UnityShots: Memory-Driven Multi-Shot Audio-Video Generation with Boundary-Aware Gating
Pith reviewed 2026-06-26 14:29 UTC · model grok-4.3
The pith
UnityShots generates coherent multi-shot videos by updating two fixed-size memory slots at each cut with a boundary-aware gate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
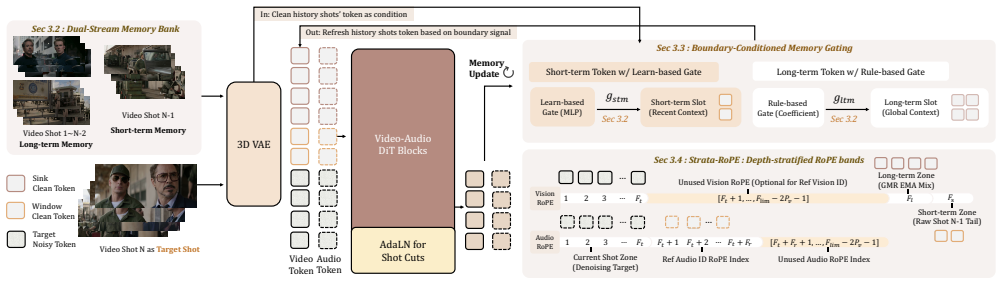
UnityShots maintains two fixed-size memory slots on the LTX-2.3 backbone, a long-term memory slot anchored to the opening shot and a short-term memory slot holding the preceding tail, both updated at every cut by a boundary-conditioned gate that fuses visual cut probability and beat-tracker signals, while injecting a reference speaker token for audio and learning a discrete cut-type prior via AdaLN for transition control.
What carries the argument
Two fixed-size memory slots (long-term anchored to opening shot, short-term to preceding tail) updated by a boundary-conditioned gate fusing visual cut probability and beat-tracker signals.
If this is right
- Multi-shot generation scales without linear memory growth or fixed-length training constraints.
- Speaker identity holds across shots through reference tokens without maintaining an audio memory bank.
- A learned cut-type prior provides direct control over transition strength during inference.
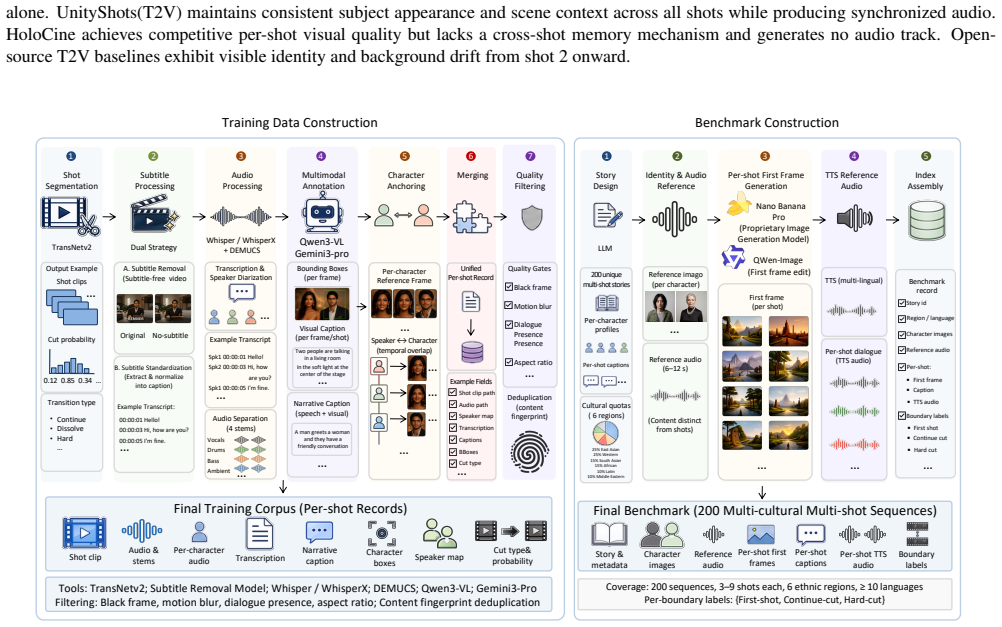
- A new benchmark of 200 multi-cultural sequences with per-shot references and boundary labels supports standardized evaluation.
Where Pith is reading between the lines
- The fixed-slot design may support extension to longer-form content if most cinematic cuts rely on short-range context.
- The same gate structure could be tested on non-cinematic domains such as instructional or documentary video where continuity rules differ.
- Replacing the beat-tracker input with other temporal signals might adapt the method to silent or music-free generation tasks.
Load-bearing premise
The boundary-conditioned gate can preserve subject appearance, scene context, and speaker identity across cuts using only two fixed-size memory slots updated at every cut.
What would settle it
A controlled comparison measuring cross-shot coherence metrics on sequences with five or more shots when the boundary gate is replaced by uniform random updates or when one memory slot is removed.
Figures





read the original abstract
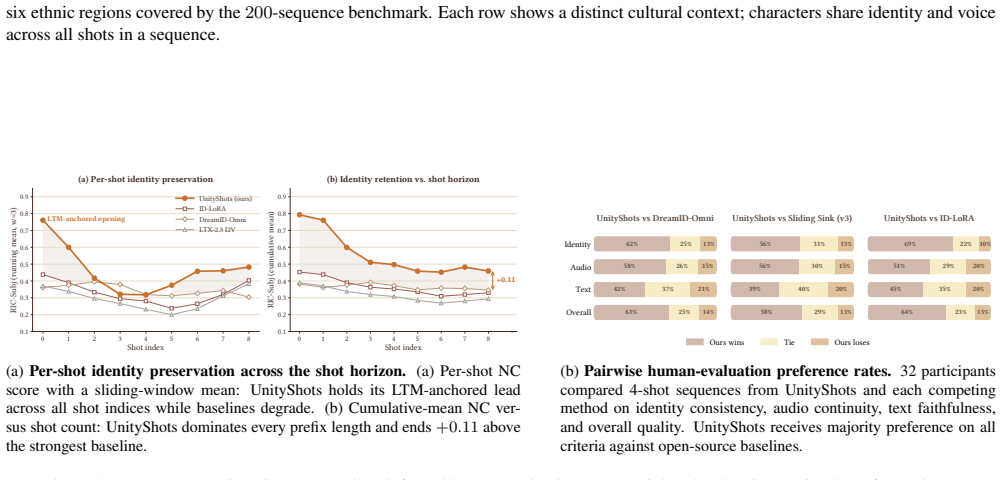
Generating a coherent multi-shot video requires structured cross-shot memory. Subject appearance, scene context, and speaker identity must persist across cuts. Existing approaches either train end-to-end over fixed-length sequences and cannot scale, generate shot-by-shot with memory banks that grow linearly, or orchestrate pretrained generators under an LLM planner without a multi-shot-aware backbone. We present UnityShots, a memory-driven multi-shot audio-video generation system built on LTX-2.3, trained on annotated cinematic and music-video shots. The video stream maintains two fixed-size slots, a long-term memory (LTM) slot anchored to the opening shot and a short-term memory (STM) slot holding the immediately preceding tail, both updated at every cut by a boundary-conditioned gate that fuses visual cut probability and beat-tracker signals. The audio stream injects a reference speaker token at every shot to preserve vocal timbre without a sliding audio bank. A discrete cut-type prior, learned through AdaLN, becomes an inference-time control knob over transition strength. We release a benchmark of $200$ multi-cultural multi-shot sequences spanning six ethnic regions and ten or more languages, with per-shot reference identities, reference audio, and per-boundary transition labels. Evaluated across I2V, T2V, and R2V conditioning modes, UnityShots leads open-source baselines on every cross-shot coherence metric and matches the strongest closed-source system on the multi-shot axes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents UnityShots, a memory-driven multi-shot audio-video generation system built on LTX-2.3. It maintains subject/scene/speaker consistency via two fixed-size memory slots (LTM anchored to the opening shot and STM holding the prior tail) updated at each cut by a boundary-conditioned gate fusing visual cut probability and beat-tracker signals; audio uses a reference speaker token; a discrete cut-type prior is learned via AdaLN for inference-time control. The work also releases a benchmark of 200 multi-cultural multi-shot sequences with per-shot references and transition labels, claiming that UnityShots outperforms open-source baselines on all cross-shot coherence metrics and matches the strongest closed-source systems across I2V/T2V/R2V conditioning modes.
Significance. If the two-slot memory architecture demonstrably preserves coherence without degradation over long sequences, the approach would offer a scalable alternative to linear memory banks or fixed-length end-to-end training. The release of the 200-sequence benchmark with per-boundary labels and multi-cultural coverage is a concrete positive contribution that could support future work on multi-shot consistency.
major comments (1)
- [Architecture description] Architecture description: the central claim that subject appearance, scene context, and speaker identity are maintained across cuts (including sequences of 10 or more shots) rests on the two fixed-size slots (LTM anchored to shot 1 + STM = prior tail) updated by the boundary-conditioned gate. For sequences exceeding ~5 shots, intermediate context from shots 3–8 must be discarded or compressed into the opening-shot LTM; no ablation is reported showing that coherence metrics remain stable once the number of cuts exceeds the two-slot capacity. This directly underpins the cross-shot coherence claims.
minor comments (1)
- [Abstract] Abstract: quantitative results, ablation tables, and error analysis are absent, making it impossible to assess the magnitude of the reported gains over baselines.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of validating long-sequence coherence under the two-slot memory design. We address the concern directly below and commit to strengthening the empirical support in revision.
read point-by-point responses
-
Referee: [Architecture description] Architecture description: the central claim that subject appearance, scene context, and speaker identity are maintained across cuts (including sequences of 10 or more shots) rests on the two fixed-size slots (LTM anchored to shot 1 + STM = prior tail) updated by the boundary-conditioned gate. For sequences exceeding ~5 shots, intermediate context from shots 3–8 must be discarded or compressed into the opening-shot LTM; no ablation is reported showing that coherence metrics remain stable once the number of cuts exceeds the two-slot capacity. This directly underpins the cross-shot coherence claims.
Authors: We agree that an explicit ablation on sequence length is necessary to substantiate the claim that coherence holds for 10+ shots. The two-slot architecture is designed so that the LTM retains an anchor representation of the initial subject/scene/speaker while the boundary-conditioned gate selectively compresses and updates information into the STM at each cut; however, we did not report a controlled study varying shot count in the original submission. In the revised manuscript we will add an ablation evaluating all cross-shot coherence metrics on held-out sequences of 2, 5, 10, and 15 shots (using the released benchmark), with results demonstrating that performance remains stable beyond the nominal two-slot capacity. We will also include qualitative examples of 12-shot sequences to illustrate retention of identity and context. revision: yes
Circularity Check
No circularity: architecture description only
full rationale
The paper presents an engineering system (two fixed-size LTM/STM slots, boundary-conditioned gate fusing cut probability and beat signals, AdaLN cut-type prior, reference speaker token) without any derivation chain, equations, fitted predictions, or first-principles results. No self-citations, ansatzes, or uniqueness theorems are invoked to justify core claims. The abstract and description are self-contained architectural choices evaluated on an external benchmark; nothing reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zhaochong An, Menglin Jia, Haonan Qiu, Zijian Zhou, Xi- aoke Huang, Zhiheng Liu, Weiming Ren, Kumara Kahatapi- tiya, Ding Liu, Sen He, et al. Onestory: Coherent multi- shot video generation with adaptive memory.arXiv preprint arXiv:2512.07802, 2025. 2
arXiv 2025
-
[2]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhao- hai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Jun- yang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shix...
Pith/arXiv arXiv 2025
-
[3]
Max Bain, Jaesung Huh, Tengda Han, and Andrew Zisser- man. Whisperx: Time-accurate speech transcription of long- form audio.arXiv preprint arXiv:2303.00747, 2023. 1
arXiv 2023
-
[4]
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 2
Pith/arXiv arXiv 2023
-
[5]
Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Leo Jing, David Schnurr, Joe Taylor, Troy Luh- man, Eric Luhman, et al. Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024. 2
2024
-
[6]
Seedance 2.0.https : / / seed
ByteDance. Seedance 2.0.https : / / seed . bytedance.com/en/seed2, 2026. 2
2026
-
[7]
Aviad Dahan, Moran Yanuka, Noa Kraicer, Lior Wolf, and Raja Giryes. Id-lora: Identity-driven audio-video personalization with in-context lora.arXiv preprint arXiv:2603.10256, 2026. 2, 6, 3
arXiv 2026
-
[8]
Hybrid spectrogram and waveform source separation.arXiv preprint arXiv:2111.03600, 2021
Alexandre D ´efossez. Hybrid spectrogram and waveform source separation.arXiv preprint arXiv:2111.03600, 2021. 1
arXiv 2021
-
[9]
Clap learning audio concepts from nat- ural language supervision
Benjamin Elizalde, Soham Deshmukh, Mahmoud Al Ismail, and Huaming Wang. Clap learning audio concepts from nat- ural language supervision. InICASSP 2023-2023 IEEE In- ternational Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP), pages 1–5. IEEE, 2023. 5
2023
-
[10]
Beat this! accurate beat tracking without dbn postprocessing
Francesco Foscarin, Jan Schl ¨uter, and Gerhard Widmer. Beat this! accurate beat tracking without dbn postprocessing. arXiv preprint arXiv:2407.21658, 2024. 4, 5
arXiv 2024
-
[11]
Xu Guo, Fulong Ye, Qichao Sun, Liyang Chen, Bingchuan Li, Pengze Zhang, Jiawei Liu, Songtao Zhao, Qian He, and Xiangwang Hou. Dreamid-omni: Unified framework for controllable human-centric audio-video generation.arXiv preprint arXiv:2602.12160, 2026. 3, 5, 6, 2
arXiv 2026
-
[12]
Long context tuning for video generation.arXiv preprint arXiv:2503.10589, 2025
Yuwei Guo, Ceyuan Yang, Ziyan Yang, Zhibei Ma, Zhi- jie Lin, Zhenheng Yang, Dahua Lin, and Lu Jiang. Long context tuning for video generation.arXiv preprint arXiv:2503.10589, 2025. 2
arXiv 2025
-
[13]
Ltx-2: Efficient joint audio-visual foundation model.arXiv preprint arXiv:2601.03233, 2026
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, et al. Ltx-2: Efficient joint audio-visual foundation model.arXiv preprint arXiv:2601.03233, 2026. 2, 3, 6
Pith/arXiv arXiv 2026
-
[14]
Cut2next: Generating next shot via in-context tuning.arXiv preprint arXiv:2508.08244,
Jingwen He, Hongbo Liu, Jiajun Li, Ziqi Huang, Yu Qiao, Wanli Ouyang, and Ziwei Liu. Cut2next: Generating next shot via in-context tuning.arXiv preprint arXiv:2508.08244,
-
[15]
Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 4
2020
-
[16]
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion mod- els.arXiv preprint arXiv:2210.02303, 2022. 2
Pith/arXiv arXiv 2022
-
[17]
Video dif- fusion models.Advances in neural information processing systems, 35:8633–8646, 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video dif- fusion models.Advances in neural information processing systems, 35:8633–8646, 2022. 2
2022
-
[18]
In-context LoRA for diffusion transformers
Lianghua Huang, Wei Wang, Zhi-Fan Wu, Yupeng Shi, Huanzhang Dou, Chen Liang, Yutong Feng, Yu Liu, and Jingren Zhou. In-context LoRA for diffusion transformers. arXiv preprint arXiv:2410.23775, 2024. 2
arXiv 2024
-
[19]
Vbench: Comprehensive bench- mark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive bench- mark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024. 5, 2
2024
-
[20]
Shotadapter: Text-to- multi-shot video generation with diffusion models
Ozgur Kara, Krishna Kumar Singh, Feng Liu, Duygu Cey- lan, James M Rehg, and Tobias Hinz. Shotadapter: Text-to- multi-shot video generation with diffusion models. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 28405–28415, 2025. 2
2025
-
[21]
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 2
Pith/arXiv arXiv 2024
-
[22]
Kling ai.https://klingai
Kuaishou Technology. Kling ai.https://klingai. com/, 2026. 2, 5, 6
2026
-
[23]
Ke Li, Maoliang Li, Jialiang Chen, Jiayu Chen, Zihao Zheng, Shaoqi Wang, and Xiang Chen. Direct: Video mashup cre- ation via hierarchical multi-agent planning and intent-guided editing.arXiv preprint arXiv:2604.04875, 2026. 2, 3
Pith/arXiv arXiv 2026
-
[24]
Zhengyang Liang, Daoan Zhang, Huichi Zhou, Rui Huang, Bobo Li, Yuechen Zhang, Shengqiong Wu, Xiaohan Wang, Jiebo Luo, Lizi Liao, et al. Univa: Universal video agent towards open-source next-generation video generalist.arXiv preprint arXiv:2511.08521, 2025. 2, 3
arXiv 2025
-
[25]
Audioldm 2: Learning holistic audio gen- eration with self-supervised pretraining.IEEE/ACM Trans- actions on Audio, Speech, and Language Processing, 32: 2871–2883, 2024
Haohe Liu, Yi Yuan, Xubo Liu, Xinhao Mei, Qiuqiang Kong, Qiao Tian, Yuping Wang, Wenwu Wang, Yuxuan Wang, and Mark D Plumbley. Audioldm 2: Learning holistic audio gen- eration with self-supervised pretraining.IEEE/ACM Trans- actions on Audio, Speech, and Language Processing, 32: 2871–2883, 2024. 3
2024
-
[26]
Chetwin Low, Weimin Wang, and Calder Katyal. Ovi: Twin backbone cross-modal fusion for audio-video genera- tion.arXiv preprint arXiv:2510.01284, 2025. 6, 2
Pith/arXiv arXiv 2025
-
[27]
Filmweaver: Weaving consistent multi- shot videos with cache-guided autoregressive diffusion
Xiangyang Luo, Qingyu Li, Xiaokun Liu, Wenyu Qin, Miao Yang, Meng Wang, Pengfei Wan, Di Zhang, Kun Gai, and Shao-Lun Huang. Filmweaver: Weaving consistent multi- shot videos with cache-guided autoregressive diffusion. In Proceedings of the AAAI Conference on Artificial Intelli- gence, pages 7689–7697, 2026. 2
2026
-
[28]
Yawen Luo, Xiaoyu Shi, Junhao Zhuang, Yutian Chen, Quande Liu, Xintao Wang, Pengfei Wan, and Tianfan Xue. Shotstream: Streaming multi-shot video generation for inter- active storytelling.arXiv preprint arXiv:2603.25746, 2026. 2
arXiv 2026
-
[29]
Yihao Meng, Hao Ouyang, Yue Yu, Qiuyu Wang, Wen Wang, Ka Leong Cheng, Hanlin Wang, Yixuan Li, Cheng Chen, Yanhong Zeng, et al. Holocine: Holistic generation of cinematic multi-shot long video narratives.arXiv preprint arXiv:2510.20822, 2025. 2, 5, 6
arXiv 2025
-
[30]
Dinov2: Learning robust visual features without supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 5
Pith/arXiv arXiv 2023
-
[31]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 4195–4205,
-
[32]
Movie gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720,
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih- Yao Ma, Ching-Yao Chuang, et al. Movie gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720,
-
[33]
Zero: Memory optimizations toward training trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward training trillion parameter models. InSC20: international confer- ence for high performance computing, networking, storage and analysis, pages 1–16. IEEE, 2020. 5
2020
-
[34]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 2
2022
-
[35]
Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 5
Pith/arXiv arXiv 2010
-
[36]
Transnet v2: An ef- fective deep network architecture for fast shot transition detection
Tom ´as Soucek and Jakub Lokoc. Transnet v2: An ef- fective deep network architecture for fast shot transition detection. corr abs/2008.04838 (2020).arXiv preprint arXiv:2008.04838, 2020. 4, 5, 1
arXiv 2008
-
[37]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
-
[38]
Mova: Towards scalable and synchronized video-audio generation.arXiv preprint arXiv:2602.08794, 2026
OpenMOSS Team, Donghua Yu, Mingshu Chen, Qi Chen, Qi Luo, Qianyi Wu, Qinyuan Cheng, Ruixiao Li, Tianyi Liang, Wenbo Zhang, et al. Mova: Towards scalable and synchronized video-audio generation.arXiv preprint arXiv:2602.08794, 2026. 6, 2, 3
arXiv 2026
-
[39]
Meta audiobox aesthetics: Unified automatic quality assessment for speech, music, and sound
Andros Tjandra, Yi-Chiao Wu, Baishan Guo, John Hoffman, Brian Ellis, Apoorv Vyas, Bowen Shi, Sanyuan Chen, Matt Le, Nick Zacharov, et al. Meta audiobox aesthetics: Unified automatic quality assessment for speech, music, and sound. arXiv preprint arXiv:2502.05139, 2025. 5
Pith/arXiv arXiv 2025
-
[40]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 3
2017
-
[41]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianx- iao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. 2
Pith/arXiv arXiv 2025
-
[42]
Cinemaster: A 3d-aware and controllable frame- work for cinematic text-to-video generation
Qinghe Wang, Yawen Luo, Xiaoyu Shi, Xu Jia, Huchuan Lu, Tianfan Xue, Xintao Wang, Pengfei Wan, Di Zhang, and Kun Gai. Cinemaster: A 3d-aware and controllable frame- work for cinematic text-to-video generation. InProceedings of the Special Interest Group on Computer Graphics and In- teractive Techniques Conference Conference Papers, pages 1–10, 2025. 2
2025
-
[43]
Qinghe Wang, Xiaoyu Shi, Baolu Li, Weikang Bian, Quande Liu, Huchuan Lu, Xintao Wang, Pengfei Wan, Kun Gai, and Xu Jia. Multishotmaster: A controllable multi-shot video generation framework.arXiv preprint arXiv:2512.03041,
-
[44]
Internvid: A large-scale video-text dataset for multimodal understanding and generation
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, et al. Internvid: A large-scale video-text dataset for multimodal understanding and generation. InInter- national Conference on Learning Representations, pages 42055–42079, 2024. 5
2024
-
[45]
Qwen-image technical report,
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, De- qing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingk...
-
[46]
Xiaoxue Wu, Bingjie Gao, Yu Qiao, Yaohui Wang, and Xinyuan Chen. Cinetrans: Learning to generate videos with cinematic transitions via masked diffusion models.arXiv preprint arXiv:2508.11484, 2025. 2
arXiv 2025
-
[47]
Captain cin- ema: Towards short movie generation.arXiv preprint arXiv:2507.18634, 2025
Junfei Xiao, Ceyuan Yang, Lvmin Zhang, Shengqu Cai, Yang Zhao, Yuwei Guo, Gordon Wetzstein, Maneesh Agrawala, Alan L Yuille, and Lu Jiang. Captain cin- ema: Towards short movie generation.arXiv preprint arXiv:2507.18634, 2025. 2
arXiv 2025
-
[48]
Motioncanvas: Cinematic shot design with controllable image-to-video generation
Jinbo Xing, Long Mai, Cusuh Ham, Jiahui Huang, Anirud- dha Mahapatra, Chi-Wing Fu, Tien-Tsin Wong, and Feng Liu. Motioncanvas: Cinematic shot design with controllable image-to-video generation. InProceedings of the Special Interest Group on Computer Graphics and Interactive Tech- niques Conference Conference Papers, pages 1–11, 2025. 2
2025
-
[49]
Cogvideox: Text-to- video diffusion models with an expert transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xi- aohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to- video diffusion models with an expert transformer. InIn- ternational Conference on Learning Representations, pages 83048–83077, 2025. 2
2025
-
[50]
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip- adapter: Text compatible image prompt adapter for text-to- image diffusion models.arXiv preprint arXiv:2308.06721,
-
[51]
Storymem: Multi-shot long video storytelling with memory.arXiv preprint arXiv:2512.19539, 2025
Kaiwen Zhang, Liming Jiang, Angtian Wang, Jacob Zhiyuan Fang, Tiancheng Zhi, Qing Yan, Hao Kang, Xin Lu, and Xingang Pan. Storymem: Multi-shot long video storytelling with memory.arXiv preprint arXiv:2512.19539, 2025. 2, 4, 5
arXiv 2025
-
[52]
Frame context packing and drift prevention in next-frame-prediction video diffusion models
Lvmin Zhang, Shengqu Cai, Muyang Li, Gordon Wetzstein, and Maneesh Agrawala. Frame context packing and drift prevention in next-frame-prediction video diffusion models. Advances in Neural Information Processing Systems, 38: 30546–30566, 2026. 2
2026
-
[53]
Peixuan Zhang, Zijian Jia, Kaiqi Liu, Shuchen Weng, Si Li, and Boxin Shi. Stage: Storyboard-anchored gener- ation for cinematic multi-shot narrative.arXiv preprint arXiv:2512.12372, 2025. 2
arXiv 2025
-
[54]
Fo- leycrafter: Bring silent videos to life with lifelike and syn- chronized sounds.International Journal of Computer Vision, 134(1):46, 2026
Yiming Zhang, Yicheng Gu, Yanhong Zeng, Zhening Xing, Yuancheng Wang, Zhizheng Wu, Bin Liu, and Kai Chen. Fo- leycrafter: Bring silent videos to life with lifelike and syn- chronized sounds.International Journal of Computer Vision, 134(1):46, 2026. 3
2026
-
[55]
Open-sora: Democratizing efficient video production for all.arXiv preprint arXiv:2412.20404, 2024
Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chenhui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You. Open-sora: Democratizing efficient video production for all.arXiv preprint arXiv:2412.20404, 2024. 2
Pith/arXiv arXiv 2024
-
[56]
Jinsong Zhou, Yihua Du, Xinli Xu, Luozhou Wang, Zijie Zhuang, Yehang Zhang, Shuaibo Li, Xiaojun Hu, Bolan Su, and Ying-cong Chen. Videomemory: Toward consis- tent video generation via memory integration.arXiv preprint arXiv:2601.03655, 2026. 2, 3
arXiv 2026
-
[57]
Nipemaembemawili,haraka.\
Yupeng Zhou, Daquan Zhou, Ming-Ming Cheng, Jiashi Feng, and Qibin Hou. Storydiffusion: Consistent self- attention for long-range image and video generation.Ad- vances in Neural Information Processing Systems, 37: 110315–110340, 2024. 2 HoloCine(14B, no Audio) Story:TheShadowWall(Noon-screencaptions,nosignswithEnglishtext)Shot1:Mediumstaticshot.Warmstudiol...
2024
-
[58]
and an inferred transition type (CONTINUE,DISSOLVE, HARD) used to populate the cut-type prior in the boundary- conditioned gating module.(2) Subtitle handling.Each shot is annotated with its burnt-in subtitle text, if any. Dur- ing training,20%of samples randomly apply a subtitle- removal model to produce a subtitle-free variant, enabling the model to gen...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.