Unlocking Model Potentials Through Adaptive Multi-Agent Scaffolding for Efficient Issue Resolution
Pith reviewed 2026-06-25 20:12 UTC · model grok-4.3
The pith
A decentralized multi-agent scaffold with event-based messaging and rubric-based branching outperforms baselines on SWE-bench using identical models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
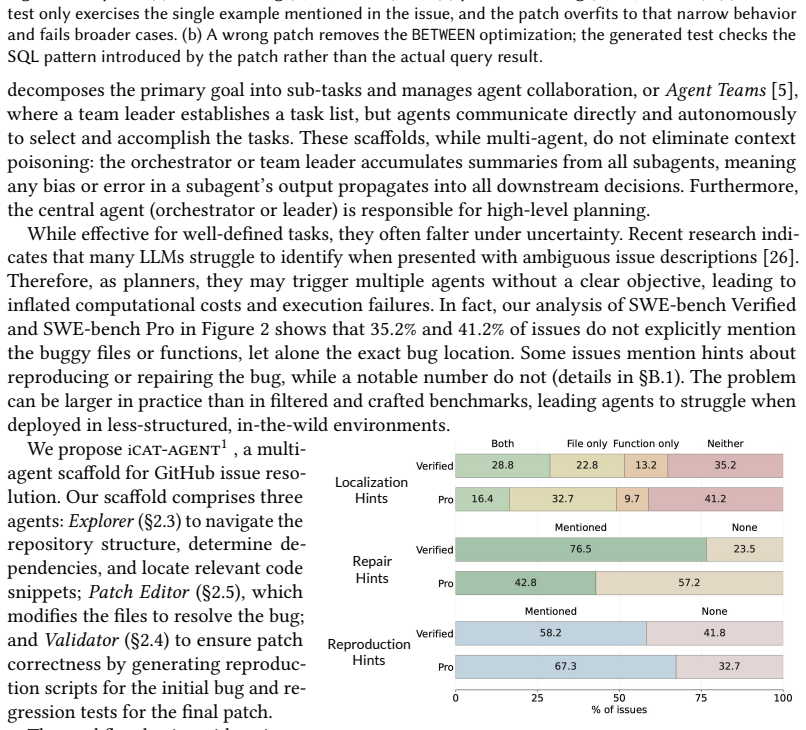
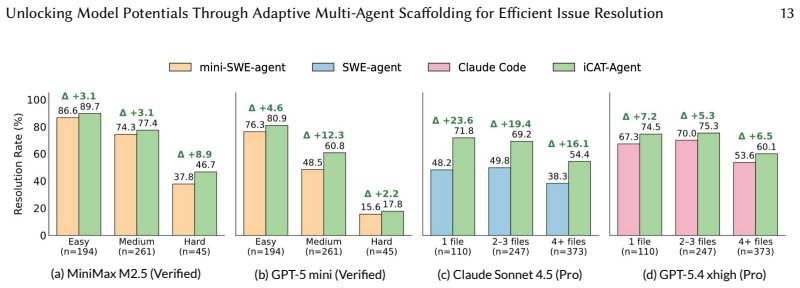
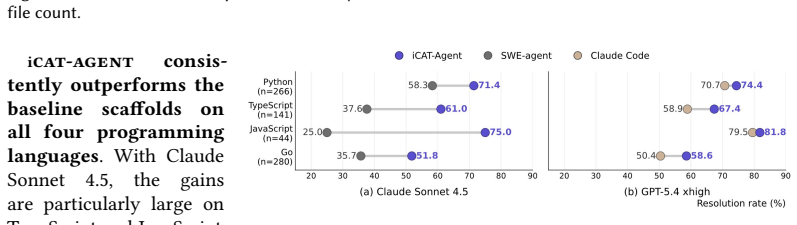
icat-agent is a decentralized multi-agent scaffolding that replaces shared context with synchronous, event-based message passing and uses a rubric-based issue quality check to pivot its workflow: parallel patching and validation for well-defined issues, or preliminary exploration for low-quality ones. On SWE-bench Verified and SWE-bench Pro it outperforms baselines including SWE-agent, mini-SWE-agent, and Claude Code while using the same models, with gains of 3.6-8.4 percent and 6.3-18.5 percent respectively, and reduces average cost by $1.18 per instance. The same backbone resolves markedly more issues under icat-agent than under existing scaffolds, reaching 67.4 percent on SWE-bench Pro.
What carries the argument
icat-agent's decentralized scaffolding that substitutes shared context with synchronous event-based message passing and applies rubric-based quality classification to adapt between patching and exploration workflows.
If this is right
- icat-agent raises resolution rates by 3.6-8.4% on SWE-bench Verified and 6.3-18.5% on SWE-bench Pro across all difficulty levels compared with baselines using identical models.
- Average cost per instance drops by $1.18 relative to the multi-agent Claude Code baseline.
- With GPT-5.4-xhigh the scaffold reaches 67.4% on SWE-bench Pro, 8.3 points above the prior best result.
- The same model backbone solves substantially more issues under icat-agent than under existing scaffolds.
Where Pith is reading between the lines
- Event-based messaging patterns may reduce context loss in multi-agent systems applied to domains beyond software repair, such as automated scientific hypothesis testing.
- Varying the rubric criteria or adding learned quality predictors could refine branching decisions for specific issue distributions.
- The observed cost reduction suggests the approach could scale to repositories larger than those in current benchmarks without linear growth in expense.
Load-bearing premise
The rubric-based issue quality check reliably classifies issues to select the correct workflow branch and synchronous event-based message passing prevents context degradation and poisoning more effectively than shared context.
What would settle it
Replace the rubric check with random branching or swap event-based messaging for shared context on the same SWE-bench instances and measure whether the reported performance margins over baselines disappear.
Figures







read the original abstract
Resolving issues with ambiguous and incomplete descriptions, particularly concerning complex bugs, requires a sophisticated, long-horizon workflow. Agents must navigate codebases to locate the root cause, reproduce the failure, implement a fix, and validate the resulting patch. Inefficient context management, thereby, can lead to rapid context degradation and context poisoning, preventing successful resolution. We propose icat-agent, a decentralized, multi-agent scaffolding that replaces shared context with synchronous, event-based message passing. Utilizing a rubric-based issue quality check, icat-agent strategically pivots its workflow: it initiates parallel patching and validation for well-defined issues, while deploying preliminary exploration for low-quality ones. A comprehensive evaluation of icat-agent on SWE-bench Verified and SWE-bench Pro demonstrates that it consistently outperforms prominent baselines across all difficulty levels, including SWE-agent, mini-SWE-agent, and Claude Code, while using the same underlying models, improving by 3.6-8.4% on SWE-bench Verified and 6.3-18.5% on SWE-bench Pro. icat-agent is also computationally efficient, reducing the average cost by $1.18 per instance compared with the multi-agent Claude Code baseline. Our findings reveal that a robust scaffold such as icat-agent unlocks substantial latent capability within a fixed model, with the same backbone resolving markedly more issues under icat-agent than under existing scaffolds. icat-agent +GPT-5.4-xhigh resolves 67.4% of SWE-bench Pro problems, outperforming the current best result on SWE-bench Pro (59.10%, mini-SWE-agent+GPT-5.4-xhigh) by 8.3 percentage points.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces icat-agent, a decentralized multi-agent scaffolding for software issue resolution that replaces shared context with synchronous event-based message passing and uses a rubric-based issue quality classifier to adaptively branch: parallel patching/validation for well-defined issues versus preliminary exploration for low-quality ones. It reports consistent outperformance over SWE-agent, mini-SWE-agent, and Claude Code (same underlying models) on SWE-bench Verified (+3.6–8.4%) and SWE-bench Pro (+6.3–18.5%), plus cost reduction ($1.18/instance vs. Claude Code) and a new SOTA of 67.4% on Pro with GPT-5.4-xhigh.
Significance. If the performance deltas are robustly attributable to the adaptive scaffolding rather than unablated factors, the result would indicate that carefully designed multi-agent workflows can unlock substantial latent capability in fixed LLMs on long-horizon software engineering tasks, with direct implications for agentic systems in SE.
major comments (3)
- [§3.2] §3.2 (Rubric-based Issue Quality Check): The manuscript defines the rubric and the pivot logic but reports no quantitative validation—no accuracy/precision/recall on a labeled SWE-bench subset, no inter-annotator agreement, and no error analysis of misclassifications. Because the claimed gains rest on the classifier correctly triggering the appropriate branch, this omission prevents attribution of the 3.6–18.5% improvements to the adaptive mechanism.
- [§5] §5 (Experimental Evaluation): The results section presents aggregate percentage improvements and a cost comparison but supplies no statistical significance tests, confidence intervals, per-difficulty breakdowns with error bars, or ablation studies isolating the contribution of event-based messaging versus the quality-check pivot versus other design choices.
- [§4.1] §4.1 (Message Passing Design): The claim that synchronous event-based passing “sufficiently prevents context degradation and poisoning” is asserted without supporting measurements (e.g., context-length traces, poisoning incident rates, or comparison against shared-context baselines under identical model settings).
minor comments (2)
- [Table 1] Table 1 and Figure 3: axis labels and legend entries use inconsistent model shorthand (e.g., “GPT-5.4-xhigh” vs. “Claude-3.5”) that should be standardized for readability.
- [§2] §2 (Related Work): The discussion of prior multi-agent scaffolds omits recent SWE-bench-specific ablations on context management; adding 2–3 targeted citations would strengthen positioning.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each of the major comments below, indicating the revisions we plan to make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Rubric-based Issue Quality Check): The manuscript defines the rubric and the pivot logic but reports no quantitative validation—no accuracy/precision/recall on a labeled SWE-bench subset, no inter-annotator agreement, and no error analysis of misclassifications. Because the claimed gains rest on the classifier correctly triggering the appropriate branch, this omission prevents attribution of the 3.6–18.5% improvements to the adaptive mechanism.
Authors: We agree that quantitative validation is necessary to robustly attribute the gains to the adaptive mechanism. In the revised manuscript, we will add a dedicated evaluation of the issue quality classifier on a labeled subset of SWE-bench, including accuracy, precision, recall, inter-annotator agreement metrics, and error analysis of any misclassifications. revision: yes
-
Referee: [§5] §5 (Experimental Evaluation): The results section presents aggregate percentage improvements and a cost comparison but supplies no statistical significance tests, confidence intervals, per-difficulty breakdowns with error bars, or ablation studies isolating the contribution of event-based messaging versus the quality-check pivot versus other design choices.
Authors: The current manuscript focuses on aggregate results, but we acknowledge the value of additional statistical rigor and component analysis. We will revise §5 to include statistical significance tests, confidence intervals, per-difficulty breakdowns with error bars, and ablation studies for the key design choices including event-based messaging and the quality-check pivot. revision: yes
-
Referee: [§4.1] §4.1 (Message Passing Design): The claim that synchronous event-based passing “sufficiently prevents context degradation and poisoning” is asserted without supporting measurements (e.g., context-length traces, poisoning incident rates, or comparison against shared-context baselines under identical model settings).
Authors: We will strengthen this section by adding supporting measurements such as context-length traces during execution, observed poisoning incident rates, and more detailed comparisons to shared-context approaches under matched conditions. This will be included in the revised version to better substantiate the design choice. revision: yes
Circularity Check
No circularity; claims rest on direct empirical benchmark comparisons
full rationale
The manuscript advances an empirical claim that icat-agent outperforms named baselines (SWE-agent, mini-SWE-agent, Claude Code) on SWE-bench Verified and Pro by measured percentages, using identical underlying models. No derivation chain, equations, fitted parameters renamed as predictions, or self-citations are invoked to support the performance deltas; the results are presented as outcomes of controlled experiments. The rubric-based classifier is described as a design choice whose accuracy is not quantified in the provided text, but this is an evidence gap rather than a circular reduction. The central result therefore remains self-contained against external benchmarks and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
https://tree-sitter.github.io/tree-sitter/
Tree-sitter. https://tree-sitter.github.io/tree-sitter/
-
[2]
Toufique Ahmed, Martin Hirzel, Rangeet Pan, Avraham Shinnar, and Saurabh Sinha. Tdd-bench verified: Can llms generate tests for issues before they get resolved?arXiv preprint arXiv:2412.02883, 2024
arXiv 2024
-
[3]
Otter: Generating tests from issues to validate swe patches.ICML, 2025
Toufique Ahmed, Jatin Ganhotra, Rangeet Pan, Avraham Shinnar, Saurabh Sinha, and Martin Hirzel. Otter: Generating tests from issues to validate swe patches.ICML, 2025
2025
-
[4]
Claude Sonnet 4.5 system card
Anthropic. Claude Sonnet 4.5 system card. Technical report, Anthropic, September 2025. URL https://www.anthropic. com/claude-sonnet-4-5-system-card
2025
-
[5]
Anthropic agent teams
Anthropic. Anthropic agent teams. https://code.claude.com/docs/en/agent-teams, 2026
2026
-
[6]
MASAI: Modular architecture for software-engineering AI agents
Daman Arora, Atharv Sonwane, Nalin Wadhwa, Abhav Mehrotra, Saiteja Utpala, Ramakrishna Bairi, Aditya Kanade, and Nagarajan Natarajan. MASAI: Modular architecture for software-engineering AI agents. InNeurIPS 2024 Workshop on Open-World Agents (OW A), 2024
2024
-
[7]
URL https://github.com/Intelligent-CAT-Lab/icat-agent
Artifact, 2026. URL https://github.com/Intelligent-CAT-Lab/icat-agent
2026
-
[8]
Ibragim Badertdinov, Alexander Golubev, Maksim Nekrashevich, Anton Shevtsov, Simon Karasik, Andrei An- driushchenko, Maria Trofimova, Daria Litvintseva, and Boris Yangel. Swe-rebench: An automated pipeline for task collection and decontaminated evaluation of software engineering agents, 2025. URL https://arxiv.org/abs/2505.20411
arXiv 2025
-
[9]
CodeR: Issue resolving with multi-agent and task graphs.arXiv preprint arXiv:2406.01304, 2024
Dong Chen, Shaoxin Lin, Muhan Zeng, Daoguang Zan, Jian-Gang Wang, Anton Cheshkov, Jun Sun, Hao Yu, Guoliang Dong, Artem Aliev, et al. CodeR: Issue resolving with multi-agent and task graphs.arXiv preprint arXiv:2406.01304, 2024
arXiv 2024
-
[10]
Can old tests do new tricks for resolving swe issues?, 2026
Yang Chen, Toufique Ahmed, Reyhaneh Jabbarvand, and Martin Hirzel. Can old tests do new tricks for resolving swe issues?, 2026
2026
-
[11]
Jimenez, John Yang, Leyton Ho, Tejal Patwardhan, Kevin Liu, and Aleksander Madry
Neil Chowdhury, James Aung, Chan Jun Shern, Oliver Jaffe, Dane Sherburn, Giulio Starace, Evan Mays, Rachel Dias, Marwan Aljubeh, Mia Glaese, Carlos E. Jimenez, John Yang, Leyton Ho, Tejal Patwardhan, Kevin Liu, and Aleksander Madry. Introducing SWE-bench verified. OpenAI, 2024. URL https://openai.com/index/introducing-swe-bench- verified/
2024
-
[12]
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, Karmini Sampath, Maya Krishnan, Srivatsa Kundurthy, Sean Hendryx, Zifan Wang, Vijay Bharadwaj, , Vol. 1, No. 1, Article . Publication date: June 2026. Unlocking Model Potentials Through Adaptive Multi-Agent Scaffolding for Eff...
Pith/arXiv arXiv 2026
-
[13]
Metagpt: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. Metagpt: Meta programming for a multi-agent collaborative framework. InInternational Conference on Learning Representations, 2024
2024
-
[14]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. Swe-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations (ICLR), 2024
2024
-
[15]
Langgraph
LangChain. Langgraph. https://github.com/langchain-ai/langgraph, 2026
2026
-
[16]
Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12: 157–173, 2024
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12: 157–173, 2024
2024
-
[17]
https://www.minimax.io/news/minimax-m25, 2026
MiniMax. https://www.minimax.io/news/minimax-m25, 2026
2026
-
[18]
Swt-bench: Testing and validating real-world bug-fixes with code agents.Advances in Neural Information Processing Systems, 37:81857–81887, 2024
Niels Mündler, Mark N Müller, Jingxuan He, and Martin Vechev. Swt-bench: Testing and validating real-world bug-fixes with code agents.Advances in Neural Information Processing Systems, 37:81857–81887, 2024
2024
-
[19]
GPT-5 system card
OpenAI. GPT-5 system card. https://openai.com/index/gpt-5-system-card/, 2025. Accessed: 2026-05-01
2025
-
[20]
GPT-5.4 system card
OpenAI. GPT-5.4 system card. https://openai.com/index/introducing-gpt-5-4/, 2025
2025
-
[21]
Huy Nhat Phan, Phong X. Nguyen, and Nghi D. Q. Bui. HyperAgent: Generalist software engineering agents to solve coding tasks at scale.arXiv preprint arXiv:2409.16299, 2024
arXiv 2024
-
[22]
(2024) Chatdev: Communicative agents for software development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. Chatdev: Communicative agents for software development. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15174–15186. As...
-
[23]
Swe-polybench: A multi-language benchmark for repository level evaluation of coding agents, 2025
Muhammad Shihab Rashid, Christian Bock, Yuan Zhuang, Alexander Buchholz, Tim Esler, Simon Valentin, Luca Franceschi, Martin Wistuba, Prabhu Teja Sivaprasad, Woo Jung Kim, Anoop Deoras, Giovanni Zappella, and Laurent Callot. Swe-polybench: A multi-language benchmark for repository level evaluation of coding agents, 2025. URL https://arxiv.org/abs/2504.08703
arXiv 2025
-
[24]
Mini-SWE-Agent: A minimal agent scaffold for software engineering
SWE-Agent Team. Mini-SWE-Agent: A minimal agent scaffold for software engineering. https://github.com/SWE- agent/mini-swe-agent, 2025
2025
-
[25]
Context rot: Why ai gets worse the longer you chat
Teresa Torres. Context rot: Why ai gets worse the longer you chat. https://www.producttalk.org/context-rot/, 2026
2026
-
[26]
Ambig-swe: Interactive agents to overcome underspecificity in software engineering
Sanidhya Vijayvargiya, Xuhui Zhou, Akhila Yerukola, Maarten Sap, and Graham Neubig. Ambig-swe: Interactive agents to overcome underspecificity in software engineering. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[27]
How we broke top ai agent benchmarks: And what comes next
Hao Wang, Qiuyang Mang, Alvin Cheung, Koushik Sen, and Dawn Song. How we broke top ai agent benchmarks: And what comes next. https://rdi.berkeley.edu/blog/trustworthy-benchmarks-cont, 2026
2026
-
[28]
Aegis: An agent-based framework for bug reproduction from issue descriptions
Xinchen Wang, Pengfei Gao, Xiangxin Meng, Chao Peng, Ruida Hu, Yun Lin, and Cuiyun Gao. Aegis: An agent-based framework for bug reproduction from issue descriptions. InProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering, pages 331–342, 2025
2025
-
[29]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. OpenHands: An open platform for AI software developers as generalist agents. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[30]
The long-horizon task mirage? diagnosing where and why agentic systems break
Xinyu Jessica Wang, Haoyue Bai, Yiyou Sun, Haorui Wang, Shuibai Zhang, Wenjie Hu, Mya Schroder, Bilge Mutlu, Dawn Song, and Robert D Nowak. The long-horizon task mirage? diagnosing where and why agentic systems break. arXiv preprint arXiv:2604.11978, 2026
Pith/arXiv arXiv 2026
-
[31]
Live-swe-agent: Can software engineering agents self-evolve on the fly?, 2025
Chunqiu Steven Xia, Zhe Wang, Yan Yang, Yuxiang Wei, and Lingming Zhang. Live-swe-agent: Can software engineering agents self-evolve on the fly?, 2025. URL https://arxiv.org/abs/2511.13646
arXiv 2025
-
[32]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. SWE-Agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
2024
-
[33]
John Yang, Carlos E. Jimenez, Alex L. Zhang, Kilian Lieret, Joyce Yang, Xindi Wu, Ori Press, Niklas Muennighoff, Gabriel Synnaeve, Karthik R. Narasimhan, Diyi Yang, Sida I. Wang, and Ofir Press. Swe-bench multimodal: Do ai systems generalize to visual software domains?, 2024. URL https://arxiv.org/abs/2410.03859
arXiv 2024
-
[34]
Multi-swe-bench: A multilingual benchmark for issue resolving, 2025
Daoguang Zan, Zhirong Huang, Wei Liu, Hanwu Chen, Linhao Zhang, Shulin Xin, Lu Chen, Qi Liu, Xiaojian Zhong, Aoyan Li, Siyao Liu, Yongsheng Xiao, Liangqiang Chen, Yuyu Zhang, Jing Su, Tianyu Liu, Rui Long, Kai Shen, and Liang Xiang. Multi-swe-bench: A multilingual benchmark for issue resolving, 2025. URL https://arxiv.org/abs/2504.02605. , Vol. 1, No. 1, ...
Pith/arXiv arXiv 2025
-
[35]
Swe-bench goes live!Neurips 2025, 2025
Linghao Zhang, Shilin He, Chaoyun Zhang, Yu Kang, Bowen Li, Chengxing Xie, Junhao Wang, Maoquan Wang, Yufan Huang, Shengyu Fu, Elsie Nallipogu, Qingwei Lin, Yingnong Dang, Saravan Rajmohan, and Dongmei Zhang. Swe-bench goes live!Neurips 2025, 2025
2025
-
[36]
Linghao Zhang, Shilin He, Chaoyun Zhang, Yu Kang, Bowen Li, Chengxing Xie, Junhao Wang, Maoquan Wang, Yufan Huang, Shengyu Fu, Elsie Nallipogu, Qingwei Lin, Yingnong Dang, Saravan Rajmohan, and Dongmei Zhang. Swe-bench goes live!, 2025. URL https://arxiv.org/abs/2505.23419
arXiv 2025
-
[37]
AutoCodeRover: Autonomous program im- provement
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. AutoCodeRover: Autonomous program im- provement. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA),
-
[38]
doi: 10.1145/3650212.3680384. , Vol. 1, No. 1, Article . Publication date: June 2026. Unlocking Model Potentials Through Adaptive Multi-Agent Scaffolding for Efficient Issue Resolution 21 A Details of Implementations A.1 Details of Tools In this section, we discuss the details of the tools designed and used in the icat-agent. icat-agent implements a set o...
-
[39]
Do not only inspect the function mentioned in the plan
Trace the full code path before editing. Do not only inspect the function mentioned in the plan. - Use trace_call_chain() to find callers and callees. - Read the metaclass, factory, base class, or option parser if involved. - Understand how the value flows from definition to processing to usage
-
[40]
Do not edit test files
Modify source code only. Do not edit test files
-
[41]
Think about edge cases and edit multiple files if needed
-
[42]
Ensure each edit affects only the intended code region
-
[43]
patch_generated
When the patch is ready, call: share_findings("patch_generated", "<description>")
-
[44]
## Inter-agent Communication - Reproducer findings provide reproduction behavior and validation results
If validation fails, revise the patch and share a new patch_generated finding. ## Inter-agent Communication - Reproducer findings provide reproduction behavior and validation results. - If validation fails, reflect on the feedback and revise the patch. - Do not declare completion until the reproducer confirms that all tests pass. - Carefully decide what t...
2026
-
[45]
- Search broadly for tests in the affected module or package
Identify and run existing regression tests related to the issue. - Search broadly for tests in the affected module or package. - Run the affected package's test suite, not only individual tests. - Register regression tests and run them before any fix. - Share baseline results with the other agents
-
[46]
bug_confirmed
Write and run a comprehensive reproduction script. - Use existing tests to learn setup patterns. - Test each scenario separately. - Each scenario must have its own assertion and failure message. - Avoid combining configurations in one test, because this can mask bugs. - When the bug is reproduced, call: share_findings("bug_confirmed", "<details>")
-
[47]
Wait for the patch editor's fix and call apply_patch() to apply it
-
[48]
Thoroughly validate the patch. a. First check that the patched code compiles or passes a smoke test. b. Re-run the reproduction script. c. Run all registered regression tests. d. Run additional related tests for modules touched by the patch. e. Add edge-case tests for scenarios mentioned in the issue description. f. If the issue mentions multiple scenario...
-
[49]
validation_passed
Share validation results. - If the bug is fixed and all tests pass, call: share_findings("validation_passed", "<summary>") - If any test fails, any error occurs, or the bug remains, call: share_findings("validation_failed", "<specific failure details>") Then call apply_patch() again to wait for the revised patch. - IMPORTANT: After a validation failure, R...
2026
-
[50]
Choices",
Localization hints Determine whether the issue explicitly or implicitly mentions buggy files, classes, functions, methods, stack traces, modules, or code locations. **buggy_files**: List of FULL file paths mentioned or strongly implied **buggy_classes**: List of classes mentioned or implied in the issue (e.g. "Choices", "IntegerChoices"). **buggy_function...
-
[51]
Repair strategy Determine whether the issue describes a fix strategy, expected code change, or implementation tip
-
[52]
quality":
Reproduction hints Determine whether the issue includes reproduction steps, input examples, failing commands, expected behavior, actual behavior, stack traces, or test cases. Classify the issue quality as one of: - high: clear localization, repair, and reproduction information; - low: partial information, but additional repository exploration is needed; R...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.