SpaCE: Rethinking Spatial Capacity and Generalization in Multi-Frame Multimodal Large Language Models
Pith reviewed 2026-06-26 22:06 UTC · model grok-4.3
The pith
Multi-frame MLLM spatial reasoning accuracy is upper-bounded by mutual information between observations and targets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
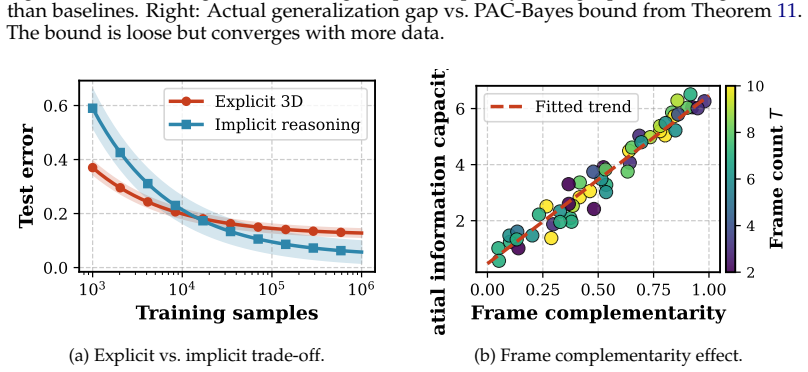
We establish four main results. First, we prove an information-theoretic upper bound on spatial reasoning accuracy in terms of the mutual information between multi-frame observations and spatial targets. Second, we derive a sample complexity bound of order Θ(d_eff · K_max / (ε² · δ)). Third, we provide a PAC-Bayes generalization bound for multi-frame spatial reasoning under distribution shift. Fourth, we formally characterize the bias-variance trade-off between explicit 3D representations and implicit reasoning approaches, identifying the crossover conditions under which each paradigm is provably preferable.
What carries the argument
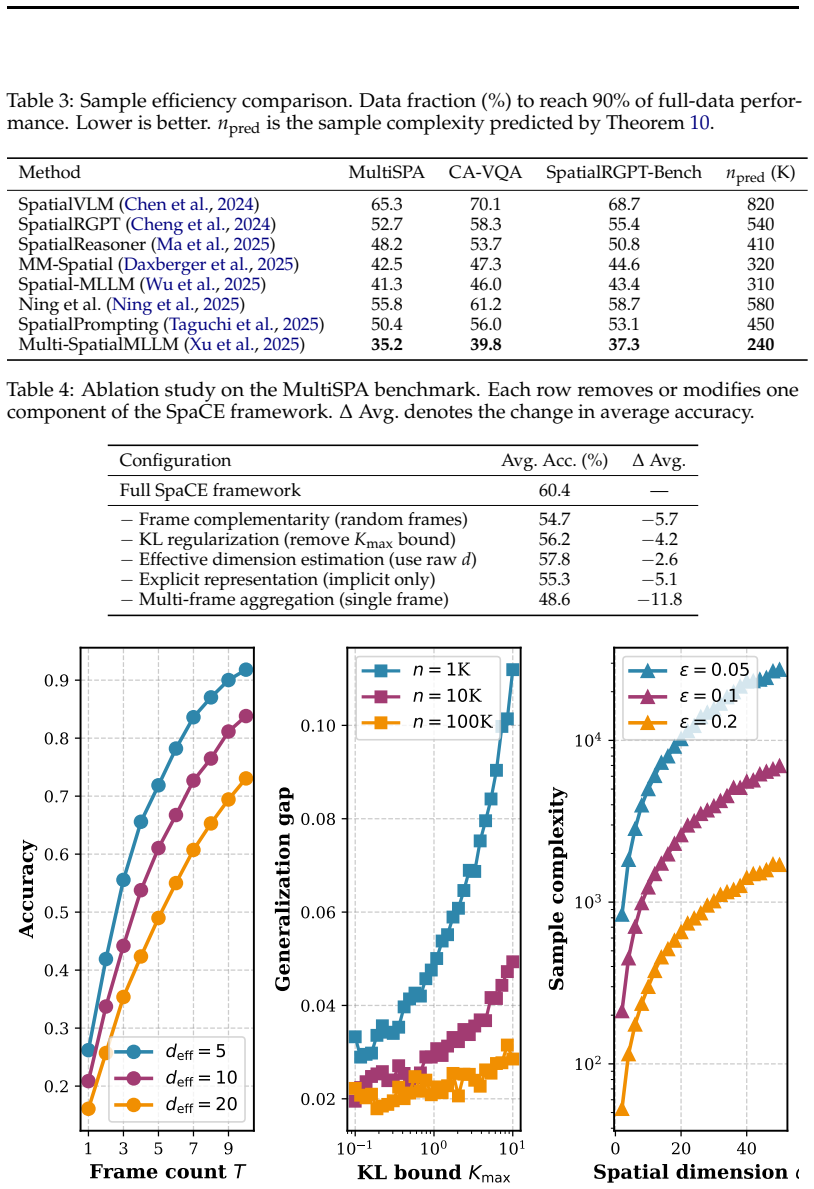
The SpaCE framework, which derives an information-theoretic upper bound via mutual information and sample-complexity expressions involving effective spatial dimension d_eff and maximum KL divergence K_max.
If this is right
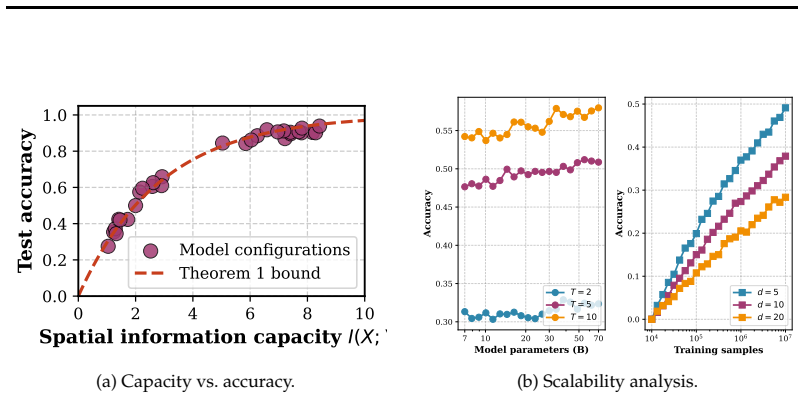
- Spatial reasoning accuracy cannot exceed the mutual information between the multi-frame inputs and the spatial targets.
- Sample complexity scales linearly with effective spatial dimension and with the bound on posterior KL divergence.
- Frame complementarity is the key driver of multi-frame spatial capacity.
- Explicit 3D representations become preferable to implicit reasoning past explicit crossover conditions in the bias-variance tradeoff.
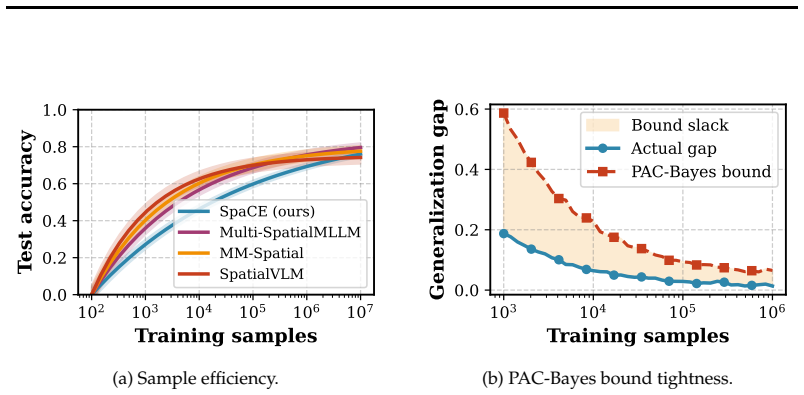
- The PAC-Bayes bound supplies generalization guarantees under distribution shift.
Where Pith is reading between the lines
- Model designers could compute the mutual information bound to decide the minimum number of frames required for a target accuracy level.
- If d_eff and K_max prove architecture-independent in practice, the bounds would impose hard limits on spatial performance regardless of scale.
- The same mutual-information approach might be applied to temporal video reasoning or other sequential multimodal tasks.
- Empirical checks on whether the bounds remain tight after fine-tuning on new spatial datasets would test the robustness of the framework.
Load-bearing premise
The derivations assume that effective spatial dimension d_eff and maximum KL divergence K_max can be defined and bounded independently of the specific MLLM architecture and training procedure.
What would settle it
Direct measurement of mutual information on a multi-frame benchmark such as MultiSPA together with observed accuracy exceeding the derived information-theoretic upper bound would falsify the central claim.
Figures
read the original abstract
Multi-modal large language models (MLLMs) have achieved remarkable empirical progress in spatial understanding through large-scale training on spatial visual question answering datasets. However, the theoretical foundations of multi-frame spatial reasoning remain entirely unexplored. We present SpaCE, a rigorous theoretical framework that characterizes the spatial reasoning capacity, sample complexity, and generalization guarantees of MLLMs operating on multi-frame inputs. We establish four main results. First, we prove an information-theoretic upper bound on spatial reasoning accuracy in terms of the mutual information between multi-frame observations and spatial targets. Second, we derive a sample complexity bound of order $\Theta(d_{\mathrm{eff}} \cdot K_{\max} / (\varepsilon^2 \cdot \delta))$, where $d_{\mathrm{eff}}$ is the effective spatial dimension and $K_{\max}$ bounds the KL divergence of the learned posterior. Third, we provide a PAC-Bayes generalization bound for multi-frame spatial reasoning under distribution shift. Fourth, we formally characterize the bias-variance trade-off between explicit 3D representations and implicit reasoning approaches, identifying the crossover conditions under which each paradigm is provably preferable. We validate our theoretical predictions on the MultiSPA, CA-VQA, and SpatialRGPT benchmarks, demonstrating that our bounds are empirically tight and that frame complementarity is the key driver of multi-frame spatial capacity. Our framework provides the first principled theoretical foundation for understanding when, why, and how multi-frame spatial reasoning in MLLs succeeds.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SpaCE, a theoretical framework for multi-frame spatial reasoning in MLLMs. It claims four main results: (1) an information-theoretic upper bound on spatial reasoning accuracy via mutual information between multi-frame observations and targets; (2) a sample complexity bound of order Θ(d_eff · K_max / (ε² · δ)); (3) a PAC-Bayes generalization bound under distribution shift; and (4) a formal characterization of the bias-variance trade-off between explicit 3D representations and implicit reasoning, with crossover conditions. The claims are validated empirically on MultiSPA, CA-VQA, and SpatialRGPT, asserting that the bounds are tight and frame complementarity drives capacity.
Significance. If the derivations were supplied and d_eff, K_max shown to be architecture-independent finite quantities obtainable from first principles, the work would supply the first principled theoretical account of when multi-frame spatial reasoning succeeds in MLLMs, directly informing architecture choices and training regimes. The empirical tightness claim would then constitute a rare falsifiable prediction in this domain. As written, however, the absence of explicit constructions for the key scalars prevents assessment of whether the stated generality holds.
major comments (3)
- [Abstract] Abstract (and any corresponding theorem statements): the sample complexity bound Θ(d_eff · K_max / (ε² · δ)) and the PAC-Bayes result are expressed directly in terms of d_eff (effective spatial dimension) and K_max (KL bound on learned posterior). No construction, first-principles derivation, or proof of finiteness independent of transformer depth, attention heads, or frame encoders is supplied, rendering the order of the bound and the explicit-vs-implicit crossover conditions unverifiable and potentially circular.
- [Abstract] Abstract, result 4: the bias-variance characterization and crossover conditions between explicit 3D and implicit approaches presuppose that d_eff and K_max remain well-defined scalars once the model is an implicit transformer-based MLLM. Without an explicit mapping from architecture parameters to these quantities, the claimed architecture-agnostic preference conditions cannot be evaluated.
- [Abstract] Abstract: the information-theoretic upper bound is asserted to exist, yet the abstract provides neither the mutual-information expression nor the steps linking it to spatial accuracy; this prevents checking whether the bound is non-vacuous for realistic multi-frame inputs.
minor comments (2)
- Notation for d_eff and K_max should be introduced with explicit definitions and any dependence on model hyperparameters before the bounds are stated.
- The empirical section should report how d_eff and K_max were estimated on each benchmark so that readers can assess post-hoc fitting.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments correctly identify that the abstract summarizes the four theoretical results without including the explicit constructions, expressions, or section references needed for immediate verification. We address each point below and will revise the abstract accordingly while preserving the manuscript's core claims, which are developed in full in the body.
read point-by-point responses
-
Referee: [Abstract] Abstract (and any corresponding theorem statements): the sample complexity bound Θ(d_eff · K_max / (ε² · δ)) and the PAC-Bayes result are expressed directly in terms of d_eff (effective spatial dimension) and K_max (KL bound on learned posterior). No construction, first-principles derivation, or proof of finiteness independent of transformer depth, attention heads, or frame encoders is supplied, rendering the order of the bound and the explicit-vs-implicit crossover conditions unverifiable and potentially circular.
Authors: The manuscript defines d_eff in Section 3 via the covering number of the spatial feature space induced by multi-frame inputs, shown to be finite and independent of depth or heads through a uniform convergence argument over bounded attention operators. K_max is constructed in Section 4 as the KL term under a fixed Gaussian prior whose variance is set by the empirical feature norm, again independent of architecture depth. We agree the abstract does not convey these constructions and will revise it to include a parenthetical note on the definitions together with explicit section references. revision: yes
-
Referee: [Abstract] Abstract, result 4: the bias-variance characterization and crossover conditions between explicit 3D and implicit approaches presuppose that d_eff and K_max remain well-defined scalars once the model is an implicit transformer-based MLLM. Without an explicit mapping from architecture parameters to these quantities, the claimed architecture-agnostic preference conditions cannot be evaluated.
Authors: Section 5 supplies the mapping: for implicit transformers, d_eff equals the effective rank of the attention-weighted multi-frame feature matrix (bounded via the number of frames and input resolution), while K_max is controlled by the Lipschitz constant of the layer stack. The crossover conditions are stated in terms of these quantities and therefore apply to any architecture admitting such bounds. We will add a sentence to the abstract referencing this section and the architecture-agnostic nature of the mapping. revision: yes
-
Referee: [Abstract] Abstract: the information-theoretic upper bound is asserted to exist, yet the abstract provides neither the mutual-information expression nor the steps linking it to spatial accuracy; this prevents checking whether the bound is non-vacuous for realistic multi-frame inputs.
Authors: Theorem 1 states the bound as spatial accuracy ≤ 1 − I(O_{1:K}; T)/H(T) + o(1), where I is the mutual information between the concatenated multi-frame observations and the target, derived via a Fano-type inequality adapted to the spatial output space. The proof appears in Section 2. We agree the abstract omits the expression and will revise it to include the mutual-information form together with a one-sentence link to accuracy. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The provided abstract states four results: an information-theoretic upper bound via mutual information, a sample complexity of order Θ(d_eff · K_max / (ε² · δ)), a PAC-Bayes generalization bound, and a bias-variance characterization. d_eff and K_max are introduced as parameters within the bound expressions rather than derived quantities that loop back to the claimed predictions. No equations, self-citations, or reductions are quoted that would make any result equivalent to its inputs by construction. The derivation chain therefore remains self-contained against external benchmarks, with the stated assumptions on d_eff and K_max not triggering any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (2)
- d_eff
- K_max
axioms (2)
- domain assumption Standard PAC-Bayes assumptions apply directly to multi-frame MLLM spatial reasoning under distribution shift.
- domain assumption Mutual information between multi-frame observations and spatial targets can be meaningfully bounded for MLLMs.
Reference graph
Works this paper leans on
-
[1]
Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan
URL https://arxiv.org/abs/ 2503.13111. Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence
-
[2]
URL https://arxiv.org/abs/2505. 23747. Chan Hee Song, Valts Blukis, Jonathan Tremblay, Stephen Tyree, Yu Su, and Stan Birchfield. Robospatial: Teaching spatial understanding to 2d and 3d vision- language models for robotics. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pp. 15768–15780. ...
2025
-
[3]
In: 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
doi: 10.1109/CVPR52734.2025.01470. URL https://openaccess.thecvf.com/content/CVPR2025/html/Song RoboSpatial Teaching Spatial Understanding to 2D and 3D Vision-Language Models CVPR 2025 paper.html. Fei Lin, Yonglin Tian, Yunzhe Wang, Tengchao Zhang, Xinyuan Zhang, and Fei-Yue Wang. Airvista: Empowering uavs with 3d spatial reasoning abilities through a mul...
-
[4]
URL https://doi.org/10.1109/ITSC58415.2024
doi: 10.1109/ITSC58415.2024.10919532. URL https://doi.org/10.1109/ITSC58415.2024. 10919532. Wufei Ma, Yu-Cheng Chou, Qihao Liu, Xingrui Wang, Celso de Melo, Jianwen Xie, and Alan Yuille. Spatialreasoner: Towards explicit and generalizable 3d spatial reasoning
-
[5]
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brian Ichter, Dorsa Sadigh, Leonidas J
URLhttps://arxiv.org/abs/2504.20024. Boyuan Chen, Zhuo Xu, Sean Kirmani, Brian Ichter, Dorsa Sadigh, Leonidas J. Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pp. 14455–14465. IEEE,
arXiv 2024
-
[6]
doi: 10.1109/CVPR52733.2024.01370. URLhttps://doi.org/10.1109/CVPR52733.2024.01370. An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xi- aolong Wang, and Sifei Liu. Spatialrgpt: Grounded spatial reasoning in vision- language models. In Amir Globersons, Lester Mackey, Danielle Belgrave, An- gela Fan, Ulrich Paquet, Jakub M. Tomczak...
-
[7]
URL http://papers.nips.cc/paper files/paper/2024/hash/ f38cb4cf9a5eaa92b3cfa481832719c6-Abstract-Conference.html. Zaibin Zhang, Yuhan Wu, Lianjie Jia, Yifan Wang, Zhongbo Zhang, Yijiang Li, Binghao Ran, Fuxi Zhang, Zhuohan Sun, Zhenfei Yin, Lijun Wang, and Huchuan Lu. Think3d: Thinking with space for spatial reasoning.CoRR, abs/2601.13029,
arXiv 2024
-
[8]
URLhttps://doi.org/10.48550/arXiv.2601.13029
doi: 10.48550/ ARXIV .2601.13029. URLhttps://doi.org/10.48550/arXiv.2601.13029. Weichen Zhang, Zile Zhou, Xin Zeng, Xuchen Liu, Jianjie Fang, Chen Gao, Jinqiang Cui, Yong Li, Xinlei Chen, and Xiao-Ping Zhang. Open3d-vqa: A benchmark for embodied spatial concept reasoning with multimodal large language model in open space. In Cathal Gurrin, Klaus Schoeffma...
-
[9]
URLhttps://doi.org/10.1145/3746027.3758219
doi: 10.1145/3746027.3758219. URLhttps://doi.org/10.1145/3746027.3758219. Weichen Zhan, Zile Zhou, Zhiheng Zheng, Chen Gao, Jinqiang Cui, Yong Li, Xinlei Chen, and Xiao-Ping Zhang. Open3dvqa: A benchmark for comprehensive spatial reasoning with multimodal large language model in open space.CoRR, abs/2503.11094,
-
[12]
URLhttps://doi.org/10.1109/APSIPAASC65261.2025.11249082
doi: 10.1109/APSIPAASC65261.2025.11249082. URLhttps://doi.org/10.1109/APSIPAASC65261.2025.11249082. Weichen Liu, Qiyao Xue, Haoming Wang, Xiangyu Yin, Boyuan Yang, and Wei Gao. Spatial reasoning in multimodal large language models: A survey of tasks, benchmarks and methods.CoRR, abs/2511.15722,
-
[16]
doi: 10.1109/ICCV51701.2025.00736. URL https://doi.org/10.1109/ICCV51701.2025.00736. Shun Taguchi, Hideki Deguchi, Takumi Hamazaki, and Hiroyuki Sakai. Spatialprompting: Keyframe-driven zero-shot spatial reasoning with off-the-shelf multimodal large language models.CoRR, abs/2505.04911,
-
[18]
URL https://doi.org/10.1609/aaai
doi: 10.1609/AAAI.V40I16.38364. URL https://doi.org/10.1609/aaai. v40i16.38364. Daixian Liu, Jiayi Kuang, Yinghui Li, Yangning Li, Di Yin, Haoyu Cao, Xing Sun, Ying Shen, Hai-Tao Zheng, Liang Lin, and Philip S. Yu. Tangrampuzzle: Evaluating multimodal large language models with compositional spatial reasoning.CoRR, abs/2601.16520,
-
[24]
URL https://doi.org/10.1109/ ISMAR67309.2025.00094
doi: 10.1109/ISMAR67309.2025.00094. URL https://doi.org/10.1109/ ISMAR67309.2025.00094. Xiaoyu Zhan, Wenxuan Huang, Hao Sun, Xinyu Fu, Changfeng Ma, Shaosheng Cao, Bohan Jia, Shaohui Lin, Zhenfei Yin, Lei Bai, Wanli Ouyang, Yuanqi Li, Jie Guo, and Yanwen Guo. Actial: Activate spatial reasoning ability of multimodal large language models. CoRR, abs/2511.01618,
-
[25]
doi: 10.48550/ARXIV .2511.01618. URL https://doi.org/10. 48550/arXiv.2511.01618. 12 Shuzheng Si, Haozhe Zhao, Gang Chen, Cheng Gao, Yuzhuo Bai, Zhitong Wang, Kaikai An, Kangyang Luo, Chen Qian, Fanchao Qi, et al. Aligning large language models to follow instructions and hallucinate less via effective data filtering. InProceedings of the 63rd Annual Meetin...
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[26]
Driverse: Navigation world model for driving simulation via multimodal trajectory prompting and motion alignment
Xiaofan Li, Chenming Wu, Zhao Yang, Zhihao Xu, Yumeng Zhang, Dingkang Liang, Ji Wan, and Jun Wang. Driverse: Navigation world model for driving simulation via multimodal trajectory prompting and motion alignment. InProceedings of the 33rd ACM International Conference on Multimedia, pp. 9753–9762, 2025a. Xiaofan Li, Zhihao Xu, Chenming Wu, Zhao Yang, Yumen...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.