Keep The Essentials: Efficient Reference Conditioned Generation via Token Dropping
Pith reviewed 2026-06-26 08:58 UTC · model grok-4.3
The pith
Fine-tuning reference diffusion models on randomly dropped tokens lets them generate from sparse reference inputs while preserving quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
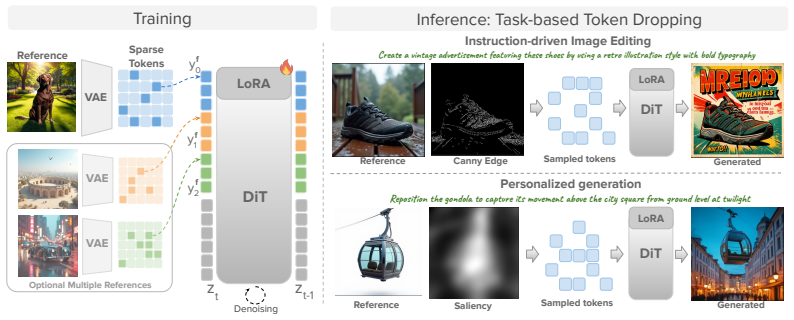
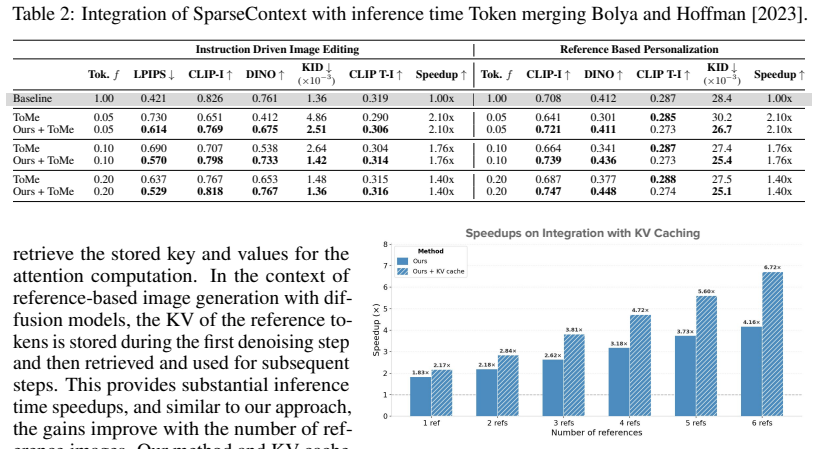
Sparse Context constructs sparse reference representations by keeping only a reduced subset of reference tokens. Fine-tuning the model with random token dropping at varying ratios during training makes it robust to partial reference inputs, decoupling it from any particular selection rule. At inference, task-aware strategies replace random dropping and adapt the token budget to the specific input and task, yielding large speed gains without loss of visual quality in spatially-aligned editing and subject-driven generation.
What carries the argument
Random token dropping during fine-tuning, which trains the model to generate from incomplete reference token sets and thereby supports flexible task-aware selection at inference.
If this is right
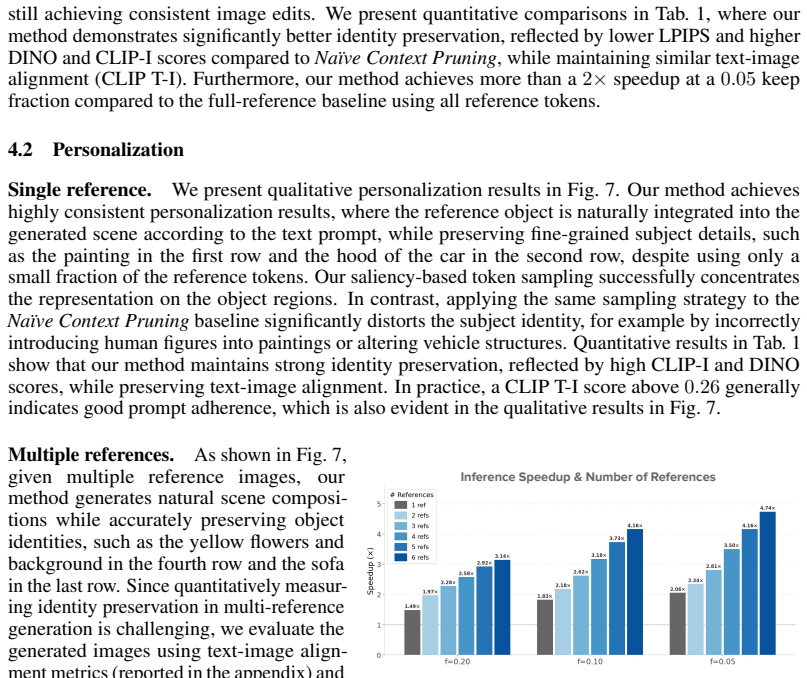
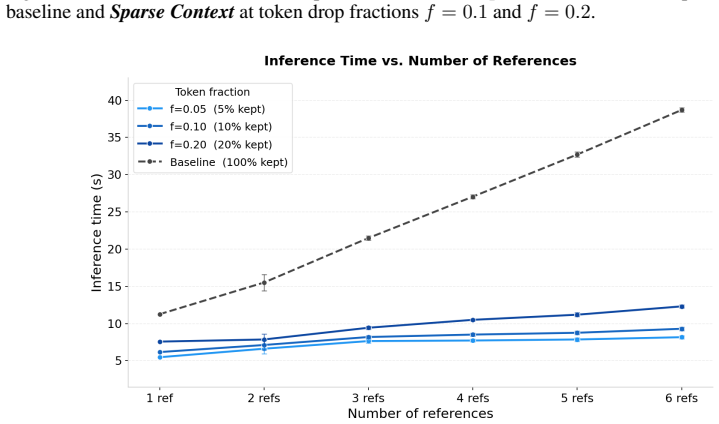
- Multi-reference generation runs approximately four times faster at inference.
- Single-reference generation runs approximately two times faster at inference.
- The same trained model supports both spatially-aligned editing and subject-driven generation without retraining.
- Token budget can be adjusted per input and task while keeping generation quality intact.
- The method works on existing reference-conditioned diffusion architectures without architectural changes.
Where Pith is reading between the lines
- The same fine-tuning pattern could be tested on reference-based video or 3D generation models.
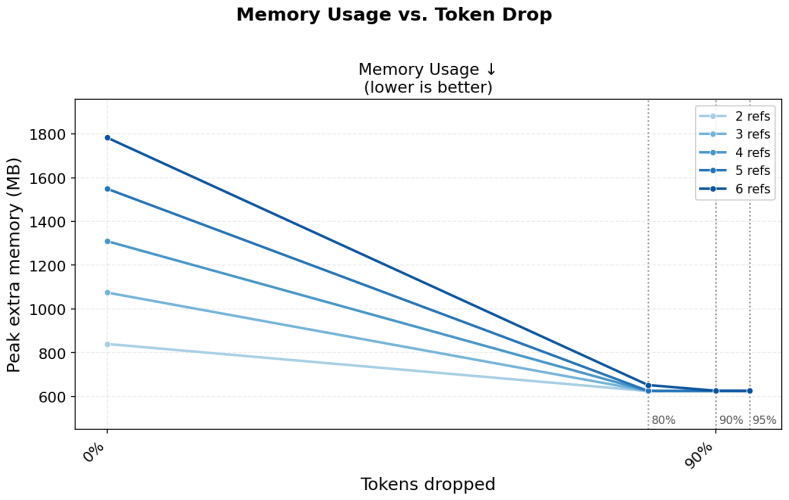
- Memory footprint during inference would likely drop in proportion to the token reduction.
- If the selection rule can be made differentiable, end-to-end training of the selector together with the generator becomes possible.
Load-bearing premise
That training the model with random drops at varying ratios will make it work equally well with any later task-aware selection rule chosen at inference time.
What would settle it
Measure visual quality on a held-out task where the selection rule at inference differs markedly from any random-drop pattern seen in training; a clear drop in quality relative to the full-token baseline would falsify the robustness claim.
Figures









read the original abstract
Reference-based diffusion models enable highly controllable image generation by leveraging elements from input images to guide prompt-driven synthesis. However, these models are computationally expensive in runtime, and their cost scales severely with the number of input references. While the efficiency of diffusion models has been extensively studied in the context of prompt-driven generation, it remains largely under-explored in the realm of reference-based models. This setting presents unique challenges not addressed by methods focusing solely on generation. In particular, the wasteful representation of references as dense token grids offers significant opportunities for improvement. In this work, we present Sparse Context, a method for constructing sparse reference representations by retaining only a reduced subset of reference tokens. We observe that even without modifying the model, dropping a significant portion of reference tokens at inference time largely preserves its generation capabilities. To fully realize this potential, we fine-tune the model with random token dropping at varying ratios, encouraging robustness to partial reference representations. Crucially, this training strategy decouples the model from any specific token selection rule, allowing flexible control at inference time. At inference time, instead of random dropping, we apply task-aware token selection strategies that prioritize the most informative regions of the reference images, adapting the token budget to the input and task requirements. Extensive experiments show our method achieves a 4x increase in inference speed for multi-reference generation and an 2x for single reference generation. Importantly, this efficiency is achieved without compromising visual quality across both spatially-aligned editing and subject-driven generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Sparse Context, a method to accelerate reference-conditioned diffusion models by constructing sparse reference representations through token dropping. The approach fine-tunes the model using random token dropping at varying ratios to promote robustness to partial inputs, then applies task-aware selection strategies at inference time. The central claims are a 4x inference speedup for multi-reference generation and 2x for single-reference generation, achieved without compromising visual quality in spatially-aligned editing and subject-driven generation tasks.
Significance. If the empirical claims hold, the work addresses an under-explored efficiency gap in reference-based diffusion models, where cost scales with the number of references. The training strategy of random dropping to enable flexible inference-time selection could be broadly useful if the decoupling effect is confirmed, potentially improving practicality of controllable generation without requiring architecture changes.
major comments (2)
- [Abstract] Abstract: The central claim that random-ratio token dropping during fine-tuning 'decouples the model from any specific token selection rule' is asserted without a direct empirical test. No section or result is described that compares generation quality (metrics or human preference) under random masks versus the task-aware strategies (e.g., saliency- or attention-based) at identical token budgets; this comparison is load-bearing for the robustness and flexibility assertions.
- [Abstract] Abstract: The abstract states that 'extensive experiments show' 4x and 2x speedups 'without compromising visual quality,' yet supplies no quantitative metrics, baselines, ablation tables, or error analysis. This absence prevents evaluation of whether the quality-preservation claim holds at the reported speedups.
minor comments (1)
- The abstract refers to 'spatially-aligned editing and subject-driven generation' without naming the specific datasets, tasks, or evaluation protocols used to support the quality claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline revisions to strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that random-ratio token dropping during fine-tuning 'decouples the model from any specific token selection rule' is asserted without a direct empirical test. No section or result is described that compares generation quality (metrics or human preference) under random masks versus the task-aware strategies (e.g., saliency- or attention-based) at identical token budgets; this comparison is load-bearing for the robustness and flexibility assertions.
Authors: We agree that the abstract does not explicitly present a direct side-by-side comparison of generation quality under random versus task-aware token selection at matched budgets. The manuscript demonstrates the benefit of random-ratio training by showing that task-aware selection at inference preserves quality after such training, but a dedicated ablation isolating the selection rule itself would more directly support the decoupling claim. We will add this comparison (including quantitative metrics and human preference results) to the experiments section and revise the abstract to reference it. revision: yes
-
Referee: [Abstract] Abstract: The abstract states that 'extensive experiments show' 4x and 2x speedups 'without compromising visual quality,' yet supplies no quantitative metrics, baselines, ablation tables, or error analysis. This absence prevents evaluation of whether the quality-preservation claim holds at the reported speedups.
Authors: The referee correctly notes that the abstract summarizes the speedup and quality claims without including supporting numbers. The body of the manuscript reports these details via FID, CLIP similarity, and user-study results across multiple tables and figures. To address the concern, we will revise the abstract to incorporate key quantitative metrics (e.g., specific FID values and speedup ratios with quality preservation) while remaining within length constraints. revision: yes
Circularity Check
No circularity in empirical efficiency method
full rationale
The paper presents an empirical method: observe that random token dropping at inference preserves quality, then fine-tune with random-ratio dropping to encourage robustness, followed by task-aware selection at inference. No equations, derivations, or self-citations are shown that reduce the claimed 4x/2x speedups or quality preservation to fitted parameters, self-definitions, or prior author results by construction. The decoupling assertion is an empirical claim tied to the training procedure and validated experimentally, not a circular reduction. The work is self-contained against external benchmarks with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Reference images can be tokenized and partially dropped while preserving generation quality in diffusion models
- ad hoc to paper Random token dropping during fine-tuning produces robustness to arbitrary task-aware selection at inference
Reference graph
Works this paper leans on
-
[1]
URL https://arxiv.org/abs/2311.03335. Omri Avrahami, Or Patashnik, Ohad Fried, Egor Nemchinov, Kfir Aberman, Dani Lischinski, and Daniel Cohen-Or. Stable flow: Vital layers for training-free image editing. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 7877–7888,
-
[2]
Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923,
10 Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report...
-
[3]
Longformer: The long-document transformer
Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150,
Pith/arXiv arXiv 2004
-
[4]
URL https://arxiv.org/abs/2304.08465. Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, et al. Rethinking attention with performers.arXiv preprint arXiv:2009.14794,
arXiv 2009
-
[5]
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H
URL https://arxiv.org/abs/2105.05233. Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H. Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image generation using textual inversion,
-
[6]
Rinon Gal, Or Lichter, Elad Richardson, Or Patashnik, Amit H
URLhttps://arxiv.org/abs/2208.01618. Rinon Gal, Or Lichter, Elad Richardson, Or Patashnik, Amit H. Bermano, Gal Chechik, and Daniel Cohen-Or. Lcm-lookahead for encoder-based text-to-image personalization,
-
[7]
Renoise: Real image inversion through iterative noising.arXiv preprint arXiv:2403.14602,
Daniel Garibi, Or Patashnik, Andrey V oynov, Hadar Averbuch-Elor, and Daniel Cohen-Or. Renoise: Real image inversion through iterative noising.arXiv preprint arXiv:2403.14602,
-
[8]
Zhanqiu Hu, Jian Meng, Yash Akhauri, Mohamed S Abdelfattah, Jae-sun Seo, Zhiru Zhang, and Udit Gupta. Flashdlm: Accelerating diffusion language model inference via efficient kv caching and guided diffusion.arXiv preprint arXiv:2505.21467,
-
[9]
ISSN 0162-8828. doi: 10.1109/TPAMI. 2025.3541625. URLhttps://doi.org/10.1109/TPAMI.2025.3541625. Inbar Huberman-Spiegelglas, Vladimir Kulikov, and Tomer Michaeli. An edit friendly ddpm noise space: Inversion and manipulations,
-
[10]
Mude Hui, Siwei Yang, Bingchen Zhao, Yichun Shi, Heng Wang, Peng Wang, Cihang Xie, and Yuyin Zhou
URLhttps://arxiv.org/abs/2304.06140. Mude Hui, Siwei Yang, Bingchen Zhao, Yichun Shi, Heng Wang, Peng Wang, Cihang Xie, and Yuyin Zhou. Hq-edit: A high-quality dataset for instruction-based image editing. InThe Thirteenth International Conference on Learning Representations. Xuan Ju, Ailing Zeng, Yuxuan Bian, Shaoteng Liu, and Qiang Xu. Pnp inversion: Boo...
-
[11]
Multi-concept customization of text-to-image diffusion
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi-concept customization of text-to-image diffusion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1931–1941,
1931
-
[12]
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or
URL https://arxiv.org/abs/2108.01073. Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real images using guided diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6038–6047, June
-
[13]
URLhttp://dx.doi.org/10.1145/3588432.3591513
doi: 10.1145/3588432.3591513. URLhttp://dx.doi.org/10.1145/3588432.3591513. William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205,
-
[14]
doi: https://doi.org/10.1111/cgf.15063. URL https://onlinelibrary. wiley.com/doi/abs/10.1111/cgf.15063. Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. 13 Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda ...
-
[15]
Zhuoran Shen, Mingyuan Zhang, Haiyu Zhao, Shuai Yi, and Hongsheng Li
URL https://arxiv.org/abs/ 2205.11487. Zhuoran Shen, Mingyuan Zhang, Haiyu Zhao, Shuai Yi, and Hongsheng Li. Efficient attention: Atten- tion with linear complexities. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 3531–3539,
-
[16]
Zhenxiong Tan, Songhua Liu, Xingyi Yang, Qiaochu Xue, and Xinchao Wang
URL https://arxiv.org/abs/2010.02502. Zhenxiong Tan, Songhua Liu, Xingyi Yang, Qiaochu Xue, and Xinchao Wang. Ominicontrol: Minimal and universal control for diffusion transformer.arXiv preprint arXiv:2411.15098,
Pith/arXiv arXiv 2010
-
[17]
Sinong Wang, Belinda Z Li, Madian Khabsa, Han Fang, and Hao Ma
URLhttps://arxiv.org/abs/2211.12572. Sinong Wang, Belinda Z Li, Madian Khabsa, Han Fang, and Hao Ma. Linformer: Self-attention with linear complexity.arXiv preprint arXiv:2006.04768,
arXiv 2006
-
[18]
Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025a
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025a. Haoyu Wu, Jingyi Xu, Hieu Le, and Dimitris Samaras. Importance-based token merging for efficient image and video generation. InProceedings of the IEEE/CVF Interna...
-
[19]
Yu Zeng, Vishal M Patel, Haochen Wang, Xun Huang, Ting-Chun Wang, Ming-Yu Liu, and Yogesh Balaji
URL https://arxiv.org/abs/2308.06721. Yu Zeng, Vishal M Patel, Haochen Wang, Xun Huang, Ting-Chun Wang, Ming-Yu Liu, and Yogesh Balaji. Jedi: Joint-image diffusion models for finetuning-free personalized text-to-image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,
-
[20]
For the base model, our method achieves more than 2× speedup when 5% of the tokens are preserved
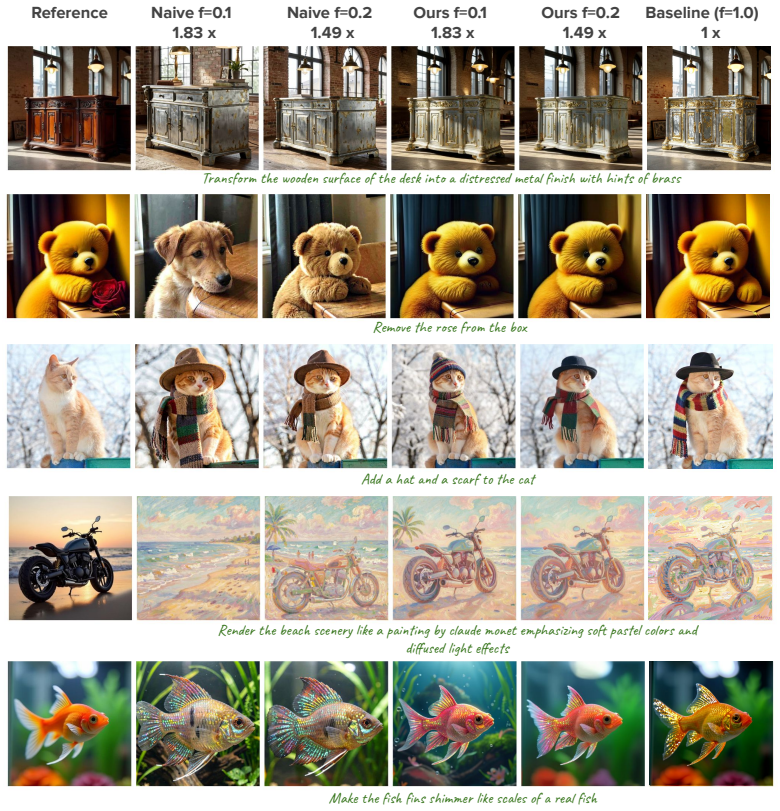
Our fine-tuning strategy significantly outperforms the Naïve token dropping strategy in terms of image fidelity and text alignment while being equally fast. For the base model, our method achieves more than 2× speedup when 5% of the tokens are preserved. This showcases the generalization of our approach in accelerating different model architectures, inclu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.