COMPOSE: Static Timing-driven Composable Reconfigurable Architecture for Accelerating Recurrence-Bound Loops
Pith reviewed 2026-06-26 12:47 UTC · model grok-4.3
The pith
COMPOSE forms processing elements dynamically in CGRAs using static timing to fuse operations across loop iterations and cut inter-iteration serialization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
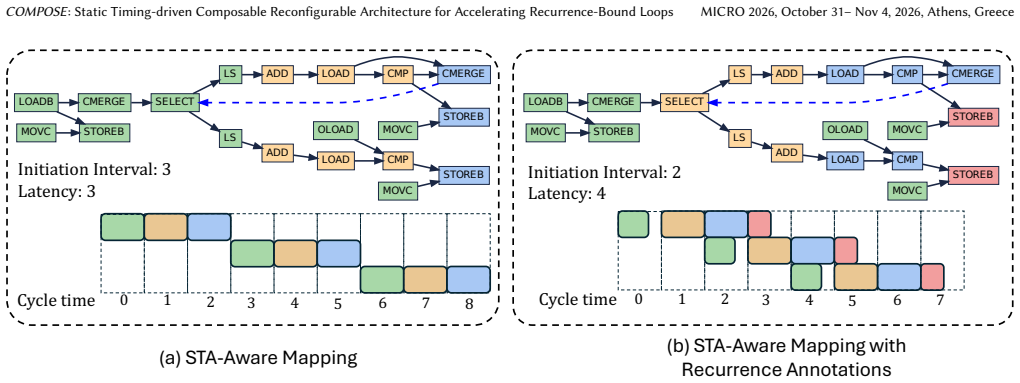
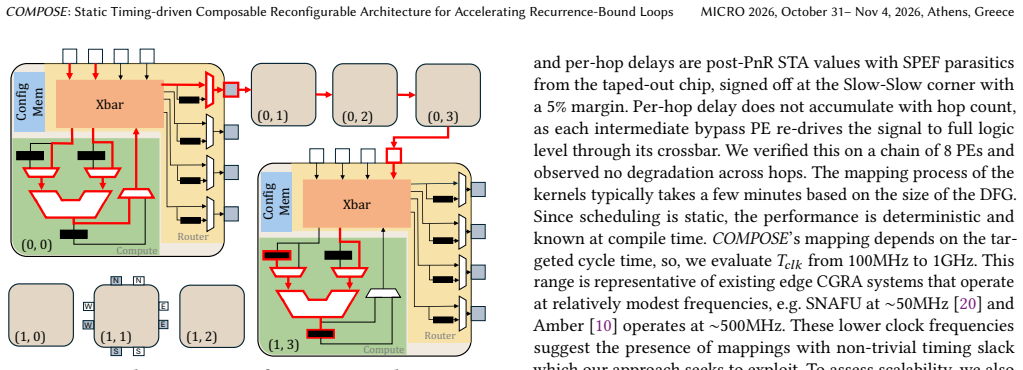
COMPOSE enables dynamic formation of PEs at compile time guided by static timing information. By spatially fusing operations across loop iterations and selectively utilizing slack, COMPOSE resolves inter-iteration dependencies that limit throughput and enables low latency execution by reducing slack wastage. Additionally, the architecture reduces register file pressure by deferring output registration when intermediate values remain locally consumable, which significantly lowers redundant memory traffic.
What carries the argument
The composable CGRA that performs compile-time, static-timing-guided dynamic formation of processing elements to fuse operations across iterations.
If this is right
- Recurrence-bound loops achieve higher throughput because inter-iteration dependencies are resolved by spatial fusion rather than serialized scheduling.
- Energy-delay product drops on average by 2.9x because slack is consumed and register-file traffic is reduced.
- Area and power overheads remain minimal while delivering the gains over fixed-PE baselines.
- Workloads with abundant but recurrence-limited parallelism become better candidates for CGRA acceleration.
Where Pith is reading between the lines
- The same timing-guided composition idea might apply to other spatial architectures if their place-and-route tools can export equivalent slack data.
- Compiler passes that currently target only operation scheduling could be extended to also decide fusion boundaries using the same static timing model.
- In memory-constrained embedded systems the reduced register traffic could translate into smaller on-chip memories without performance loss.
Load-bearing premise
Static timing information available at compile time is accurate and sufficient to guide safe dynamic PE formation and slack use without introducing new dependencies or needing runtime corrections.
What would settle it
Execute the evaluated workloads on fabricated hardware where measured delays deviate from the compile-time static timing model and check whether the reported 1.6x performance gain and absence of dependency violations still hold.
Figures





read the original abstract
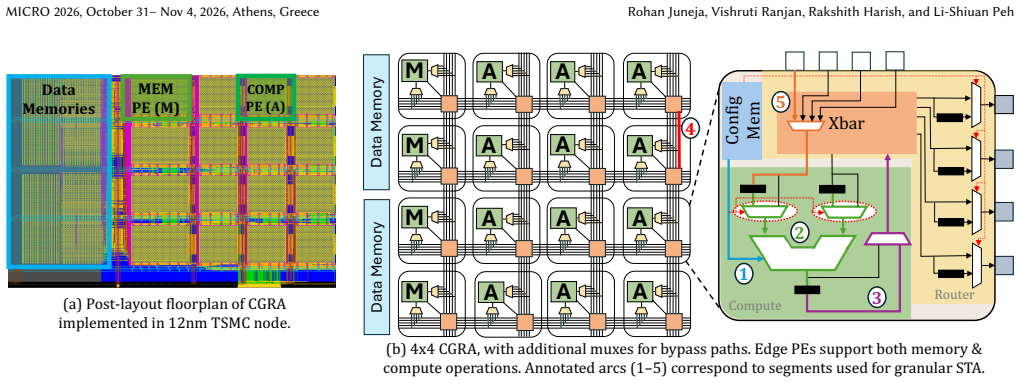
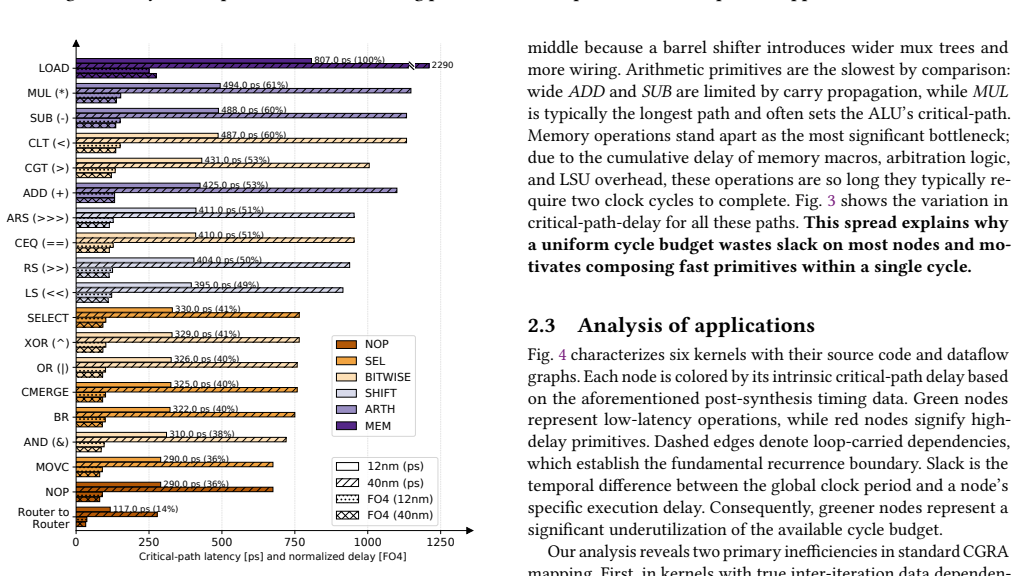
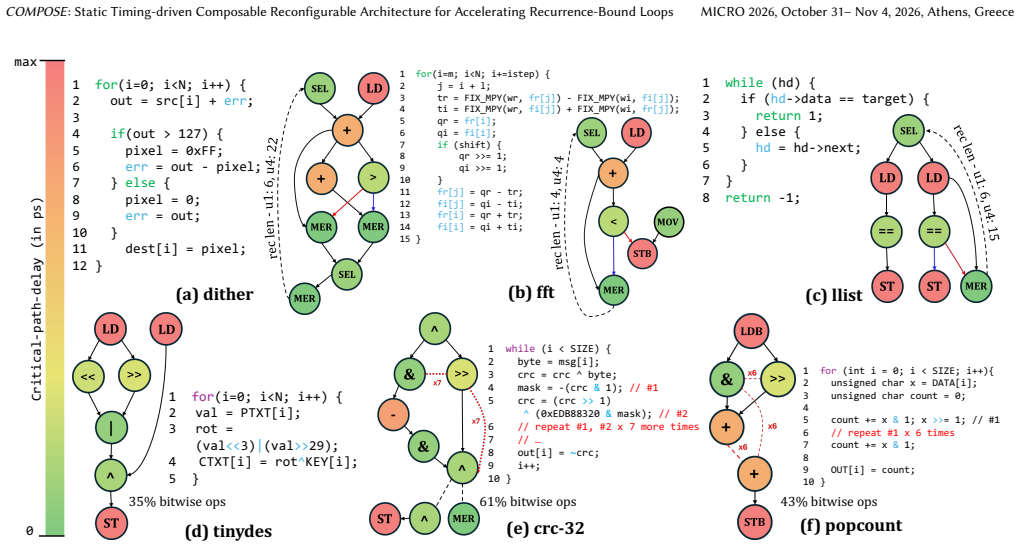
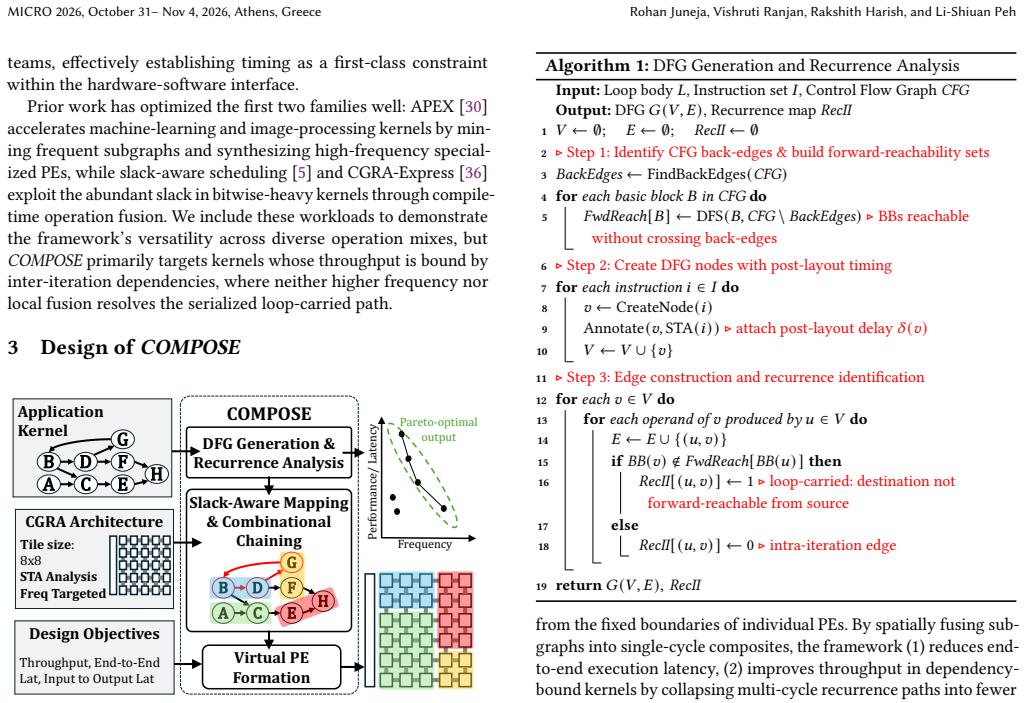
Coarse-Grained Reconfigurable Architectures (CGRAs) provide a spatially programmable substrate well suited for accelerating compute-intensive workloads with abundant parallelism. However, traditional CGRA execution models rely on rigid, fixed-size processing elements (PEs) that are statically bound to individual operations, which forces inter-iteration dependencies to be resolved through serialized scheduling. This limits throughput and reduces parallelism across loop iterations. Moreover, static execution schedules often fail to exploit available timing slack between operations, leading to resource underutilization and increased latency. The frequent registering of intermediate results further exacerbates pressure on register files and local memories, introducing data movement overheads that reduce energy efficiency, particularly in power or memory constrained environments. To address these challenges, we introduce COMPOSE, a composable CGRA architecture that enables dynamic formation of PEs at compile time guided by static timing information. By spatially fusing operations across loop iterations and selectively utilizing slack, COMPOSE resolves inter-iteration dependencies that limit throughput and enables low latency execution by reducing slack wastage. Additionally, the architecture reduces register file pressure by deferring output registration when intermediate values remain locally consumable, which significantly lowers redundant memory traffic. Across a diverse set of workloads, COMPOSE on average delivers 1.6x performance improvement and 2.9x EDP reduction over state-of-the-art (SOTA), at minimal area and power overheads.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
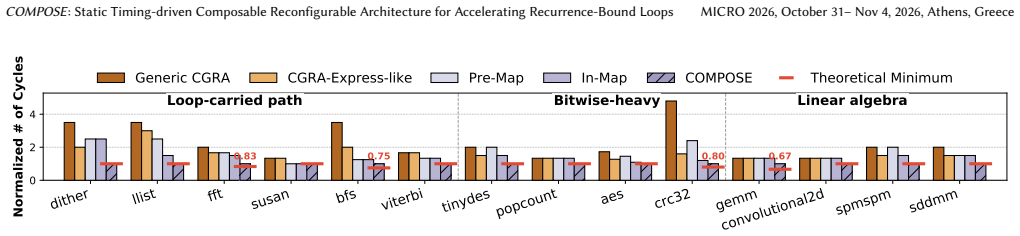
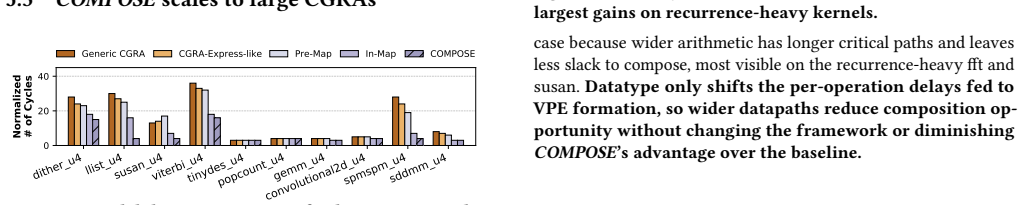
Summary. The paper introduces COMPOSE, a composable CGRA that enables compile-time dynamic formation of processing elements (PEs) guided by static timing information. By spatially fusing operations across loop iterations, selectively consuming timing slack, and deferring registration of locally consumable values, the architecture aims to resolve inter-iteration dependencies, reduce slack wastage, and lower register-file and memory pressure in recurrence-bound loops. The central empirical claim is an average 1.6× performance improvement and 2.9× EDP reduction versus SOTA at minimal area/power overhead.
Significance. If the performance and EDP claims are substantiated by sound experiments and the static-timing assumption holds, the work would offer a practical way to improve CGRA utilization for loops that are currently limited by rigid PE sizing and serialized inter-iteration scheduling. The compile-time composability approach is a concrete contribution to the CGRA literature.
major comments (2)
- [Abstract] Abstract: the manuscript states concrete 1.6× performance and 2.9× EDP numbers yet supplies no experimental methodology, workload list, baseline descriptions, or error analysis. Without these details it is impossible to assess whether the reported gains are supported by the data.
- [Architecture / Timing model (exact section number not visible in provided text)] Architecture and timing model sections: the 1.6×/2.9× claim rests on the premise that static timing information available at compile time is accurate and complete enough to (a) safely fuse operations into dynamic PEs, (b) consume slack without creating unaccounted dataflow edges, and (c) defer registration without runtime correction. The manuscript provides no cycle-accurate simulation with perturbed delays, formal timing verification, or sensitivity analysis that this condition holds for the evaluated workloads; this assumption is load-bearing for the central performance claim.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly named the benchmark suite or loop characteristics used to obtain the reported averages.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the manuscript states concrete 1.6× performance and 2.9× EDP numbers yet supplies no experimental methodology, workload list, baseline descriptions, or error analysis. Without these details it is impossible to assess whether the reported gains are supported by the data.
Authors: We agree that the abstract would benefit from additional context on the evaluation. The full manuscript details the workloads, baselines (including SOTA CGRA designs), cycle-accurate simulation methodology, and performance metrics in the experimental evaluation section. To address the concern, we will revise the abstract to include a concise statement referencing the evaluation methodology, the set of recurrence-bound loop workloads, and the comparison baselines used to obtain the reported averages. revision: yes
-
Referee: [Architecture / Timing model (exact section number not visible in provided text)] Architecture and timing model sections: the 1.6×/2.9× claim rests on the premise that static timing information available at compile time is accurate and complete enough to (a) safely fuse operations into dynamic PEs, (b) consume slack without creating unaccounted dataflow edges, and (c) defer registration without runtime correction. The manuscript provides no cycle-accurate simulation with perturbed delays, formal timing verification, or sensitivity analysis that this condition holds for the evaluated workloads; this assumption is load-bearing for the central performance claim.
Authors: The architecture uses static timing analysis from standard synthesis flows to guide compile-time composition and slack consumption, which is a deliberate design choice to avoid runtime overhead. The reported results are obtained from cycle-accurate simulations that incorporate the timing model for the evaluated workloads. We acknowledge that explicit sensitivity analysis under perturbed delays or formal verification of all dataflow edges would further substantiate robustness. We will add a sensitivity study in the revised manuscript that perturbs interconnect and PE delays within realistic bounds and reports the resulting performance variation. revision: yes
Circularity Check
No circularity; architecture claims rest on external experimental evaluation
full rationale
The provided abstract and description contain no equations, fitted parameters, self-citations, or derivation steps that reduce to inputs by construction. Performance and EDP numbers are presented as measured outcomes over SOTA baselines rather than quantities forced by the timing model itself. The architecture proposal is therefore self-contained against external benchmarks with no load-bearing self-referential elements.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Traditional CGRAs rely on rigid fixed-size PEs statically bound to operations, forcing serialized inter-iteration scheduling.
invented entities (1)
-
Composable CGRA with compile-time dynamic PE formation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
[n. d.]. SN40L RDU AI Chip. https://sambanova.ai/products/sn40l-rdu-ai-chip. Accessed: 2025-08-14
2025
-
[2]
Giovanni Ansaloni, Paolo Bonzini, and Laura Pozzi. 2008. Design and Architec- tural Exploration of Expression-Grained Reconfigurable Arrays. In2008 Sympo- sium on Application Specific Processors. 26–33. https://doi.org/10.1109/SASP.2008. 4570782
-
[3]
Giovanni Ansaloni, Paolo Bonzini, and Laura Pozzi. 2009. Heterogeneous coarse- grained processing elements: a template architecture for embedded processing acceleration. InProceedings of the Conference on Design, Automation and Test in Europe(Nice, France)(DATE ’09). European Design and Automation Association, Leuven, BEL, 542–547
2009
-
[4]
Giovanni Ansaloni, Paolo Bonzini, and Laura Pozzi. 2011. EGRA: A Coarse Grained Reconfigurable Architectural Template.IEEE Transactions on Very Large Scale Integration (VLSI) Systems19, 6 (2011), 1062–1074. https://doi.org/10.1109/ TVLSI.2010.2044667
arXiv 2011
-
[5]
Giovanni Ansaloni, Laura Pozzi, Kazuyuki Tanimura, and Nikil Dutt. 2011. Slack- aware scheduling on Coarse Grained Reconfigurable Arrays. In2011 Design, Automation & Test in Europe. 1–4. https://doi.org/10.1109/DATE.2011.5763323
-
[6]
Zhenyu Bai, Pranav Dangi, Rohan Juneja, Zhaoying Li, Zhanglu Yan, Huiying Lan, and Tulika Mitra. 2025. A Data-Driven Dynamic Execution Orchestration Architecture. InProceedings of the 31st ACM International Conference on Archi- tectural Support for Programming Languages and Operating Systems, Volume 1 (Pittsburgh, PA, USA)(ASPLOS ’26). Association for Com...
-
[7]
Bhasker and Rakesh Chadha
J. Bhasker and Rakesh Chadha. 2009.Static Timing Analysis for Nanometer Designs: A Practical Approach(1st ed.). Springer Publishing Company, Incorporated
2009
-
[8]
David Blaauw, Kaviraj Chopra, Ashish Srivastava, and Lou Scheffer. 2008. Statis- tical Timing Analysis: From Basic Principles to State of the Art.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems27, 4 (2008), 589–607. https://doi.org/10.1109/TCAD.2007.907047
-
[9]
A Piecewise Rotation of the Circle, IPR Maps and Their Connection with Translation Surfaces
Doug Burger, Stephen W. Keckler, and Simha Sethumadhavan. 2009.Composable Multicore Chips. Springer US, Boston, MA, 73–109. https://doi.org/10.1007/978- 1-4419-0263-4_3
-
[10]
Alex Carsello and et el. [n. d.]. Amber: A 367 GOPS, 538 GOPS/W 16nm SoC with a Coarse-Grained Reconfigurable Array for Flexible Acceleration of Dense Linear Algebra. InVLSI’22. 70–71. https://doi.org/10.1109/VLSITechnologyandCir46769. 2022.9830509
-
[11]
N. Clark, J. Blome, M. Chu, S. Mahlke, S. Biles, and K. Flautner. 2005. An archi- tecture framework for transparent instruction set customization in embedded processors. In32nd International Symposium on Computer Architecture (ISCA’05). 272–283. https://doi.org/10.1109/ISCA.2005.9
-
[12]
Nathan Clark, Amir Hormati, Scott Mahlke, and Sami Yehia. 2006. Scalable subgraph mapping for acyclic computation accelerators. InProceedings of the 2006 International Conference on Compilers, Architecture and Synthesis for Embedded Systems(Seoul, Korea)(CASES ’06). Association for Computing Machinery, New York, NY, USA, 147–157. https://doi.org/10.1145/1...
-
[13]
N. Clark, M. Kudlur, Hyunchul Park, S. Mahlke, and K. Flautner. 2004. Application- Specific Processing on a General-Purpose Core via Transparent Instruction Set Customization. In37th International Symposium on Microarchitecture (MICRO- 37’04). 30–40. https://doi.org/10.1109/MICRO.2004.5
-
[14]
Jason Cong, Hui Huang, Chiyuan Ma, Bingjun Xiao, and Peipei Zhou. 2014. A Fully Pipelined and Dynamically Composable Architecture of CGRA. In2014 IEEE 22nd Annual International Symposium on Field-Programmable Custom Computing Machines. 9–16. https://doi.org/10.1109/FCCM.2014.12
-
[15]
Efficient Computer. [n. d.]. Electron E1. https://www.efficient.computer/electron- e1 Accessed: 2026-04-06
2026
-
[16]
Joseph A. Fisher. 1983. Very Long Instruction Word architectures and the ELI-512. SIGARCH Comput. Archit. News11, 3 (June 1983), 140–150. https://doi.org/10. 1145/1067651.801649
arXiv 1983
-
[17]
Kermin E Fleming and et al. 2020. Processors, methods, and systems with a configurable spatial accelerator. US Patent 10,558,575
2020
-
[18]
Taro Fujii and et al. [n. d.]. New Generation Dynamically Reconfigurable Proces- sor Technology for Accelerating Embedded AI Applications. InVLSI’18. 41–42. https://doi.org/10.1109/VLSIC.2018.8502438
-
[19]
Souradip Ghosh, Graham Gobieski, Keyi Zhang, Brandon Lucia, Nathan Beck- mann, and Tony Nowatzki. 2025. NUPEA: Optimizing Critical Loads on Spatial Dataflow Architectures via Non-Uniform Processing-Element Access. InProceed- ings of the 52nd Annual International Symposium on Computer Architecture (ISCA ’25). Association for Computing Machinery, New York, ...
-
[20]
Graham Gobieski, Ahmet Oguz Atli, Kenneth Mai, Brandon Lucia, and Nathan Beckmann. [n. d.]. Snafu: An Ultra-Low-Power, Energy-Minimal CGRA- Generation Framework and Architecture. InISCA’21. 1027–1040. https://doi.org/ 10.1109/ISCA52012.2021.00084
-
[21]
Graham Gobieski, Souradip Ghosh, Marijn Heule, Todd Mowry, Tony Nowatzki, Nathan Beckmann, and Brandon Lucia. 2023. RipTide: A Programmable, Energy- Minimal Dataflow Compiler and Architecture. InProceedings of the 55th Annual IEEE/ACM International Symposium on Microarchitecture(Chicago, Illinois, USA) (MICRO ’22). IEEE Press, 546–564. https://doi.org/10....
-
[22]
Shantanu Gupta, Shuguang Feng, Amin Ansari, Scott Mahlke, and David Au- gust. 2011. Bundled execution of recurring traces for energy-efficient gen- eral purpose processing. InProceedings of the 44th Annual IEEE/ACM Inter- national Symposium on Microarchitecture(Porto Alegre, Brazil)(MICRO-44). Association for Computing Machinery, New York, NY, USA, 12–23....
-
[23]
David Money Harris, Ron Ho, Gu-Yeon Wei, and Mark Horowitz. 1998. The Fanout-of-4 Inverter Delay Metric. https://api.semanticscholar.org/CorpusID: 9167634
1998
-
[24]
2017.On-Chip Net- works: Second Edition(2nd ed.)
Natalie Enright Jerger, Tushar Krishna, and Li-Shiuan Peh. 2017.On-Chip Net- works: Second Edition(2nd ed.). Morgan & Claypool Publishers
2017
-
[25]
Rohan Juneja, Pranav Dangi, Thilini Kaushalya Bandara, Zhaoying Li, Dhanan- jaya Wijerathne, Li-Shiuan Peh, and Tulika Mitra. 2025. Building an Open CGRA Ecosystem for Agile Innovation. arXiv:2508.19090 [cs.AR] https: //arxiv.org/abs/2508.19090
arXiv 2025
-
[26]
Rohan Juneja, Pranav Dangi, Thilini Kaushalya Bandara, Tulika Mitra, and Li- Shiuan Peh. 2025. Nexus Machine: An Energy-Efficient Active Message Inspired Reconfigurable Architecture. InProceedings of the 58th IEEE/ACM International Symposium on Microarchitecture (MICRO ’25). Association for Computing Machin- ery, New York, NY, USA, 1221–1235. https://doi....
-
[27]
Changmoo Kim, Mookyoung Chung, Yeongon Cho, Mario Konijnenburg, Soojung Ryu, and Jeongwook Kim. 2012. ULP-SRP: Ultra low power Samsung Reconfig- urable Processor for biomedical applications. In2012 International Conference on Field-Programmable Technology. 329–334. https://doi.org/10.1109/FPT.2012. 6412157
-
[28]
Zhaoying Li, Pranav Dangi, Chenyang Yin, Thilini Kaushalya Bandara, Rohan Juneja, Cheng Tan, Zhenyu Bai, and Tulika Mitra. 2025. Enhancing CGRA Efficiency Through Aligned Compute and Communication Provisioning. InPro- ceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1(Rotter...
-
[29]
Bingfeng Mei, Serge Vernalde, Diederik Verkest, Haris Man, and Rudy Lauwereins. [n. d.]. ADRES: An Architecture with Tightly Coupled VLIW Processor and Coarse-Grained Reconfigurable Matrix. InFPL’03. https://doi.org/10.1007/978-3- 540-45234-8_7
-
[30]
Horowitz, Pat Hanrahan, and Priyanka Raina
Jackson Melchert, Kathleen Feng, Caleb Donovick, Ross Daly, Ritvik Sharma, Clark Barrett, Mark A. Horowitz, Pat Hanrahan, and Priyanka Raina. 2023. APEX: A Framework for Automated Processing Element Design Space Exploration using Frequent Subgraph Analysis. InProceedings of the 28th ACM International Confer- ence on Architectural Support for Programming L...
-
[31]
Jackson Melchert, Yuchen Mei, Kalhan Koul, Qiaoyi Liu, Mark Horowitz, and Priyanka Raina. 2024. Cascade: An Application Pipelining Toolkit for Coarse- Grained Reconfigurable Arrays.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems43, 10 (2024), 3055–3067. https://doi.org/10.1109/ TCAD.2024.3390542
arXiv 2024
-
[32]
V. P. Nambiar, Y. S. Chong, T. K. Bandara, D. Wijerathne, Z. Li, R. Juneja, L.-S. Peh, T. Mitra, and A. T. Do. 2024. A 360 GOPS/W CGRA in a RISC-V SoC with Multi-Hop Routers and Idle-State Instructions for Edge Computing Applications. In2024 21st International SoC Design Conference (ISOCC). 89–90. https://doi.org/ 10.1109/ISOCC62682.2024.10762131
-
[33]
Vishnu P. Nambiar, Yi Sheng Chong, Thilini Kaushalya Bandara, Dhananjaya Wi- jerathne, Zhaoying Li, Rohan Juneja, Li-Shiuan Peh, Tulika Mitra, and Anh Tuan Do. 2024. PACE: A Scalable and Energy Efficient CGRA in a RISC-V SoC for Edge Computing Applications. In2024 IEEE Hot Chips 36 Symposium (HCS). 1–1. https://doi.org/10.1109/HCS61935.2024.10665106
-
[34]
Tony Nowatzki, Vinay Gangadhar, Newsha Ardalani, and Karthikeyan Sankar- alingam. 2017. Stream-Dataflow Acceleration.SIGARCH Comput. Archit. News 45, 2 (June 2017), 416–429. https://doi.org/10.1145/3140659.3080255
-
[35]
Taewook Oh, Bernhard Egger, Hyunchul Park, and Scott Mahlke. 2009. Re- currence cycle aware modulo scheduling for coarse-grained reconfigurable architectures. InProceedings of the 2009 ACM SIGPLAN/SIGBED Conference on Languages, Compilers, and Tools for Embedded Systems(Dublin, Ireland) (LCTES ’09). Association for Computing Machinery, New York, NY, USA, ...
-
[36]
Yongjun Park, Hyunchul Park, and Scott Mahlke. 2009. CGRA express: accel- erating execution using dynamic operation fusion. InProceedings of the 2009 International Conference on Compilers, Architecture, and Synthesis for Embedded Systems(Grenoble, France)(CASES ’09). Association for Computing Machinery, New York, NY, USA, 271–280. https://doi.org/10.1145/...
-
[37]
Raghu Prabhakar and Sumti Jairath. 2021. SambaNova SN10 RDU:Accelerating Software 2.0 with Dataflow. In2021 IEEE Hot Chips 33 Symposium (HCS). 1–37. https://doi.org/10.1109/HCS52781.2021.9567250
-
[38]
Jiajun Qin, Cheng Tan, Ruihong Yin, Tianhua Xia, Sai Qian Zhang, and Bei Yu. [n. d.]. FLAME: A Framework Exploring Execution Strategies for Multi-Cycle Operations in CGRA. ([n. d.])
-
[39]
B. Ramakrishna Rau. 1994. Iterative modulo scheduling: an algorithm for software pipelining loops. InProceedings of the 27th Annual International Symposium on Microarchitecture(San Jose, California, USA)(MICRO 27). Association for Computing Machinery, New York, NY, USA, 63–74. https://doi.org/10.1145/ 192724.192731
arXiv 1994
-
[40]
R. Ruiz-Sautua, M.C. Molina, J.M. Mendias, and R. Hermida. 2005. Behavioural transformation to improve circuit performance in high-level synthesis. InDesign, Automation and Test in Europe. 1252–1257 Vol. 2. https://doi.org/10.1109/DATE. 2005.81
-
[41]
Richard M. Russell. 1978. The CRAY-1 computer system.Commun. ACM21, 1 (Jan. 1978), 63–72. https://doi.org/10.1145/359327.359336
-
[42]
Nimish Shah, Wannes Meert, and Marian Verhelst. 2022. DPU-v2: Energy-efficient execution of irregular directed acyclic graphs. In2022 55th IEEE/ACM International Symposium on Microarchitecture (MICRO). 1288–1307. https://doi.org/10.1109/ MICRO56248.2022.00090
arXiv 2022
-
[43]
Mukund Sivaraman and Shail Aditya. 2002. Cycle-time aware architecture syn- thesis of custom hardware accelerators. InProceedings of the 2002 International Conference on Compilers, Architecture, and Synthesis for Embedded Systems(Greno- ble, France)(CASES ’02). Association for Computing Machinery, New York, NY, USA, 35–42. https://doi.org/10.1145/581630.581637
-
[44]
Aaron Stillmaker and Bevan Baas. 2017. Scaling equations for the accurate prediction of CMOS device performance from 180nm to 7nm.Integration58 (2017), 74–81. https://doi.org/10.1016/j.vlsi.2017.02.002
-
[45]
1999.Logical effort: designing fast CMOS circuits
Ivan Sutherland, Bob Sproull, and David Harris. 1999.Logical effort: designing fast CMOS circuits. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA
1999
-
[46]
Cheng Tan, Manupa Karunaratne, Tulika Mitra, and Li-Shiuan Peh. 2018. Stitch: fusible heterogeneous accelerators enmeshed with many-core architecture for wearables. InProceedings of the 45th Annual International Symposium on Computer Architecture(Los Angeles, California)(ISCA ’18). IEEE Press, 575–587. https: //doi.org/10.1109/ISCA.2018.00054
-
[47]
Christopher Torng, Peitian Pan, Yanghui Ou, Cheng Tan, and Christopher Batten
-
[48]
Blockhammer: Preventing rowhammer at low cost by blacklisting rapidly-accessed dram rows,
Ultra-Elastic CGRAs for Irregular Loop Specialization. In2021 IEEE Interna- tional Symposium on High-Performance Computer Architecture (HPCA). 412–425. https://doi.org/10.1109/HPCA51647.2021.00042
-
[49]
Dhananjaya Wijerathne, Zhaoying Li, Manupa Karunarathne, Anuj Pathania, and Tulika Mitra. 2019. CASCADE: High Throughput Data Streaming via Decoupled Access-Execute CGRA.ACM Trans. Embed. Comput. Syst.18, 5s, Article 50 (Oct. 2019), 26 pages. https://doi.org/10.1145/3358177
-
[50]
Sabrina Yarzada and Christopher Torng. 2026. Capstone: Power- Capped Pipelining for Coarse-Grained Reconfigurable Array Compilers. arXiv:2603.00909 [cs.AR] https://arxiv.org/abs/2603.00909
arXiv 2026
-
[51]
Sami Yehia, Nathan Clark, Scott Mahlke, and Krisztián Flautner. 2005. Exploring the design space of LUT-based transparent accelerators. 11–21. https://doi.org/ 10.1145/1086297.1086301
-
[52]
Zaretsky, Gaurav Mittal, Robert P
David C. Zaretsky, Gaurav Mittal, Robert P. Dick, and Prith Banerjee. 2007. Balanced Scheduling and Operation Chaining in High-Level Synthesis for FPGA Designs. In8th International Symposium on Quality Electronic Design (ISQED’07). 595–601. https://doi.org/10.1109/ISQED.2007.41
-
[53]
Rong Zhu, Bo Wang, and Dajiang Liu. 2022. RF-CGRA: A Routing-Friendly CGRA with Hierarchical Register Chains. In2022 Design, Automation & Test in Europe Conference & Exhibition (DATE). 262–267. https://doi.org/10.23919/DATE54114. 2022.9774601
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.