MAAM: Anchor-Preserving Compression and Contextual Calibration for Chinese Discriminatory Language Detection
Pith reviewed 2026-06-27 16:57 UTC · model grok-4.3
The pith
MAAM retains discrimination-relevant semantic anchors and calibrates them with contextual priors to improve Chinese discriminatory language detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
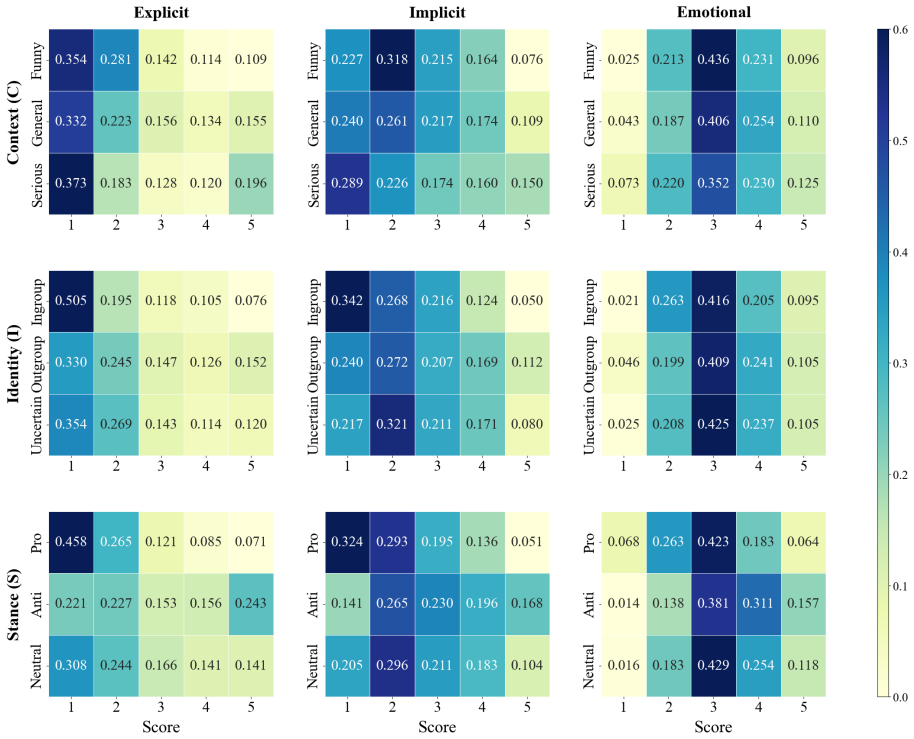
MAAM retains discrimination-relevant semantic anchors and calibrates them with C-I-S contextual priors (Contextual Tone, Group Identity, and Stance Polarity) to detect explicit and implicit bias in Chinese text, producing consistent gains in accuracy, F1, Brier score, and expected calibration error on encoder baselines while remaining competitive with frontier LLMs under zero-shot and few-shot prompting and delivering greater compactness and stability.
What carries the argument
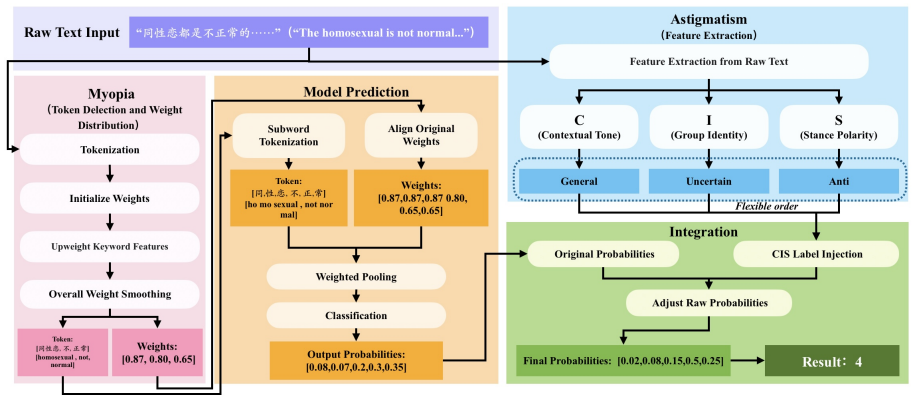
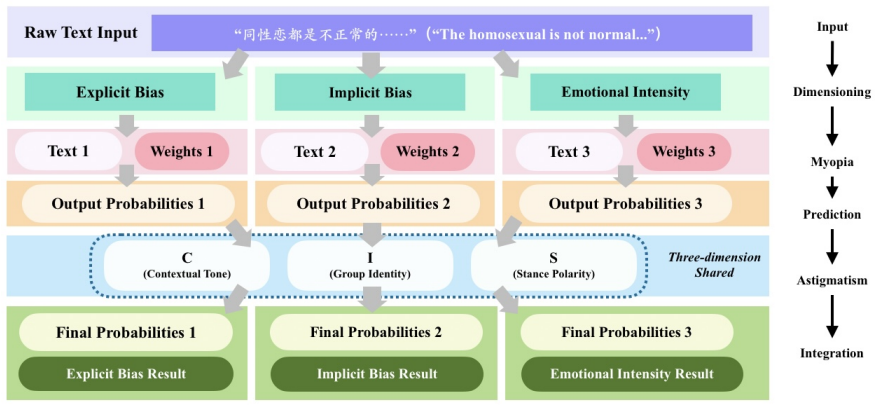
Myopia-Astigmatism Anchor Mechanism (MAAM), which selectively preserves semantic anchors tied to discrimination and applies calibration from Contextual Tone, Group Identity, and Stance Polarity priors.
If this is right
- Consistent gains appear across accuracy, F1, Brier score, and expected calibration error on strong encoder baselines.
- Performance remains competitive with frontier LLMs under both zero-shot and few-shot prompting.
- The approach supplies stronger compactness and stability than larger models.
- Interpretable anchor preservation and contextual calibration serve as a practical alternative to heavier model scaling for Chinese discriminatory-language assessment.
Where Pith is reading between the lines
- The same anchor-and-calibration pattern could be tested on discriminatory language tasks in other languages that rely on implicit cues.
- Real-time content-moderation systems might adopt the method to reduce compute while preserving calibration quality.
- The ChLGBT dataset could function as a public benchmark for comparing future lightweight bias detectors in Chinese.
- Combining MAAM with additional calibration techniques might further lower expected calibration error on similar tasks.
Load-bearing premise
The C-I-S contextual priors supply effective calibration for the retained semantic anchors and the ChLGBT annotations correctly capture the intended bias dimensions.
What would settle it
Applying MAAM to an independent Chinese discriminatory-language dataset and observing no reduction in expected calibration error relative to the same encoder baselines without the C-I-S priors would falsify the central claim.
Figures
read the original abstract
Chinese discriminatory-language detection is challenging because harmful intent is often implicit and context-dependent. We propose MAAM (Myopia--Astigmatism Anchor Mechanism), a lightweight, model-agnostic framework inspired by functional visual blur: rather than preserving every token equally, MAAM retains discrimination-relevant semantic anchors and calibrates them with C--I--S contextual priors (Contextual Tone, Group Identity, and Stance Polarity). We also introduce ChLGBT, to our knowledge the first Chinese LGBT-focused discriminatory-language dataset, with 8,120 manually annotated samples and three ordinal labels: explicit bias, implicit bias, and emotional intensity. Across strong encoder baselines, MAAM improves all three prediction dimensions, with consistent gains in accuracy, F1, Brier score, and expected calibration error. Compared with frontier LLM baselines under zero-shot and few-shot prompting protocols, MAAM remains competitive while offering stronger compactness and stability. These results suggest that interpretable anchor preservation and contextual calibration provide a practical alternative to heavier model scaling for Chinese discriminatory-language assessment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
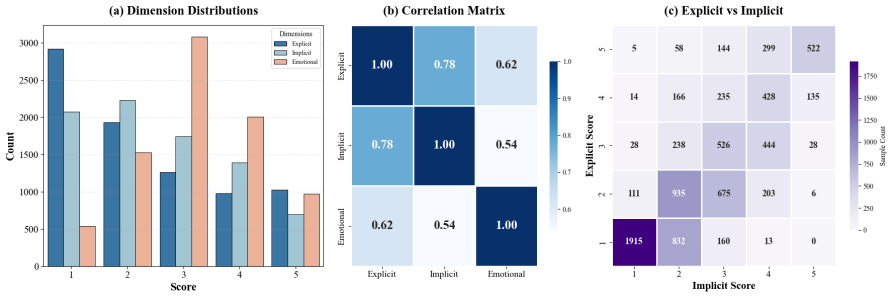
Summary. The paper proposes MAAM (Myopia-Astigmatism Anchor Mechanism), a lightweight model-agnostic framework for Chinese discriminatory language detection that retains discrimination-relevant semantic anchors and calibrates them using C-I-S contextual priors (Contextual Tone, Group Identity, Stance Polarity). It introduces the ChLGBT dataset containing 8,120 manually annotated samples with three ordinal labels (explicit bias, implicit bias, emotional intensity). The authors claim consistent improvements in accuracy, F1, Brier score, and expected calibration error over strong encoder baselines, while remaining competitive with frontier LLMs under zero- and few-shot prompting, with advantages in compactness and stability.
Significance. If the empirical claims hold and the dataset annotations prove reliable, the work would demonstrate that interpretable anchor preservation plus targeted contextual calibration can serve as a practical, efficient alternative to model scaling for detecting implicit, context-dependent bias in Chinese text. The introduction of a specialized Chinese LGBT-focused dataset would address a clear resource gap in the field.
major comments (2)
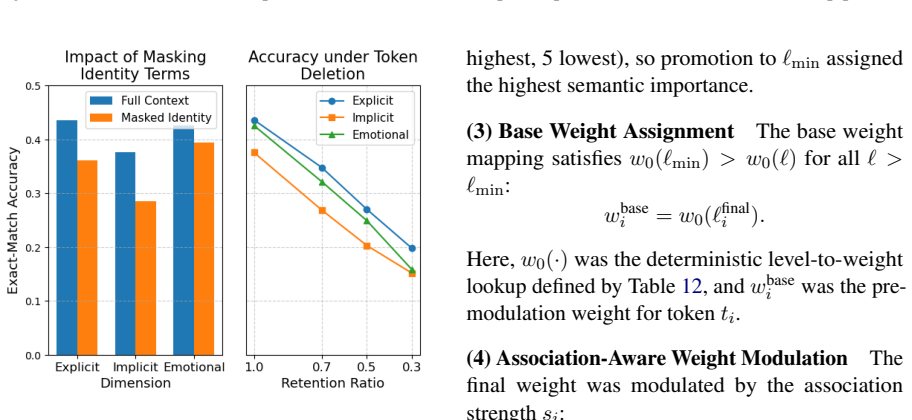
- [Abstract and Dataset section] The central performance claims (gains in accuracy, F1, Brier score, and ECE over encoder baselines, plus competitiveness with LLMs) rest on the ChLGBT annotations faithfully capturing the intended bias dimensions and on the C-I-S priors providing effective calibration. However, no inter-annotator agreement statistics, annotation protocol, or validation of label reliability are referenced, and no ablation removing individual C-I-S components is described. If either premise fails, the reported improvements become uninterpretable.
- [Abstract] The abstract asserts quantitative improvements across all three prediction dimensions but supplies no numerical results, baseline values, dataset splits, or error analysis. This absence prevents verification of whether the data actually support the stated gains in accuracy/F1/Brier/ECE or the compactness/stability advantages.
minor comments (1)
- [Introduction] The acronym MAAM is expanded as 'Myopia-Astigmatism Anchor Mechanism' but the visual analogy is not connected to any concrete algorithmic step or equation; a brief mapping from the metaphor to the implementation would improve clarity.
Simulated Author's Rebuttal
Thank you for the detailed and constructive review. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and additions.
read point-by-point responses
-
Referee: [Abstract and Dataset section] The central performance claims (gains in accuracy, F1, Brier score, and ECE over encoder baselines, plus competitiveness with LLMs) rest on the ChLGBT annotations faithfully capturing the intended bias dimensions and on the C-I-S priors providing effective calibration. However, no inter-annotator agreement statistics, annotation protocol, or validation of label reliability are referenced, and no ablation removing individual C-I-S components is described. If either premise fails, the reported improvements become uninterpretable.
Authors: We agree that explicit reporting of annotation reliability and component ablations is necessary to support the claims. The full manuscript describes the three-annotator protocol (experts in Chinese linguistics and LGBT studies) and the ordinal labeling process in the Dataset section, but we omitted inter-annotator agreement metrics (e.g., Fleiss' kappa) and a dedicated ablation on individual C-I-S priors. In the revision we will add the agreement statistics, a validation subsection, and a full ablation table removing Contextual Tone, Group Identity, and Stance Polarity one at a time. revision: yes
-
Referee: [Abstract] The abstract asserts quantitative improvements across all three prediction dimensions but supplies no numerical results, baseline values, dataset splits, or error analysis. This absence prevents verification of whether the data actually support the stated gains in accuracy/F1/Brier/ECE or the compactness/stability advantages.
Authors: We accept that the abstract should be more self-contained. The current version summarizes the direction of gains without numbers to stay within length limits. In the revision we will insert concise quantitative results (e.g., accuracy and F1 deltas over the strongest encoder baseline, Brier/ECE reductions, and a note on the 70/15/15 split) while preserving readability; the detailed error analysis and full tables will remain in the main body. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces MAAM as a lightweight framework for discriminatory language detection and presents the ChLGBT dataset with empirical results on accuracy, F1, Brier score, and ECE. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or claimed results. The central claims rest on experimental comparisons rather than any self-definitional or load-bearing reduction to inputs. The derivation chain is therefore self-contained with no detectable circular steps.
Axiom & Free-Parameter Ledger
invented entities (2)
-
MAAM (Myopia-Astigmatism Anchor Mechanism)
no independent evidence
-
ChLGBT dataset
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Proceedings of the International AAAI Conference on Web and Social Media , volume=
The lgbtq+ minority stress on social media (missom) dataset: A labeled dataset for natural language processing and machine learning , author=. Proceedings of the International AAAI Conference on Web and Social Media , volume=
-
[9]
Procedia Computer Science , volume=
Sentiments comparison on Twitter about LGBT , author=. Procedia Computer Science , volume=. 2023 , publisher=
2023
-
[10]
arXiv preprint arXiv:2109.00227 , year=
Dataset for identification of homophobia and transophobia in multilingual YouTube comments , author=. arXiv preprint arXiv:2109.00227 , year=
-
[11]
Language Resources and Evaluation , volume=
Hope speech detection in spanish: The lgbt case , author=. Language Resources and Evaluation , volume=. 2023 , publisher=
2023
-
[12]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
CBBQ: A Chinese bias benchmark dataset curated with human-AI collaboration for large language models , author=. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
2024
-
[13]
Findings of the Association for Computational Linguistics: EMNLP 2022 , pages=
Towards identifying social bias in dialog systems: Framework, dataset, and benchmark , author=. Findings of the Association for Computational Linguistics: EMNLP 2022 , pages=
2022
-
[14]
arXiv preprint arXiv:2301.00395 , year=
Corgi-pm: A chinese corpus for gender bias probing and mitigation , author=. arXiv preprint arXiv:2301.00395 , year=
-
[15]
Findings of the Association for Computational Linguistics: EMNLP 2020 , month = nov, year =
Revisiting Pre-Trained Models for Chinese Natural Language Processing , author =. Findings of the Association for Computational Linguistics: EMNLP 2020 , month = nov, year =. doi:10.18653/v1/2020.findings-emnlp.159 , url =
-
[16]
The Stem Cell Hypothesis: Dilemma behind Multi-Task Learning with Transformer Encoders
He, Han and Choi, Jinho D. The Stem Cell Hypothesis: Dilemma behind Multi-Task Learning with Transformer Encoders. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021
2021
-
[17]
2011 , publisher=
Computing Krippendorff’s alpha-reliability , author=. 2011 , publisher=
2011
-
[18]
2025 , publisher=
Token Pruning for Efficient NLP, Vision, and Speech Models , author=. 2025 , publisher=
2025
-
[19]
arXiv preprint arXiv:2602.18450 , year=
Asymptotic Semantic Collapse in Hierarchical Optimization , author=. arXiv preprint arXiv:2602.18450 , year=
-
[20]
arXiv preprint arXiv:2511.19928 , year=
Context-Aware Token Pruning and Discriminative Selective Attention for Transformer Tracking , author=. arXiv preprint arXiv:2511.19928 , year=
-
[21]
Proceedings of the 14th International Conference on Recent Advances in Natural Language Processing , pages=
Noisy self-training with data augmentations for offensive and hate speech detection tasks , author=. Proceedings of the 14th International Conference on Recent Advances in Natural Language Processing , pages=
-
[22]
Proceedings of the 31st International Conference on Computational Linguistics: Industry Track , pages=
A Simple yet Efficient Prompt Compression Method for Text Classification Data Annotation Using LLM , author=. Proceedings of the 31st International Conference on Computational Linguistics: Industry Track , pages=
-
[23]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Towards Objective Fine-tuning: How LLMs’ Prior Knowledge Causes Potential Poor Calibration? , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[24]
Language Models (Mostly) Know What They Know
Language models (mostly) know what they know , author=. arXiv preprint arXiv:2207.05221 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Causal reasoning and large language models: Opening a new frontier for causality , author=
-
[26]
Learning for dynamics and control conference , pages=
Can foundation models perform zero-shot task specification for robot manipulation? , author=. Learning for dynamics and control conference , pages=. 2022 , organization=
2022
-
[27]
Energy and Policy Considerations for Deep Learning in NLP
Energy and Policy Considerations for Deep Learning in NLP , author=. arXiv preprint arXiv:1906.02243 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[28]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Chbias: Bias evaluation and mitigation of chinese conversational language models , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[29]
Proceedings of the 13th international workshop on semantic evaluation , pages=
Semeval-2019 task 5: Multilingual detection of hate speech against immigrants and women in twitter , author=. Proceedings of the 13th international workshop on semantic evaluation , pages=
2019
-
[30]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
COLD: A benchmark for Chinese offensive language detection , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[31]
1976 , publisher=
Beyond culture , author=. 1976 , publisher=
1976
-
[32]
1998 , publisher=
Communicating effectively with the Chinese , author=. 1998 , publisher=
1998
-
[33]
2010 , publisher=
Vision: A computational investigation into the human representation and processing of visual information , author=. 2010 , publisher=
2010
-
[34]
Behavioral and brain sciences , volume=
Whatever next? Predictive brains, situated agents, and the future of cognitive science , author=. Behavioral and brain sciences , volume=. 2013 , publisher=
2013
-
[35]
International conference on learning representations , year=
ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness , author=. International conference on learning representations , year=
-
[36]
Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
Latent hatred: A benchmark for understanding implicit hate speech , author=. Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
2021
-
[37]
Proceedings of the 29th international conference on computational linguistics , pages=
Generalizable implicit hate speech detection using contrastive learning , author=. Proceedings of the 29th international conference on computational linguistics , pages=
-
[38]
Discourse, Context & Media , volume=
Context in abusive language detection: On the interdependence of context and annotation of user comments , author=. Discourse, Context & Media , volume=. 2025 , publisher=
2025
-
[39]
Proceedings of the 2024 joint international conference on computational linguistics, language resources and evaluation (LREC-COLING 2024) , pages=
Humans need context, what about machines? investigating conversational context in abusive language detection , author=. Proceedings of the 2024 joint international conference on computational linguistics, language resources and evaluation (LREC-COLING 2024) , pages=
2024
-
[40]
PoWER-BERT: Accelerating
Goyal, Saurabh and Choudhury, Anamitra Roy and Raje, Saurabh and Chakaravarthy, Venkatesan and Sabharwal, Yogish and Verma, Ashish , booktitle=. PoWER-BERT: Accelerating. 2020 , publisher=
2020
-
[41]
Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
Learned Token Pruning for Transformers , author=. Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=. 2022 , publisher=. doi:10.1145/3534678.3539260 , url=
-
[42]
Proceedings of the 34th International Conference on Machine Learning , series=
On Calibration of Modern Neural Networks , author=. Proceedings of the 34th International Conference on Machine Learning , series=. 2017 , publisher=
2017
-
[43]
Information , volume=
Chinese cyberbullying detection using XLNet and deep bi-LSTM hybrid model , author=. Information , volume=. 2024 , publisher=
2024
-
[44]
Proceedings of the 47th international ACM SIGIR conference on research and development in information retrieval , pages=
C-pack: Packed resources for general chinese embeddings , author=. Proceedings of the 47th international ACM SIGIR conference on research and development in information retrieval , pages=
-
[45]
Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
The stem cell hypothesis: Dilemma behind multi-task learning with transformer encoders , author=. Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
2021
-
[46]
arXiv preprint arXiv:2406.04068 , year=
Reassessing how to compare and improve the calibration of machine learning models , author=. arXiv preprint arXiv:2406.04068 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.