A Trainable-by-Parts Operator Learning Framework: Bridging DeepONet and Karhunen-Loeve Expansions for Large-Scale Applications
Pith reviewed 2026-06-30 00:57 UTC · model grok-4.3
The pith
The KL-DNN constructs latent spaces via low-rank SVD and nested Karhunen-Loeve expansions to deliver full-resolution predictions for large-scale PDEs with only 100 training samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
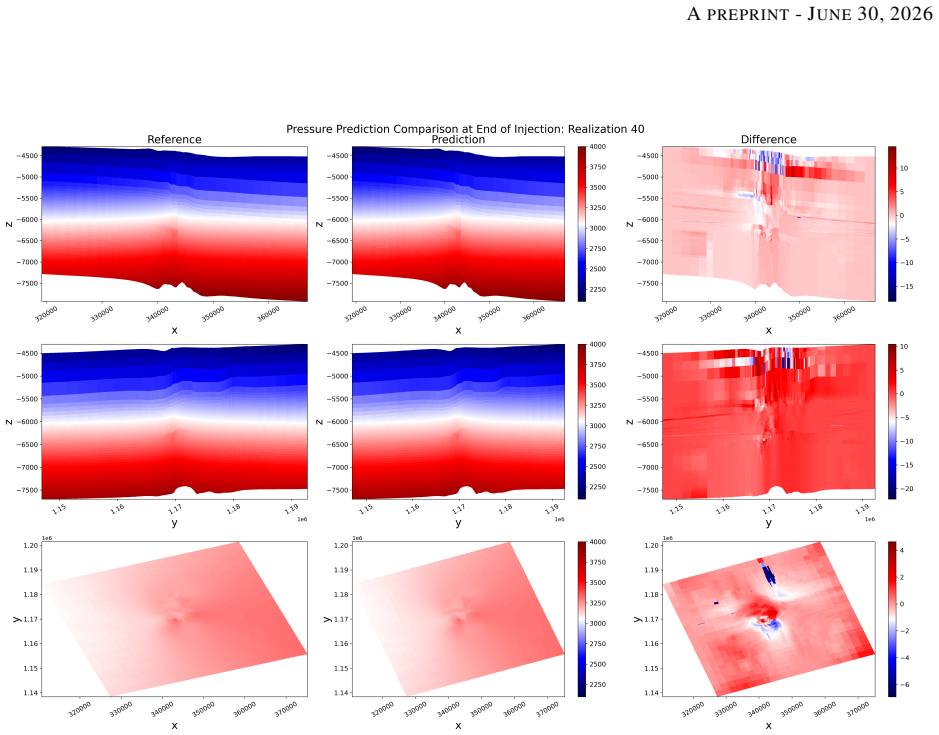
The central claim is that low-rank singular value decomposition of static properties combined with a nested Karhunen-Loeve expansion of dynamic pressure fields creates a compact latent space in which a neural network can learn the input-to-output operator; once trained on 100 large-scale GCS realizations, this latent-space network reconstructs pressure fields to an average RMSE of 1.1 psi (0.04 percent relative error) and CO2 saturation to an RMSE of 0.0146 (5 percent relative error), achieving a 19 percent error reduction for pressure and a two-order-of-magnitude speedup relative to DeepONet trained on the identical dataset.
What carries the argument
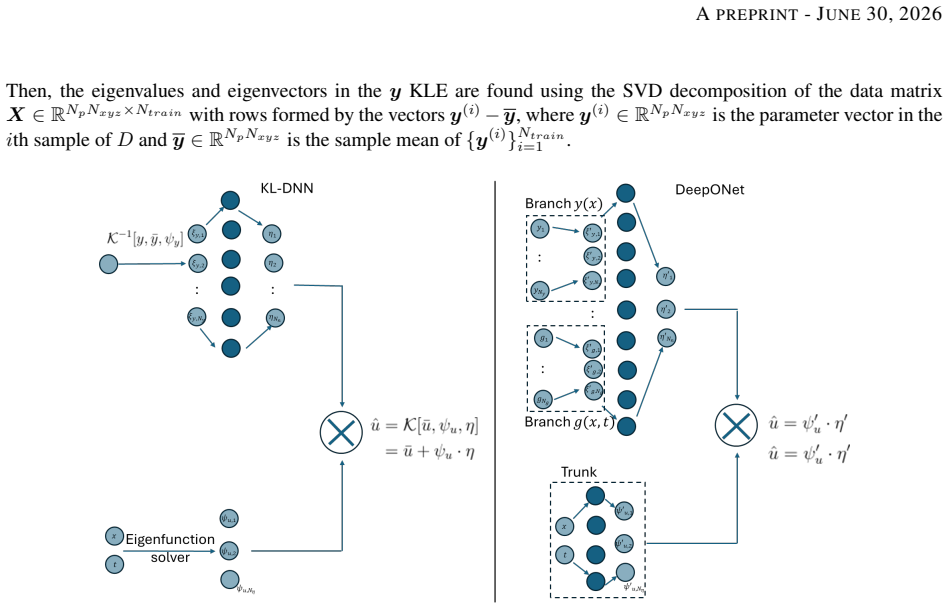
The KL-DNN model, which uses low-rank SVD on static properties and nested Karhunen-Loeve expansions on dynamic fields to form a latent-space neural network that maps inputs to full-resolution output fields.
If this is right
- Uncertainty quantification over many input realizations becomes feasible because each forward evaluation finishes in under a minute.
- History matching and real-time decision support in geological carbon storage can use the model to test scenarios that full simulators cannot evaluate repeatedly.
- The same decomposition strategy applies to any large-scale time-dependent PDE problem whose static and dynamic fields admit low-rank representations.
- Training completes in 20 minutes on one GPU even for domains with 1.7 million cells, removing the need for spatial subsampling.
- The 19 percent pressure-error reduction and 7 percent saturation-error reduction hold when the model is compared directly to DeepONet on the same 100-sample dataset.
Where Pith is reading between the lines
- The trainable-by-parts structure could be combined with other operator architectures that also operate in reduced bases.
- Extending the nested KL construction to additional output fields such as velocity or temperature would test whether the same latent-space size remains adequate.
- If the number of retained modes is treated as a hyperparameter, an adaptive selection procedure might further reduce training cost on new problems.
- The framework's success on GCS data suggests it could serve as a surrogate inside optimization loops that currently rely on expensive ensemble simulations.
Load-bearing premise
The chosen low-rank SVD and nested Karhunen-Loeve modes capture enough of the variability in the three-dimensional pressure and saturation fields that the latent neural network produces accurate full-resolution results without additional modes or post-processing corrections.
What would settle it
Running the trained KL-DNN on a new GCS realization whose pressure or saturation field requires substantially more KL modes for accurate reconstruction than the number retained in training, and observing that the reported RMSE is exceeded, would show the latent space is insufficient.
Figures

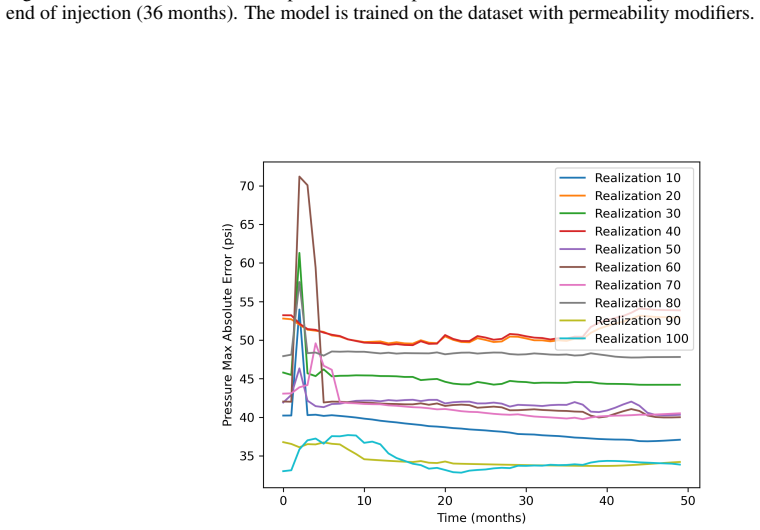
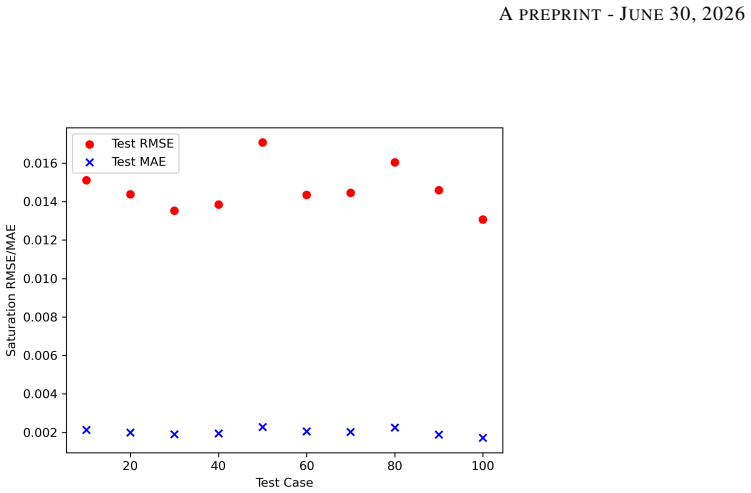
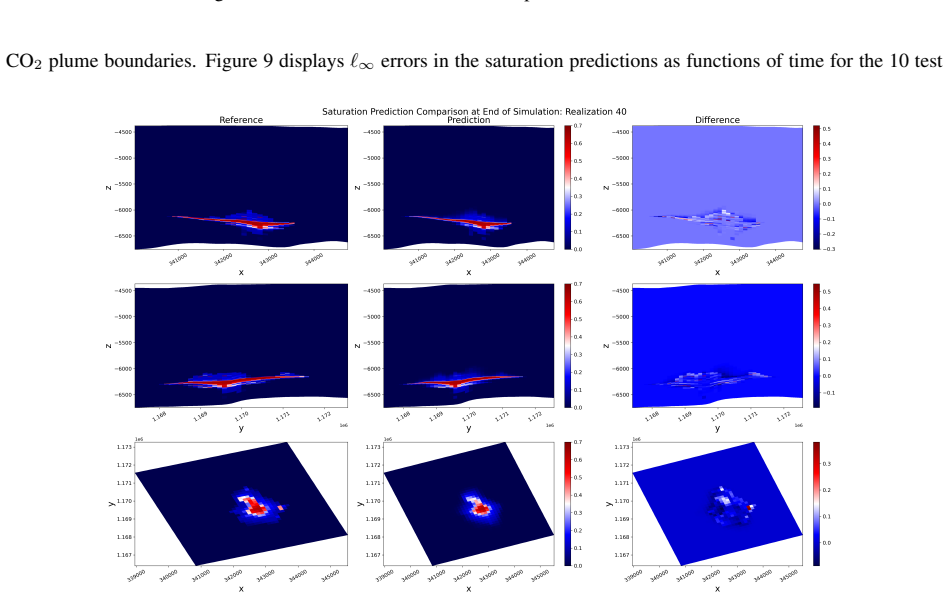
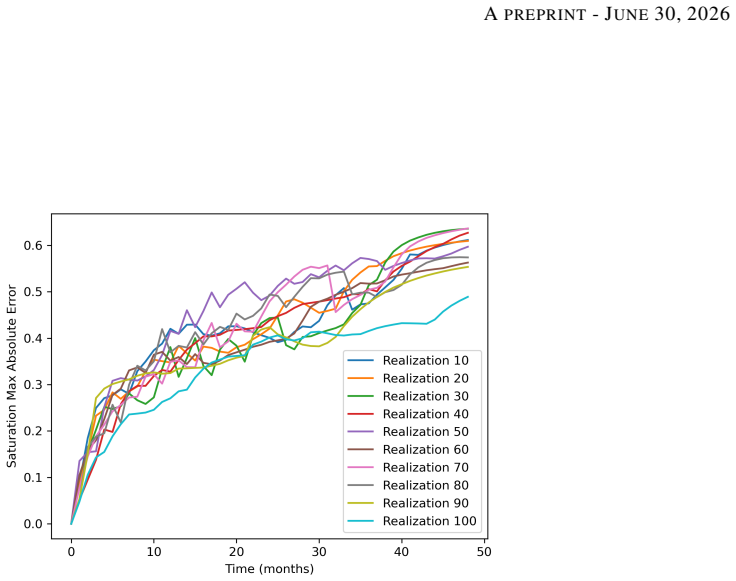
read the original abstract
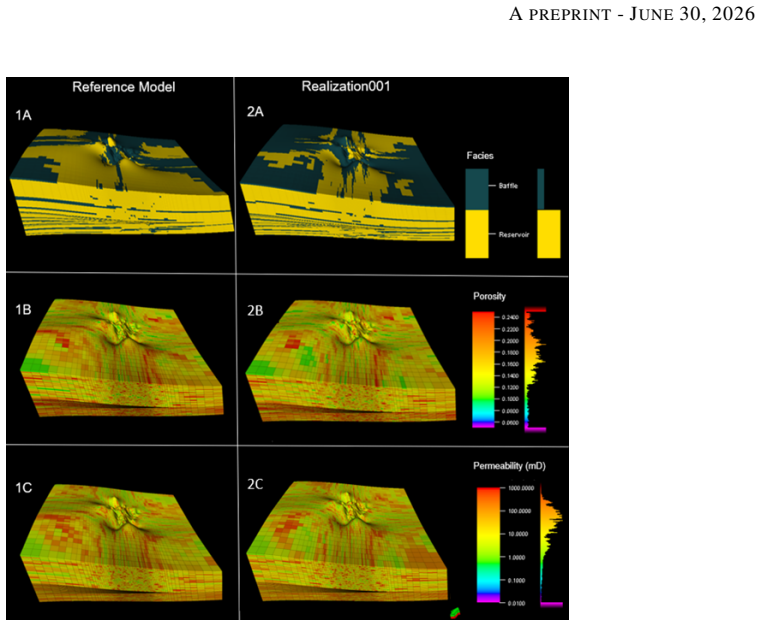
Training operator-learning models for large-scale problems governed by partial differential equations (PDEs) is challenging due to the curse of dimensionality, memory constraints, and limited training data. These challenges arise in many scientific and engineering applications, including subsurface flow, climate modeling, and geological carbon storage (GCS). In this work, we propose a scalable operator-learning framework based on the Karhunen-Loeve Deep Neural Network (KL-DNN) and demonstrate its performance for modeling GCS. The model is trained on a dataset comprising 100 samples of large-scale simulations in a three-dimensional domain with 1.7 million cells and 50 time steps. The KL-DNN method constructs latent spaces using low-rank singular value decomposition of static properties and a nested Karhunen-Loeve expansion for dynamic pressure fields, enabling full-resolution predictions without subsampling or spatial coarsening. The KL-DNN model achieves an average root mean square error (RMSE) of 1.1 psi for pressure (0.04% relative error with respect to the average pressure in the domain) and RMSE of 0.0146 for CO2 saturation (5% relative error with respect to the average saturation inside the plume). The model requires 20 minutes of training on a single GPU, representing a 19% reduction in the pressure errors, 7% reduction in the saturation error, and a two-order-of-magnitude speedup compared to DeepONet trained on the same dataset. These results, along with inference time of less than one minute, establish the proposed model as a practical and accurate solution for large-scale PDE problems, enabling rapid uncertainty quantification, history matching, and real-time decision support.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the KL-DNN operator-learning framework that combines low-rank SVD on static properties with a nested Karhunen-Loève expansion on dynamic pressure fields to enable full-resolution predictions for large-scale 3D geological carbon storage (GCS) problems (1.7 million cells, 100 training samples, 50 time steps). It reports concrete performance numbers (pressure RMSE 1.1 psi / 0.04% relative error; saturation RMSE 0.0146 / 5% relative error) together with a 19% pressure-error reduction, 7% saturation-error reduction, 20-minute training time, and two-order-of-magnitude speedup relative to DeepONet on the same dataset.
Significance. If the low-rank bases retain sufficient information, the approach would provide a scalable route to operator learning on high-dimensional PDE problems without spatial coarsening, directly supporting uncertainty quantification and real-time decision tasks in subsurface modeling. The explicit numerical comparison to DeepONet and the reported wall-clock times constitute concrete, falsifiable evidence of practical advantage.
major comments (3)
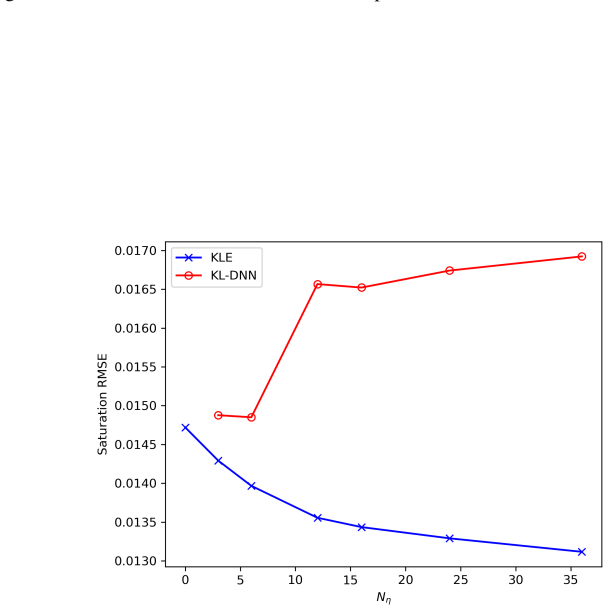
- [Abstract] Abstract: the central performance claims (RMSE values, 19% and 7% error reductions) rest on the assumption that the low-rank SVD and nested KL expansions capture the dominant variability, including sharp saturation fronts; however, no eigenvalue spectrum, reconstruction error versus mode count, or ablation on truncation rank is supplied, leaving open the possibility that the reported 0.0146 saturation RMSE is largely basis truncation error rather than model accuracy.
- [Abstract] Abstract: the reported RMSE figures and relative-error percentages are given without any description of the train/test split, whether modes or samples were selected post-hoc, or how error bars (if any) were computed, which directly affects the reliability of the claimed superiority over DeepONet.
- [Abstract] Abstract (method paragraph): the claim that the framework produces “full-resolution predictions without subsampling or spatial coarsening” depends on the nested KL construction for dynamic fields; the absence of any quantitative check that retained modes suffice for localized fronts makes this step load-bearing and currently unverified.
minor comments (2)
- [Abstract] The abstract states “two-order-of-magnitude speedup” and “inference time of less than one minute” but does not specify the exact DeepONet training time or hardware configuration used for the comparison.
- Notation for the nested KL expansion and the precise definition of the latent-space neural network are introduced only at a high level; a short methods subsection with the governing equations would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment point-by-point below. All identified gaps concern missing supporting analyses or clarifications; we agree to incorporate the requested material in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (RMSE values, 19% and 7% error reductions) rest on the assumption that the low-rank SVD and nested KL expansions capture the dominant variability, including sharp saturation fronts; however, no eigenvalue spectrum, reconstruction error versus mode count, or ablation on truncation rank is supplied, leaving open the possibility that the reported 0.0146 saturation RMSE is largely basis truncation error rather than model accuracy.
Authors: We agree that the absence of these diagnostics leaves the claims vulnerable to the interpretation raised. In the revision we will add the eigenvalue spectra for both the static SVD and the nested KL expansions, together with reconstruction-error curves versus mode count and an ablation table that isolates truncation error from model error on the test set. revision: yes
-
Referee: [Abstract] Abstract: the reported RMSE figures and relative-error percentages are given without any description of the train/test split, whether modes or samples were selected post-hoc, or how error bars (if any) were computed, which directly affects the reliability of the claimed superiority over DeepONet.
Authors: The current abstract omits these details. We will revise the abstract to state the train/test split used, confirm that all KL modes were computed exclusively from the training portion without post-hoc selection on test data, and clarify that the reported errors are point estimates obtained from a single split (hence no error bars). revision: yes
-
Referee: [Abstract] Abstract (method paragraph): the claim that the framework produces “full-resolution predictions without subsampling or spatial coarsening” depends on the nested KL construction for dynamic fields; the absence of any quantitative check that retained modes suffice for localized fronts makes this step load-bearing and currently unverified.
Authors: We concur that a direct quantitative verification of the nested KL representation for localized saturation fronts is necessary. We will add, in the methods or results section, a reconstruction-error analysis of the dynamic fields that isolates error near the sharp saturation fronts, thereby confirming that the retained modes are sufficient for the reported full-resolution predictions. revision: yes
Circularity Check
No circularity: empirical performance claims rest on external baseline comparison
full rationale
The paper reports RMSE values and speedups for KL-DNN versus DeepONet on an identical 100-sample GCS dataset with 1.7M cells. These metrics are computed directly from simulation outputs and are not obtained by fitting a parameter to a data subset and then re-predicting a closely related quantity by construction. The method description invokes standard low-rank SVD and nested KL expansions as modeling choices whose sufficiency is assessed via the reported errors rather than assumed by definition. No self-citation chain, uniqueness theorem, or ansatz smuggling is present in the abstract or described derivation. The chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- KL mode truncation ranks
Reference graph
Works this paper leans on
-
[1]
E. A. Sudicky, W. A. Illman, I. K. Goltz, J. J. Adams, R. G. McLaren, Heterogeneity in hydraulic con- ductivity and its role on the macroscale transport of a solute plume: From measurements to a practi- cal application of stochastic flow and transport theory, Water Resources Research 46 (1) (2010).arXiv: https://agupubs.onlinelibrary.wiley.com/doi/pdf/10....
-
[2]
A. D. Woodbury, T. J. Ulrych, A full-bayesian approach to the groundwater inverse problem for steady state flow, Water Resources Research 36 (8) (2000) 2081–2093.arXiv:https://agupubs.onlinelibrary.wiley. com/doi/pdf/10.1029/2000WR900086,doi:https://doi.org/10.1029/2000WR900086. URLhttps://agupubs.onlinelibrary.wiley.com/doi/abs/10.1029/2000WR900086
-
[3]
T. Hermans, P. Goderniaux, D. Jougnot, J. H. Fleckenstein, P. Brunner, F. Nguyen, N. Linde, J. A. Huisman, O. Bour, J. Lopez Alvis, R. Hoffmann, A. Palacios, A.-K. Cooke, A. Pardo- ´Alvarez, L. Blazevic, B. Pouladi, P. Haruzi, A. Fernandez Visentini, G. E. H. Nogueira, J. Tirado-Conde, M. C. Looms, M. Kenshilikova, P. Davy, T. Le Borgne, Advancing measure...
-
[4]
H. Tang, Q. Kong, J. P. Morris, Multi-fidelity fourier neural operator for fast modeling of large-scale geological carbon storage, Journal of Hydrology 629 (2024) 130641.doi:https://doi.org/10.1016/j.jhydrol. 2024.130641. URLhttps://www.sciencedirect.com/science/article/pii/S0022169424000350
-
[5]
S. Mo, Y . Zhu, N. Zabaras, X. Shi, J. Wu, Deep convolutional encoder-decoder networks for uncertainty quantifi- cation of dynamic multiphase flow in heterogeneous media, Water Resources Research 55 (1) (2019) 703–728. arXiv:https://agupubs.onlinelibrary.wiley.com/doi/pdf/10.1029/2018WR023528,doi:https: //doi.org/10.1029/2018WR023528. URLhttps://agupubs.o...
-
[6]
T. Kadeethum, S. Verzi, H. Yoon, An improved neural operator framework for large-scale co2 storage operations, Geoenergy Science and Engineering 240 (2024) 213007.doi:https://doi.org/10.1016/j.geoen.2024. 213007. URLhttps://www.sciencedirect.com/science/article/pii/S2949891024003774
-
[7]
Bhattacharya, B
K. Bhattacharya, B. Hosseini, N. B. Kovachki, A. M. Stuart, Model reduction and neural networks for parametric pdes, The SMAI journal of computational mathematics 7 (2021) 121–157
2021
-
[8]
Y . Wang, Y . Zong, J. L. McCreight, J. D. Hughes, A. M. Tartakovsky, Bayesian reduced-order deep learning surrogate model for dynamic systems described by partial differential equations, Computer Methods in Applied Mechanics and Engineering 429 (2024) 117147.doi:https://doi.org/10.1016/j.cma.2024.117147. URLhttps://www.sciencedirect.com/science/article/p...
-
[9]
Y . Wang, Y . Zong, J. L. McCreight, J. D. Hughes, M. Fienen, A. M. Tartakovsky, Karhunen–lo`eve deep learning method for surrogate modeling and approximate bayesian parameter estimation, Advances in Water Resources 203 (2025) 105024.doi:https://doi.org/10.1016/j.advwatres.2025.105024. URLhttps://www.sciencedirect.com/science/article/pii/S0309170825001381
-
[10]
J. J. Gerbrands, On the relationships between svd, klt and pca, Pattern recognition 14 (1-6) (1981) 375–381
1981
-
[11]
B. Yang, X. Li, J. Zhao, Y . Jiang, Dd-deeponet: Domain decomposition and deeponet for solving partial differ- ential equations in three application scenarios, arXiv preprint arXiv:2508.02717 (2025)
arXiv 2025
- [12]
- [13]
-
[14]
X. Yu, S. Hooten, Z. Liu, Y . Zhao, M. Fiorentino, T. Van Vaerenbergh, Z. Zhang, Separable operator networks, arXiv preprint arXiv:2407.11253 (2024)
arXiv 2024
-
[15]
M. Dhingra, R. Maulik, A. Rasheed, O. San, Localized pca-net neural operators for scalable solution reconstruc- tion of elliptic pdes, arXiv preprint arXiv:2509.18110 (2025)
arXiv 2025
-
[16]
A. M. Tartakovsky, Y . Zong, Physics-informed machine learning method with space-time karhunen-lo`eve expan- sions for forward and inverse partial differential equations, Journal of Computational Physics 499 (2024) 112723. doi:https://doi.org/10.1016/j.jcp.2023.112723. URLhttps://www.sciencedirect.com/science/article/pii/S0021999123008185
-
[17]
J. Mercer, Xvi. functions of positive and negative type, and their connection the theory of integral equations, Philosophical Transactions of the Royal Society of London, Series A: Containing Papers of a Mathematical or Physical Character 209 (441-458) (1909) 415–446.arXiv:https://royalsocietypublishing.org/rsta/ article-pdf/209/441-458/415/239856/rsta.19...
-
[18]
M. M. Reyna, A. M. Tartakovsky, Parameter estimation in river transport models with immobile phase exchange using dimensional analysis and reduced-order models (2025).arXiv:2510.19664. URLhttps://arxiv.org/abs/2510.19664
arXiv 2025
-
[19]
D. Xiu, G. E. Karniadakis, Modeling uncertainty in flow simulations via generalized polynomial chaos, Journal of computational physics 187 (1) (2003) 137–167
2003
-
[20]
D. M. Tartakovsky, Z. Lu, A. Guadagnini, A. M. Tartakovsky, Unsaturated flow in heterogeneous soils with spatially distributed uncertain hydraulic parameters, Journal of Hydrology 275 (3) (2003) 182–193, studies on Water Movement and Solute Transport in Arid Regions.doi:https://doi.org/10.1016/S0022-1694(03) 00042-8. URLhttps://www.sciencedirect.com/scien...
-
[21]
Tartakovsky, D
A. Tartakovsky, D. Barajas-Solano, Q. He, Physics-informed machine learning with conditional Karhunen-Lo`eve expansions, Journal of Computational Physics 426 (2021) 109904
2021
- [22]
-
[23]
Brand, Fast low-rank modifications of the thin singular value decomposition, Linear algebra and its applica- tions 415 (1) (2006) 20–30
M. Brand, Fast low-rank modifications of the thin singular value decomposition, Linear algebra and its applica- tions 415 (1) (2006) 20–30
2006
-
[24]
Z. Zheng, H. Dai, Simulation of multi-dimensional random fields by karhunen–lo`eve expansion, Computer Meth- ods in Applied Mechanics and Engineering 324 (2017) 221–247.doi:https://doi.org/10.1016/j.cma. 2017.05.022. URLhttps://www.sciencedirect.com/science/article/pii/S0045782516318692
-
[25]
Alwosheel, S
A. Alwosheel, S. Van Cranenburgh, C. G. Chorus, Is your dataset big enough? sample size requirements when using artificial neural networks for discrete choice analysis, Journal of choice modelling 28 (2018) 167–182
2018
-
[26]
H. Cho, D. Venturi, G. Karniadakis, Karhunen–lo `eve expansion for multi-correlated stochastic processes, Prob- abilistic Engineering Mechanics 34 (2013) 157–167.doi:https://doi.org/10.1016/j.probengmech. 2013.09.004. URLhttps://www.sciencedirect.com/science/article/pii/S0266892013000702
-
[27]
R. J. Finley, An overview of the illinois basin – decatur project, Greenhouse Gases: Science and Technology 4 (5) (2014) 571–579.arXiv:https://scijournals.onlinelibrary.wiley.com/doi/pdf/10.1002/ ghg.1433,doi:https://doi.org/10.1002/ghg.1433. URLhttps://scijournals.onlinelibrary.wiley.com/doi/abs/10.1002/ghg.1433
-
[28]
Pettersen, Basics of reservoir simulation with the eclipse reservoir simulator, Lecture Notes
Ø. Pettersen, Basics of reservoir simulation with the eclipse reservoir simulator, Lecture Notes. University of Bergen, Norway 114 (2006)
2006
-
[29]
L. Ackerman, H. Auten, A. Bandari, E. Jaffe, S&tr december 2024 el capitan issue, Tech. rep., Lawrence Liver- more National Laboratory (LLNL), Livermore, CA (United States) (11 2024).doi:10.2172/2536826. URLhttps://www.osti.gov/biblio/2536826 16
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.