VeriDrive: Verifiable Counterfactual Supervision for Cost-Efficient Vision-Language Planning
Pith reviewed 2026-06-27 22:18 UTC · model grok-4.3
The pith
VeriDrive converts driving rationales into a verifiable Perception-Evaluation-Revision chain that improves planning metrics at lower annotation cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
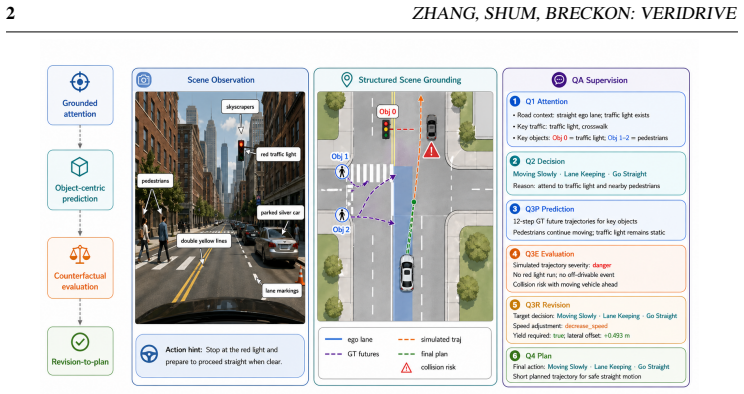
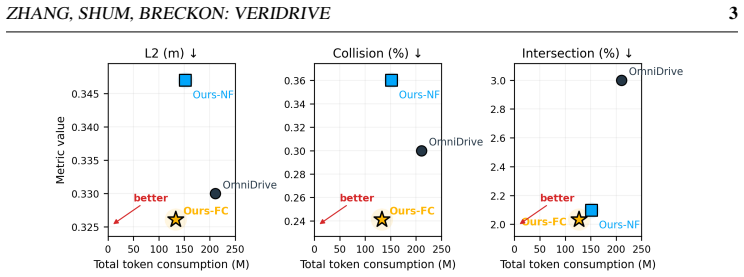
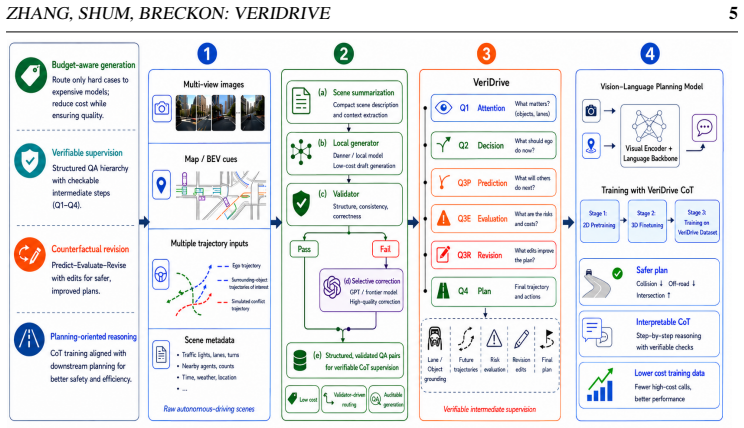
VeriDrive constructs planning-oriented, verifiable counterfactual supervision by converting driving reasoning into a Perception-Evaluation-Revision chain that grounds key objects in future motion, evaluates alternative ego trajectories with rule-checkable evidence, revises risky intent toward expert behavior, and produces final planning targets; local generation combined with validator-guided selective correction scales the process so that only invalid or difficult samples incur full model cost, resulting in improved open-loop planning metrics over OmniDrive at reduced logged token usage, generation time, and actual paid LLM/VLM cost.
What carries the argument
Perception-Evaluation-Revision chain: a structured sequence that grounds objects, applies rule-checkable trajectory evaluation, and produces revision targets to create auditable planning supervision.
If this is right
- Auditable intermediate fields allow direct inspection of why a planning target was chosen, reducing reliance on opaque free-form rationales.
- Selective correction limits expensive frontier-model calls to a minority of samples while preserving overall data quality.
- The resulting dataset trains models that outperform OmniDrive baselines on nuScenes under identical Omni-Q training conditions.
- Rule-checkable evidence in the evaluation step makes counterfactual trajectory comparisons reproducible without additional human review.
Where Pith is reading between the lines
- The same chain structure could be adapted to other sequential decision domains where rule-based checks on future states are feasible.
- Releasing the validator scripts would let independent groups audit or extend the generated dataset without re-running the full pipeline.
- Lower per-sample cost might enable repeated iterations of dataset construction as base models improve, creating a feedback loop for supervision quality.
Load-bearing premise
The validator-guided selective correction accurately flags invalid or difficult samples without introducing selection bias that affects the final performance gains or cost savings.
What would settle it
Run the same training pipeline but replace validator selection with uniform random sampling of samples for full correction; if the L2, collision, and intersection gains disappear or total paid cost rises above the reported savings, the selective-correction benefit is not supported.
Figures



read the original abstract
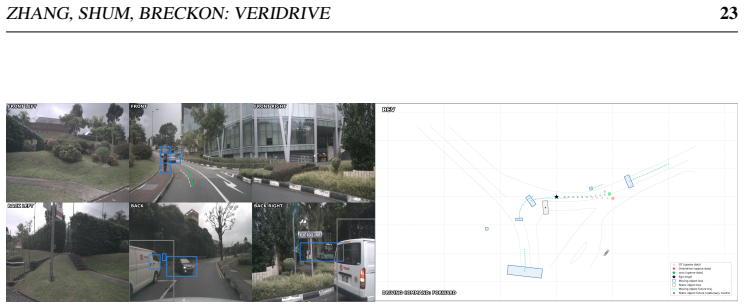
Vision-language driving models increasingly use reasoning supervision to bridge perception, prediction, and planning, but existing driving rationales are often free-form and expensive to generate with frontier models. We present VeriDrive, a framework for constructing planning-oriented, verifiable counterfactual supervision. VeriDrive converts driving reasoning into a structured Perception-Evaluation-Revision chain that grounds key objects in future motion, evaluates alternative ego trajectories with rule-checkable evidence, revises risky intent toward expert behavior, and produces final planning targets. To scale data construction, VeriDrive combines local generation with validator-guided selective correction, escalating only invalid or difficult samples. We build the VeriDrive dataset on nuScenes and train under the Omni-Q protocol. Controlled open-loop experiments show that VeriDrive improves L2, Collision, and Intersection over OmniDrive while reducing logged token usage, generation time, and actual paid LLM/VLM cost. These results show that auditable intermediate fields and structured revision targets can improve vision-language planning supervision under realistic annotation budgets. Code, prompts, and validator scripts are coming soon and will be released after the review process.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents VeriDrive, a framework for constructing planning-oriented verifiable counterfactual supervision for vision-language driving models. It converts reasoning into a structured Perception-Evaluation-Revision chain that grounds objects in future motion, evaluates alternative trajectories with rule-checkable evidence, and revises toward expert behavior. The approach combines local generation with validator-guided selective correction (escalating only invalid or difficult samples) to build a dataset on nuScenes, trains under the Omni-Q protocol, and reports improvements in L2, Collision, and Intersection metrics over OmniDrive alongside reductions in token usage, generation time, and paid LLM/VLM costs.
Significance. If the empirical claims hold under rigorous controls, VeriDrive could provide a scalable, lower-cost method for generating auditable supervision data for vision-language planning in autonomous driving, addressing the expense of frontier-model rationales. The planned release of code, prompts, and validator scripts would be a positive contribution to reproducibility.
major comments (2)
- [Abstract] Abstract: The central claim that VeriDrive yields better supervision and cost savings rests on the validator-guided selective correction producing a representative dataset without selection bias. The abstract provides no validator accuracy metrics, inter-annotator agreement on escalation decisions, or ablations isolating selective vs. exhaustive correction; without these, reported gains in L2/Collision/Intersection and cost metrics cannot be attributed to the Perception-Evaluation-Revision structure rather than filtering artifacts.
- [Abstract] Abstract: The abstract asserts metric improvements and cost reductions from 'controlled open-loop experiments' but supplies no details on experimental controls, statistical significance testing, error bars, dataset split construction, or baseline implementation specifics for the OmniDrive comparison; these omissions make the soundness of the performance claims impossible to evaluate from the provided text.
minor comments (1)
- The statement that code, prompts, and validator scripts 'are coming soon and will be released after the review process' should specify a concrete timeline or repository to support the reproducibility claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and will revise the abstract to improve self-containment while preserving its brevity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that VeriDrive yields better supervision and cost savings rests on the validator-guided selective correction producing a representative dataset without selection bias. The abstract provides no validator accuracy metrics, inter-annotator agreement on escalation decisions, or ablations isolating selective vs. exhaustive correction; without these, reported gains in L2/Collision/Intersection and cost metrics cannot be attributed to the Perception-Evaluation-Revision structure rather than filtering artifacts.
Authors: The full manuscript reports validator accuracy, inter-annotator agreement, and the selective-vs-exhaustive ablation in Sections 3.2 and 5.2; these results indicate that performance gains are attributable to the structured chain rather than filtering. To make this evident from the abstract alone, we will revise the abstract to include a concise clause referencing validator performance and the ablation outcome. revision: yes
-
Referee: [Abstract] Abstract: The abstract asserts metric improvements and cost reductions from 'controlled open-loop experiments' but supplies no details on experimental controls, statistical significance testing, error bars, dataset split construction, or baseline implementation specifics for the OmniDrive comparison; these omissions make the soundness of the performance claims impossible to evaluate from the provided text.
Authors: The manuscript body (Section 4) details the open-loop protocol, nuScenes splits, OmniDrive baseline following the Omni-Q protocol, error bars, and significance testing. We will revise the abstract to briefly note these controls (e.g., 'with error bars and significance testing on nuScenes splits') so that the claims can be evaluated from the abstract text. revision: yes
Circularity Check
No derivations or self-referential steps; purely empirical framework
full rationale
The paper introduces VeriDrive as a structured Perception-Evaluation-Revision chain for counterfactual supervision, combined with validator-guided selective correction to build a dataset on nuScenes. It then reports controlled open-loop experiments comparing L2/Collision/Intersection metrics and token/cost reductions against OmniDrive under the Omni-Q protocol. No equations, fitted parameters renamed as predictions, uniqueness theorems, or self-citation chains appear in the provided text. All claims rest on direct empirical comparisons rather than any derivation that reduces to its own inputs by construction. This matches the reader's assessment of no significant circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Alternative ego trajectories in driving scenes can be evaluated using rule-checkable evidence.
invented entities (1)
-
Perception-Evaluation-Revision chain
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Qwen3-VL technical report.arXiv preprint arXiv:2511.21631, 2025
Shuai Bai et al. Qwen3-VL technical report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[2]
Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuScenes: A mul- timodal dataset for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11621–11631, 2020. 16ZHANG, SHUM, BRECKON: VERIDRIVE
2020
-
[3]
SOLVE: Synergy of language-vision and end-to-end networks for au- tonomous driving
Xuesong Chen, Linjiang Huang, Tao Ma, Rongyao Fang, Shaoshuai Shi, and Hong- sheng Li. SOLVE: Synergy of language-vision and end-to-end networks for au- tonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12068–12077, 2025
2025
-
[4]
Chenxu Dang, Jie Wang, Guang Li, Zhiwen Hou, Zihan You, Hangjun Ye, Jie Ma, Long Chen, and Yan Wang. Sparseoccvla: Bridging occupancy and vision-language models via sparse queries for unified 4d scene understanding and planning.arXiv preprint arXiv:2601.06474, 2026
arXiv 2026
-
[5]
Talk2car: Taking control of your self-driving car
Thierry Deruyttere, Simon Vandenhende, Dusan Grujicic, Luc Van Gool, and Marie- Francine Moens. Talk2car: Taking control of your self-driving car. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP- IJCNLP), pages 2088–2098, 2019. doi: 10...
-
[6]
EV A-02: A visual representation for neon genesis.Image and Vision Computing, 149: 105171, 2024
Yuxin Fang, Quan Sun, Xinggang Wang, Tiejun Huang, Xinlong Wang, and Yue Cao. EV A-02: A visual representation for neon genesis.Image and Vision Computing, 149: 105171, 2024. doi: 10.1016/j.imavis.2024.105171
-
[7]
ST-P3: End-to-end vision-based autonomous driving via spatial-temporal fea- ture learning
Shengchao Hu, Li Chen, Penghao Wu, Hongyang Li, Junchi Yan, and Dacheng Tao. ST-P3: End-to-end vision-based autonomous driving via spatial-temporal fea- ture learning. InComputer Vision – ECCV 2022, pages 533–549, 2022. doi: 10.1007/978-3-031-19839-7_31
-
[8]
UniAD: Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, Lewei Lu, Xiaosong Jia, Qiang Liu, Jifeng Dai, Yu Qiao, and Hongyang Li. UniAD: Planning-oriented autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17853–17862, 2023
2023
-
[9]
Robotron-drive: All-in-one large multimodal model for autonomous driving
Zhijian Huang, Chengjian Feng, Feng Yan, Baihui Xiao, Zequn Jie, Yujie Zhong, Xi- aodan Liang, and Lin Ma. Robotron-drive: All-in-one large multimodal model for autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 8011–8021, 2025
2025
-
[10]
V AD: Vectorized scene repre- sentation for efficient autonomous driving
Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. V AD: Vectorized scene repre- sentation for efficient autonomous driving. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV), pages 8340–8350, 2023
2023
-
[11]
Textual explanations for self-driving vehicles
Jinkyu Kim, Anna Rohrbach, Trevor Darrell, John Canny, and Zeynep Akata. Textual explanations for self-driving vehicles. InProceedings of the European Conference on Computer Vision (ECCV), pages 563–578, 2018
2018
-
[12]
Enhancing end-to-end autonomous driving with latent world model
Yingyan Li, Lue Fan, Jiawei He, Yuqi Wang, Yuntao Chen, Zhaoxiang Zhang, and Tieniu Tan. Enhancing end-to-end autonomous driving with latent world model. In International Conference on Learning Representations (ICLR), 2025
2025
-
[13]
Zhiqi Li, Zhiding Yu, Shiyi Lan, Jiahan Li, Jan Kautz, Tong Lu, and Jose M. Alvarez. Is ego status all you need for open-loop end-to-end autonomous driving? InProceedings ZHANG, SHUM, BRECKON: VERIDRIVE17 of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14864–14873, 2024
2024
-
[14]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 26296–26306, 2024
2024
-
[15]
DRAMA: Joint risk localization and captioning in driving
Srikanth Malla, Chiho Choi, Isht Dwivedi, Joon Hee Choi, and Jiachen Li. DRAMA: Joint risk localization and captioning in driving. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1043–1052, 2023
2023
-
[16]
Lingoqa: Visual question answering for au- tonomous driving
Ana-Maria Marcu, Long Chen, Jan Hünermann, Alice Karnsund, Benoit Hanotte, Pra- jwal Chidananda, Saurabh Nair, Vijay Badrinarayanan, Alex Kendall, Jamie Shot- ton, Elahe Arani, and Oleg Sinavski. Lingoqa: Visual question answering for au- tonomous driving. InComputer Vision – ECCV 2024, pages 252–269, 2024. doi: 10.1007/978-3-031-72980-5_15
-
[17]
Reason2drive: Towards interpretable and chain-based reasoning for au- tonomous driving
Ming Nie, Renyuan Peng, Chunwei Wang, Xinyue Cai, Jianhua Han, Hang Xu, and Li Zhang. Reason2drive: Towards interpretable and chain-based reasoning for au- tonomous driving. InComputer Vision – ECCV 2024, pages 292–308, 2024. doi: 10.1007/978-3-031-73347-5_17
-
[18]
Nuscenes- qa: A multi-modal visual question answering benchmark for autonomous driving sce- nario
Tianwen Qian, Jingjing Chen, Linhai Zhuo, Yang Jiao, and Yu-Gang Jiang. Nuscenes- qa: A multi-modal visual question answering benchmark for autonomous driving sce- nario. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), vol- ume 38, pages 4542–4550, 2024. doi: 10.1609/aaai.v38i5.28253
-
[19]
Toward driving scene understanding: A dataset for learning driver behavior and causal reasoning
Vasili Ramanishka, Yi-Ting Chen, Teruhisa Misu, and Kate Saenko. Toward driving scene understanding: A dataset for learning driver behavior and causal reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7699–7707, 2018
2018
-
[20]
Rank2tell: A multimodal driving dataset for joint importance ranking and reasoning
Enna Sachdeva, Nakul Agarwal, Suhas Chundi, Sean Roelofs, Jiachen Li, Mykel Kochenderfer, Chiho Choi, and Behzad Dariush. Rank2tell: A multimodal driving dataset for joint importance ranking and reasoning. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 7513–7522, 2024
2024
-
[21]
DriveLM: Driving with graph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, and Hongyang Li. DriveLM: Driving with graph visual question answering. InComputer Vision – ECCV 2024, pages 256–274, 2024
2024
-
[22]
Drivevlm: The convergence of autonomous driving and large vision-language models
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, XianPeng Lang, and Hang Zhao. Drivevlm: The convergence of autonomous driving and large vision-language models. InProceedings of The 8th Conference on Robot Learning, pages 4698–4726, 2025
2025
-
[23]
OpenLane-V2: A topology reasoning benchmark for unified 3d hd mapping
Huijie Wang, Tianyu Li, Yang Li, Li Chen, Chonghao Sima, Zhenbo Liu, Bangjun Wang, Peijin Jia, Yuting Wang, Shengyin Jiang, Feng Wen, Hang Xu, Ping Luo, Junchi 18ZHANG, SHUM, BRECKON: VERIDRIVE Yan, Wei Zhang, and Hongyang Li. OpenLane-V2: A topology reasoning benchmark for unified 3d hd mapping. InAdvances in Neural Information Processing Systems (NeurIP...
2023
-
[24]
Shihao Wang, Zhiding Yu, Xiaohui Jiang, Shiyi Lan, Min Shi, Nadine Chang, Jan Kautz, Ying Li, and Jose M. Alvarez. OmniDrive: A holistic vision-language dataset for autonomous driving with counterfactual reasoning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22442–22452, June 2025
2025
-
[25]
Language prompt for autonomous driving
Dongming Wu, Wencheng Han, Yingfei Liu, Tiancai Wang, Cheng-Zhong Xu, Xi- angyu Zhang, and Jianbing Shen. Language prompt for autonomous driving. InPro- ceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 8359– 8367, 2025. doi: 10.1609/aaai.v39i8.32902
-
[26]
In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp
Yiran Xu, Xiaoyin Yang, Lihang Gong, Hsuan-Chu Lin, Tz-Ying Wu, Yunsheng Li, and Nuno Vasconcelos. Explainable object-induced action decision for autonomous vehicles. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9523–9532, 2020. doi: 10.1109/CVPR42600.2020.00954
-
[27]
AutoDrive-P3: Unified chain of perception–prediction–planning thought via reinforce- ment fine-tuning
Yuqi Ye, Zijian Zhang, Junhong Lin, Shangkun Sun, Changhao Peng, and Wei Gao. AutoDrive-P3: Unified chain of perception–prediction–planning thought via reinforce- ment fine-tuning. InInternational Conference on Learning Representations (ICLR),
-
[28]
Rethinking the Open-Loop Evaluation of End-to-End Autonomous Driving in nuScenes
Jiang-Tian Zhai, Ze Feng, Jinhao Du, Yongqiang Mao, Jiang-Jiang Liu, Zichang Tan, Yifu Zhang, Xiaoqing Ye, and Jingdong Wang. Rethinking the open-loop evaluation of end-to-end autonomous driving in nuScenes.arXiv preprint arXiv:2305.10430, 2023. doi: 10.48550/arXiv.2305.10430
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.10430 2023
-
[29]
World4drive: End-to-end autonomous driving via intention-aware physical latent world model
Yupeng Zheng, Pengxuan Yang, Zebin Xing, Qichao Zhang, Yuhang Zheng, Yinfeng Gao, Pengfei Li, Teng Zhang, Zhongpu Xia, Peng Jia, XianPeng Lang, and Dongbin Zhao. World4drive: End-to-end autonomous driving via intention-aware physical latent world model. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 28632–28642, 2025
2025
-
[30]
Opendrivevla: Towards end-to-end autonomous driving with large vision language ac- tion model
Xingcheng Zhou, Xuyuan Han, Feng Yang, Yunpu Ma, V olker Tresp, and Alois Knoll. Opendrivevla: Towards end-to-end autonomous driving with large vision language ac- tion model. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), volume 40, pages 13782–13790, 2026. doi: 10.1609/aaai.v40i16.38386. ZHANG, SHUM, BRECKON: VERIDRIVE19 A Suppl...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.