SEAM: Shortcut-Aware Real-Time Detection of Scripted vs. Spontaneous Speech for Interview Guardrails
Pith reviewed 2026-06-27 21:18 UTC · model grok-4.3
The pith
Shortcut prevention in data design lets a compact model detect scripted speech at 0.97 AUC on unseen interview recordings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Robust real-time scriptedness detection depends not only on the backbone but on shortcut-aware data design and evaluation; uniform preprocessing, seam-aware sampling, and non-speech augmentation together enable a DistilHuBERT model to reach 0.971 ROC-AUC on an external interview-domain set while standard training produces models that fail to generalize.
What carries the argument
SEAM framework that combines uniform preprocessing, seam-aware sampling, non-speech augmentation, and a compact DistilHuBERT backbone to block corpus- and channel-based shortcuts.
If this is right
- Models trained without the shortcut-prevention steps will show inflated internal metrics yet drop sharply on new interview data.
- An 8-second window is sufficient for high-accuracy real-time scriptedness decisions once shortcuts are removed.
- Post-training quantization preserves external performance while reducing the model to 41.8 MB.
- Future scriptedness detectors must report both internal and external results to demonstrate that performance stems from speaking style rather than data artifacts.
Where Pith is reading between the lines
- The same data-design approach could be tested on other binary audio classification tasks that currently suffer from corpus leakage.
- If seam-aware sampling proves critical, it suggests that explicit modeling of temporal boundaries between speech segments is a general requirement for style-based audio tasks.
- Releasing code and checkpoints allows direct measurement of whether the 0.971 AUC holds under further domain shifts such as different languages or microphone types.
Load-bearing premise
The external interview evaluation set contains no corpus-specific or channel artifacts that a model could exploit in the same way it exploits training-data artifacts.
What would settle it
Train the SEAM model and a version without seam-aware sampling and non-speech augmentation; if both reach comparable ROC-AUC on a fresh external interview set drawn from different recording conditions, the claim that shortcut prevention drives generalization is false.
Figures
read the original abstract
Scripted vs spontaneous speech detection is appealing for interview guardrails, but benchmark performance can be inflated by shortcuts tied to corpus identity, channel conditions, and recording artifacts rather than speaking style itself. We present SEAM, a shortcut-aware framework for real-time scriptedness detection that combines uniform preprocessing, seam-aware sampling, non-speech augmentation, and a compact DistilHuBERT backbone. With 8s windows, the model achieves 0.971 +- 0.004 ROC-AUC on an external interview-domain evaluation set. Removing the shortcut-prevention components improves internal held-out metrics but sharply reduces external performance, indicating shortcut learning. Post-training quantization reduces the model footprint to 41.8MB with little loss in external performance. The results demonstrate that robust real-time scriptedness detection depends not only on the backbone, but on shortcut-aware data design and evaluation. We release code and model checkpoints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SEAM, a shortcut-aware framework for real-time detection of scripted versus spontaneous speech using uniform preprocessing, seam-aware sampling, non-speech augmentation, and a compact DistilHuBERT backbone. It reports that an 8-second window model achieves 0.971 ± 0.004 ROC-AUC on an external interview-domain evaluation set. An ablation study shows that removing the shortcut-prevention components improves internal held-out metrics but sharply degrades external performance, which the authors interpret as evidence of shortcut learning in the baseline. Post-training quantization yields a 41.8 MB model with minimal external-performance loss. Code and checkpoints are released.
Significance. If the external evaluation set is free of its own label-correlated artifacts, the work provides concrete evidence that explicit shortcut-prevention mechanisms in data design can produce more robust generalization than backbone choice alone. The ablation directly links the proposed components to the external-performance gain, and the release of code and checkpoints strengthens reproducibility.
major comments (1)
- [Abstract and evaluation section] The central claim that the ablation demonstrates detection of speaking style rather than a different shortcut rests on the external interview-domain set being free of corpus-specific or channel artifacts. The manuscript provides limited detail on the external set's construction, sampling mechanics, and potential confounds (e.g., recording conditions, microphone response, or corpus identity cues), which the paper's own logic implies can be exploited.
minor comments (1)
- [Abstract] The abstract states the external ROC-AUC but does not specify the exact number of speakers, total duration, or label distribution in the external set.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below and will revise the manuscript to provide greater transparency on the external evaluation set.
read point-by-point responses
-
Referee: [Abstract and evaluation section] The central claim that the ablation demonstrates detection of speaking style rather than a different shortcut rests on the external interview-domain set being free of corpus-specific or channel artifacts. The manuscript provides limited detail on the external set's construction, sampling mechanics, and potential confounds (e.g., recording conditions, microphone response, or corpus identity cues), which the paper's own logic implies can be exploited.
Authors: We agree that additional detail on the external set is warranted to strengthen the central claim. In the revised manuscript we will add a dedicated paragraph in the evaluation section describing the external interview-domain set's construction, including sampling procedure, source corpora, recording conditions, and any preprocessing applied to reduce corpus-identity or channel cues. This will directly address the concern that the ablation may be capturing a different shortcut. We maintain that the observed pattern—shortcut-prevention components improve external ROC-AUC while their removal boosts internal metrics—remains the strongest available evidence that the model is learning speaking-style distinctions rather than dataset artifacts, but we accept that fuller documentation is required for the claim to be fully convincing. revision: yes
Circularity Check
No circularity; empirical results grounded in external held-out evaluation
full rationale
The paper's central claims rest on training a model (DistilHuBERT backbone with shortcut-prevention components) and reporting ROC-AUC on an external interview-domain evaluation set, plus an ablation comparing variants on internal vs. external metrics. No mathematical derivation, self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations are present in the provided text. The ablation result is an independent empirical observation rather than a reduction to the model's own inputs by construction. This is the standard case of a self-contained empirical ML paper evaluated against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The external interview-domain evaluation set measures generalization to speaking style rather than dataset-specific artifacts.
Reference graph
Works this paper leans on
-
[1]
clean studio audio
Introduction Distinguishing scripted speech from spontaneous speech is use- ful in applications such as corpus curation, speaking-style anal- ysis, and guardrails for conversational systems [13, 14]. In AI- assisted job interviews, this distinction has a particularly practi- cal role: a lightweight real-time audio model can flag stretches of speech that s...
-
[2]
SEAM: Shortcut-Aware Real-Time Detection of Scripted vs. Spontaneous Speech for Interview Guardrails
Related Work 2.1. Scripted vs. spontaneous speech classification Prior work has studied scripted, read, narrated, and spon- taneous speech classification as a speaking-style recognition problem motivated by corpus analysis and downstream me- dia applications. The closest recent reference point is El- ishaet al.[13], who show that transformer-based audio m...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
clean audio implies scripted speech,
The SEAM Framework We refer to our end-to-end pipeline asSEAM. The core idea is that robust scripted-vs.-spontaneous detection does not come from the backbone alone, but from coordinated choices in task design, data curation, preprocessing, sampling, augmentation, and evaluation. SEAM is designed for real-time interview guardrails, where the model must op...
-
[4]
Absolute metrics in this regime are not directly comparable to the full-training results; we use them to measure relative trends across design choices
Results We report results in two experimental regimes.(i) Full-training regime:the primary reported system is trained for three epochs on the full internal dataset (12 shards per class; 240 h per class) and evaluated on the grouped internaleval/testsplits and the external interview-domain set (Table 1).(ii) Fixed-budget regime:to compare architectural and...
-
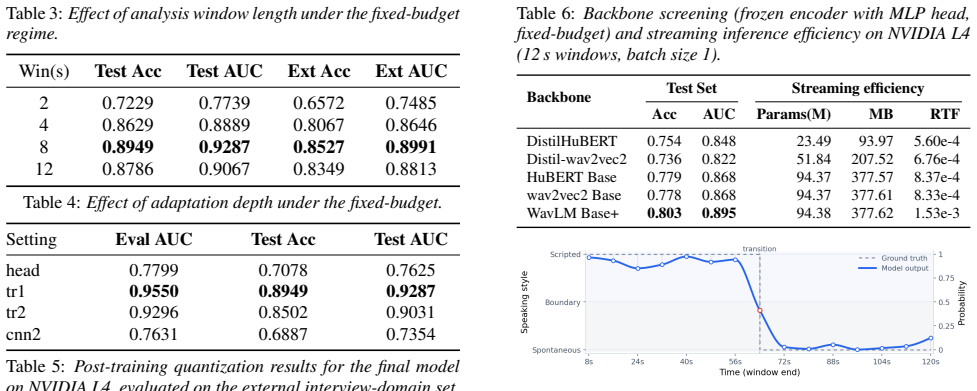
[5]
Discussion and Limitations Our results suggest that robust scripted-versus-spontaneous de- tection depends not only on the backbone, but on shortcut- Table 6:Backbone screening (frozen encoder with MLP head, fixed-budget) and streaming inference efficiency on NVIDIA L4 (12 s windows, batch size 1). Backbone Test Set Streaming efficiency Acc AUC Params(M) ...
-
[6]
Conclusion and Future Work We presented SEAM, a compact real-time framework for scripted-versus-spontaneous speech detection that emphasizes shortcut-aware training and evaluation. Results show that im- proving robustness to corpus and channel shortcuts is impor- tant for transfer to interview-domain audio, while still support- ing practical low-latency d...
-
[7]
All authors reviewed, edited, and verified the final content, results, and claims
Generative AI Use Disclosure Generative AI tools were used for language polishing and LaTeX formatting assistance. All authors reviewed, edited, and verified the final content, results, and claims
-
[8]
The People’s Speech: A Large-Scale Diverse English Speech Recognition Dataset for Commercial Usage,
D. Galvez, G. Diamos, J. Ciro,et al., “The People’s Speech: A Large-Scale Diverse English Speech Recognition Dataset for Commercial Usage,”arXiv preprint arXiv:2111.09344, 2021
-
[9]
Filler Word Detection and Classification: A Dataset and Benchmark,
G. Zhu, J.-P. Caceres, and J. Salamon, “Filler Word Detection and Classification: A Dataset and Benchmark,” inProc. Interspeech, 2022
2022
-
[10]
Mining the Spoken Wikipedia for Speech Data and Beyond,
A. K ¨ohn, F. Stegen, and T. Baumann, “Mining the Spoken Wikipedia for Speech Data and Beyond,” inProc. LREC, 2016
2016
-
[11]
The Spoken Wikipedia Corpus collection: Harvesting, alignment and an application to hyperlistening,
T. Baumann, A. K ¨ohn, and F. Hennig, “The Spoken Wikipedia Corpus collection: Harvesting, alignment and an application to hyperlistening,”Language Resources and Evaluation, 2018
2018
-
[12]
Lib- rispeech: An ASR Corpus Based on Public Domain Audio Books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- rispeech: An ASR Corpus Based on Public Domain Audio Books,” inProc. ICASSP, 2015
2015
-
[13]
wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Represen- tations,
A. Baevski, H. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Represen- tations,” inProc. NeurIPS, 2020
2020
-
[14]
HuBERT: Self- Supervised Speech Representation Learning by Masked Predic- tion of Hidden Units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai,et al., “HuBERT: Self- Supervised Speech Representation Learning by Masked Predic- tion of Hidden Units,”IEEE/ACM TASLP, 2021
2021
-
[15]
WavLM: Large-Scale Self- Supervised Pre-training for Full Stack Speech Processing,
S. Chen, C. Wang, Z. Chen,et al., “WavLM: Large-Scale Self- Supervised Pre-training for Full Stack Speech Processing,”IEEE Journal of Selected Topics in Signal Processing, 2022
2022
-
[16]
DistilHuBERT: Speech Representation Learning by Layer-wise Distillation of Hidden-unit BERT,
H.-J. Chang, S.-W. Yang, and H.-Y . Lee, “DistilHuBERT: Speech Representation Learning by Layer-wise Distillation of Hidden- unit BERT,”arXiv preprint arXiv:2110.01900, 2021
-
[17]
Domain-Adversarial Training of Neural Networks,
Y . Ganin, E. Ustinova, H. Ajakan,et al., “Domain-Adversarial Training of Neural Networks,”JMLR, 2016
2016
-
[18]
SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition,
D. S. Park, W. Chan, Y . Zhang,et al., “SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition,” inProc. Interspeech, 2019
2019
-
[19]
Silero V AD: Pre-trained V oice Activity De- tector,
Silero Team, “Silero V AD: Pre-trained V oice Activity De- tector,” GitHub repository, 2021.https://github.com/ snakers4/silero-vad
2021
-
[20]
Classification of Spontaneous and Scripted Speech for Multilin- gual Audio,
S. Elisha, A. McDowell, M. Beguerisse-D ´ıaz, and E. Benetos, “Classification of Spontaneous and Scripted Speech for Multilin- gual Audio,”arXiv preprint arXiv:2412.11896, 2024
-
[21]
”Speaking styles in speech research.” Work- shop on Integrating Speech and Natural Language
Llisterri, Joaquim. ”Speaking styles in speech research.” Work- shop on Integrating Speech and Natural Language. 1992
1992
-
[23]
”Comparison of prosodic properties between read and spontaneous speech material.” Speech communication 10.2 (1991): 163-169
Howell, Peter, and Karima Kadi-Hanifi. ”Comparison of prosodic properties between read and spontaneous speech material.” Speech communication 10.2 (1991): 163-169
1991
-
[24]
Low, Daniel M., et al. ”Identifying bias in models that detect vocal fold paralysis from audio recordings using explainable machine learning and clinician ratings.” PLOS Digital Health 3.5 (2024): e0000516
2024
-
[25]
SUPERB: Speech processing Universal PERformance Benchmark,
Yang, Shu-wen, et al. ”Superb: Speech processing universal per- formance benchmark.” arXiv preprint arXiv:2105.01051 (2021)
-
[26]
”De- constructing demographic bias in speech-based machine learning models for digital health.” Frontiers in Digital Health 6 (2024): 1351637
Yang, Michael, Abd-Allah El-Attar, and Theodora Chaspari. ”De- constructing demographic bias in speech-based machine learning models for digital health.” Frontiers in Digital Health 6 (2024): 1351637
2024
-
[27]
”Revealing confounding biases: A novel benchmarking approach for aggregate-level performance metrics in health assessments.” Proc
Polle, Roseline, et al. ”Revealing confounding biases: A novel benchmarking approach for aggregate-level performance metrics in health assessments.” Proc. Interspeech 2024 (2024): 1440-1444
2024
-
[28]
Shim, Hye-jin, et al. ”How to construct perfect and worse- than-coin-flip spoofing countermeasures: A word of warning on shortcut learning.” arXiv preprint arXiv:2306.00044 (2023)
-
[29]
”Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods.” Advances in large margin classifiers 10.3 (1999): 61-74
Platt, John. ”Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods.” Advances in large margin classifiers 10.3 (1999): 61-74
1999
-
[30]
Adam: A Method for Stochastic Optimization
Kingma, Diederik P., and Jimmy Ba. ”Adam: A method for stochastic optimization.” arXiv preprint arXiv:1412.6980 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[31]
”Content-based representations of audio using siamese neural networks.” 2018 IEEE International Con- ference on Acoustics, Speech and Signal Processing (ICASSP)
Manocha, Pranay, et al. ”Content-based representations of audio using siamese neural networks.” 2018 IEEE International Con- ference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018
2018
-
[32]
”Hear: Holistic evaluation of audio represen- tations.” NeurIPS 2021 Competitions and Demonstrations Track
Turian, Joseph, et al. ”Hear: Holistic evaluation of audio represen- tations.” NeurIPS 2021 Competitions and Demonstrations Track. PMLR, 2022
2021
-
[33]
Manocha, Pranay, et al. ”A differentiable perceptual audio met- ric learned from just noticeable differences.” arXiv preprint arXiv:2001.04460 (2020)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.