On Subquadratic Architectures: From Applications to Principles
Pith reviewed 2026-06-27 10:25 UTC · model grok-4.3
The pith
xLSTM outperforms Mamba-2 and Gated DeltaNet on tasks with complex dependencies through more flexible and stable memory correction via gating.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
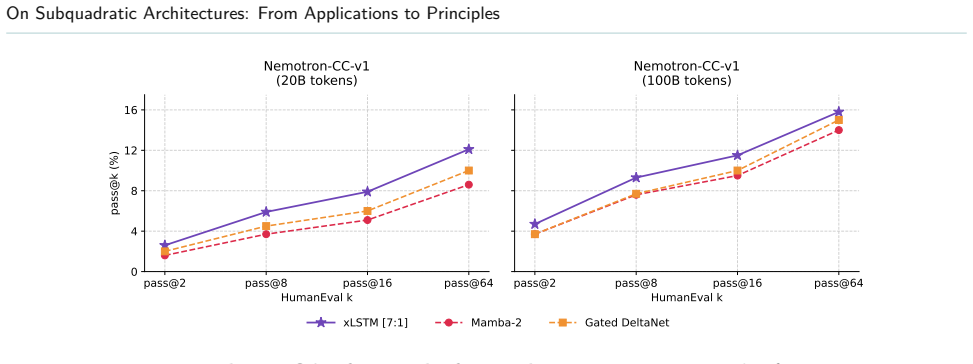
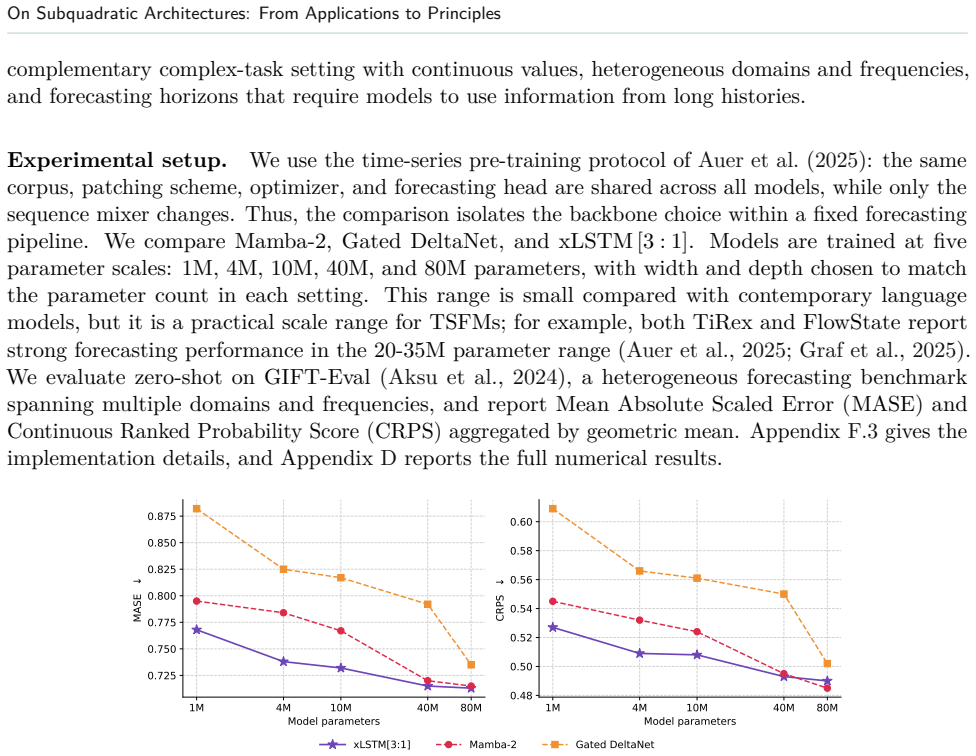
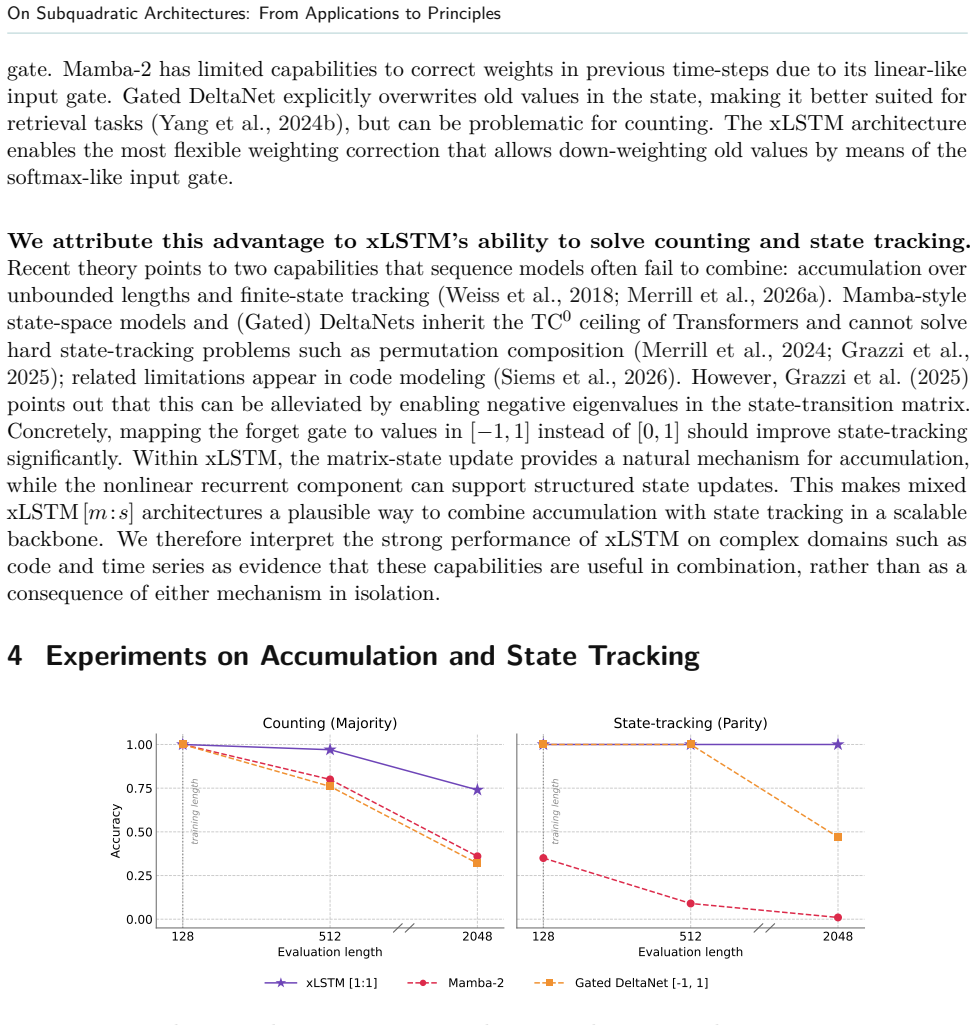
Across these settings, xLSTM delivers the strongest overall performance. To explain xLSTM's advantage, we present a unified formulation and analyze the underlying architectural mechanisms, focusing on state tracking and memory dynamics. Our results show that xLSTM enables more flexible and stable memory correction via its gating scheme. We corroborate these findings on controlled synthetic length-generalization tasks. Overall, our findings indicate that xLSTM's gains on complex tasks stem from robust state tracking and accumulation.
What carries the argument
xLSTM's gating scheme, which supports flexible and stable memory correction within a unified formulation of state tracking and memory dynamics across the three architectures.
If this is right
- xLSTM's gating produces more robust state tracking and accumulation than the mechanisms in Mamba-2 or Gated DeltaNet.
- The performance ordering holds across code pre-training, model distillation, and time-series pre-training.
- The advantage appears in both real-world application tasks and controlled synthetic length-generalization tests.
- Memory correction stability explains why xLSTM scales better on sequences that require tracking intricate dependencies.
Where Pith is reading between the lines
- Architectures could be improved by adding gating components that allow selective memory updates similar to xLSTM.
- The emphasis on state tracking suggests that future comparisons should measure memory dynamics directly rather than only final task accuracy.
- If the pattern generalizes, subquadratic models with explicit correction mechanisms may become the default choice for foundation models operating on long inputs.
Load-bearing premise
The three evaluation settings capture the relevant differences in handling complex dependencies and that performance gaps observed there will appear in other sequence modeling problems.
What would settle it
Consistent outperformance by Mamba-2 or Gated DeltaNet over xLSTM on a fourth task with complex dependencies, such as a held-out long-context code completion benchmark, would falsify the central performance claim.
Figures

read the original abstract
Transformers dominate modern sequence modeling, but their quadratic attention incurs substantial computational cost. Subquadratic architectures offer a scalable alternative. However, it remains unclear which designs yield the most effective sequence models. We compare three leading approaches: xLSTM, Mamba-2, and Gated DeltaNet. We evaluate these models on tasks with complex dependencies: (1) code-model pre-training, (2) distillation of code models from large language models, and (3) pre-training of time-series foundation models. Across these settings, xLSTM delivers the strongest overall performance. To explain xLSTM's advantage, we present a unified formulation and analyze the underlying architectural mechanisms, focusing on state tracking and memory dynamics. Our results show that xLSTM enables more flexible and stable memory correction via its gating scheme. We corroborate these findings on controlled synthetic length-generalization tasks. Overall, our findings indicate that xLSTM's gains on complex tasks stem from robust state tracking and accumulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper compares xLSTM, Mamba-2, and Gated DeltaNet on three tasks with complex dependencies (code-model pre-training, distillation of code models, and time-series foundation model pre-training). It reports that xLSTM achieves the strongest overall performance and attributes this to its gating scheme enabling more flexible and stable memory correction, as analyzed via a unified formulation of state tracking and memory dynamics and corroborated on synthetic length-generalization tasks.
Significance. If the performance ordering and mechanistic attribution hold after proper controls, the work would provide actionable guidance on subquadratic architecture design by identifying gating as a key factor for robust state accumulation on long-range dependency tasks.
major comments (2)
- [Abstract] Abstract and evaluation sections: the claim that performance differences are causally due to the gating scheme for memory correction lacks supporting ablations (e.g., removing the correction term while keeping state dimension and update rules matched across models) or quantitative isolation of the mechanism; without these, alternative explanations such as differences in state size or training dynamics cannot be ruled out.
- [Evaluation settings] The generalization from the three chosen task families to broader 'complex dependencies' in sequence modeling is not supported by evidence that the observed gaps are mechanism-driven rather than domain-specific; the synthetic length-generalization tasks are mentioned but no details on controls for state dimension or update rules are provided to establish causality.
minor comments (2)
- The unified formulation would be clearer if presented with explicit equations showing the common state-update structure for all three models.
- Tables reporting performance should include error bars or statistical tests to allow assessment of whether reported advantages are robust.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important areas for strengthening the causal claims regarding the gating mechanism. We respond to each major comment below and outline planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation sections: the claim that performance differences are causally due to the gating scheme for memory correction lacks supporting ablations (e.g., removing the correction term while keeping state dimension and update rules matched across models) or quantitative isolation of the mechanism; without these, alternative explanations such as differences in state size or training dynamics cannot be ruled out.
Authors: We agree that the manuscript would benefit from explicit ablations that isolate the memory correction term while matching state dimensions and update rules across models. The unified formulation provides a theoretical lens on state tracking and memory dynamics, but does not include the quantitative isolation experiments suggested. We will add these controlled ablations in the revision to rule out confounds such as state size and training dynamics. revision: yes
-
Referee: [Evaluation settings] The generalization from the three chosen task families to broader 'complex dependencies' in sequence modeling is not supported by evidence that the observed gaps are mechanism-driven rather than domain-specific; the synthetic length-generalization tasks are mentioned but no details on controls for state dimension or update rules are provided to establish causality.
Authors: The three tasks span distinct domains that require handling complex dependencies, and the synthetic tasks were intended to isolate mechanism effects via length generalization. However, the current manuscript provides insufficient detail on the controls applied to state dimension and update rules in those experiments. We will expand the synthetic experiments section with explicit descriptions of the matching procedures and additional results showing that xLSTM's advantages hold under these controls. revision: yes
Circularity Check
No significant circularity; empirical comparison with post-hoc analysis
full rationale
The paper advances no first-principles derivation or mathematical prediction chain. Its central claims are empirical performance rankings on three task families plus an interpretive unified formulation for state-tracking analysis. These rest on experimental outcomes rather than any quantity fitted to a subset and then renamed as a prediction, and no load-bearing step reduces to a self-citation whose validity is presupposed by the present work. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Beck, Maximilian and Pöppel, Korbinian and Spanring, Markus and Auer, Andreas and Prudnikova, Oleksandra and Kopp, Michael and Klambauer, Günter and Brandstetter, Johannes and Hochreiter, Sepp , title =. 2024 , booktitle =. doi:10.52202/079017-3417 , url =
-
[2]
2022 , booktitle =
Gu, Albert and Goel, Karan and Re, Christopher , title =. 2022 , booktitle =
2022
-
[3]
2024 , booktitle =
Gu, Albert and Dao, Tri , title =. 2024 , booktitle =
2024
-
[4]
Wu, Yuxin and He, Kaiming , title =. Computer. 2018 , editor =. doi:10.1007/978-3-030-01261-8_1 , url =
-
[5]
Attention
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and. Attention. 2017 , booktitle =
2017
-
[6]
Learning phrase representations using RNN encoder–decoder for statistical machine translation
Cho, Kyunghyun and van Merrienboer, Bart and Gulcehre, Caglar and Bahdanau, Dzmitry and Bougares, Fethi and Schwenk, Holger and Bengio, Yoshua , title =. 2014 , booktitle =. doi:10.3115/v1/D14-1179 , url =
-
[7]
Hochreiter, Sepp and Schmidhuber, Jürgen , title =. 1997 , journal =. doi:10.1162/neco.1997.9.8.1735 , url =
-
[8]
2020 , booktitle =
Katharopoulos, Angelos and Vyas, Apoorv and Pappas, Nikolaos and Fleuret, François , title =. 2020 , booktitle =
2020
-
[9]
2021 , booktitle =
Choromanski, Krzysztof and Likhosherstov, Valerii and Dohan, David and Song, Xingyou and Gane, Andreea and Sarlos, Tamas and Hawkins, Peter and Davis, Jared and Mohiuddin, Afroz and Kaiser, Lukasz and Belanger, David and Colwell, Lucy and Weller, Adrian , title =. 2021 , booktitle =
2021
-
[10]
and Schmidhuber, Jürgen and Cummins, Fred , title =
Gers, Felix A. and Schmidhuber, Jürgen and Cummins, Fred , title =. 1999 , booktitle =. doi:10.1049/cp:19991218 , url =
-
[11]
Peng, Bo and Alcaide, Eric and Anthony, Quentin and Albalak, Alon and Arcadinho, Samuel and Biderman, Stella and Cao, Huanqi and Cheng, Xin and Chung, Michael and Derczynski, Leon and Du, Xingjian and Grella, Matteo and Gv, Kranthi and He, Xuzheng and Hou, Haowen and Kazienko, Przemyslaw and Kocon, Jan and Kong, Jiaming and Koptyra, Bartłomiej and Lau, Ha...
-
[12]
2024 , booktitle =
Dao, Tri and Gu, Albert , title =. 2024 , booktitle =
2024
-
[13]
2022 , booktitle =
Gupta, Ankit and Gu, Albert and Berant, Jonathan , title =. 2022 , booktitle =
2022
-
[14]
2024 , booktitle =
Yang, Songlin and Wang, Bailin and Shen, Yikang and Panda, Rameswar and Kim, Yoon , title =. 2024 , booktitle =
2024
-
[15]
Parallelizing Linear Transformers with the Delta Rule over Sequence Length , url =
Yang, Songlin and Wang, Bailin and Zhang, Yu and Shen, Yikang and Kim, Yoon , title =. 2024 , booktitle =. doi:10.52202/079017-3668 , url =
-
[16]
2024 , booktitle =
Merrill, William and Petty, Jackson and Sabharwal, Ashish , title =. 2024 , booktitle =
2024
-
[17]
Retentive Network: A Successor to Transformer for Large Language Models
Sun, Yutao and Dong, Li and Huang, Shaohan and Ma, Shuming and Xia, Yuqing and Xue, Jilong and Wang, Jianyong and Wei, Furu , title =. 2023 , publisher =. doi:10.48550/arXiv.2307.08621 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.08621 2023
-
[18]
Glorioso, Paolo and Anthony, Quentin and Tokpanov, Yury and Whittington, James and Pilault, Jonathan and Ibrahim, Adam and Millidge, Beren , title =. 2024 , publisher =. doi:10.48550/arXiv.2405.16712 , url =
-
[19]
2025 , booktitle =
Zhang, Michael and Arora, Simran and Chalamala, Rahul and Spector, Benjamin Frederick and Wu, Alan and Ramesh, Krithik and Singhal, Aaryan and Re, Christopher , title =. 2025 , booktitle =
2025
-
[20]
2024 , booktitle =
Xiao, Guangxuan and Tian, Yuandong and Chen, Beidi and Han, Song and Lewis, Mike , title =. 2024 , booktitle =
2024
-
[21]
Longformer: The Long-Document Transformer
Beltagy, Iz and Peters, Matthew E. and Cohan, Arman , title =. 2020 , publisher =. doi:10.48550/arXiv.2004.05150 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2004.05150 2020
-
[22]
2021 , booktitle =
Schlag, Imanol and Irie, Kazuki and Schmidhuber, Jürgen , title =. 2021 , booktitle =
2021
-
[23]
2022 , booktitle =
Hua, Weizhe and Dai, Zihang and Liu, Hanxiao and Le, Quoc , title =. 2022 , booktitle =
2022
-
[24]
Grazzi, Riccardo and Siems, Julien and Zela, Arber and Franke, Jörg K. H. and Hutter, Frank and Pontil, Massimiliano , title =. 2025 , booktitle =
2025
-
[25]
Team, Qwen , xauthor =. Qwen3. 2025 , publisher =. doi:10.48550/arXiv.2505.09388 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[26]
Program Synthesis with Large Language Models
Austin, Jacob and Odena, Augustus and Nye, Maxwell and Bosma, Maarten and Michalewski, Henryk and Dohan, David and Jiang, Ellen and Cai, Carrie and Terry, Michael and Le, Quoc and Sutton, Charles , title =. 2021 , publisher =. doi:10.48550/arXiv.2108.07732 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2108.07732 2021
-
[27]
Training Verifiers to Solve Math Word Problems
Cobbe, Karl and Kosaraju, Vineet and Bavarian, Mohammad and Chen, Mark and Jun, Heewoo and Kaiser, Lukasz and Plappert, Matthias and Tworek, Jerry and Hilton, Jacob and Nakano, Reiichiro and Hesse, Christopher and Schulman, John , title =. 2021 , publisher =. doi:10.48550/arXiv.2110.14168 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2110.14168 2021
-
[28]
2025 , booktitle =
Auer, Andreas and Podest, Patrick and Klotz, Daniel and Böck, Sebastian and Klambauer, Günter and Hochreiter, Sepp , title =. 2025 , booktitle =
2025
-
[29]
and Klambauer, Günter and Böck, Sebastian and Hochreiter, Sepp , title =
Beck, Maximilian and Pöppel, Korbinian and Lippe, Phillip and Kurle, Richard and Blies, Patrick M. and Klambauer, Günter and Böck, Sebastian and Hochreiter, Sepp , title =. 2025 , booktitle =
2025
-
[30]
Bick, Aviv and Li, Kevin Y. and Xing, Eric P. and Kolter, J. Z. and Gu, Albert , title =. 2024 , booktitle =. doi:10.52202/079017-0999 , url =
-
[31]
and Gu, Albert , title =
Bick, Aviv and Katsch, Tobias and Sohoni, Nimit Sharad and Desai, Arjun D. and Gu, Albert , title =. 2025 , booktitle =
2025
-
[32]
Wang, Junxiong and Paliotta, Daniele and May, Avner and Rush, Alexander M. and Dao, Tri , title =. 2024 , booktitle =. doi:10.52202/079017-1996 , url =
-
[33]
Distilling the Knowledge in a Neural Network
Hinton, Geoffrey and Vinyals, Oriol and Dean, Jeff , title =. 2015 , publisher =. doi:10.48550/arXiv.1503.02531 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1503.02531 2015
-
[34]
Team, Jamba , xauthor =. Jamba:. 2025 , booktitle =
2025
-
[35]
2025 , booktitle =
Ren, Liliang and Liu, Yang and Lu, Yadong and Shen, Yelong and Liang, Chen and Chen, Weizhu , title =. 2025 , booktitle =
2025
-
[36]
2024 , booktitle =
Mercat, Jean and Vasiljevic, Igor and Keh, Sedrick Scott and Arora, Kushal and Dave, Achal and Gaidon, Adrien and Kollar, Thomas , title =. 2024 , booktitle =
2024
-
[37]
2025 , booktitle =
Lan, Disen and Sun, Weigao and Hu, Jiaxi and Du, Jusen and Cheng, Yu , title =. 2025 , booktitle =
2025
-
[38]
Chen, Mark and Tworek, Jerry and Jun, Heewoo and Yuan, Qiming and Pinto, Henrique Ponde de Oliveira and Kaplan, Jared and Edwards, Harri and Burda, Yuri and Joseph, Nicholas and Brockman, Greg and Ray, Alex and Puri, Raul and Krueger, Gretchen and Petrov, Michael and Khlaaf, Heidy and Sastry, Girish and Mishkin, Pamela and Chan, Brooke and Gray, Scott and...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2107.03374 2021
-
[39]
2023 , booktitle =
Liu, Jiawei and Xia, Chunqiu Steven and Wang, Yuyao and Zhang, Lingming , title =. 2023 , booktitle =
2023
-
[40]
NVIDIA , xauthor =. Nemotron 3. 2025 , publisher =. doi:10.48550/arXiv.2512.20848 , url =
-
[41]
Why Are Linear RNNs More Parallelizable?
Merrill, William and Jiang, Hongjian and Li, Yanhong and Lin, Anthony and Sabharwal, Ashish , title =. 2026 , publisher =. doi:10.48550/arXiv.2603.03612 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2603.03612 2026
-
[42]
Ba, Jimmy Lei and Kiros, Jamie Ryan and Hinton, Geoffrey E. , title =. 2016 , publisher =. doi:10.48550/arXiv.1607.06450 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1607.06450 2016
-
[43]
Merrill, William , title =. Proceedings of the. 2019 , editor =. doi:10.18653/v1/W19-3901 , url =
-
[44]
GLU Variants Improve Transformer
Shazeer, Noam , title =. 2020 , publisher =. doi:10.48550/arXiv.2002.05202 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2002.05202 2020
-
[45]
2026 , url =
Yang, Songlin and Zhang, Yu , title =. 2026 , url =
2026
-
[46]
2024 , url =
Mishra, Mayank , title =. 2024 , url =
2024
-
[47]
Hauzenberger, Lukas and Schmidinger, Niklas and Schmied, Thomas and Hartl, Anamaria-Roberta and Stap, David and Hoedt, Pieter-Jan and Beck, Maximilian and Böck, Sebastian and Klambauer, Günter and Hochreiter, Sepp , title =. 2026 , publisher =. doi:10.48550/arXiv.2603.15590 , url =
-
[48]
2025 , booktitle =
Goldstein, Daniel and Alcaide, Eric and Lu, Janna and Cheah, Eugene , title =. 2025 , booktitle =
2025
-
[49]
2021 , booktitle =
Hendrycks, Dan and Burns, Collin and Kadavath, Saurav and Arora, Akul and Basart, Steven and Tang, Eric and Song, Dawn and Steinhardt, Jacob , title =. 2021 , booktitle =
2021
-
[50]
2024 , booktitle =
Lightman, Hunter and Kosaraju, Vineet and Burda, Yuri and Edwards, Harrison and Baker, Bowen and Lee, Teddy and Leike, Jan and Schulman, John and Sutskever, Ilya and Cobbe, Karl , title =. 2024 , booktitle =
2024
-
[51]
Du, Wei and Toshniwal, Shubham and Kisacanin, Branislav and Mahdavi, Sadegh and Moshkov, Ivan and Armstrong, George and Ge, Stephen and Minasyan, Edgar and Chen, Feng and Gitman, Igor , title =. 2025 , publisher =. doi:10.48550/arXiv.2512.15489 , url =
-
[52]
Merrill, William and Li, Yanhong and Romero, Tyler and Svete, Anej and Costello, Caia and Dasigi, Pradeep and Groeneveld, Dirk and Heineman, David and Kuehl, Bailey and Lambert, Nathan and Li, Chuan and Lo, Kyle and Malik, Saumya and Matusz, D. J. and Minixhofer, Benjamin and Morrison, Jacob and Soldaini, Luca and Timbers, Finbarr and Walsh, Pete and Smit...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.03444 2026
-
[53]
Sarrof, Yash and Veitsman, Yana and Hahn, Michael , title =. 2024 , booktitle =. doi:10.52202/079017-1304 , url =
-
[54]
and Wang, Hao and Mahoney, Michael W
Ansari, Abdul Fatir and Stella, Lorenzo and Turkmen, Ali Caner and Zhang, Xiyuan and Mercado, Pedro and Shen, Huibin and Shchur, Oleksandr and Rangapuram, Syama Sundar and Arango, Sebastian Pineda and Kapoor, Shubham and Zschiegner, Jasper and Maddix, Danielle C. and Wang, Hao and Mahoney, Michael W. and Torkkola, Kari and Wilson, Andrew Gordon and Bohlke...
2024
-
[55]
An Empirical Study of Mamba-based Language Models
Waleffe, Roger and Byeon, Wonmin and Riach, Duncan and Norick, Brandon and Korthikanti, Vijay and Dao, Tri and Gu, Albert and Hatamizadeh, Ali and Singh, Sudhakar and Narayanan, Deepak and Kulshreshtha, Garvit and Singh, Vartika and Casper, Jared and Kautz, Jan and Shoeybi, Mohammad and Catanzaro, Bryan , title =. 2024 , publisher =. doi:10.48550/arXiv.24...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.07887 2024
-
[56]
2024 , booktitle =
Woo, Gerald and Liu, Chenghao and Kumar, Akshat and Xiong, Caiming and Savarese, Silvio and Sahoo, Doyen , title =. 2024 , booktitle =
2024
-
[57]
2024 , booktitle =
Das, Abhimanyu and Kong, Weihao and Sen, Rajat and Zhou, Yichen , title =. 2024 , booktitle =
2024
-
[58]
Cohen, Ben and Khwaja, Emaad and Wang, Kan and Masson, Charles and Ramé, Elise and Doubli, Youssef and Abou-Amal, Othmane , title =. 2024 , publisher =. doi:10.48550/arXiv.2407.07874 , url =
-
[59]
NeurIPS Workshop on Time Series in the Age of Large Models , year =
Aksu, Taha and Woo, Gerald and Liu, Juncheng and Liu, Xu and Liu, Chenghao and Savarese, Silvio and Xiong, Caiming and Sahoo, Doyen , title =. NeurIPS Workshop on Time Series in the Age of Large Models , year =
-
[60]
2025 , booktitle =
Moroshan, Vladyslav and Siems, Julien and Zela, Arber and Carstensen, Timur and Hutter, Frank , title =. 2025 , booktitle =
2025
-
[61]
Team, Kimi , xauthor =. Kimi. 2025 , publisher =. doi:10.48550/arXiv.2510.26692 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.26692 2025
-
[62]
2025 , booktitle =
Siems, Julien and Carstensen, Timur and Zela, Arber and Hutter, Frank and Pontil, Massimiliano and Grazzi, Riccardo , title =. 2025 , booktitle =
2025
-
[63]
2026 , publisher =
Siems, Julien and Grazzi, Riccardo and Kalinin, Kirill and Ballani, Hitesh and Rahmani, Babak , title =. 2026 , publisher =
2026
-
[64]
Recent Advances in Time Series Foundation Models Have We Reached the 'BERT Moment'? , year =
Graf, Lars and Ortner, Thomas and Woźniak, Stanisław and Pantazi, Angeliki , title =. Recent Advances in Time Series Foundation Models Have We Reached the 'BERT Moment'? , year =
-
[65]
Weiss, Gail and Goldberg, Yoav and Yahav, Eran , title =. Proceedings of the 56th. 2018 , editor =. doi:10.18653/v1/P18-2117 , url =
-
[66]
Proceedings of BigScience Episode
Black, Sidney and Biderman, Stella and Hallahan, Eric and Anthony, Quentin and Gao, Leo and Golding, Laurence and He, Horace and Leahy, Connor and McDonell, Kyle and Phang, Jason and Pieler, Michael and Prashanth, Usvsn Sai and Purohit, Shivanshu and Reynolds, Laria and Tow, Jonathan and Wang, Ben and Weinbach, Samuel , title =. Proceedings of. 2022 , edi...
-
[67]
2026 , booktitle =
Beck, Maximilian and Schweighofer, Kajetan and Böck, Sebastian and Lehner, Sebastian and Hochreiter, Sepp , title =. 2026 , booktitle =
2026
-
[68]
and Bohn, Jeremias and Kelber, Josefin and Mosca, Edoardo and Groh, Georg , title =
Fichtl, Alexander M. and Bohn, Jeremias and Kelber, Josefin and Mosca, Edoardo and Groh, Georg , title =. 2025 , publisher =. doi:10.48550/arXiv.2510.05364 , url =
-
[69]
, title =
Deletang, Gregoire and Ruoss, Anian and Grau-Moya, Jordi and Genewein, Tim and Wenliang, Li Kevin and Catt, Elliot and Cundy, Chris and Hutter, Marcus and Legg, Shane and Veness, Joel and Ortega, Pedro A. , title =. 2023 , booktitle =
2023
-
[70]
2023 , booktitle =
Liu, Bingbin and Ash, Jordan and Goel, Surbhi and Krishnamurthy, Akshay and Zhang, Cyril , title =. 2023 , booktitle =
2023
-
[71]
International Conference on Learning Representations , year=
NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE , author=. International Conference on Learning Representations , year=
-
[72]
1991 , publisher=
Neural sequence chunkers , author=. 1991 , publisher=
1991
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.