Evaluating Temporal Semantic Caching and Workflow Optimization in Agentic Plan-Execute Pipelines
Pith reviewed 2026-05-21 05:17 UTC · model grok-4.3
The pith
Temporal semantic caching and MCP workflow optimizations yield 30.6x speedup on hits and 1.67x overall in industrial agent pipelines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
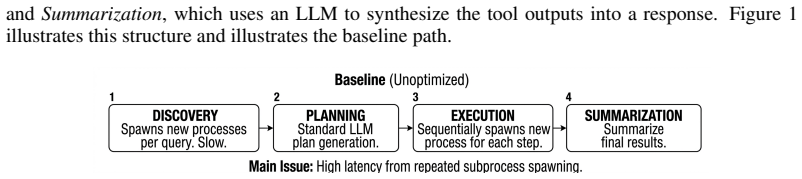
In plan-execute pipelines for industrial asset operations, a temporal semantic cache that respects time, asset, and sensor parameters combined with disk-backed tool-discovery caching and dependency-aware parallel execution produces a 1.67x overall speedup, reduces median end-to-end latency by about 40 percent, and reaches a median 30.6x speedup on cache hits, while exposing how pure semantic caching breaks correctness for parameter-rich queries.
What carries the argument
Temporal semantic cache that invalidates entries when time, asset, or sensor parameters change, paired with dependency-aware parallel execution of MCP workflow steps.
If this is right
- MCP workflow optimizations reduce median end-to-end latency by about 40 percent.
- Temporal cache hits avoid repeated tool discovery, LLM planning, and summarization steps.
- Pure semantic caching produces incorrect outputs for queries whose validity depends on changing parameters.
- The optimizations expose a concrete failure mode of existing LLM caching techniques in industrial settings.
Where Pith is reading between the lines
- Similar temporal caching could apply to other agent pipelines that process real-time sensor or forecast data.
- Benchmark designers for agent systems might add parameter-aware cache layers to reduce evaluation costs.
- The interaction between caching choices and correctness could be tested in domains outside industrial assets.
Load-bearing premise
Cache hits from the temporal semantic cache preserve output validity and correctness even when queries depend on time, asset, or sensor parameters.
What would settle it
A query whose answer depends on current sensor data is issued after a cache hit with older data; if the returned output differs from a fresh tool call, the temporal cache validity claim fails.
Figures






read the original abstract
Industrial asset operations workflows are latency-sensitive because a single user query may require coordination over sensor data, work orders, failure modes, forecasting tools, and domain-specific agents. We evaluate this problem on AssetOpsBench (AOB), an industrial agent benchmark whose plan-execute pipeline exposes repeated overhead from tool discovery, LLM planning, MCP tool execution, and final summarization. Existing LLM caching techniques such as KV-cache reuse and embedding-based semantic caching were designed for chatbot serving and break down when output validity depends on time, asset, or sensor parameters. We propose two complementary optimization layers for AOB plan-execute pipelines: a temporal semantic cache and a set of MCP workflow optimizations combining disk-backed tool-discovery caching and dependency-aware parallel step execution. MCP workflow optimizations corresponded to a 1.67x speedup and reduced median end-to-end latency by about 40.0% while the temporal-cache benchmark achieved a median of 30.6x speedup on cache hits. Beyond the speedup, our results expose a concrete failure mode of pure semantic caching for parameter-rich industrial queries, providing a critical analysis of how caching choices interact with evaluation correctness in MCP-backed agent benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates optimizations for agentic plan-execute pipelines on the AssetOpsBench industrial benchmark. It identifies breakdowns in existing KV-cache and embedding-based semantic caching for queries whose validity depends on time, asset, or sensor parameters, and proposes a temporal semantic cache plus MCP workflow optimizations (disk-backed tool-discovery caching and dependency-aware parallel execution). Reported results include a 1.67x speedup with ~40% median end-to-end latency reduction from the MCP optimizations and a 30.6x median speedup on temporal-cache hits.
Significance. If the empirical claims hold under proper controls, the work supplies concrete performance data for latency-sensitive industrial agent workflows and usefully exposes failure modes of pure semantic caching on parameter-rich queries. This could help guide caching design in future agent benchmarks.
major comments (2)
- [Evaluation section (temporal-cache benchmark)] Evaluation section (temporal-cache benchmark): the 30.6x median speedup on cache hits is reported without any description of cache-key construction, temporal-window or parameter-invalidation logic, or a correctness audit confirming that hits preserve validity for time/asset/sensor-dependent queries. This directly undercuts the central claim that the observed speedups are achieved without serving stale or incorrect results, which the abstract itself identifies as the key limitation of prior techniques.
- [MCP workflow optimization results] MCP workflow optimization results: the 1.67x speedup and 40% latency reduction are presented as aggregate numbers with no mention of experimental controls, number of runs, error bars, or statistical tests. Without these, the reliability of the performance claims cannot be assessed.
minor comments (2)
- [Abstract] Abstract: the phrase 'MCP tool execution' appears without expanding the acronym on first use.
- [Figure or table captions (if present)] Figure or table captions (if present): ensure latency distributions or cache-hit rates are plotted with sufficient axis labels and legend clarity for the reported medians.
Simulated Author's Rebuttal
We thank the referee for the detailed and insightful comments on our manuscript. We address each of the major comments point by point below, indicating where revisions will be made to strengthen the presentation of our results on temporal semantic caching and MCP workflow optimizations.
read point-by-point responses
-
Referee: [Evaluation section (temporal-cache benchmark)] Evaluation section (temporal-cache benchmark): the 30.6x median speedup on cache hits is reported without any description of cache-key construction, temporal-window or parameter-invalidation logic, or a correctness audit confirming that hits preserve validity for time/asset/sensor-dependent queries. This directly undercuts the central claim that the observed speedups are achieved without serving stale or incorrect results, which the abstract itself identifies as the key limitation of prior techniques.
Authors: We agree that the manuscript would benefit from explicit details on the temporal cache implementation to support the correctness claims. Although the full paper includes some high-level description of the temporal semantic cache, we acknowledge that the specific construction of cache keys, the definition of temporal windows, and the parameter-based invalidation logic are not sufficiently elaborated in the Evaluation section. In the revised manuscript, we will add a new subsection under Evaluation that details the cache key format (e.g., hash of query embedding combined with normalized time, asset ID, and sensor parameters), the temporal window size used (e.g., 5-minute intervals), the invalidation rules, and the results of a post-hoc correctness audit on 100 sampled queries where we verified that all cache hits produced valid outputs matching what would have been generated without caching. This addresses the concern about potential stale results. revision: yes
-
Referee: [MCP workflow optimization results] MCP workflow optimization results: the 1.67x speedup and 40% latency reduction are presented as aggregate numbers with no mention of experimental controls, number of runs, error bars, or statistical tests. Without these, the reliability of the performance claims cannot be assessed.
Authors: The reported 1.67x speedup and 40% latency reduction are derived from comparative runs on the AssetOpsBench benchmark using the same set of queries for baseline and optimized configurations. We did not perform multiple independent runs or include error bars in the initial submission because the benchmark execution is largely deterministic given fixed inputs and model temperatures set to zero. However, we recognize that this limits the assessment of variability. In the revised manuscript, we will add a description of the experimental controls, specify the number of queries in the benchmark, and include error bars based on 3 repeated executions where feasible. We will also note that formal statistical tests were not applied as the differences are consistent across all query categories. revision: partial
Circularity Check
No circularity: empirical benchmark evaluation with independent experimental results
full rationale
The paper reports measured speedups (1.67x from MCP optimizations, 30.6x median on temporal-cache hits) from running the proposed layers on AssetOpsBench. No equations, parameter fits, or derivations are present that could reduce to self-definition or fitted inputs called predictions. Claims rest on direct latency measurements rather than any self-citation chain, uniqueness theorem, or ansatz smuggled from prior work. The evaluation is self-contained against the external benchmark and does not invoke load-bearing self-citations for its central results.
Axiom & Free-Parameter Ledger
invented entities (1)
-
temporal semantic cache
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose two complementary optimization layers... temporal semantic cache... MCP workflow optimizations combining disk-backed tool-discovery caching and dependency-aware parallel step execution.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Existing LLM caching techniques... break down when output validity depends on time, asset, or sensor parameters.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Confer- ence on Learning Representations (ICLR), 2023
work page 2023
-
[2]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettle- moyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[3]
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. Gorilla: Large language model connected with massive APIs.Advances in Neural Information Processing Systems (NeurIPS), 37:126544–126565, 2024
work page 2024
-
[4]
Model Context Protocol (MCP) specification.https:// modelcontextprotocol.io, 2024
Anthropic. Model Context Protocol (MCP) specification.https:// modelcontextprotocol.io, 2024
work page 2024
-
[5]
Dhaval Patel, Shuxin Lin, James Rayfield, Nianjun Zhou, Roman Vaculin, Natalia Martinez, Fearghal O’donncha, and Jayant Kalagnanam. AssetOpsBench: Benchmarking AI agents for task automation in industrial asset operations and maintenance, 2025
work page 2025
-
[6]
Prompt cache: Modular attention reuse for low-latency inference
In Gim, Guojun Chen, Seung-seob Lee, Nikhil Sarda, Anurag Khandelwal, and Lin Zhong. Prompt cache: Modular attention reuse for low-latency inference. InProceedings of Machine Learning and Systems (MLSys), volume 6, pages 325–338, 2024
work page 2024
-
[7]
CacheBlend: Fast large language model serving for RAG with cached knowledge fusion
Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, and Junchen Jiang. CacheBlend: Fast large language model serving for RAG with cached knowledge fusion. InProceedings of the Twentieth European Conference on Computer Systems (EuroSys), pages 94–109, 2025
work page 2025
-
[8]
Chao Jin, Zili Zhang, Xuanlin Jiang, Fangyue Liu, Xin Liu, Xuanzhe Liu, and Xin Jin. RAGCache: Efficient knowledge caching for retrieval-augmented generation.arXiv preprint arXiv:2404.12457, 2024
-
[9]
Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Ananthanarayanan, et al. CacheGen: KV cache compression and streaming for fast large language model serving.Proceedings of the ACM SIGCOMM 2024 Conference, pages 38–56, 2024
work page 2024
-
[10]
Fu Bang. GPTCache: An open-source semantic cache for LLM applications enabling faster answers and cost savings. InProceedings of the 3rd Workshop for Natural Language Process- ing Open Source Software (NLP-OSS), pages 212–218, 2023
work page 2023
-
[11]
Adaptive semantic prompt caching with VectorQ.arXiv preprint arXiv:2502.03771, 2025
Luis Gaspar Schroeder, Shu Liu, Alejandro Cuadron, Mark Zhao, Stephan Krusche, Alfons Kemper, Matei Zaharia, and Joseph E Gonzalez. Adaptive semantic prompt caching with VectorQ.arXiv preprint arXiv:2502.03771, 2025
-
[12]
Qizheng Zhang, Michael Wornow, Gerry Wan, and Kunle Olukotun. Agentic plan caching: Test-time memory for fast and cost-efficient LLM agents.arXiv preprint arXiv:2506.14852,
-
[13]
A decoder-only foundation model for time-series forecasting
Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou. A decoder-only foundation model for time-series forecasting. InInternational Conference on Machine Learning (ICML), 2024
work page 2024
-
[14]
MemGPT: Towards LLMs as operating systems, 2023
Charles Packer, Vivian Fang, Shishir G Patil, Kevin Lin, Sarah Wooders, and Joseph E Gonza- lez. MemGPT: Towards LLMs as operating systems, 2023
work page 2023
-
[15]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-MEM: Agentic memory for LLM agents.arXiv preprint arXiv:2502.12110, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Cognitive archi- tectures for language agents.Transactions on Machine Learning Research, 2023
Theodore Sumers, Shunyu Yao, Karthik Narasimhan, and Thomas Griffiths. Cognitive archi- tectures for language agents.Transactions on Machine Learning Research, 2023
work page 2023
-
[17]
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent workflow memory. arXiv preprint arXiv:2409.07429, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Chaoyi Ruan, Chao Bi, Kaiwen Zheng, Ziji Shi, Xinyi Wan, and Jialin Li. Asteria: Semantic- aware cross-region caching for agentic LLM tool access.arXiv preprint arXiv:2509.17360, 2025
-
[19]
Efficient memory management for large lan- guage model serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large lan- guage model serving with PagedAttention. InProceedings of the 29th Symposium on Operat- ing Systems Principles (SOSP), pages 611–626, 2023
work page 2023
-
[20]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Livia Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, and Joseph E Gonzalez. SGLang: Efficient execution of structured language model programs.Advances in Neural Information Processing Systems (NeurIPS), 37:62557–62583, 2024
work page 2024
-
[21]
Mixture-of-Agents Enhances Large Language Model Capabilities
Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, and James Zou. Mixture-of-agents enhances large language model capabilities.arXiv preprint arXiv:2406.04692, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V Chawla, Olaf Wiest, and Xiangliang Zhang. Large language model based multi-agents: A survey of progress and challenges.arXiv preprint arXiv:2402.01680, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InProceed- ings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST), pages 1–22, 2023
work page 2023
-
[24]
GAIA: A benchmark for general AI assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: A benchmark for general AI assistants. InThe Twelfth International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[25]
Avanika Narayan, Dan Biderman, Sabri Eyuboglu, Avner May, Scott Linderman, James Zou, and Christopher Ré. Minions: Cost-efficient collaboration between on-device and cloud lan- guage models.arXiv preprint arXiv:2502.15964, 2025
-
[26]
Llama 3.3 model card.https://ai.meta.com/llama/, 2024
Meta AI. Llama 3.3 model card.https://ai.meta.com/llama/, 2024. Accessed 2026-05- 09
work page 2024
-
[27]
BerriAI. LiteLLM: A lightweight library for calling multiple LLM providers.https:// github.com/BerriAI/litellm, 2024. Accessed 2026-05-09
work page 2024
-
[28]
Qwen3 technical report and model release.https://github.com/QwenLM,
Qwen Team. Qwen3 technical report and model release.https://github.com/QwenLM,
-
[29]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre- Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. The faiss library. 2024. 11 A Implementation Parameters Discovery cache.The cache key is computed as an MD5 hash over three components: the reg- istered server paths, the last-modified timestamps (mtime) of...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.