Which Pairs to Compare for LLM Post-Training?
Pith reviewed 2026-06-26 20:35 UTC · model grok-4.3
The pith
Comparison selection in DPO post-training is governed by one design-dependent information matrix that sets the optimality gap.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes matching upper and lower bounds on the post-training optimality gap of a DPO-trained policy. The bounds show that the choice of labeled comparison pairs affects downstream performance exclusively through a single design-dependent information matrix. This matrix directly links the allocation of labels to the resulting parameter estimation error and hence to policy suboptimality, yielding an explicit optimization criterion for budgeted comparison curation.
What carries the argument
The design-dependent information matrix, which aggregates the contribution of each selected comparison pair to the estimation quality of the DPO objective and thereby determines the policy optimality gap.
If this is right
- Budgeted comparison curation reduces to optimizing the information matrix rather than enumerating all pairs.
- Practical sampling designs can be constructed to select the most informative pairs from large completion pools.
- The same matrix supplies both upper and lower bounds, so the criterion is tight rather than loose.
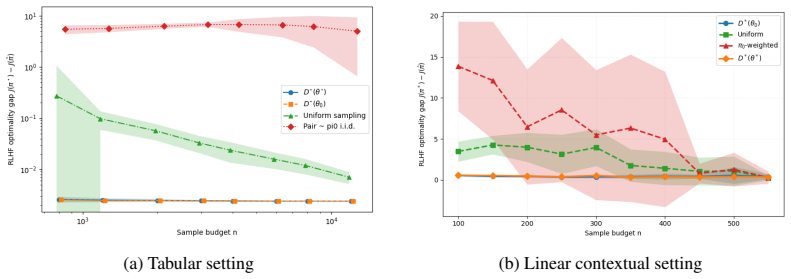
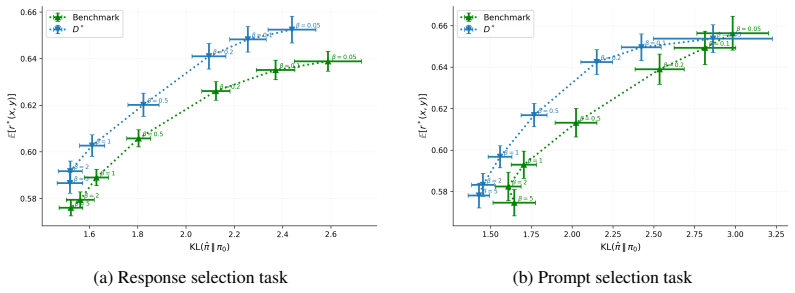
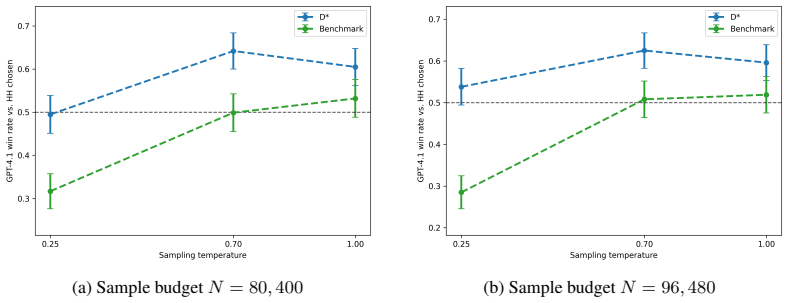
- Experiments on synthetic settings and language-model benchmarks show consistent gains in sample efficiency over standard heuristics.
Where Pith is reading between the lines
- The matrix formulation may extend to other preference objectives if their loss surfaces admit analogous information structures.
- An adaptive version could recompute the matrix after each batch of labels and refine the remaining selections.
- In deployment the matrix would need to be estimated from a pilot sample of the model, introducing an extra approximation layer.
Load-bearing premise
The derivation assumes that the mapping from chosen comparison pairs to the DPO loss and to policy suboptimality can be captured exactly by the information matrix without additional bias from model misspecification, optimization dynamics, or the specific form of the preference probability model.
What would settle it
Run DPO on pairs chosen by the matrix criterion versus uniform random selection; if the observed policy gap deviates substantially from the matrix-predicted gap on a held-out benchmark, the central claim fails.
Figures
read the original abstract
Preference-based post-training has become a central paradigm for aligning language models. A common data-collection strategy is to generate a small set of completions for each prompt and label the resulting comparison pairs. However, human preference labels are often much more expensive than generating additional completions, suggesting a different use of the same labeling budget: generate a larger pool of completions, but label only the most informative comparison pairs. This paper studies which pairs should be compared in preference-based post-training. We formulate comparison curation as a sampling-design problem and evaluate designs by the quality of the final policy under the preference-based post-training objective. We instantiate this framework for Direct Preference Optimization (DPO), analyzing how the choice of labeled pairs propagates through DPO training to downstream policy performance. Our main results provide matching upper and lower bounds on the post-training optimality gap of the DPO-trained policy. The bounds show that comparison selection affects downstream performance through a single design-dependent information matrix, which links label allocation to parameter estimation error and policy suboptimality. This yields an explicit optimization criterion for budgeted comparison curation and motivates practical sampling designs for selecting informative pairs from large generated completion pools. Experiments on synthetic settings and language-model post-training benchmarks show that the proposed designs consistently improve sample efficiency over common comparison-selection heuristics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that comparison pair selection in DPO-based LLM post-training can be optimized using a sampling design that minimizes a design-dependent information matrix, which provides matching upper and lower bounds on the optimality gap of the trained policy. This matrix links the allocation of labels to parameter estimation error and policy suboptimality, leading to practical sampling designs that improve efficiency, as shown in synthetic and benchmark experiments.
Significance. If the bounds are tight and the assumptions hold, this provides a principled, theoretically justified approach to budgeted preference data curation, which could substantially improve the efficiency of LLM alignment by focusing labeling effort on informative pairs. The connection between sampling design and downstream performance via the information matrix is a key insight if the derivations are complete and free of hidden assumptions.
major comments (2)
- [Abstract and main theoretical results] The matching upper and lower bounds on the post-training optimality gap are presented as being determined solely by the design-dependent information matrix. However, this requires that the mapping from pairs to DPO loss to policy suboptimality has no residual bias from the Bradley-Terry preference model, neural policy misspecification, or non-convex optimization dynamics. The paper should explicitly state and justify these conditions or provide conditions under which the bounds remain predictive.
- [Experiments] The abstract mentions experiments on synthetic settings and language-model benchmarks showing improved sample efficiency, but without details on how data was split, exclusion rules, or statistical significance (error bars), it is difficult to assess whether the gains are robust or potentially influenced by post-hoc design choices.
minor comments (2)
- Clarify the exact definition of the information matrix and how it is computed from the sampling design in the main text.
- Ensure all notation for the optimality gap and bounds is consistent between theory and experiments.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and main theoretical results] The matching upper and lower bounds on the post-training optimality gap are presented as being determined solely by the design-dependent information matrix. However, this requires that the mapping from pairs to DPO loss to policy suboptimality has no residual bias from the Bradley-Terry preference model, neural policy misspecification, or non-convex optimization dynamics. The paper should explicitly state and justify these conditions or provide conditions under which the bounds remain predictive.
Authors: The bounds are derived under the standard assumptions that the Bradley-Terry model holds exactly for the preferences, the policy is well-specified with respect to the DPO objective, and optimization reaches the global minimum. These are the same assumptions used throughout the DPO literature. We will revise the manuscript to state these conditions explicitly in the theoretical results section and add discussion of when the bounds remain approximately predictive under mild violations. revision: yes
-
Referee: [Experiments] The abstract mentions experiments on synthetic settings and language-model benchmarks showing improved sample efficiency, but without details on how data was split, exclusion rules, or statistical significance (error bars), it is difficult to assess whether the gains are robust or potentially influenced by post-hoc design choices.
Authors: We agree that these details are needed. The revised manuscript will include explicit descriptions of data splitting procedures, any pair exclusion rules, and results with error bars together with statistical significance tests. revision: yes
Circularity Check
Derivation of information-matrix bounds is mathematically self-contained
full rationale
The paper derives matching upper and lower bounds on the DPO optimality gap directly from the preference-based post-training objective and the sampling design. The design-dependent information matrix is constructed from the chosen comparison pairs, the Bradley-Terry preference model, and the DPO loss; the bounds then follow from standard parametric estimation arguments linking the matrix to parameter error and policy suboptimality. No parameters are fitted to the target performance metric, no self-citation supplies a load-bearing uniqueness theorem, and no ansatz is smuggled in. The central claim is therefore a mathematical consequence of the stated model and design rather than a reduction of the result to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Preference labels are generated according to a probabilistic model whose Fisher information can be expressed as a design-dependent matrix
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[2]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[3]
Advances in Neural Information Processing Systems , year=
Deep reinforcement learning from human preferences , author=. Advances in Neural Information Processing Systems , year=
-
[4]
, journal=
Bradley, Ralph Allan and Terry, Milton E. , journal=. Rank analysis of incomplete block designs:
-
[5]
Optimal design for the
Gra. Optimal design for the. Statistical Methods & Applications , volume=. 2008 , doi=
2008
-
[6]
Journal of statistical planning and inference , volume=
Adaptive paired comparison design , author=. Journal of statistical planning and inference , volume=. 2005 , publisher=
2005
-
[7]
Peter and Chiang, Michael F
Guo, Yuan and Tian, Peng and Kalpathy-Cramer, Jayashree and Ostmo, Susan and Campbell, J. Peter and Chiang, Michael F. and Erdogmus, Deniz and Dy, Jennifer and Ioannidis, Stratis , booktitle=. Experimental Design under the. 2018 , month=
2018
-
[8]
Just Sort It!
Maystre, Lucas and Grossglauser, Matthias , booktitle=. Just Sort It!. 2017 , publisher=
2017
-
[9]
Advances in Neural Information Processing Systems , year=
Learning to summarize from human feedback , author=. Advances in Neural Information Processing Systems , year=
-
[10]
arXiv preprint arXiv:2502.01203 , year=
KL-Regularized RLHF with Multiple Reference Models: Exact Solutions and Sample Complexity , author=. arXiv preprint arXiv:2502.01203 , year=
-
[11]
arXiv preprint arXiv:2407.13399 , year=
Correcting the mythos of kl-regularization: Direct alignment without overoptimization via chi-squared preference optimization , author=. arXiv preprint arXiv:2407.13399 , year=
-
[12]
Journal of Machine Learning Research , volume=
Estimation from pairwise comparisons: Sharp minimax bounds with topology dependence , author=. Journal of Machine Learning Research , volume=
-
[13]
Provably robust dpo: Aligning language models with noisy feedback , author=. arXiv preprint arXiv:2403.00409 , year=
-
[14]
arXiv preprint arXiv:2506.04272 , year=
Understanding the Impact of Sampling Quality in Direct Preference Optimization , author=. arXiv preprint arXiv:2506.04272 , year=
-
[15]
arXiv preprint arXiv:2508.18312 , year=
What Matters in Data for DPO? , author=. arXiv preprint arXiv:2508.18312 , year=
-
[16]
Joint European Conference on Machine Learning and Knowledge Discovery in Databases , pages=
Active preference optimization for sample efficient rlhf , author=. Joint European Conference on Machine Learning and Knowledge Discovery in Databases , pages=. 2025 , organization=
2025
-
[17]
arXiv preprint arXiv:2402.09401 , year=
Reinforcement learning from human feedback with active queries , author=. arXiv preprint arXiv:2402.09401 , year=
-
[18]
arXiv preprint arXiv:2402.08114 , year=
Active preference learning for large language models , author=. arXiv preprint arXiv:2402.08114 , year=
-
[19]
Foundations of Computational Mathematics , volume=
User-friendly tail bounds for sums of random matrices , author=. Foundations of Computational Mathematics , volume=
-
[20]
arXiv preprint arXiv:2502.04270 , year=
Pilaf: Optimal human preference sampling for reward modeling , author=. arXiv preprint arXiv:2502.04270 , year=
-
[21]
International Conference on Machine Learning , pages=
Scaling laws for reward model overoptimization , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[22]
Handbook of econometrics , volume=
Large sample estimation and hypothesis testing , author=. Handbook of econometrics , volume=. 1994 , publisher=
1994
-
[23]
2000 , publisher=
Asymptotic statistics , author=. 2000 , publisher=
2000
-
[24]
Advances in Neural Information Processing Systems , volume=
Optimal design for human preference elicitation , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
International Conference on Learning Representations , volume=
Exploratory preference optimization: Harnessing implicit q*-approximation for sample-efficient rlhf , author=. International Conference on Learning Representations , volume=
-
[26]
arXiv preprint arXiv:2503.01076 , year=
Active learning for direct preference optimization , author=. arXiv preprint arXiv:2503.01076 , year=
-
[27]
ActiveDPO: Active Direct Preference Optimization for Sample-Efficient Alignment
Activedpo: Active direct preference optimization for sample-efficient alignment , author=. arXiv preprint arXiv:2505.19241 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
arXiv preprint arXiv:2410.17055 , year=
Optimal design for reward modeling in rlhf , author=. arXiv preprint arXiv:2410.17055 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.