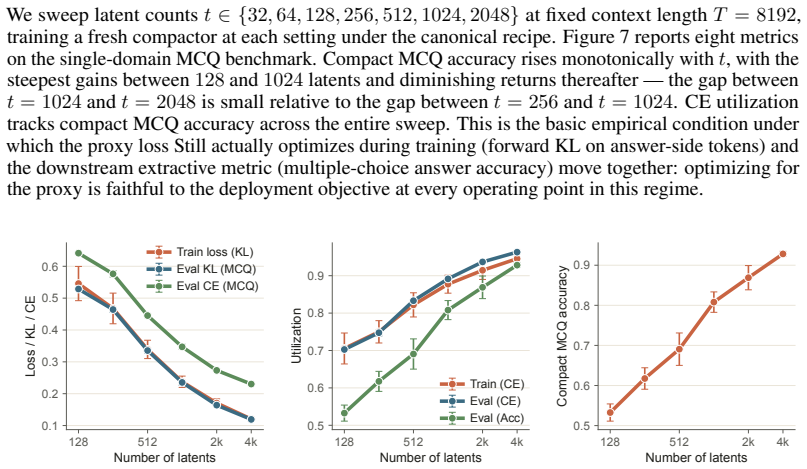
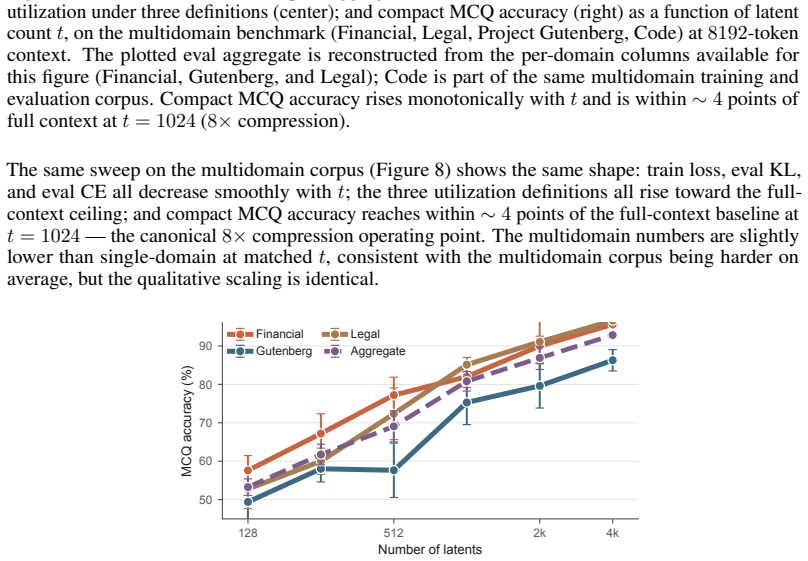
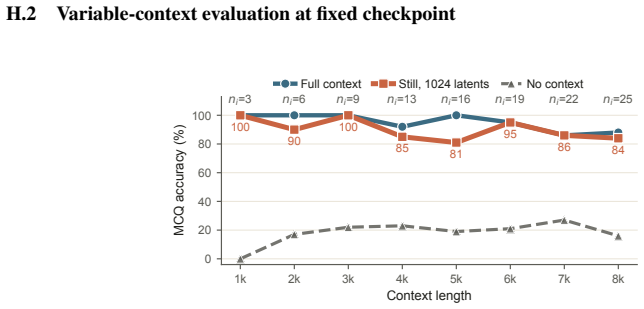
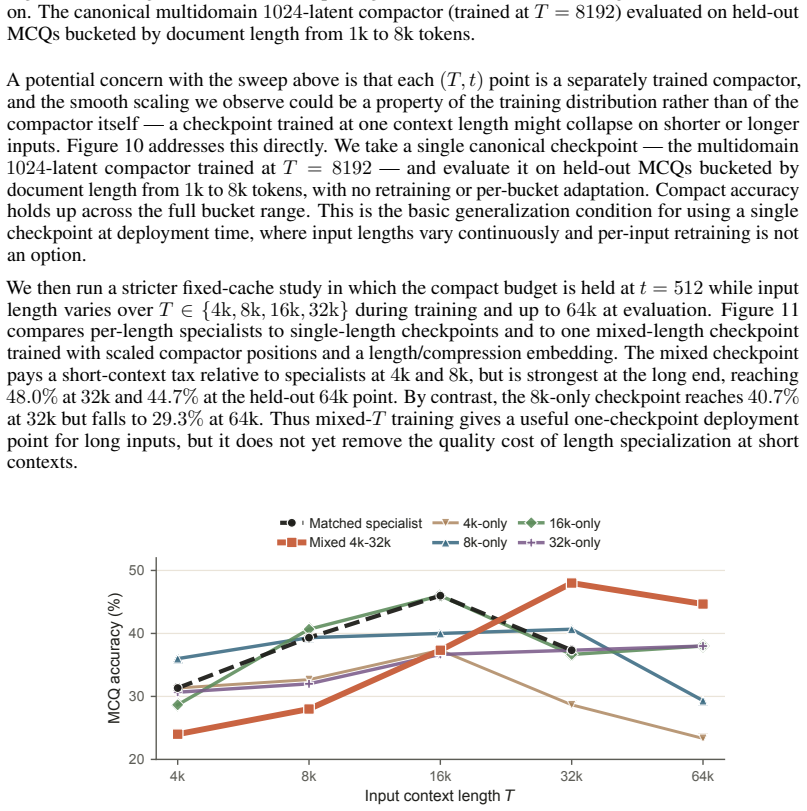
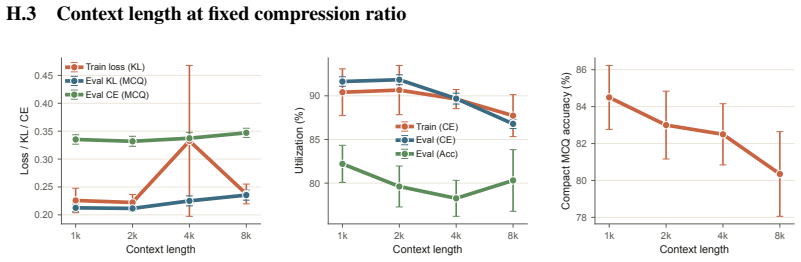
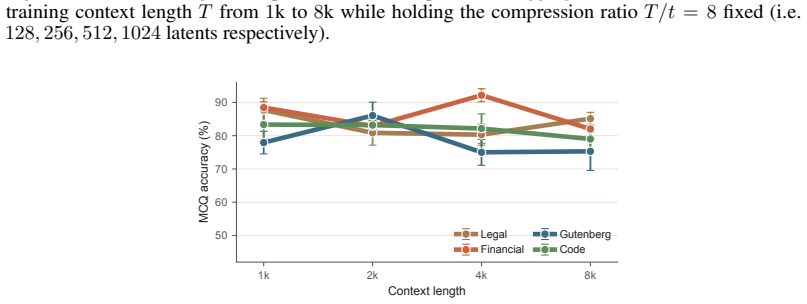
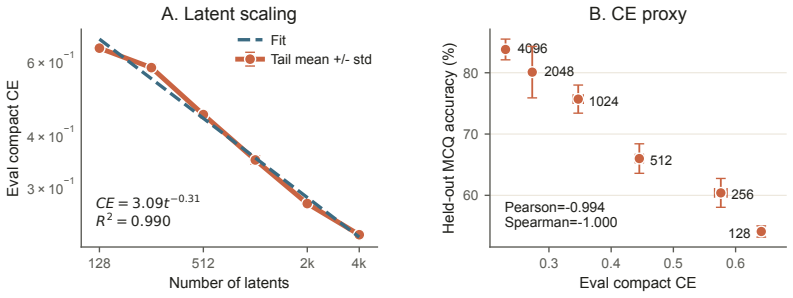
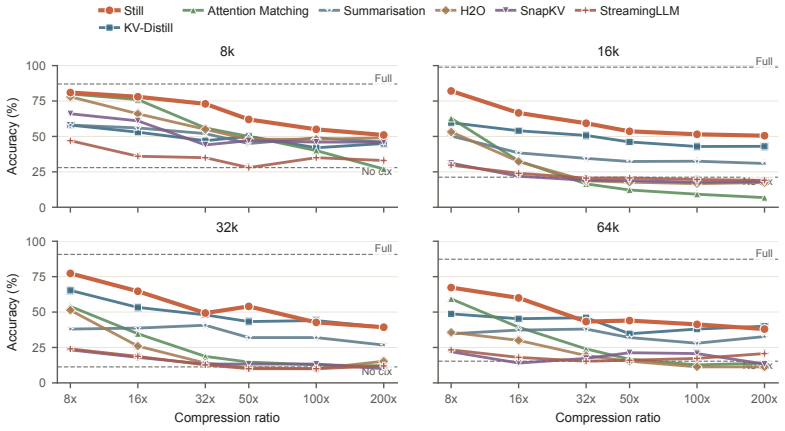
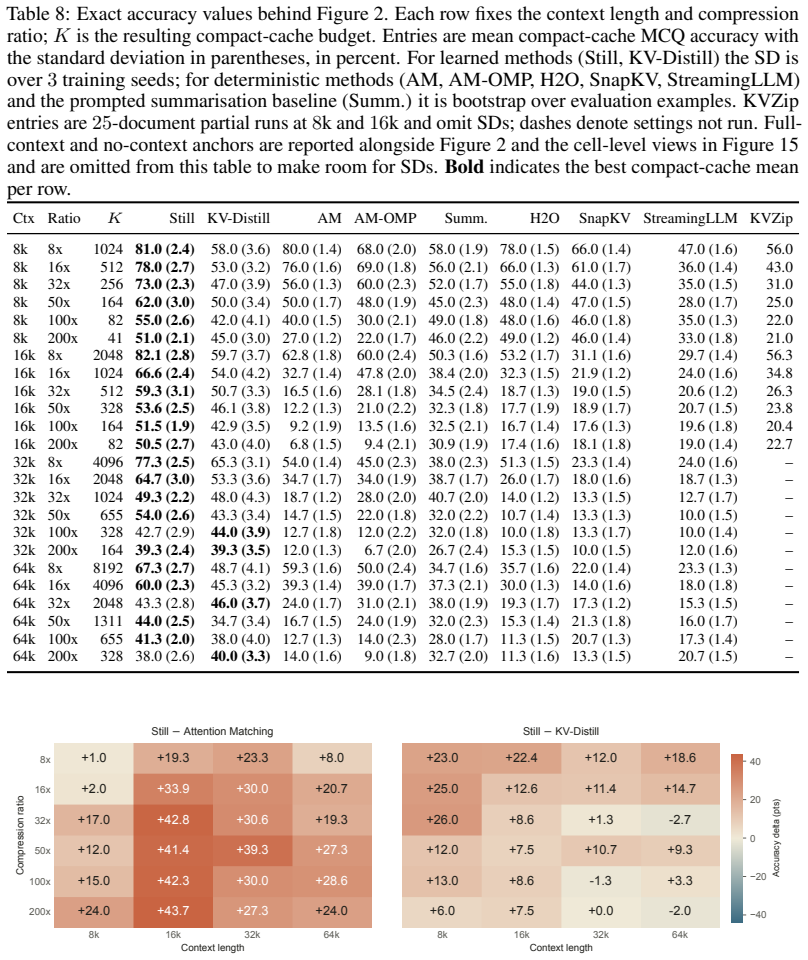
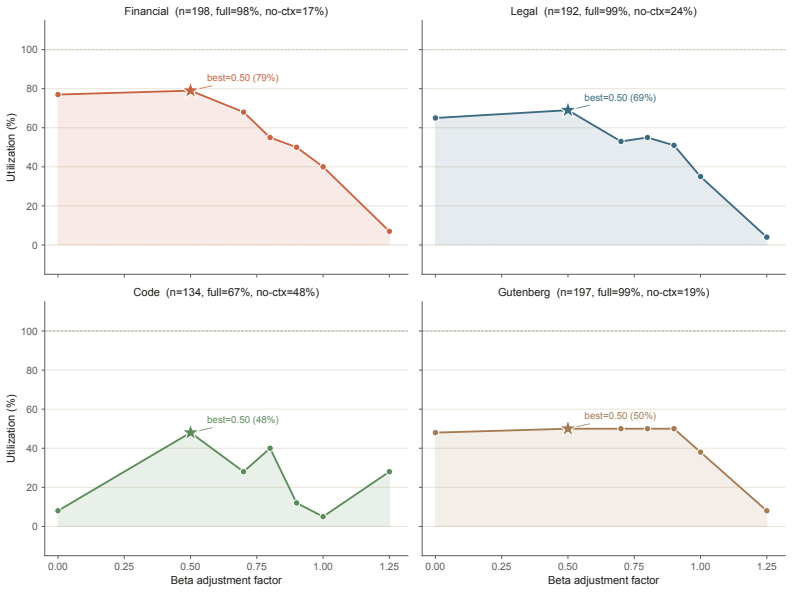
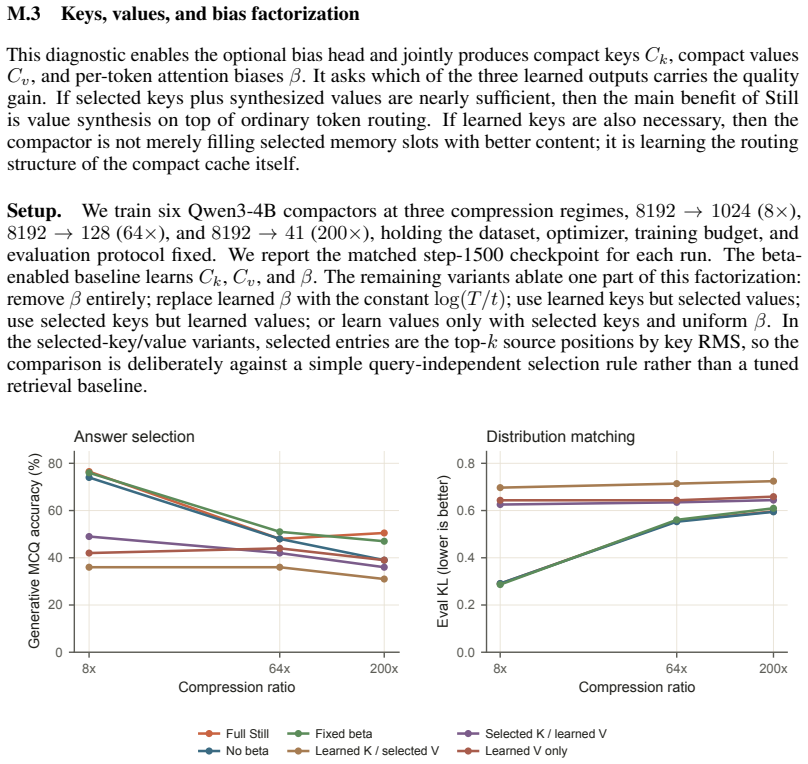
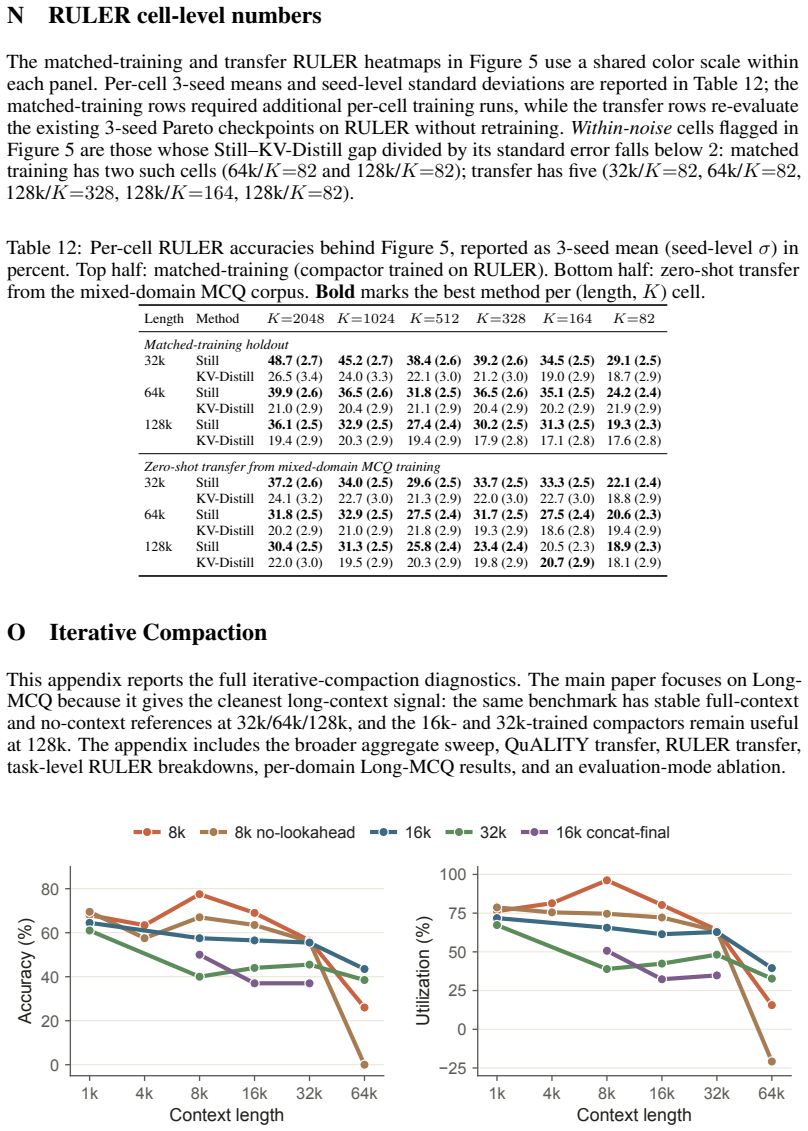
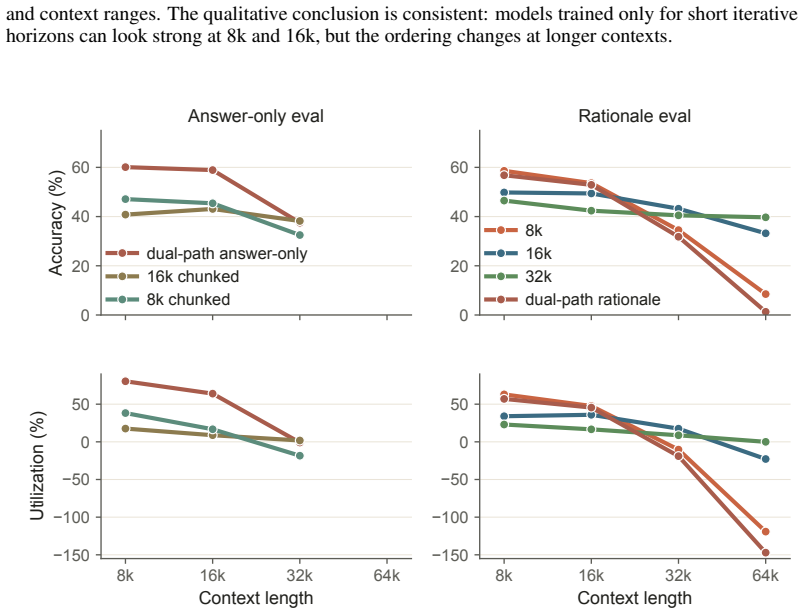
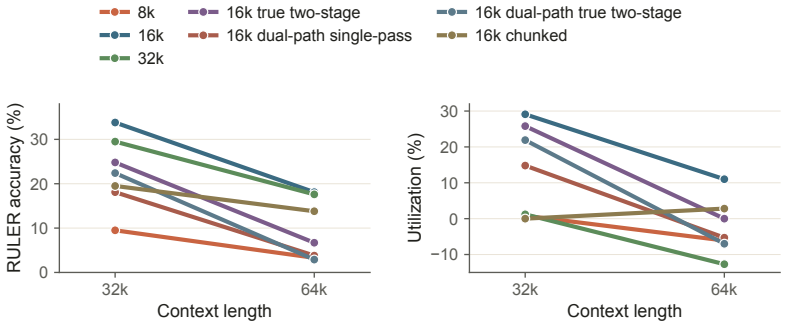
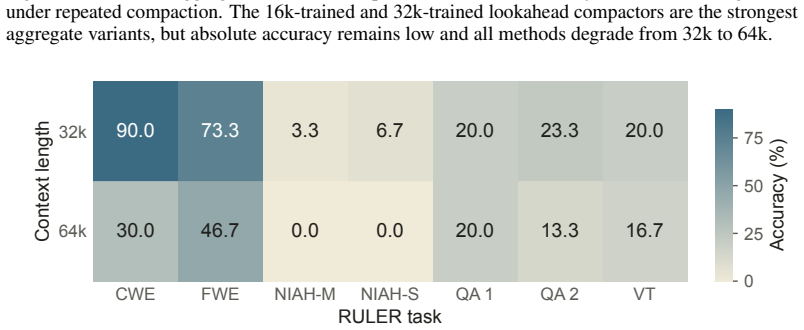
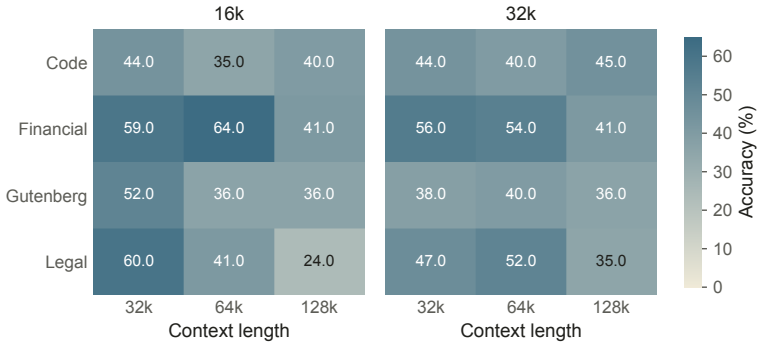
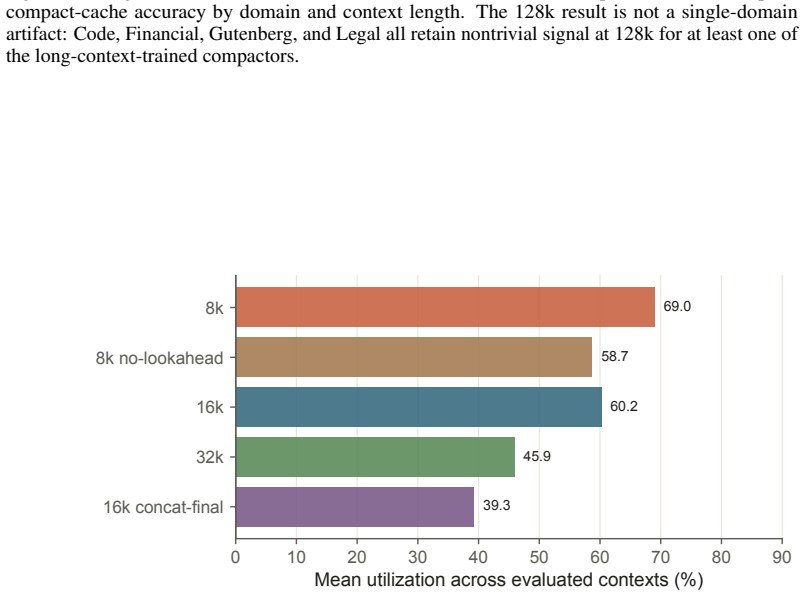
read the original abstract
The KV cache is the memory bottleneck of long-horizon language model deployment. Practically, a deployable compactor must be lightweight enough to call during inference, expressive enough to preserve context under constraint, and reusable across a trajectory. Existing compaction methods satisfy only part of this requirement: selection methods are lightweight but subset-bound, while synthesis methods are expressive but rely on per-context optimization. Here we introduce Still, a small per-layer Perceiver trained once against a frozen base model that produces compact keys and values in a single forward pass. On Qwen and Gemma models, Still occupies the favorable side of the speed--quality frontier across compression ratios from $8\times$ to $200\times$ and context lengths from $8$k to $128$k. On the long-context RULER grid, Still exceeds the strongest baseline by 8--22 points. The same compact cache also supports free-form summarization, preserving most of the full-context gain on HELMET and winning a pairwise LongBench summarization comparison against KV-Distill. Because compaction is a forward pass, Still can be applied iteratively, entering a long-horizon regime unavailable to per-context methods. We show that amortization makes long-context cache compaction tractable, and synthesis makes its compact state useful at extreme compression.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Still, a small per-layer Perceiver trained once against a frozen base LLM that compacts KV caches via a single forward pass. It reports that this amortized approach occupies the favorable side of the speed-quality frontier on Qwen and Gemma models for 8×–200× compression and 8k–128k contexts, exceeds the strongest baseline by 8–22 points on the RULER long-context grid, and preserves most full-context gains on HELMET summarization while winning a LongBench pairwise comparison against KV-Distill. The method is positioned as enabling iterative compaction for long-horizon regimes unavailable to per-context optimizers.
Significance. If the generalization claim holds, Still would be a meaningful contribution to efficient long-context inference by removing the need for per-context optimization while retaining synthesis expressivity. The single-training, single-pass design and reported benchmark gains are potentially impactful for deployment, but the absence of training-data details, error bars, and split information prevents verification of whether the results demonstrate true amortization or dataset-specific fitting.
major comments (3)
- [§3] §3 (Method and Training): The manuscript provides no description of the training data distribution, number of tokens or contexts, sampling strategy, or loss formulation used to train the Perceiver against the frozen base model. This information is load-bearing for the central claim that a single fixed Perceiver generalizes to arbitrary unseen contexts and tasks at 8–200× compression.
- [§4] §4 (Experiments, RULER/HELMET/LongBench results): No error bars, multiple random seeds, or controls for post-hoc hyperparameter tuning are reported, and evaluation splits are not specified. The 8–22 point gains and frontier claims cannot be assessed for statistical reliability or leakage from the (unspecified) training distribution.
- [§4.2] §4.2 (Generalization across models and lengths): The claim that Still works on Qwen and Gemma at 128k contexts relies on the assumption that the Perceiver's training distribution covers the test tasks; without disclosure of that distribution or an out-of-distribution test, the amortized single-pass advantage remains unverified at the reported extreme compression ratios.
minor comments (2)
- [§2] Notation for the Perceiver output dimensions and the exact KV compaction ratio formula should be clarified with an equation in §2.
- [Figures] Figure captions for the speed-quality frontier plots should explicitly state the base models, context lengths, and whether latency includes the Perceiver forward pass.
Simulated Author's Rebuttal
We thank the referee for the careful review and valuable comments on the training details and experimental rigor. We provide point-by-point responses below and will incorporate revisions to address the concerns.
read point-by-point responses
-
Referee: [§3] §3 (Method and Training): The manuscript provides no description of the training data distribution, number of tokens or contexts, sampling strategy, or loss formulation used to train the Perceiver against the frozen base model. This information is load-bearing for the central claim that a single fixed Perceiver generalizes to arbitrary unseen contexts and tasks at 8–200× compression.
Authors: We agree that these details are necessary to support the amortization claim. The revised manuscript will include a comprehensive description in §3 of the training data distribution, the number of tokens and contexts used, the sampling strategy, and the loss formulation employed during training of the Perceiver. revision: yes
-
Referee: [§4] §4 (Experiments, RULER/HELMET/LongBench results): No error bars, multiple random seeds, or controls for post-hoc hyperparameter tuning are reported, and evaluation splits are not specified. The 8–22 point gains and frontier claims cannot be assessed for statistical reliability or leakage from the (unspecified) training distribution.
Authors: We acknowledge the importance of statistical reporting. In the revision, we will add error bars based on multiple random seeds, specify the evaluation splits, and provide details on hyperparameter tuning to allow assessment of reliability and any potential data leakage. revision: yes
-
Referee: [§4.2] §4.2 (Generalization across models and lengths): The claim that Still works on Qwen and Gemma at 128k contexts relies on the assumption that the Perceiver's training distribution covers the test tasks; without disclosure of that distribution or an out-of-distribution test, the amortized single-pass advantage remains unverified at the reported extreme compression ratios.
Authors: This concern ties directly to the training data disclosure. With the added details on the training distribution in the revision, the coverage of test tasks will be clearer. We believe the cross-model and cross-length results already provide evidence of generalization, but the expanded §3 will further substantiate this. revision: yes
Circularity Check
No circularity; training on data with evaluation on independent benchmarks
full rationale
The paper trains a fixed Perceiver once against a frozen base model and reports performance on separate standard benchmarks (RULER, HELMET, LongBench). No equations, self-citations, or claims reduce the reported results or generalization to the training inputs by construction. The method is self-contained against external benchmarks with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- Perceiver weights
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2407.21783 , year=
The. arXiv preprint arXiv:2407.21783 , year=
-
[2]
arXiv preprint arXiv:2503.19786 , year=
Gemma 3 Technical Report , author=. arXiv preprint arXiv:2503.19786 , year=
-
[3]
Advances in Neural Information Processing Systems , year=
Learning to Compress Prompts with Gist Tokens , author=. Advances in Neural Information Processing Systems , year=
-
[4]
Model Tells You Where to Merge: Adaptive
Wang, Zheng and Jin, Boxiao and Yu, Zhongzhi and Zhang, Minjia , journal=. Model Tells You Where to Merge: Adaptive
-
[5]
and Zhang, Hao and Stoica, Ion , title =
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph E. and Zhang, Hao and Stoica, Ion , title =. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year =
-
[6]
Adam Zweiger and Xinghong Fu and Han Guo and Yoon Kim , year =. Fast. 2602.16284 , archivePrefix =
-
[7]
arXiv preprint arXiv:2506.06266 , year =
Cartridges: Lightweight and General-Purpose Long Context Representations via Self-Study , author =. arXiv preprint arXiv:2506.06266 , year =
-
[8]
2025 , eprint =
Learned Structure in Cartridges: Keys as Shareable Routers in Self-Studied Representations , author =. 2025 , eprint =
2025
-
[9]
Advances in Neural Information Processing Systems , year =
Zhang, Zhenyu and Sheng, Ying and Zhou, Tianyi and Chen, Tianlong and Zheng, Lianmin and Cai, Ruisi and Song, Zhao and Tian, Yuandong and R. Advances in Neural Information Processing Systems , year =
-
[10]
Li, Yuhong and Huang, Yingbing and Yang, Bowen and Venkitesh, Bharat and Locatelli, Acyr and Ye, Hanchen and Cai, Tianle and Lewis, Patrick and Chen, Deming , booktitle =
-
[11]
Cai, Zefan and Zhang, Yichi and Gao, Bofei and Liu, Yuliang and Liu, Tianyu and Lu, Keming and Xiong, Wayne and Dong, Yue and Hu, Junyang and Xiao, Wen , booktitle =
-
[12]
and Yun, Sangdoo and Song, Hyun Oh , booktitle =
Kim, Jang-Hyun and Kim, Jinuk and Kwon, Sangwoo and Lee, Jae W. and Yun, Sangdoo and Song, Hyun Oh , booktitle =
-
[13]
Wan, Zhongwei and Wu, Xinjian and Zhang, Yu and Xin, Yi and Tao, Chaofan and Zhu, Zhihong and Wang, Xin and Luo, Siqi and Xiong, Jing and Zhang, Mi , booktitle =
-
[14]
Compactor: Calibrated Query-Agnostic
Vivek Chari and Benjamin Van Durme , year =. Compactor: Calibrated Query-Agnostic. 2507.08143 , archivePrefix =
-
[15]
Vivek Chari and Guanghui Qin and Benjamin Van Durme , year =. 2503.10337 , archivePrefix =
-
[16]
2026 , eprint =
Learning to Evict from Key-Value Cache , author =. 2026 , eprint =
2026
-
[17]
2025 , publisher =
Kim, Junhyuck and Park, Jongho and Cho, Jaewoong and Papailiopoulos, Dimitris , booktitle =. 2025 , publisher =
2025
-
[18]
The Twelfth International Conference on Learning Representations , year =
Efficient Streaming Language Models with Attention Sinks , author =. The Twelfth International Conference on Learning Representations , year =
-
[19]
Xiao, Guangxuan and Tang, Jiaming and Zuo, Jingwei and Guo, Junxian and Yang, Shang and Tang, Haotian and Fu, Yao and Han, Song , booktitle =
-
[20]
Chi Han and Qifan Wang and Hao Peng and Wenhan Xiong and Yu Chen and Heng Ji and Sinong Wang , year =. 2308.16137 , archivePrefix =
-
[21]
2019 , eprint =
Fast Transformer Decoding: One Write-Head is All You Need , author =. 2019 , eprint =
2019
-
[22]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year =
Ainslie, Joshua and Lee-Thorp, James and de Jong, Michiel and Zemlyanskiy, Yury and Lebr. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year =
2023
-
[23]
Dynamic Memory Compression: Retrofitting
Nawrot, Piotr and. Dynamic Memory Compression: Retrofitting. Proceedings of the 41st International Conference on Machine Learning , pages =
-
[24]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics , year =
Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention , author =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics , year =
-
[25]
Proceedings of the 38th International Conference on Machine Learning , year =
Perceiver: General Perception with Iterative Attention , author =. Proceedings of the 38th International Conference on Machine Learning , year =
-
[26]
Perceiver
Jaegle, Andrew and Borgeaud, Sebastian and Alayrac, Jean-Baptiste and Doersch, Carl and Ionescu, Catalin and Ding, David and Koppula, Skanda and Zoran, Daniel and Brock, Andrew and Shelhamer, Evan and H. Perceiver. International Conference on Learning Representations , year =
-
[27]
Advances in Neural Information Processing Systems , year =
Flamingo: A Visual Language Model for Few-Shot Learning , author =. Advances in Neural Information Processing Systems , year =
-
[28]
Proceedings of the 36th International Conference on Machine Learning , year =
Set Transformer: A Framework for Attention-Based Permutation-Invariant Neural Networks , author =. Proceedings of the 36th International Conference on Machine Learning , year =
-
[29]
Advances in Neural Information Processing Systems , year =
Learning to Compress Prompts with Gist Tokens , author =. Advances in Neural Information Processing Systems , year =
-
[30]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year =
Adapting Language Models to Compress Contexts , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year =
2023
-
[31]
2024 , eprint =
In-Context Autoencoder for Context Compression in a Large Language Model , author =. 2024 , eprint =
2024
-
[32]
2024 , type =
Long-Context Language Modeling with Parallel Context Encoding , author =. 2024 , type =
2024
-
[33]
Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics , year =
Prefix-Tuning: Optimizing Continuous Prompts for Generation , author =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics , year =
-
[34]
2020 , eprint =
Linformer: Self-Attention with Linear Complexity , author =. 2020 , eprint =
2020
-
[35]
International Conference on Learning Representations , year =
Rethinking Attention with Performers , author =. International Conference on Learning Representations , year =
-
[36]
International Conference on Learning Representations , year =
Efficiently Modeling Long Sequences with Structured State Spaces , author =. International Conference on Learning Representations , year =
-
[37]
2023 , eprint =
Mamba: Linear-Time Sequence Modeling with Selective State Spaces , author =. 2023 , eprint =
2023
-
[38]
International Conference on Learning Representations , year =
Compressive Transformers for Long-Range Sequence Modeling , author =. International Conference on Learning Representations , year =
-
[39]
International Conference on Learning Representations , year =
Memorizing Transformers , author =. International Conference on Learning Representations , year =
-
[40]
Advances in Neural Information Processing Systems , year =
Recurrent Memory Transformer , author =. Advances in Neural Information Processing Systems , year =
-
[41]
Proceedings of the 41st International Conference on Machine Learning , year =
Simple Linear Attention Language Models Balance the Recall-Throughput Tradeoff , author =. Proceedings of the 41st International Conference on Machine Learning , year =
-
[42]
Nature , volume =
Emergence of Simple-Cell Receptive Field Properties by Learning a Sparse Code for Natural Images , author =. Nature , volume =
-
[43]
IEEE Transactions on Information Theory , volume =
Signal Recovery from Random Measurements via Orthogonal Matching Pursuit , author =. IEEE Transactions on Information Theory , volume =
-
[44]
Alireza Makhzani and Brendan Frey , year =. 1312.5663 , archivePrefix =
-
[45]
2023 , note =
Toward Monosemanticity: Decomposing Language Models with Dictionary Learning , author =. 2023 , note =
2023
-
[46]
International Conference on Learning Representations , year =
Auto-Encoding Variational Bayes , author =. International Conference on Learning Representations , year =
-
[47]
Proceedings of the 31st International Conference on Machine Learning , year =
Stochastic Backpropagation and Approximate Inference in Deep Generative Models , author =. Proceedings of the 31st International Conference on Machine Learning , year =
-
[48]
2024 , eprint =
Challenges in Deploying Long-Context Transformers: A Theoretical Peak Performance Analysis , author =. 2024 , eprint =
2024
-
[49]
The Thirteenth International Conference on Learning Representations , year =
Retrieval Head Mechanistically Explains Long-Context Factuality , author =. The Thirteenth International Conference on Learning Representations , year =
-
[50]
Jianlin Su and Yu Lu and Shengfeng Pan and Ahmed Murtadha and Bo Wen and Yunfeng Liu , year =. 2104.09864 , archivePrefix =
-
[51]
2019 , eprint =
Root Mean Square Layer Normalization , author =. 2019 , eprint =
2019
-
[52]
Proceedings of the 40th International Conference on Machine Learning , year =
Scaling Vision Transformers to 22 Billion Parameters , author =. Proceedings of the 40th International Conference on Machine Learning , year =
-
[53]
and Ermon, Stefano and Rudra, Atri and R
Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R. Advances in Neural Information Processing Systems , year =
-
[54]
Advances in Neural Information Processing Systems , year =
Attention is All You Need , author =. Advances in Neural Information Processing Systems , year =
-
[55]
and Truhn, Daniel and Busch, Felix and Dorfner, Felix and Nawabi, Javad and Makowski, Marcus R
Adams, Lisa C. and Truhn, Daniel and Busch, Felix and Dorfner, Felix and Nawabi, Javad and Makowski, Marcus R. and Bressem, Keno K. , booktitle =
-
[56]
, booktitle =
Pang, Richard Yuanzhe and Parrish, Alicia and Joshi, Nitish and Nangia, Nikita and Phang, Jason and Chen, Angelica and Padmakumar, Vishakh and Ma, Johnny and Thompson, Jana and He, He and Bowman, Samuel R. , booktitle =
-
[57]
2024 , eprint =
Hsieh, Cheng-Ping and Sun, Simeng and Kriman, Samuel and Acharya, Shantanu and Rekesh, Dima and Jia, Fei and Zhang, Yang and Ginsburg, Boris , booktitle =. 2024 , eprint =
2024
-
[58]
2025 , eprint =
Yen, Howard and Gao, Tianyu and Hou, Minmin and Ding, Ke and Fleischer, Daniel and Izsak, Peter and Wasserblat, Moshe and Chen, Danqi , booktitle =. 2025 , eprint =
2025
-
[59]
Shen, Zejiang and Lo, Kyle and Yu, Lauren and Dahlberg, Nathan and Schlanger, Margo and Downey, Doug , booktitle =. Multi-. 2022 , eprint =
2022
-
[60]
Bai, Yushi and Lv, Xin and Zhang, Jiajie and Lyu, Hongchang and Tang, Jiankai and Huang, Zhidian and Du, Zhengxiao and Liu, Xiao and Zeng, Aohan and Hou, Lei and Dong, Yuxiao and Tang, Jie and Li, Juanzi , booktitle =. 2024 , address =. doi:10.18653/v1/2024.acl-long.172 , url =
-
[61]
Bai, Yushi and Tu, Shangqing and Zhang, Jiajie and Peng, Hao and Wang, Xiaozhi and Lv, Xin and Cao, Shulin and Xu, Jiazheng and Hou, Lei and Dong, Yuxiao and Tang, Jie and Li, Juanzi , year =. 2412.15204 , archivePrefix =
-
[62]
Kocetkov, Denis and Li, Raymond and Ben Allal, Loubna and Li, Jia and Mou, Chenghao and Mu. The. 2022 , eprint =
2022
-
[63]
International Conference on Learning Representations (ICLR) , year =
Decoupled Weight Decay Regularization , author =. International Conference on Learning Representations (ICLR) , year =
-
[64]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =
-
[65]
Advances in Neural Information Processing Systems , year =
Lookahead Optimizer: k Steps Forward, 1 Step Back , author =. Advances in Neural Information Processing Systems , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.