UniRTL: Unifying Code and Graph for Robust RTL Representation Learning
Pith reviewed 2026-06-28 23:46 UTC · model grok-4.3
The pith
UniRTL learns unified RTL representations by jointly pretraining on code and its control data flow graph.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
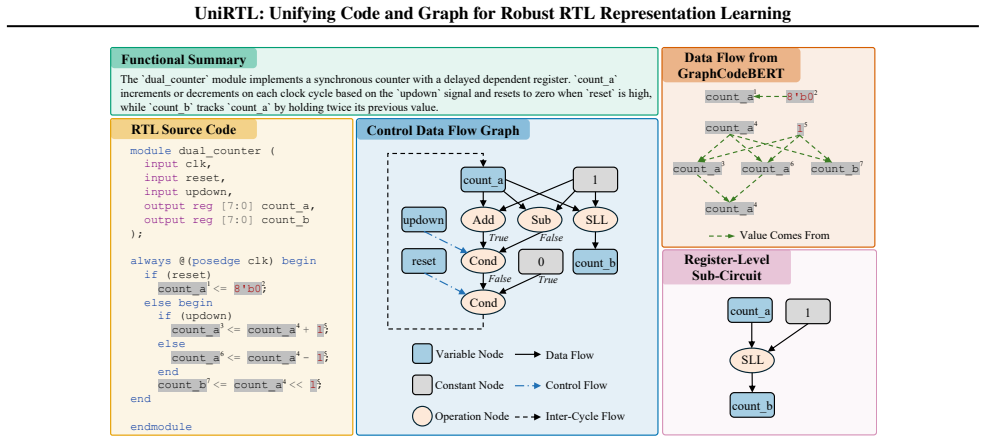
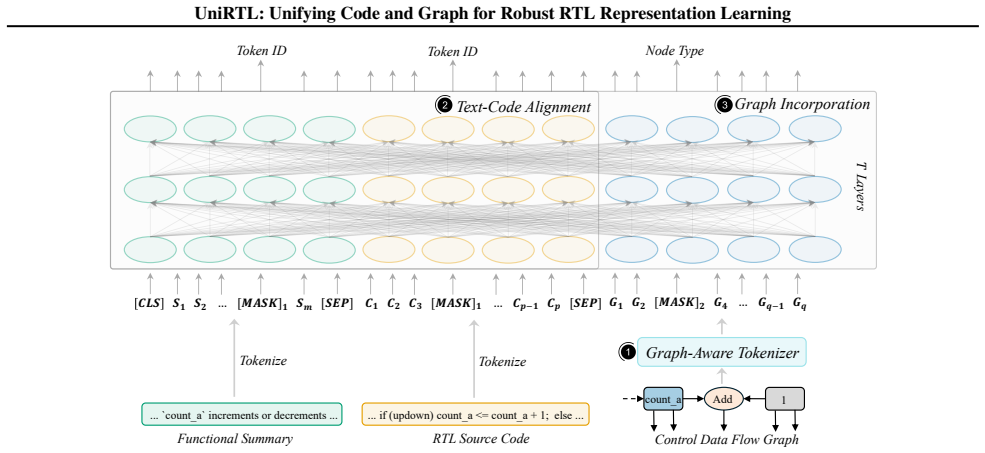
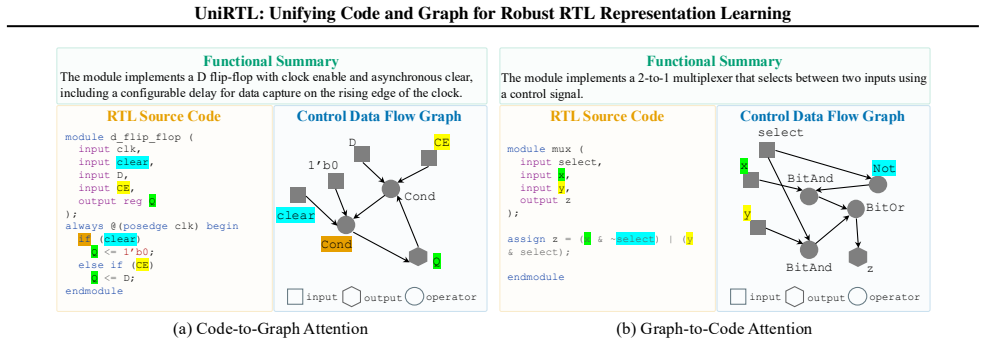
UniRTL is a multimodal pretraining framework that learns unified RTL representations by jointly leveraging code and CDFG, achieving fine-grained alignment through mutual masked modeling and a hierarchical training strategy that first uses a pretrained graph-aware tokenizer and staged alignment of text and code before integrating the graph.
What carries the argument
UniRTL framework that performs mutual masked modeling between code and CDFG inside a staged training schedule that begins with text-code alignment and then adds graph integration.
If this is right
- Representations trained on both modalities produce higher accuracy than code-only or graph-only baselines on circuit performance prediction.
- The same representations improve retrieval of functionally similar RTL modules compared with prior single-modality methods.
- The staged training schedule allows the model to absorb structural information without overwriting semantic signals learned earlier.
- The resulting representations can serve as a shared foundation for multiple downstream hardware automation tasks.
Where Pith is reading between the lines
- The same alignment technique could be tested on other hardware description languages or on netlist-level graphs to check whether the benefit is specific to RTL.
- If the joint representations reduce the amount of labeled data needed for new tasks, they could lower the barrier for applying machine learning to smaller design teams.
- Extending the mutual masking objective to include timing or power reports might further enrich the learned features without changing the core architecture.
- The hierarchical schedule offers a template for adding additional modalities such as simulation waveforms once the code-graph alignment is stable.
Load-bearing premise
The control data flow graph and the RTL code supply complementary information whose integration is required for a complete understanding of the design.
What would settle it
A controlled experiment in which an ablation that removes either the code modality or the graph modality matches or exceeds UniRTL accuracy on both performance prediction and code retrieval would falsify the necessity of the joint approach.
Figures
read the original abstract
Developing effective representations for register transfer level (RTL) designs is crucial for accelerating the hardware design workflow. Existing approaches, however, typically rely on a single data modality, either the RTL code or its associated graph-based representation, limiting the expressiveness and generalization ability of the learned representations. For RTL, the control data flow graph (CDFG) offers a comprehensive structural representation that preserves complete information, while the code modality explicitly encodes semantic and functional information. We argue that integrating these complementary modalities is essential for a thorough understanding of RTL designs. To this end, we propose UniRTL, a multimodal pretraining framework that learns unified RTL representations by jointly leveraging code and CDFG. UniRTL achieves fine-grained alignment between code and graph through mutual masked modeling and employs a hierarchical training strategy that incorporates a pretrained graph-aware tokenizer and staged alignment of text (i.e., functional summary) and code prior to graph integration. We evaluate UniRTL on two downstream tasks, performance prediction and code retrieval, under multiple settings. Experimental results show that UniRTL consistently outperforms prior methods, establishing it as a more robust and powerful foundation for advancing hardware design automation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes UniRTL, a multimodal pretraining framework for RTL designs that jointly leverages code and control data flow graph (CDFG) modalities via mutual masked modeling for fine-grained alignment, a hierarchical training strategy with a pretrained graph-aware tokenizer, and staged alignment of text and code prior to graph integration. It evaluates the approach on performance prediction and code retrieval tasks under multiple settings and claims consistent outperformance over prior methods, positioning it as a robust foundation for hardware design automation.
Significance. If the empirical claims hold under rigorous validation, the work could meaningfully advance RTL representation learning by demonstrating the value of complementary code and structural modalities, potentially improving generalization in hardware design tasks.
major comments (1)
- Abstract: the central claim of consistent outperformance on performance prediction and code retrieval is stated without any experimental details, baselines, metrics, datasets, or data-handling procedures, rendering it impossible to assess whether the data supports the claims.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater specificity in the abstract. We agree that providing key experimental context will strengthen the presentation and will revise the abstract accordingly in the next version.
read point-by-point responses
-
Referee: Abstract: the central claim of consistent outperformance on performance prediction and code retrieval is stated without any experimental details, baselines, metrics, datasets, or data-handling procedures, rendering it impossible to assess whether the data supports the claims.
Authors: We acknowledge that the current abstract is concise and omits specific details. In the revision we will add a brief clause noting the primary datasets (RTL benchmarks from OpenCores and industrial sources), representative baselines (CodeBERT, GraphCodeBERT, and prior RTL-specific models), core metrics (MAE/RMSE for performance prediction; Recall@1/5/10 and MRR for retrieval), and that all experiments follow standard train/validation/test splits with results reported in Section 4. This keeps the abstract within length limits while enabling readers to gauge the claims. Full experimental protocols remain in the main body. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents UniRTL as a multimodal pretraining framework that jointly leverages RTL code and CDFG via mutual masked modeling and staged alignment, with performance claims resting on empirical evaluations across downstream tasks (performance prediction, code retrieval). No load-bearing step reduces a prediction or result to its own inputs by construction, no self-definitional equivalence appears in the described methodology, and any self-citations are not invoked to justify uniqueness or force the central architecture. The derivation remains self-contained against external benchmarks and experimental results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption CDFG offers a comprehensive structural representation that preserves complete information for RTL designs.
- domain assumption Code modality explicitly encodes semantic and functional information.
Reference graph
Works this paper leans on
-
[1]
Bai, J., Bai, S., Chu, Y ., Cui, Z., Dang, K., Deng, X., Fan, Y ., Ge, W., Han, Y ., Huang, F., et al. Qwen technical report.arXiv preprint arXiv:2309.16609,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Speech- bert: An audio-and-text jointly learned language model for end-to-end spoken question answering
Chuang, Y .-S., Liu, C.-L., Lee, H.-y., and Lee, L.-s. Speech- bert: An audio-and-text jointly learned language model for end-to-end spoken question answering. InProc. In- terspeech 2020, pp. 4168–4172,
2020
-
[3]
Bert: Pre-training of deep bidirectional transformers for lan- guage understanding
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pre-training of deep bidirectional transformers for lan- guage understanding. InProceedings of the 2019 confer- ence of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp. 4171–4186,
2019
-
[4]
Codebert: A pre-trained model for programming and natural lan- guages
Feng, Z., Guo, D., Tang, D., Duan, N., Feng, X., Gong, M., Shou, L., Qin, B., Liu, T., Jiang, D., et al. Codebert: A pre-trained model for programming and natural lan- guages. InFindings of the Association for Computational Linguistics: EMNLP 2020, pp. 1536–1547,
2020
-
[5]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
Guo, D., Zhu, Q., Yang, D., Xie, Z., Dong, K., Zhang, W., Chen, G., Bi, X., Wu, Y ., Li, Y ., et al. Deepseek-coder: When the large language model meets programming–the rise of code intelligence.arXiv preprint arXiv:2401.14196,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
CodeSearchNet Challenge: Evaluating the State of Semantic Code Search
Husain, H., Wu, H.-H., Gazit, T., Allamanis, M., and Brockschmidt, M. Codesearchnet challenge: Evaluat- ing the state of semantic code search.arXiv preprint arXiv:1909.09436,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[8]
Nv-embed: Improved techniques for training llms as generalist embedding models
Lee, C., Roy, R., Xu, M., Raiman, J., Shoeybi, M., Catan- zaro, B., and Ping, W. Nv-embed: Improved techniques for training llms as generalist embedding models. In International Conference on Learning Representations, volume 2025, pp. 79310–79333,
2025
-
[9]
Craftrtl: High- quality synthetic data generation for verilog code models with correct-by-construction non-textual representations and targeted code repair
Liu, M., Tsai, Y .-D., Zhou, W., and Ren, H. Craftrtl: High- quality synthetic data generation for verilog code models with correct-by-construction non-textual representations and targeted code repair. InInternational Conference on Learning Representations, volume 2025, pp. 90377– 90422, 2025a. Liu, S., Fang, W., Lu, Y ., Wang, J., Zhang, Q., Zhang, H., a...
2025
-
[10]
Beyond Tokens: Enhancing RTL Quality Estimation via Structural Graph Learning
Liu, Y ., Xu, C., Zhou, Y ., Li, Z., and Xu, Q. Deeprtl: Bridg- ing verilog understanding and generation with a unified representation model. InThe Thirteenth International Conference on Learning Representations, 2025b. Liu, Y ., Zhang, H., Wang, Y ., Tsaras, D., Chen, L., Yuan, M., and Xu, Q. Beyond tokens: Enhancing rtl quality estimation via structural...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Mteb: Massive text embedding benchmark
Muennighoff, N., Tazi, N., Magne, L., and Reimers, N. Mteb: Massive text embedding benchmark. InProceed- ings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pp. 2014– 2037,
2014
-
[12]
Generative representational in- struction tuning
Muennighoff, N., Su, H., Wang, L., Yang, N., Wei, F., Yu, T., Singh, A., and Kiela, D. Generative representational in- struction tuning. InInternational Conference on Learning Representations, volume 2025, pp. 45544–45613,
2025
-
[13]
Text and Code Embeddings by Contrastive Pre-Training
Neelakantan, A., Xu, T., Puri, R., Radford, A., Han, J. M., Tworek, J., Yuan, Q., Tezak, N., Kim, J. W., Hallacy, C., et al. Text and code embeddings by contrastive pre- training.arXiv preprint arXiv:2201.10005,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Oord, A. v. d., Li, Y ., and Vinyals, O. Representation learn- ing with contrastive predictive coding.arXiv preprint arXiv:1807.03748,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Code Llama: Open Foundation Models for Code
Roziere, B., Gehring, J., Gloeckle, F., Sootla, S., Gat, I., Tan, X. E., Adi, Y ., Liu, J., Sauvestre, R., Remez, T., et al. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950,
work page internal anchor Pith review Pith/arXiv arXiv
- [16]
-
[17]
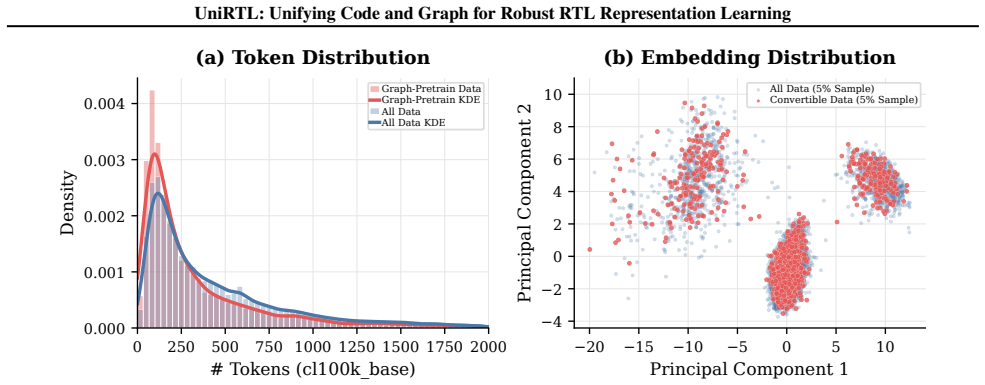
We compare the full pretraining dataset and the subset of designs successfully converted into CDFGs using token-count distributions and UniRTL embedding distributions
12 UniRTL: Unifying Code and Graph for Robust RTL Representation Learning 0 250 500 750 1000 1250 1500 1750 2000 # Tokens (cl100k_base) 0.000 0.001 0.002 0.003 0.004Density (a) Token Distribution Graph-Pretrain Data Graph-Pretrain KDE All Data All Data KDE −20 −15 −10 −5 0 5 10 Principal Component 1 −4 −2 0 2 4 6 8 10 Principal Component 2 (b) Embedding D...
2000
-
[18]
This transformation does not affect the practical utility of the predictor, as we are more concerned with the relative quality of different designs
and StructRTL (Liu et al., 2025c) to apply a logarithm transformation to these values, making the target distribution more suitable for model learning. This transformation does not affect the practical utility of the predictor, as we are more concerned with the relative quality of different designs. For training, we adopt the log-cosh loss (Saleh & Saleh,...
2022
-
[19]
Determine whether the given pair of RTL code snippets is functionally equivalent
and NV-Embed-v2 (Lee et al., 2025), we prepend the instruction “Determine whether the given pair of RTL code snippets is functionally equivalent.” to their model-specific templates to adapt their embeddings to this task. For GraphCodeBERT (Guo et al.,
2025
-
[20]
We evaluate models using five metrics: Average Precision (AP), Accuracy, F1, Precision, and Recall, with AP serving as the main metric
with hard negatives for downstream fine-tuning on this task: Lfec =− 1 M MX i=1 log exp cos(fθ(Ri),fθ(Ei)) τ PM j=1 exp cos(fθ(Ri),fθ(Ej ))) τ +PM j=1 Phj k=1 cos(fθ(Ri),fθ(Uj [k])) τ (13) where M is the batch size, fθ is the embedding function, τ is the temperature hyperparameter, and hj = min(length(Uj),max hard negatives), is the number of hard...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.