Building a privacy-preserving Federated Recommender system for mobile devices
Pith reviewed 2026-05-25 06:14 UTC · model grok-4.3
The pith
A two-stage pipeline generates shortlists in the cloud from non-sensitive data then re-ranks them on-device with private context signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
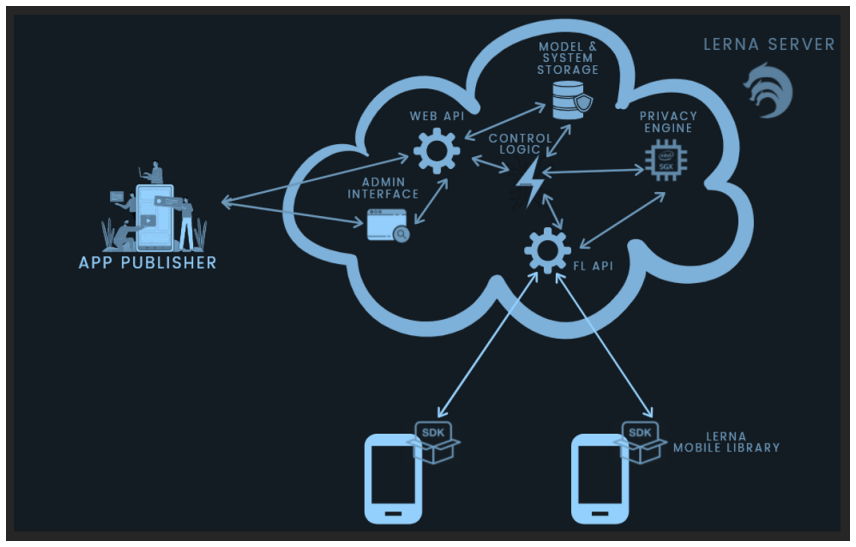
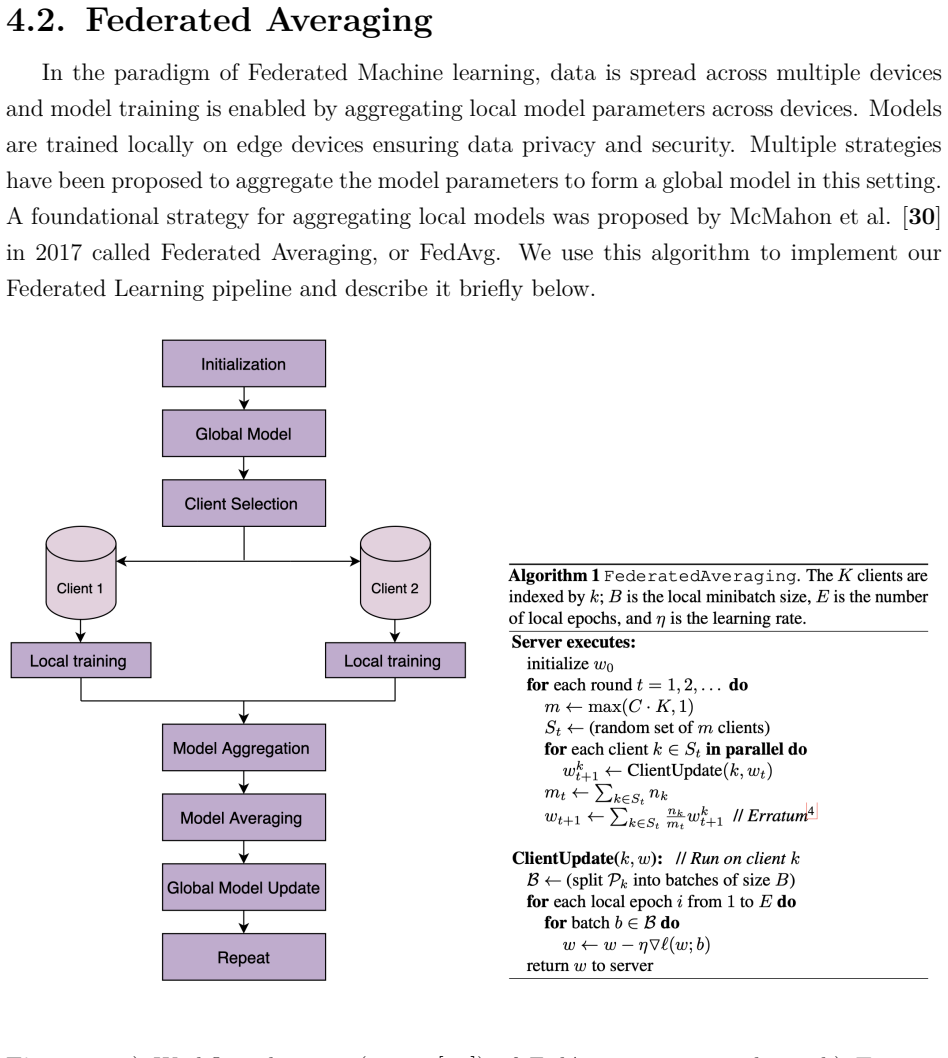
The central claim is that a two-stage federated recommendation pipeline—cloud-based collaborative filtering on non-sensitive app-context data to produce a shortlist, followed by on-device re-ranking that uses sensitive mobile signals—delivers effective personalization while ensuring the sensitive data never leaves the device and only model updates are transmitted.
What carries the argument
The two-stage federated pipeline that isolates non-sensitive preference data for cloud shortlisting from sensitive context data used only for on-device re-ranking.
If this is right
- Personalized mobile content can be served without pooling sensitive context data on servers.
- Training continues via model updates alone, satisfying data-minimization requirements.
- The same separation pattern can be applied to other on-device personalization tasks.
- A single Kotlin Multiplatform library makes the pipeline available on both Android and iOS.
Where Pith is reading between the lines
- The design lowers the regulatory surface area for any app that must handle location or sensor streams.
- On-device re-ranking may also reduce round-trip latency once the shortlist arrives.
- If the shortlist quality is high enough, the on-device stage could be made extremely lightweight.
Load-bearing premise
Re-ranking a cloud-generated shortlist on the device with local sensitive signals yields recommendation quality comparable to a model that has direct access to the full centralized dataset.
What would settle it
A controlled experiment that measures precision or recall on held-out user interactions and shows that the on-device re-ranking stage produces materially lower accuracy than a centralized model trained on the same sensitive signals would falsify the claim of effective personalization.
Figures












read the original abstract
Serving personalized content on mobile devices has traditionally required pooling sensitive user data on centralized servers, a practice increasingly at odds with modern privacy expectations and geographical regulations. We present a two-stage federated recommendation system pipeline for mobile devices, built around a principled separation between non-sensitive user preference data and sensitive mobile context data that never leaves the device. The first stage runs a collaborative filtering model on non-sensitive app-context data in the cloud to generate a shortlist of relevant items. The second stage re-ranks these candidates on-device using sensitive mobile signals, with only model updates/gradients ever leaving the device. We validate the approach on MovieLens, UCI Human Activity Recognition, and a proprietary pilot dataset, and deliver a production-ready implementation as a Kotlin Multiplatform library deployable on Android and iOS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a two-stage federated recommender system pipeline for mobile devices. A cloud-based collaborative filtering stage generates a shortlist from non-sensitive user preference data; an on-device stage then re-ranks candidates using sensitive mobile context signals, with only model updates or gradients ever leaving the device. The approach is claimed to have been validated on MovieLens, UCI Human Activity Recognition, and a proprietary pilot dataset, and a production-ready Kotlin Multiplatform library is provided.
Significance. If the on-device re-ranking stage can be shown to deliver non-trivial personalization gains while keeping sensitive data local, the pipeline would address a practical tension between personalization and privacy regulations in mobile recommender systems. The release of a deployable cross-platform library would be a concrete engineering contribution.
major comments (1)
- [Abstract] Abstract: the manuscript states that validation occurred on MovieLens, UCI HAR, and a proprietary dataset, yet supplies no metrics (e.g., NDCG@K, precision@K), baselines, ablation results comparing the two-stage pipeline against the cloud stage alone, or error analysis. Without these data the central claim that the on-device re-ranking produces effective privacy-preserving personalization remains unsupported.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the manuscript states that validation occurred on MovieLens, UCI HAR, and a proprietary dataset, yet supplies no metrics (e.g., NDCG@K, precision@K), baselines, ablation results comparing the two-stage pipeline against the cloud stage alone, or error analysis. Without these data the central claim that the on-device re-ranking produces effective privacy-preserving personalization remains unsupported.
Authors: We agree that the abstract would be strengthened by including key quantitative results. The manuscript body reports evaluation results across the three datasets, including NDCG@K and precision@K metrics, direct comparisons against the cloud-only baseline, ablation studies isolating the on-device re-ranking contribution, and supporting analysis. To make these data immediately visible and address the concern, we will revise the abstract to summarize the main empirical findings (e.g., relative gains from the on-device stage) while retaining the high-level description. We will also verify that an explicit error analysis subsection appears in the results section. This targeted revision directly supports the central claim without altering the technical contribution. revision: yes
Circularity Check
No derivation chain present; architectural description only
full rationale
The manuscript describes a two-stage federated pipeline separating non-sensitive and sensitive data, with cloud CF generating a shortlist and on-device re-ranking. No equations, fitted parameters, predictions, or uniqueness theorems appear in the provided text. Validation is asserted on MovieLens, UCI HAR, and a proprietary dataset without any reported metrics or derivations that could reduce to inputs by construction. Self-citations are absent from the abstract and pipeline description. The contribution is therefore self-contained as an engineering architecture with no load-bearing mathematical steps to inspect for circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Human activity recognition.https://www.v7labs.com/blog/human-activity-recognition. Ac- cessed: May 25, 2026
work page 2026
- [2]
- [3]
-
[4]
ActionML. ActionML GitHub Organization. GitHub organization, 2024. URL:https://github.com/ actionml
work page 2024
-
[5]
ActionML. Universal Recommender. GitHub repository, 2024. URL:https://github.com/actionml/ universal-recommender
work page 2024
-
[6]
Endomondo Fitness Trajectories Dataset
Ahmad P. Endomondo Fitness Trajectories Dataset. Kaggle Dataset, 2023. URL:https://www.kaggle. com/datasets/pypiahmad/endomondo-fitness-trajectories
work page 2023
-
[7]
D. Anguita, Alessandro Ghio, L. Oneto, Xavier Parra, and Jorge Luis Reyes-Ortiz. Hu- man Activity Recognition Using Smartphones. UCI Machine Learning Repository, 2012. DOI: https://doi.org/10.24432/C54S4K
-
[8]
D. Anguita, Alessandro Ghio, L. Oneto, Xavier Parra, and Jorge Luis Reyes-Ortiz. A public domain dataset for human activity recognition using smartphones. InThe European Symposium on Artificial Neural Networks, 2013. URL:https://api.semanticscholar.org/CorpusID:6975432
work page 2013
-
[9]
Apache Software Foundation. Apache Mahout. Website, 2024. URLhttps://mahout.apache.org/
work page 2024
-
[10]
Apache Software Foundation. Apache Spark. Website, 2024. URL:https://spark.apache.org/
work page 2024
-
[11]
Collaborative similarity em- bedding for recommender systems
Chih-Ming Chen, Chuan-Ju Wang, Ming-Feng Tsai, and Yi-Hsuan Yang. Collaborative similarity em- bedding for recommender systems. InThe World Wide Web Conference, pages 2637–2643, 2019
work page 2019
-
[12]
InProceedings of the 1st workshop on deep learning for recommender systems, pages 7–10, 2016
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, GregCorrado, WeiChai, MustafaIspir, etal.Wide&deeplearningforrecommendersystems. InProceedings of the 1st workshop on deep learning for recommender systems, pages 7–10, 2016
work page 2016
-
[13]
Log likelihood ratios for recommendation algorithms
Data Science, Adobe Target. Log likelihood ratios for recommendation algorithms. Adobe Ex- perience League, 2024. URL:https://experienceleague.adobe.com/docs/target/assets/ log-likelihood-ratios-recommendation-algorithms.pdf
work page 2024
-
[14]
Yashar Deldjoo, Mehdi Elahi, Massimo Quadrana, and Paolo Cremonesi. Using visual features based on mpeg-7 and deep learning for movie recommendation.International journal of multimedia information retrieval, 7:207–219, 2018
work page 2018
-
[15]
Neural Network Matrix Factorization
Gintare Karolina Dziugaite and Daniel M Roy. Neural network matrix factorization.arXiv preprint arXiv:1511.06443, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[16]
What is federated averaging (fedavg)?, 2024
Educative.io. What is federated averaging (fedavg)?, 2024. URL:https://www.educative.io/ answers/what-is-federated-averaging-fedavg. 64
work page 2024
-
[17]
Pat Ferrel. Universal recommender, 2014. URL:https://www.slideshare.net/pferrel/ unified-recommender-39986309
work page 2014
-
[18]
Daniel Garcia-Gonzalez, Daniel Rivero, Enrique Fernandez-Blanco, and Miguel Luaces. A public domain dataset for real-life human activity recognition using smartphone sensors.Sensors, 20:2200, 04 2020. doi:10.3390/s20082200
-
[19]
GroupLens. MovieLens Dataset. Website, 2024. URL:https://grouplens.org/datasets/ movielens/
work page 2024
-
[20]
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. Deepfm: a factorization- machine based neural network for ctr prediction.arXiv preprint arXiv:1703.04247, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Neural collaborative filtering.https://github.com/hexiangnan/neural_ collaborative_filtering, 2024
Xiangnan He. Neural collaborative filtering.https://github.com/hexiangnan/neural_ collaborative_filtering, 2024
work page 2024
-
[22]
Neural collaborative filtering
Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. Neural collaborative filtering. InProceedings of the 26th international conference on world wide web, pages 173–182, 2017
work page 2017
-
[23]
Human activity recognition on smartphones using a bidirectional lstm network
Fabio Hernández, Luis F Suárez, Javier Villamizar, and Miguel Altuve. Human activity recognition on smartphones using a bidirectional lstm network. In2019 XXII symposium on image, signal processing and artificial vision (STSIVA), pages 1–5. IEEE, 2019
work page 2019
-
[24]
Collaborative filtering for implicit feedback datasets
Yifan Hu, Yehuda Koren, and Chris Volinsky. Collaborative filtering for implicit feedback datasets. In 2008 Eighth IEEE international conference on data mining, pages 263–272. Ieee, 2008
work page 2008
-
[25]
Elena Ivannikova, Suleiman A Khan, Were Oyomno, Qiang Fu, KE Tan, A Flanagan, et al. Federated collaborative filtering for privacy-preserving personalized recommendation system.CoRR, 2019
work page 2019
-
[26]
JetBrains. Kotlin Multiplatform. Software, 2023. URL:https://kotlinlang.org/docs/ multiplatform.html
work page 2023
-
[27]
harage: a novel multimodal smartwatch-based dataset for human activity recognition
Adria Mallol-Ragolta, Anastasia Semertzidou, Maria Pateraki, and Björn Schuller. harage: a novel multimodal smartwatch-based dataset for human activity recognition. In2021 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2021), pages 01–07. IEEE, 2021
work page 2021
-
[28]
Miguel Matey-Sanz, Sven Casteleyn, and Carlos Granell. Dataset of inertial measurements of smart- phones and smartwatches for human activity recognition.Data in Brief, 51:109809, 2023
work page 2023
-
[30]
Communication-efficient learning of deep networks from decentralized data
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. InArtificial intelligence and statistics, pages 1273–1282. PMLR, 2017
work page 2017
-
[31]
AnExpositoryNote.Thelikelihoodratio, wald, andlagrangemultipliertests.The American Statistician, 36(3 Part 1):153–157, 1982
work page 1982
-
[32]
Marco Polignano, Cataldo Musto, Marco de Gemmis, Pasquale Lops, and Giovanni Semeraro. Together is better: Hybrid recommendations combining graph embeddings and contextualized word representa- tions. InProceedings of the 15th ACM conference on recommender systems, pages 187–198, 2021. 65
work page 2021
-
[33]
Steffen Rendle. Factorization machines. In2010 IEEE International conference on data mining, pages 995–1000. IEEE, 2010
work page 2010
-
[34]
BPR: Bayesian Personalized Ranking from Implicit Feedback
Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme. Bpr: Bayesian personalized ranking from implicit feedback.arXiv preprint arXiv:1205.2618, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[35]
Deep convolutional neural networks for human activity recog- nition with smartphone sensors
Charissa Ann Ronao and Sung-Bae Cho. Deep convolutional neural networks for human activity recog- nition with smartphone sensors. InNeural Information Processing: 22nd International Conference, ICONIP 2015, November 9-12, 2015, Proceedings, Part IV 22, pages 46–53. Springer, 2015
work page 2015
-
[36]
Item-based collaborative filtering recommendation algorithms
Badrul Sarwar, George Karypis, Joseph Konstan, and John Riedl. Item-based collaborative filtering recommendation algorithms. InProceedings of the 10th international conference on World Wide Web, pages 285–295, 2001
work page 2001
-
[37]
Scalable similarity-based neighborhood meth- ods with mapreduce
Sebastian Schelter, Christoph Boden, and Volker Markl. Scalable similarity-based neighborhood meth- ods with mapreduce. InProceedings of the sixth ACM conference on Recommender systems, pages 163–170, 2012
work page 2012
-
[38]
Model evaluation: Balanced accuracy score, 2024
scikit-learn contributors. Model evaluation: Balanced accuracy score, 2024. URL:https: //scikit-learn.org/stable/modules/model_evaluation.html#balanced-accuracy-score
work page 2024
-
[39]
Hu- man activity recognition using multichannel convolutional neural network
Niloy Sikder, Md Sanaullah Chowdhury, Abu Shamim Mohammad Arif, and Abdullah-Al Nahid. Hu- man activity recognition using multichannel convolutional neural network. In2019 5th International conference on advances in electrical engineering (ICAEE), pages 560–565. IEEE, 2019
work page 2019
-
[40]
Autoint: Automatic feature interaction learning via self-attentive neural networks
Weiping Song, Chence Shi, Zhiping Xiao, Zhijian Duan, Yewen Xu, Ming Zhang, and Jian Tang. Autoint: Automatic feature interaction learning via self-attentive neural networks. InProceedings of the 28th ACM international conference on information and knowledge management, pages 1161–1170, 2019
work page 2019
-
[41]
IJCAI-16 Brick-and-Mortar Store Recommendation Dataset, 2018
Tianchi. IJCAI-16 Brick-and-Mortar Store Recommendation Dataset, 2018. URL:https://tianchi. aliyun.com/dataset/dataDetail?dataId=53
work page 2018
-
[42]
Daniel Valcarce, Alfonso Landin, Javier Parapar, and Álvaro Barreiro. Collaborative filtering em- beddings for memory-based recommender systems.Engineering Applications of Artificial Intelligence, 85:347–356, 2019
work page 2019
-
[43]
Yingfan Wang, Haiyang Huang, Cynthia Rudin, and Yaron Shaposhnik. Understanding how dimension reduction tools work: An empirical approach to deciphering t-sne, umap, trimap, and pacmap for data visualization.Journal of Machine Learning Research, 22(201):1–73, 2021. URL:http://jmlr.org/ papers/v22/20-1061.html
work page 2021
-
[44]
Federated learning with differential privacy: Algorithms and performance analysis
Kang Wei, Jun Li, Ming Ding, Chuan Ma, Howard H Yang, Farhad Farokhi, Shi Jin, Tony QS Quek, and H Vincent Poor. Federated learning with differential privacy: Algorithms and performance analysis. IEEE transactions on information forensics and security, 15:3454–3469, 2020
work page 2020
-
[45]
Yang Yang, Yi Zhu, and Yun Li. Personalized recommendation with knowledge graph via dual- autoencoder.Applied Intelligence, 52(6):6196–6207, 2022
work page 2022
- [46]
-
[47]
Deep interest network for click-through rate prediction
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. Deep interest network for click-through rate prediction. InProceedings of the 66 24th ACM SIGKDD international conference on knowledge discovery & data mining, pages 1059–1068, 2018
work page 2018
-
[48]
Retailrocket recommender system dataset, 2022
Roman Zykov, Noskov Artem, and Anokhin Alexander. Retailrocket recommender system dataset, 2022. URL:https://www.kaggle.com/dsv/4471234,doi:10.34740/KAGGLE/DSV/4471234. 67
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.