Bridging Scientific Heritage: An Arabic--Russian Parallel Corpus and LLM Benchmark for Sustainable Knowledge Transfer
Pith reviewed 2026-07-01 01:35 UTC · model grok-4.3
The pith
A hybrid Arabic-Russian parallel corpus of scientific and general texts enables fine-tuned models to translate scientific content more accurately than zero-shot baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that domain-specific fine-tuning on the introduced hybrid parallel corpus produces measurable gains in Arabic-to-Russian and Russian-to-Arabic translation of scientific abstracts, with the Qwen2.5-7B model adapted via QLoRA at rank 8 delivering the highest scores across BLEU, chrF, BERTScore, and COMET, and that few-shot prompting alone does not yield comparable gains.
What carries the argument
The hybrid parallel corpus of about 27,000 sentence pairs compiled from scientific abstracts mixed with general-domain texts, used as training data for LoRA-based adaptation of multilingual language models.
If this is right
- Domain-specific fine-tuning becomes necessary for usable performance on scientific translation tasks in these languages.
- The released models and corpus make direct knowledge exchange between the two research communities more feasible.
- The approach aligns with goals for international research partnerships and innovation infrastructure.
- Few-shot methods without adaptation are insufficient for this domain.
Where Pith is reading between the lines
- The same hybrid-corpus construction method could be tested on other language pairs that lack dedicated scientific translation resources.
- Extending evaluation from abstracts to complete research articles would reveal whether the gains hold for longer, more technical texts.
- Integration of the fine-tuned models into existing translation platforms could be measured by adoption rates among bilingual researchers.
Load-bearing premise
The mixture of scientific abstracts with general-domain texts is representative enough of real scientific writing in both languages that gains on automatic metrics will correspond to usable improvements for actual research content.
What would settle it
A side-by-side human judgment study on held-out full-length scientific papers that finds no reliable preference for the fine-tuned outputs over zero-shot outputs would undermine the claim that the reported metric gains reflect practical translation quality.
Figures
read the original abstract
Russian and Arabic are among the major languages of scientific communication. Language barriers impede the exchange of research results between these communities, which affects international collaboration and the progress of sustainability-related research. We present a benchmark for Arabic--Russian scientific translation. The benchmark includes a hybrid parallel corpus of about 27,000 sentence pairs, compiled from scientific abstracts and general-domain texts (religion, news, conversations). We fine-tune three multilingual language models -- mT5-base (580M parameters), NLLB-200-distilled-1.3B (1.3B), and Qwen2.5-7B-Instruct (7B) -- using LoRA with ranks 8, 16, 32, and 64. The Qwen2.5-7B model with QLoRA (rank 8) yields BLEU 23.15, chrF 43.89, BERTScore 0.906, and COMET 0.758. These are +4.36 BLEU and +0.051 COMET above the zero-shot baseline. Few-shot prompting with three examples does not improve performance, indicating that domain-specific fine-tuning is required. We release the models, the corpus, and the evaluation code. By lowering the language barrier for scientific texts, the work enables knowledge exchange between Arabic-speaking and Russian-speaking researchers. It contributes to sustainable partnerships (UN SDG 17) and innovation infrastructure (SDG 9), aligning with the conference's focus on technology-driven sustainable development.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a hybrid Arabic–Russian parallel corpus of ~27k sentence pairs compiled from scientific abstracts plus general-domain texts (religion, news, conversations), then benchmarks LoRA/QLoRA fine-tuning of mT5-base, NLLB-200-distilled-1.3B and Qwen2.5-7B-Instruct on Arabic-to-Russian translation. It reports that QLoRA (rank 8) on Qwen2.5-7B reaches BLEU 23.15 / chrF 43.89 / BERTScore 0.906 / COMET 0.758, outperforming the zero-shot baseline by +4.36 BLEU and +0.051 COMET, while few-shot prompting yields no gain; the authors release the corpus, models and evaluation code and position the work as enabling sustainable scientific knowledge transfer aligned with SDGs 9 and 17.
Significance. If the metric gains are shown to hold on a purely scientific test subset, the released resources would constitute a concrete, reproducible contribution to low-resource scientific translation between two major languages of research communication. The explicit release of models, corpus and code is a clear strength that supports follow-on work.
major comments (2)
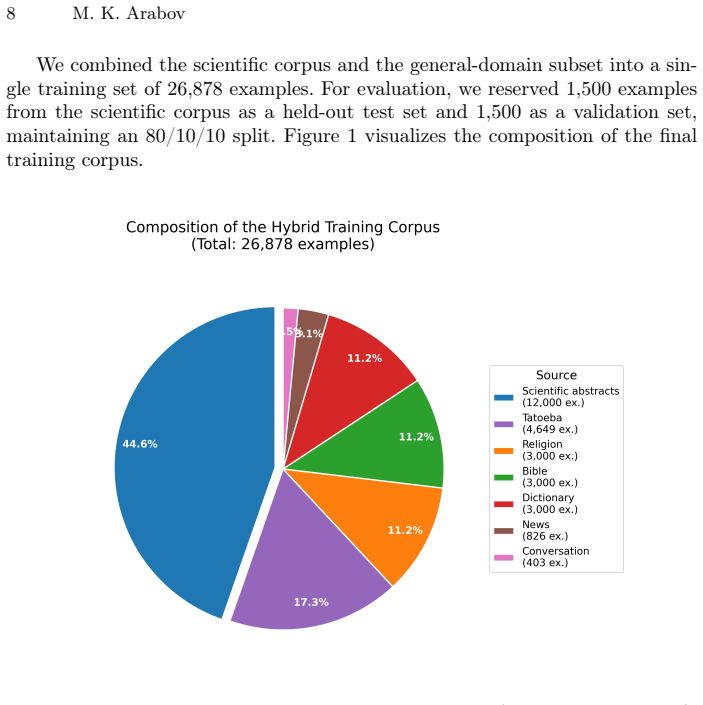
- [Corpus and evaluation setup (Section 3 / 4)] Corpus and evaluation setup (Section 3 / 4): the manuscript states that the corpus is hybrid but supplies neither the fraction of scientific abstracts in the overall collection nor any indication that the test split is restricted to scientific material. No per-domain metric tables or breakdowns are provided. Because the central claim concerns scientific knowledge transfer, the absence of this information leaves open the possibility that reported gains are driven by easier general-domain examples, directly weakening the link between the empirical results and the stated motivation.
- [Results section] Results section: the paper reports point estimates for BLEU, chrF, BERTScore and COMET but does not report statistical significance, standard deviation across random seeds, or confidence intervals for the +4.36 BLEU / +0.051 COMET deltas. Given that the headline claim rests on these specific improvements, the lack of significance testing is a load-bearing omission.
minor comments (2)
- [Abstract] Abstract: the sentence describing the corpus should explicitly state the approximate proportion of scientific abstracts versus general-domain text so readers can immediately assess domain balance.
- [Results tables] Table captions and axis labels in the results tables should indicate whether scores are computed on the full hybrid test set or a scientific-only subset.
Simulated Author's Rebuttal
We thank the referee for the constructive comments that highlight ways to better align the empirical results with the manuscript's focus on scientific translation. We address each major comment below.
read point-by-point responses
-
Referee: [Corpus and evaluation setup (Section 3 / 4)] Corpus and evaluation setup (Section 3 / 4): the manuscript states that the corpus is hybrid but supplies neither the fraction of scientific abstracts in the overall collection nor any indication that the test split is restricted to scientific material. No per-domain metric tables or breakdowns are provided. Because the central claim concerns scientific knowledge transfer, the absence of this information leaves open the possibility that reported gains are driven by easier general-domain examples, directly weakening the link between the empirical results and the stated motivation.
Authors: We agree this information is necessary to substantiate the scientific motivation. The revised manuscript will report the exact fraction of scientific abstracts in the full corpus, clarify the test-split composition, and add per-domain metric tables. We will also report separate results on the scientific subset of the test set. revision: yes
-
Referee: [Results section] Results section: the paper reports point estimates for BLEU, chrF, BERTScore and COMET but does not report statistical significance, standard deviation across random seeds, or confidence intervals for the +4.36 BLEU / +0.051 COMET deltas. Given that the headline claim rests on these specific improvements, the lack of significance testing is a load-bearing omission.
Authors: We concur that statistical rigor is required. The revision will include standard deviations and confidence intervals computed over multiple random seeds, together with significance tests (e.g., bootstrap or paired tests) for the reported deltas. revision: yes
Circularity Check
No significant circularity; empirical results independent of inputs
full rationale
The paper reports an empirical benchmark: construction of a hybrid parallel corpus (~27k pairs), fine-tuning of three models (mT5, NLLB, Qwen2.5-7B) via LoRA/QLoRA at varying ranks, and evaluation on held-out test data using standard metrics (BLEU, chrF, BERTScore, COMET) against zero-shot and few-shot baselines. No equations, derivations, fitted parameters renamed as predictions, or self-citations appear in the provided text. The reported gains (+4.36 BLEU, +0.051 COMET) are direct experimental outputs, not reductions by construction to the training data or prior author work. The hybrid corpus composition and lack of per-domain breakdowns raise validity questions but do not constitute circularity under the enumerated patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Automatic metrics such as BLEU and COMET correlate sufficiently with human judgments of translation quality for scientific text.
Reference graph
Works this paper leans on
-
[1]
In: International Conference on Learning Representations (ICLR) (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: LoRA: Low-Rank Adaptation of Large Language Models. In: International Conference on Learning Representations (ICLR) (2022). https://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[2]
In: Advances in Neural Information Processing Sys- tems, vol
Dettmers, T., Pagnoni, A., Holtzman, A., Zettlemoyer, L.: QLoRA: Efficient Fine- tuning of Quantized LLMs. In: Advances in Neural Information Processing Sys- tems, vol. 36 (2024)
2024
-
[3]
Rei, R., Stewart, C., Farinha, A.C., Lavie, A.: COMET: A Neural Framework for MT Evaluation. In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 2685–2702. Association for Com- putational Linguistics, Online (2020). https://doi.org/10.18653/v1/2020.emnlp- main.213
-
[4]
doi:10.3115/1073083.1073135 , editor =
Papineni, K., Roukos, S., Ward, T., Zhu, W.J.: BLEU: a Method for Automatic Evaluation of Machine Translation. In: Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pp. 311–318. Philadelphia, USA (2002). https://doi.org/10.3115/1073083.1073135
-
[5]
In: International Conference on Learning Rep- resentations (ICLR) (2020)
Zhang, T., Kishore, V., Wu, F., Weinberger, K.Q., Artzi, Y.: BERTScore: Evalu- ating Text Generation with BERT. In: International Conference on Learning Rep- resentations (ICLR) (2020). https://openreview.net/forum?id=SkeHuCVFDr
2020
-
[6]
In: Proceedings of the Tenth Workshop on Statistical Machine Translation, pp
Popovic, M.: chrF: Character n-gram F-score for Automatic MT Evaluation. In: Proceedings of the Tenth Workshop on Statistical Machine Translation, pp. 392–
-
[7]
https://aclanthology.org/W15-3049/
Lisbon, Portugal (2015). https://aclanthology.org/W15-3049/
2015
-
[8]
Alzubaidi, A., Alsuwaidi, S., Boussaha, B.E.A., Al Qadi, L., Alkaabi, O., Alyafeai, M., Alobeidli, H., Hacid, H.: Evaluating Arabic Large Language Mod- els: A Survey of Benchmarks, Methods, and Gaps. arXiv:2510.13430 (2025). https://arxiv.org/abs/2510.13430
arXiv 2025
-
[9]
Computer Science Review38, 100307 (2020)
Hadj Ameur, M.S., Guessoum, A.: A Survey on Arabic Machine Translation: Progress, Challenges, and Future Directions. Computer Science Review38, 100307 (2020). https://doi.org/10.1016/j.cosrev.2020.100307
-
[10]
In: Proceedings of the Third Arabic Natural Language Pro- cessing Conference (ArabicNLP 2025), pp
Al-Matham, R.N., Darwish, K., Al-Rasheed, R., Alshammari, W., Alhoshan, M., Elsayed, T.: BALSAM: A Platform for Benchmarking Arabic Large Lan- guage Models. In: Proceedings of the Third Arabic Natural Language Pro- cessing Conference (ArabicNLP 2025), pp. 258–277. Suzhou, China (2025). https://aclanthology.org/2025.arabicnlp-1.19/
2025
-
[11]
Hugging Face (2026)
ArabicNLPWorld: Arabic-Russian Parallel Corpus. Hugging Face (2026). https://huggingface.co/datasets/ArabicNLPWorld/arabic-russian-parallel-corpus
2026
-
[12]
Hugging Face (2026)
ArabicNLPWorld: Arabic-Russian Scientific Translations. Hugging Face (2026). https://huggingface.co/datasets/ArabicNLPWorld/arabic-russian-scientific- translations
2026
-
[13]
Alrashed, S., Orabona, F.: AraMix: Recycling, Refiltering, and Deduplicating to Deliver the Largest Arabic Pretraining Corpus. arXiv:2512.18834 (2025). https://arxiv.org/abs/2512.18834
arXiv 2025
-
[14]
Arabov, M.K., Khaybullina, S.S.: Adapting Large Language Models to a Low- Resource Agglutinative Language: A Comparative Study of LoRA and QLoRA for Bashkir. arXiv:2605.04948 (2026). https://arxiv.org/abs/2605.04948
Pith/arXiv arXiv 2026
-
[15]
Song, Y., Li, L., Lothritz, C., Ezzini, S., Sleem, L., Bissyandé, T.F., Klein, J.: Are Small Language Models the Silver Bullet to Low-Resource Languages Machine Translation? In: Proceedings of the Ninth Workshop on Technologies for Machine LLM Benchmark for Arabic–Russian Translation 21 Translation of Low Resource Languages (LoResMT 2026), pp. 1–26. Rabat...
2026
-
[16]
In: Proceedings of the 6th Workshop on Open-Source Arabic Corpora and Processing Tools (OSACT) (2024)
Al-Khalifa, H., Darwish, K., Mubarak, H., Ali, M., Elsayed, T.: Proceedings of the 6th Workshop on Open-Source Arabic Corpora and Processing Tools (OSACT) with Shared Tasks on Arabic LLMs Hallucination and Dialect to MSA Machine Translation. In: Proceedings of the 6th Workshop on Open-Source Arabic Corpora and Processing Tools (OSACT) (2024). https://acla...
2024
-
[17]
In: Proceedings of the First Workshop on NLP and LLMs for the Iranian Language Family, pp
Arabov, M.K.: TajPersLexon: A Tajik–Persian Lexical Resource and Hy- brid Model for Cross-Script Low-Resource NLP. In: Proceedings of the First Workshop on NLP and LLMs for the Iranian Language Family, pp. 29–37. Association for Computational Linguistics, Rabat, Morocco (2026). https://doi.org/10.18653/v1/2026.silkroadnlp-1.4
-
[18]
In: Proceedings of the 2nd Workshop on NLP for Languages Using Arabic Script, pp
Kurbonovich, A.M.: Character-Level Transformer for Tajik–Persian Translitera- tion with a Parallel Lexical Corpus. In: Proceedings of the 2nd Workshop on NLP for Languages Using Arabic Script, pp. 75–83. Association for Computational Lin- guistics, Rabat, Morocco (2026). https://doi.org/10.18653/v1/2026.abjadnlp-1.10
-
[19]
Xue, L., Constant, N., Roberts, A., Kale, M., Al-Rfou, R., Siddhant, A., Barua, A., Raffel, C.: mT5: A Massively Multilingual Pre-trained Text-to-Text Trans- former. In: Proceedings of the 2021 Conference of the North American Chap- ter of the Association for Computational Linguistics: Human Language Tech- nologies, pp. 483–498. Association for Computatio...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.