UniverSat: Resolution- and Modality-Agnostic Transformers for Earth Observation
Pith reviewed 2026-06-26 08:48 UTC · model grok-4.3
The pith
A shared patch encoder lets one transformer handle Earth observation data from any sensor, resolution, or modality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a Universal Patch Encoder maps patches from arbitrary spatial, spectral, and temporal resolutions and from both optical and non-optical sensors into a shared embedding space with a shared set of weights; this single encoder enables one ViT-style model to be trained via self-supervision on heterogeneous multimodal corpora and to yield robust, sensor-agnostic spatial features that achieve strong results on downstream classification and segmentation benchmarks.
What carries the argument
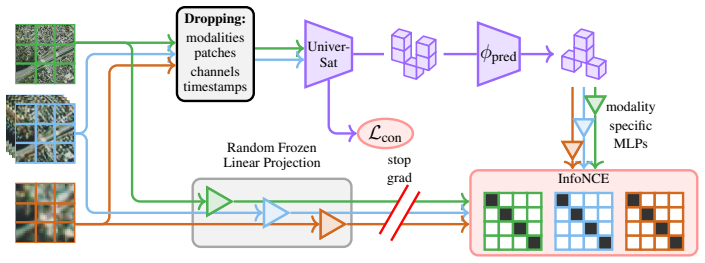
The Universal Patch Encoder, which ingests variable-sized and variable-channel patches and embeds them uniformly into a common space using one set of learned weights.
If this is right
- One model can be trained once on combined optical and non-optical datasets instead of retraining per sensor.
- Learned features remain effective when input resolution or spectral bands change at inference time.
- Self-supervision on heterogeneous corpora produces embeddings that align across modalities without explicit alignment losses.
- Downstream classification and segmentation on standard EO benchmarks improve or match specialized models.
Where Pith is reading between the lines
- Fewer specialized models would be needed across different satellite missions and agencies.
- The same backbone could support rapid adaptation to new sensors by simply adding data rather than redesigning the encoder.
- Extending the encoder to additional modalities such as LiDAR point clouds or hyperspectral bands could further reduce fragmentation in remote-sensing pipelines.
Load-bearing premise
A single set of weights can embed useful information from sensors and resolutions that differ widely without unacceptable loss or the need for modality-specific parameters.
What would settle it
Training the shared encoder on a mixed corpus and then measuring whether per-task accuracy on individual sensors falls below that of separately trained modality-specific encoders.
Figures

read the original abstract
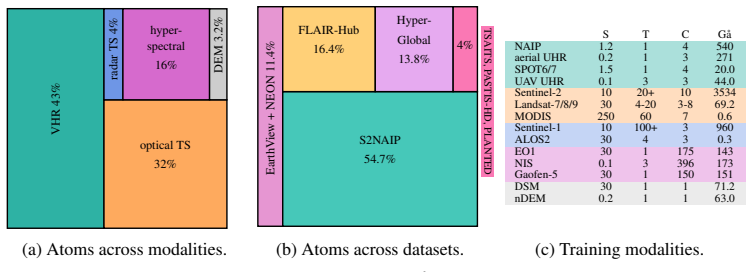
Vision Transformers (ViT) dominate computer vision. However, their reliance on rigid patch projectors hinders transfer to Earth Observation (EO), where input modalities, scales, and resolutions vary widely. We introduce UniverSat, a ViT-style backbone built around a Universal Patch Encoder that maps patches from arbitrary spatial, spectral, and temporal resolutions, and from both optical and non-optical sensors, into a shared embedding space with a shared set of weights. This enables training a single model on heterogeneous multimodal corpora via self-supervision, yielding robust, sensor-agnostic spatial features. We validate this approach with strong results across classification and segmentation on standard EO benchmarks from GeoBench, PANGEABench, and SpectralEarth. Our code and models are available at https://github.com/gastruc/UniverSat.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UniverSat, a Vision Transformer backbone featuring a Universal Patch Encoder that maps input patches from arbitrary spatial, spectral, and temporal resolutions across optical and non-optical sensors into a shared embedding space using a single set of weights. This design supports self-supervised training on heterogeneous multimodal Earth Observation corpora and is validated with results on classification and segmentation tasks from GeoBench, PANGEABench, and SpectralEarth. Code and pretrained models are released.
Significance. A working implementation of a truly modality- and resolution-agnostic patch encoder with shared weights would enable unified self-supervised models for diverse EO sensors, addressing a practical barrier in the field. The public release of code and models supports reproducibility and is a clear strength.
major comments (2)
- [§3.2] §3.2 (Universal Patch Encoder): The description does not specify the operator used to project patches with variable channel counts (e.g., 3-band optical, 2-channel SAR, or >100-band hyperspectral) into a fixed embedding dimension while employing exactly the same weights for all modalities. A standard linear projection requires input dimension = patch_size² × channels, which varies; without an explicit mechanism (fixed padding, per-channel 1×1 conv + aggregation, or similar) that preserves the 'shared set of weights … without requiring modality-specific parameters' claim, the central architectural assertion cannot be verified.
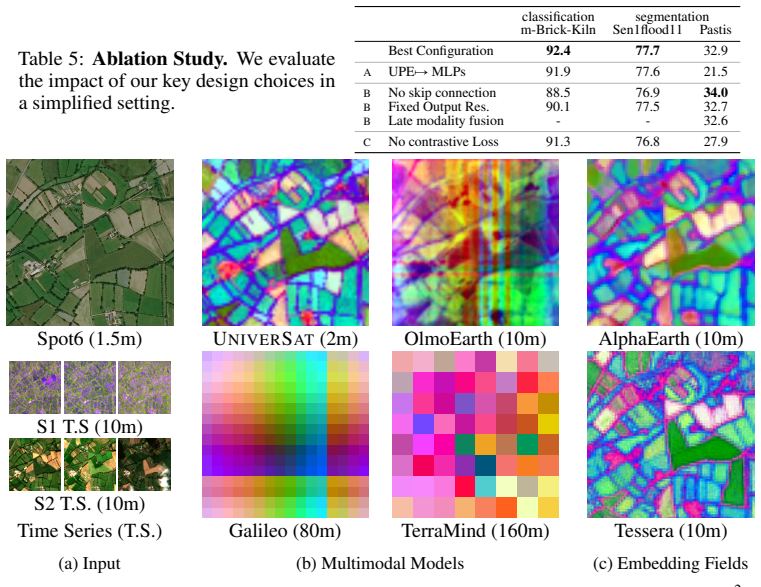
- [§4.2–4.3] §4.2–4.3 (Ablations and cross-sensor results): No ablation isolates the effect of forcing a single shared projection versus modality-specific first layers, nor reports performance when the same weights are applied to inputs whose channel counts differ by an order of magnitude. This leaves the 'sensor-agnostic spatial features' claim without direct empirical support on the load-bearing architectural choice.
minor comments (2)
- The abstract and §1 state 'strong results' without quoting the key metrics or baselines; moving the primary numbers into the introduction would improve readability.
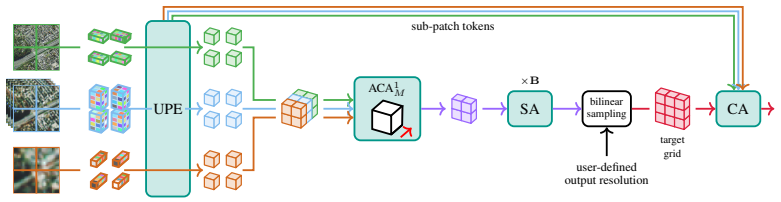
- [Figure 2] Figure 2 (architecture diagram) would benefit from an explicit call-out of the patch-projection weights and how they remain identical across the illustrated modalities.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major comment below and will revise the manuscript to improve clarity and empirical support for the Universal Patch Encoder.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Universal Patch Encoder): The description does not specify the operator used to project patches with variable channel counts (e.g., 3-band optical, 2-channel SAR, or >100-band hyperspectral) into a fixed embedding dimension while employing exactly the same weights for all modalities. A standard linear projection requires input dimension = patch_size² × channels, which varies; without an explicit mechanism (fixed padding, per-channel 1×1 conv + aggregation, or similar) that preserves the 'shared set of weights … without requiring modality-specific parameters' claim, the central architectural assertion cannot be verified.
Authors: We agree that the current description in §3.2 does not provide sufficient detail on the projection operator for variable channel counts. We will revise this section to include an explicit mathematical description of the operator (including how it accommodates differing input dimensions while using exactly the same weights), along with a diagram or pseudocode to make the shared-weights mechanism verifiable. revision: yes
-
Referee: [§4.2–4.3] §4.2–4.3 (Ablations and cross-sensor results): No ablation isolates the effect of forcing a single shared projection versus modality-specific first layers, nor reports performance when the same weights are applied to inputs whose channel counts differ by an order of magnitude. This leaves the 'sensor-agnostic spatial features' claim without direct empirical support on the load-bearing architectural choice.
Authors: We acknowledge that the existing ablations do not isolate the contribution of the shared projection. We will add a new ablation in the revised §4.2–4.3 that directly compares the shared Universal Patch Encoder against modality-specific first-layer variants on the same benchmarks. We will also include results or analysis on inputs with channel counts differing by an order of magnitude to provide empirical support for the sensor-agnostic claim. revision: yes
Circularity Check
No circularity: architecture proposal is self-contained
full rationale
The paper introduces an architectural component (Universal Patch Encoder) and validates it empirically on external benchmarks (GeoBench, PANGEABench, SpectralEarth). No derivation chain, fitted parameters presented as predictions, or self-citation load-bearing steps are present in the provided text. The central claim is an engineering extension of standard ViT self-supervision rather than a quantity defined in terms of its own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InCVPR, 2022. 1
2022
-
[2]
Momentum contrast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. InCVPR, 2020. 1
2020
-
[3]
Self-supervised learning from images with a joint- embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint- embedding predictive architecture. InCVPR, 2023. 1
2023
-
[4]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InICCV, 2021. 1
2021
-
[5]
Dinov2: Learning robust visual features without supervision.TLMR, 2023
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.TLMR, 2023. 1, 7
2023
-
[6]
Galileo: Learning global and local features in pretrained remote sensing models
Gabriel Tseng, Anthony Fuller, Marlena Reil, Henry Herzog, Patrick Beukema, Favyen Bastani, James R Green, Evan Shelhamer, Hannah Kerner, and David Rolnick. Galileo: Learning global and local features in pretrained remote sensing models. InICML, 2025. 1, 2, 3, 7, 18
2025
-
[7]
AnySat: An earth observation model for any resolutions, scales, and modalities
Guillaume Astruc, Nicolas Gonthier, Clement Mallet, and Loic Landrieu. AnySat: An earth observation model for any resolutions, scales, and modalities. InCVPR, 2025. 1, 2, 3, 5, 7, 18
2025
-
[8]
SatMAE: Pre-training transformers for temporal and multi-spectral satellite imagery
Yezhen Cong, Samar Khanna, Chenlin Meng, Patrick Liu, Erik Rozi, Yutong He, Marshall Burke, David Lobell, and Stefano Ermon. SatMAE: Pre-training transformers for temporal and multi-spectral satellite imagery. InNeurIPS, 2022. 1, 2, 3, 18
2022
-
[9]
Terramind: Large-scale generative multimodality for Earth observation.arXiv:2504.11171,
Johannes Jakubik, Felix Yang, Benedikt Blumenstiel, Erik Scheurer, Rocco Sedona, Stefano Maurogiovanni, Jente Bosmans, Nikolaos Dionelis, Valerio Marsocci, Niklas Kopp, et al. Terramind: Large-scale generative multimodality for Earth observation.arXiv:2504.11171,
-
[10]
Christopher F Brown, Michal R Kazmierski, Valerie J Pasquarella, William J Rucklidge, Masha Samsikova, Chenhui Zhang, Evan Shelhamer, Estefania Lahera, Olivia Wiles, Simon Ilyushchenko, et al. AlphaEarth Foundations: An embedding field model for accurate and efficient global mapping from sparse label data.arXiv:2507.22291, 2025. 1, 3, 18
Pith/arXiv arXiv 2025
-
[11]
Scale-MAE: A scale- aware masked autoencoder for multiscale geospatial representation learning
Colorado J Reed, Ritwik Gupta, Shufan Li, Sarah Brockman, Christopher Funk, Brian Clipp, Kurt Keutzer, Salvatore Candido, Matt Uyttendaele, and Trevor Darrell. Scale-MAE: A scale- aware masked autoencoder for multiscale geospatial representation learning. InICCV, 2023. 1, 2, 3, 5, 16, 18
2023
-
[12]
OmniSat: Self- supervised modality fusion for Earth observation
Guillaume Astruc, Nicolas Gonthier, Clement Mallet, and Loic Landrieu. OmniSat: Self- supervised modality fusion for Earth observation. InECCV, 2024. 1, 2, 3, 5, 6, 18
2024
-
[13]
Panopticon: Advancing any-sensor foundation models for earth observation.arXiv:2503.10845, 2025
Leonard Waldmann, Ando Shah, Yi Wang, Nils Lehmann, Adam J Stewart, Zhitong Xiong, Xiao Xiang Zhu, Stefan Bauer, and John Chuang. Panopticon: Advancing any-sensor foundation models for earth observation.arXiv:2503.10845, 2025. 1, 2, 3, 7, 18
arXiv 2025
-
[14]
Jonathan Prexl and Michael Schmitt. SenPa-MAE: Sensor parameter aware masked autoencoder for multi-satellite self-supervised pretraining.arXiv:2408.11000, 2024. 1, 3
arXiv 2024
-
[15]
SMARTIES: Spectrum-aware multi-sensor auto-encoder for remote sensing images
Gencer Sumbul, Chang Xu, Emanuele Dalsasso, and Devis Tuia. SMARTIES: Spectrum-aware multi-sensor auto-encoder for remote sensing images. InICCV, 2025. 1, 2, 3, 18
2025
-
[16]
Zhitong Xiong, Yi Wang, Fahong Zhang, Adam J Stewart, Joëlle Hanna, Damian Borth, Ioannis Papoutsis, Bertrand Le Saux, Gustau Camps-Valls, and Xiao Xiang Zhu. Neural plasticity- inspired foundation model for observing the Earth crossing modalities.arXiv:2403.15356, 2024. 1, 2, 3, 7, 8, 18
arXiv 2024
-
[17]
RAMEN: Resolution-adjustable multimodal encoder for Earth observation.arXiv:2512.05025, 2025
Nicolas Houdré, Diego Marcos, Hugo Riffaud de Turckheim, Dino Ienco, Laurent Wendling, Camille Kurtz, and Sylvain Lobry. RAMEN: Resolution-adjustable multimodal encoder for Earth observation.arXiv:2512.05025, 2025. 1, 2, 3, 8, 18
arXiv 2025
-
[18]
Masked image modeling with denoising contrast
Kun Yi, Yixiao Ge, Xiaotong Li, Shusheng Yang, Dian Li, Jianping Wu, Ying Shan, and Xiaohu Qie. Masked image modeling with denoising contrast. InICLR, 2023. 2 10
2023
-
[19]
OlmoEarth: Stable latent image modeling for multimodal Earth observation
Henry Herzog, Favyen Bastani, Yawen Zhang, Gabriel Tseng, Joseph Redmon, Hadrien Sablon, Ryan Park, Jacob Morrison, Alexandra Buraczynski, Karen Farley, et al. OlmoEarth: Stable latent image modeling for multimodal Earth observation. 2, 3, 6, 7, 17
-
[20]
Geo-bench: Toward foundation models for earth monitoring
Alexandre Lacoste, Nils Lehmann, Pau Rodriguez, Evan Sherwin, Hannah Kerner, Björn Lütjens, Jeremy Irvin, David Dao, Hamed Alemohammad, Alexandre Drouin, et al. Geo-bench: Toward foundation models for earth monitoring. InNeurIPS, 2023. 2, 7
2023
-
[21]
PANGAEA: A global and inclusive benchmark for geospatial foundation models.arXiv:2412.04204, 2024
Valerio Marsocci, Yuru Jia, Georges Le Bellier, David Kerekes, Liang Zeng, Sebastian Hafner, Sebastian Gerard, Eric Brune, Ritu Yadav, Ali Shibli, et al. PANGAEA: A global and inclusive benchmark for geospatial foundation models.arXiv:2412.04204, 2024. 2, 7
arXiv 2024
-
[22]
SpectralEarth: Training hyperspectral foundation models at scale.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2025
Nassim Ait Ali Braham, Conrad M Albrecht, Julien Mairal, Jocelyn Chanussot, Yi Wang, and Xiao Xiang Zhu. SpectralEarth: Training hyperspectral foundation models at scale.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2025. 2, 7, 8
2025
-
[23]
EarthView: A large scale remote sensing dataset for self-supervision
Diego Velazquez, Pau Rodriguez, Sergio Alonso, Josep M Gonfaus, Jordi Gonzalez, Gerardo Richarte, Javier Marin, Yoshua Bengio, and Alexandre Lacoste. EarthView: A large scale remote sensing dataset for self-supervision. InWACV, 2025. 2, 6, 18
2025
-
[24]
FoMo: Multi-modal, multi-scale and multi-task remote sensing foundation models for forest monitoring
Nikolaos Ioannis Bountos, Arthur Ouaknine, Ioannis Papoutsis, and David Rolnick. FoMo: Multi-modal, multi-scale and multi-task remote sensing foundation models for forest monitoring. InAAAI, 2025. 2, 3, 18
2025
-
[25]
Geography-aware self-supervised learning
Kumar Ayush, Burak Uzkent, Chenlin Meng, Kumar Tanmay, Marshall Burke, David Lobell, and Stefano Ermon. Geography-aware self-supervised learning. InICCV, 2021. 2
2021
-
[26]
Seasonal contrast: Unsupervised pre-training from uncurated remote sensing data
Oscar Manas, Alexandre Lacoste, Xavier Giró-i Nieto, David Vazquez, and Pau Rodriguez. Seasonal contrast: Unsupervised pre-training from uncurated remote sensing data. InICCV,
-
[27]
Change-aware sampling and contrastive learning for satellite images
Utkarsh Mall, Bharath Hariharan, and Kavita Bala. Change-aware sampling and contrastive learning for satellite images. InCVPR, 2023. 2
2023
-
[28]
CROCO: Cross-modal contrastive learning for localization of Earth observation data.ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2022
Wei-Hsin Tseng, Hoàng-Ân Lê, Alexandre Boulch, Sébastien Lefèvre, and Dirk Tiede. CROCO: Cross-modal contrastive learning for localization of Earth observation data.ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2022. 2, 3, 5
2022
-
[29]
Zhengpeng Feng, Clement Atzberger, Sadiq Jaffer, Jovana Knezevic, Silja Sormunen, Robin Young, Madeline C Lisaius, Markus Immitzer, Toby Jackson, James Ball, et al. Tessera: Tem- poral embeddings of surface spectra for earth representation and analysis.arXiv:2506.20380,
-
[30]
Bridging remote sensors with multisensor geospatial foundation models
Boran Han, Shuai Zhang, Xingjian Shi, and Markus Reichstein. Bridging remote sensors with multisensor geospatial foundation models. InCVPR, 2024. 2
2024
-
[31]
Towards geospatial foundation models via continual pretraining
Matías Mendieta, Boran Han, Xingjian Shi, Yi Zhu, and Chen Chen. Towards geospatial foundation models via continual pretraining. InICCV, 2023. 2
2023
-
[32]
Self-supervised spatio-temporal representation learning of satellite image time series.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2024
Iris Dumeur, Silvia Valero, and Jordi Inglada. Self-supervised spatio-temporal representation learning of satellite image time series.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2024. 2
2024
-
[33]
Lightweight, pre-trained transformers for remote sensing time-series.arXiv:2304.14065, 2023
Gabriel Tseng, Ivan Zvonkov, Mirali Purohit, David Rolnick, and Hannah Kerner. Lightweight, pre-trained transformers for remote sensing time-series.arXiv:2304.14065, 2023. 3, 18
arXiv 2023
-
[34]
Muhammad Sohail Danish, Muhammad Akhtar Munir, Syed Roshaan Ali Shah, Muham- mad Haris Khan, Rao Muhammad Anwer, Jorma Laaksonen, Fahad Shahbaz Khan, and Salman Khan. TerraFM: A scalable foundation model for unified multisensor earth obser- vation.arXiv:2506.06281, 2025. 3, 18
arXiv 2025
-
[35]
Skysense-o: Towards open-world remote sensing interpretation with vision-centric visual-language modeling
Qi Zhu, Jiangwei Lao, Deyi Ji, Junwei Luo, Kang Wu, Yingying Zhang, Lixiang Ru, Jian Wang, Jingdong Chen, Ming Yang, et al. Skysense-o: Towards open-world remote sensing interpretation with vision-centric visual-language modeling. InCVPR, 2025. 3
2025
-
[36]
MAESTRO: Masked autoencoders for multimodal, multitemporal, and multispectral earth observation data
Antoine Labatie, Michael Vaccaro, Nina Lardiere, Anatol Garioud, and Nicolas Gonthier. MAESTRO: Masked autoencoders for multimodal, multitemporal, and multispectral earth observation data. InWACV, 2026. 3, 18 11
2026
-
[37]
Self- supervised learning in remote sensing: A review.IEEE Geoscience and Remote Sensing Magazine, 2022
Yi Wang, Conrad Albrecht, Nassim Ait Ali Braham, Lichao Mou, and Xiaoxiang Zhu. Self- supervised learning in remote sensing: A review.IEEE Geoscience and Remote Sensing Magazine, 2022. 3
2022
-
[38]
CROMA: Remote sensing representations with contrastive radar-optical masked autoencoders
Anthony Fuller, Koreen Millard, and James R Green. CROMA: Remote sensing representations with contrastive radar-optical masked autoencoders. InNeurIPS, 2023. 3, 7, 8, 18
2023
-
[39]
SkySense V2: A unified foundation model for multi-modal remote sensing
Yingying Zhang, Lixiang Ru, Kang Wu, Lei Yu, Lei Liang, Yansheng Li, and Jingdong Chen. SkySense V2: A unified foundation model for multi-modal remote sensing. InICCV, 2025. 3, 18
2025
-
[40]
DUNIA: Pixel-sized embeddings via cross-modal alignment for earth observation applications
Ibrahim Fayad, Max Zimmer, Martin Schwartz, Fabian Gieseke, Philippe Ciais, Gabriel Be- louze, Sarah Brood, Aurélien de Truchis, and Alexandre d’Aspremont. DUNIA: Pixel-sized embeddings via cross-modal alignment for earth observation applications. InICML, 2025. 3, 18
2025
-
[41]
USat: A unified self-supervised encoder for multi-sensor satellite imagery
Jeremy Irvin, Lucas Tao, Joanne Zhou, Yuntao Ma, Langston Nashold, Benjamin Liu, and Andrew Y Ng. USat: A unified self-supervised encoder for multi-sensor satellite imagery. arXiv:2312.02199, 2023. 3
arXiv 2023
-
[42]
PyViT-FUSE: A foundation model for multi-sensor earth observation data.arXiv:2504.18770, 2025
Manuel Weber and Carly Beneke. PyViT-FUSE: A foundation model for multi-sensor earth observation data.arXiv:2504.18770, 2025. 3
arXiv 2025
-
[43]
FlexiViT: One model for all patch sizes
Lucas Beyer, Pavel Izmailov, Alexander Kolesnikov, Mathilde Caron, Simon Kornblith, Xiaohua Zhai, Matthias Minderer, Michael Tschannen, Ibrahim Alabdulmohsin, and Filip Pavetic. FlexiViT: One model for all patch sizes. InCVPR, 2023. 3, 17
2023
-
[44]
Atomizer: Generalizing to new modalities by breaking satellite images down to a set of scalars
Hugo Riffaud de Turckheim, Sylvain Lobry, Roberto Interdonato, and Diego Marcos. Atomizer: Generalizing to new modalities by breaking satellite images down to a set of scalars. InBMVC,
-
[45]
Axial attention in multidimensional transformers.arXiv:1912.12180, 2019
Jonathan Ho, Nal Kalchbrenner, Dirk Weissenborn, and Tim Salimans. Axial attention in multidimensional transformers.arXiv:1912.12180, 2019. 3, 4, 16
arXiv 1912
-
[46]
Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free
Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, Le Yu, Fei Huang, Suozhi Huang, et al. Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free. InNeurIPS. 5
-
[47]
Vision transformers need registers
Timothée Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers. InICLR, 2024. 5
2024
-
[48]
Towards latent masked image modeling for self-supervised visual representation learning
Yibing Wei, Abhinav Gupta, and Pedro Morgado. Towards latent masked image modeling for self-supervised visual representation learning. InECCV, 2024. 6, 17
2024
-
[49]
FLAIR-HUB : Large-scale multimodal dataset for land cover and crop mapping.ISPRS Journal of Photogram- metry and Remote Sensing, 2026
Anatol Garioud, Sébastien Giordano, Nicolas David, and Nicolas Gonthier. FLAIR-HUB : Large-scale multimodal dataset for land cover and crop mapping.ISPRS Journal of Photogram- metry and Remote Sensing, 2026. 6
2026
-
[50]
Panoptic segmentation of satellite image time series with convolutional temporal attention networks
Vivien Sainte Fare Garnot and Loic Landrieu. Panoptic segmentation of satellite image time series with convolutional temporal attention networks. InICCV, 2021. 6, 7
2021
-
[51]
TreeSatAI Bench- mark Archive: A multi-sensor, multi-label dataset for tree species classification in remote sensing.Earth System Science Data Discussions, 2022
Steve Ahlswede, Christian Schulz, Christiano Gava, Patrick Helber, Benjamin Bischke, Michael Förster, Florencia Arias, Jörn Hees, Begüm Demir, and Birgit Kleinschmit. TreeSatAI Bench- mark Archive: A multi-sensor, multi-label dataset for tree species classification in remote sensing.Earth System Science Data Discussions, 2022. 6
2022
-
[52]
Planted: A dataset for planted forest identification from multi- satellite time series
Luis Miguel Pazos-Outón, Cristina Nader Vasconcelos, Anton Raichuk, Anurag Arnab, Dan Morris, and Maxim Neumann. Planted: A dataset for planted forest identification from multi- satellite time series. InIGARSS, 2024. 6
2024
-
[53]
SatlasPretrain: A large-scale dataset for remote sensing image understanding
Favyen Bastani, Piper Wolters, Ritwik Gupta, Joe Ferdinando, and Aniruddha Kembhavi. SatlasPretrain: A large-scale dataset for remote sensing image understanding. InICCV, 2023. 6, 7, 8
2023
-
[54]
Zooming out on zooming in: Advancing super-resolution for remote sensing.arXiv:2311.18082, 2023
Piper Wolters, Favyen Bastani, and Aniruddha Kembhavi. Zooming out on zooming in: Advancing super-resolution for remote sensing.arXiv:2311.18082, 2023. 6
arXiv 2023
-
[55]
HyperSIGMA: Hyperspectral intelligence comprehension foundation model.TPAMI
Di Wang, Meiqi Hu, Yao Jin, Yuchun Miao, Jiaqi Yang, Yichu Xu, Xiaolei Qin, Jiaqi Ma, Lingyu Sun, Chenxing Li, Chuan Fu, Hongruixuan Chen, Chengxi Han, Naoto Yokoya, Jing Zhang, Minqiang Xu, Lin Liu, Lefei Zhang, Chen Wu, Bo Du, Dacheng Tao, and Liangpei Zhang. HyperSIGMA: Hyperspectral intelligence comprehension foundation model.TPAMI. 6, 8 12
-
[56]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3. arXiv:2508.10104, 2025. 7, 18
Pith/arXiv arXiv 2025
-
[57]
Yi Wang, Zhitong Xiong, Chenying Liu, Adam J. Stewart, Thomas Dujardin, Nikolaos Ioannis Bountos, Angelos Zavras, Franziska Gerken, Ioannis Papoutsis, Laura Leal-Taixé, and Xiao Xi- ang Zhu. Towards a unified copernicus foundation model for Earth vision.arXiv:2503.11849,
-
[58]
Spectralearth: Training hyperspectral foundation models at scale
Nassim Ait Ali Braham, Conrad M Albrecht, Julien Mairal, Jocelyn Chanussot, Yi Wang, and Xiao Xiang Zhu. Spectralearth: Training hyperspectral foundation models at scale. arXiv:2408.08447, 2024. 8
arXiv 2024
-
[59]
Scalable deep learning to identify brick kilns and aid regulatory capacity.Proceedings of the National Academy of Sciences, 2021
Jihyeon Lee, Nina R Brooks, Fahim Tajwar, Marshall Burke, Stefano Ermon, David B Lobell, Debashish Biswas, and Stephen P Luby. Scalable deep learning to identify brick kilns and aid regulatory capacity.Proceedings of the National Academy of Sciences, 2021. 7
2021
-
[60]
Sen1Floods11: A georeferenced dataset to train and test deep learning flood algorithms for Sentinel-1
Derrick Bonafilia, Beth Tellman, Tyler Anderson, and Erica Issenberg. Sen1Floods11: A georeferenced dataset to train and test deep learning flood algorithms for Sentinel-1. InCVPR Workshop EarthVision, 2020. 7
2020
-
[61]
Unified perceptual parsing for scene understanding
Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, and Jian Sun. Unified perceptual parsing for scene understanding. InECCV, 2018. 7
2018
-
[62]
AI4SmallFarms: A dataset for crop field delineation in southeast asian smallholder farms.IEEE Geoscience and Remote Sensing Letters, 2023
Claudio Persello, Jeroen Grift, Xinyan Fan, Claudia Paris, Ronny Hänsch, Mila Koeva, and Andrew Nelson. AI4SmallFarms: A dataset for crop field delineation in southeast asian smallholder farms.IEEE Geoscience and Remote Sensing Letters, 2023. 7
2023
-
[63]
Dingqi Ye, Daniel Kiv, Wei Hu, Jimeng Shi, and Shaowen Wang. Any model, any place, any time: Get remote sensing foundation model embeddings on demand.arXiv:2602.23678, 2026. 8
arXiv 2026
-
[64]
Cluster and predict latents patches for improved masked image modeling.arXiv:2502.08769,
Timothée Darcet, Federico Baldassarre, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Cluster and predict latents patches for improved masked image modeling.arXiv:2502.08769,
-
[65]
Learnable Fourier features for multi-dimensional spatial positional encoding.NeurIPS, 2021
Yang Li, Si Si, Gang Li, Cho-Jui Hsieh, and Samy Bengio. Learnable Fourier features for multi-dimensional spatial positional encoding.NeurIPS, 2021. 16
2021
-
[66]
Rotary position embedding for vision transformer
Byeongho Heo, Song Park, Dongyoon Han, and Sangdoo Yun. Rotary position embedding for vision transformer. InECCV, 2024. 16
2024
-
[67]
Daniela Szwarcman, Sujit Roy, Paolo Fraccaro, Thorsteinn Elí Gíslason, Benedikt Blumenstiel, Rinki Ghosal, Pedro Henrique de Oliveira, Joao Lucas de Sousa Almeida, Rocco Sedona, Yanghui Kang, et al. Prithvi-EO-2.0: A versatile multi-temporal foundation model for earth observation applications.arXiv:2412.02732, 2024. 18 13 UniverSat: Resolution- and Modali...
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.