Learning Perspectivist Social Meaning via Demographic-Conditioned Fusion Embeddings
Pith reviewed 2026-06-27 21:57 UTC · model grok-4.3
The pith
Demographic-conditioned fusion embeddings improve prediction of how social meanings vary across annotator groups.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
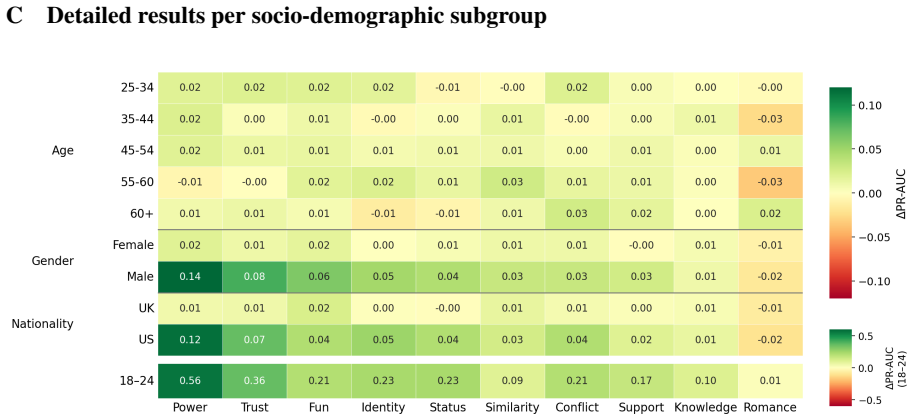
The authors demonstrate that conditioning embedding models on demographic information from annotators captures variation in social meaning labels along a perspectivist spectrum, producing statistically significant improvements over text-only baselines through multiple fusion strategies on 28k annotations, with shuffle tests confirming the demographic signal is substantive rather than spurious.
What carries the argument
Demographic-conditioned fusion embeddings that integrate textual representations with demographic profiles of annotators to model perspectival variation.
If this is right
- Fusion strategies yield 5.9-6.5 percent relative macro PR-AUC gains over text-only baselines.
- Demographic profiles supply genuine predictive information, as shown by shuffle ablations.
- The approach applies across zero-shot, few-shot, and fine-tuned modeling paradigms.
- NLP systems can shift from single ground-truth labels toward modeling a spectrum of demographic-dependent interpretations.
Where Pith is reading between the lines
- The method could be tested on whether it improves fairness metrics when applied to subjective tasks like toxicity labeling.
- Models trained this way might allow downstream applications to output different interpretations depending on the end user's demographic profile.
- Extending the fusion to continuous demographic variables rather than discrete groups could be checked on the same annotation set.
Load-bearing premise
The 28k annotations genuinely reflect perspectival differences driven by demographic backgrounds rather than annotation noise or dataset-specific artifacts.
What would settle it
A follow-up experiment that shuffles all demographic labels before fusion and finds the performance gains disappear entirely would falsify the claim that demographics carry genuine predictive signal.
Figures
read the original abstract
Social meaning in language is inherently perspectival, varying across annotator backgrounds, demographics, and ideological positions. However, most NLP systems collapse this variation into a single ground-truth label, ignoring the diversity of interpretations. In this work, we model social dimensions along a perspectivist spectrum, capturing how interpretations vary across demographic groups on a dataset consisting of 28k human annotations. We benchmark multiple modeling paradigms, including zero-shot, few-shot, and fine-tuned approaches, and propose fusion embeddings that integrate textual and demographic representations. Our fusion models yield consistent and statistically significant improvements over text-only baselines across all fusion strategies (+5.9-6.5% relative macro PR-AUC), with shuffle ablations confirming that demographic profiles carry genuine predictive signal rather than spurious correlations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes demographic-conditioned fusion embeddings to model perspectivist social meaning, where interpretations vary by annotator demographics. On a 28k-annotation dataset, it benchmarks zero-shot, few-shot, and fine-tuned approaches and reports that fusion models achieve consistent, statistically significant gains of +5.9-6.5% relative macro PR-AUC over text-only baselines; shuffle ablations are presented as evidence that demographic profiles supply genuine predictive signal.
Significance. If the empirical results and controls hold under scrutiny, the work supplies a practical, extensible technique for incorporating demographic conditioning into social-meaning models, moving the field beyond single-ground-truth assumptions toward more nuanced, group-aware representations.
major comments (2)
- [Abstract] Abstract and Methods: the central claim of statistically significant gains is presented without any description of the statistical tests performed, the exact model architectures, training hyperparameters, data splits, or evaluation protocol, rendering the reported +5.9-6.5% macro PR-AUC improvements unverifiable from the supplied text.
- [Ablation studies] Ablation studies: the shuffle ablation shows that randomizing demographic profiles degrades performance, yet this only demonstrates that the model exploits the supplied demographic labels; it does not exclude the possibility that the original 28k annotations contain systematic artifacts (annotator-pool biases, interface effects, or task-specific response patterns) that happen to covary with the recorded demographics.
minor comments (1)
- Notation for the different fusion strategies (early, late, etc.) should be defined explicitly and used consistently in equations and figures.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each major comment below, providing clarifications from the full paper and indicating where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract and Methods: the central claim of statistically significant gains is presented without any description of the statistical tests performed, the exact model architectures, training hyperparameters, data splits, or evaluation protocol, rendering the reported +5.9-6.5% macro PR-AUC improvements unverifiable from the supplied text.
Authors: The abstract is necessarily concise, but the full manuscript provides these details: model architectures and fusion strategies are described in Section 3, training hyperparameters and optimization in Appendix A, data splits (train/dev/test on the 28k annotations) in Section 4.1, evaluation protocol (macro PR-AUC with per-class averaging) in Section 4.2, and statistical significance via paired bootstrap tests (p < 0.01) in Section 5.1. We will revise the abstract to include a brief clause referencing the evaluation protocol and significance testing for improved self-containment. revision: partial
-
Referee: [Ablation studies] Ablation studies: the shuffle ablation shows that randomizing demographic profiles degrades performance, yet this only demonstrates that the model exploits the supplied demographic labels; it does not exclude the possibility that the original 28k annotations contain systematic artifacts (annotator-pool biases, interface effects, or task-specific response patterns) that happen to covary with the recorded demographics.
Authors: The shuffle ablation (Section 5.3) establishes that performance depends on the specific demographic profiles rather than arbitrary labels, supporting that demographic conditioning supplies usable signal. We agree this does not exhaustively exclude all possible annotation artifacts correlated with demographics. We will add an explicit limitations paragraph acknowledging this and noting that future work could incorporate annotator-level fixed effects or interface controls. revision: partial
Circularity Check
No circularity: empirical evaluation relies on external data and baselines
full rationale
The paper reports measured improvements (+5.9-6.5% relative macro PR-AUC) of fusion embeddings over text-only baselines on an external dataset of 28k annotations, with shuffle ablations as controls. No equations, parameters, or self-citations are shown that would make the reported gains equivalent to the inputs by construction. The derivation chain consists of standard supervised learning and ablation testing against independent benchmarks, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human annotations on social meaning tasks reflect genuine perspectival differences attributable to demographic background.
Reference graph
Works this paper leans on
-
[1]
CoRR , volume =
Yinhan Liu and Myle Ott and Naman Goyal and Jingfei Du and Mandar Joshi and Danqi Chen and Omer Levy and Mike Lewis and Luke Zettlemoyer and Veselin Stoyanov , title =. CoRR , volume =. 2019 , url =
2019
-
[2]
The pushshift reddit dataset , volume =
Baumgartner, Jason and Zannettou, Savvas and Keegan, Brian and Squire, Megan and Blackburn, Jeremy , booktitle =. The pushshift reddit dataset , volume =
-
[3]
Multimodal Post Attentive Profiling for Influencer Marketing , year =
Kim, Seungbae and Jiang, Jyun-Yu and Nakada, Masaki and Han, Jinyoung and Wang, Wei , booktitle =. Multimodal Post Attentive Profiling for Influencer Marketing , year =
-
[4]
John , doi =
Beatrice Rammstedt and Oliver P. John , doi =. Measuring personality in one minute or less: A 10-item short version of the Big Five Inventory in English and German , url =. Journal of Research in Personality , keywords =. 2007 , bdsk-url-1 =
2007
-
[5]
Social Media Fact Sheet , year =
-
[6]
Proceedings of the International AAAI Conference on Web and Social Media , volume=
The persuasive power of large language models , author=. Proceedings of the International AAAI Conference on Web and Social Media , volume=
-
[7]
2023 , publisher=
Scientific Reports , volume=. 2023 , publisher=
2023
-
[8]
Proceedings of the ACM on Human-Computer Interaction , volume=
Coloring in the links: Capturing social ties as they are perceived , author=. Proceedings of the ACM on Human-Computer Interaction , volume=. 2018 , publisher=
2018
-
[9]
Abercrombie, Gavin and Dinkar, Tanvi and Cercas Curry, Amanda and Rieser, Verena and Hovy, Dirk. Consistency is Key: Disentangling Label Variation in Natural Language Processing with Intra-Annotator Agreement. Proceedings of the The 4th Workshop on Perspectivist Approaches to NLP. 2025. doi:10.18653/v1/2025.nlperspectives-1.6
-
[10]
Language Resources and Evaluation , volume=
Perspectivist approaches to natural language processing: a survey , author=. Language Resources and Evaluation , volume=. 2025 , publisher=
2025
-
[11]
The ``problem'' of human label variation: On ground truth in data, modeling and evaluation
Plank, Barbara. The ``Problem'' of Human Label Variation: On Ground Truth in Data, Modeling and Evaluation. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.731
-
[12]
Cabitza, Federico and Campagner, Andrea and Basile, Valerio , title =. Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Educational Advances in Artificial Intelligence , articleno =. 2023 , isbn =. doi:10.1609/aaai.v37i...
-
[14]
URL https: //aclanthology.org/2025.acl-long.104/
Orlikowski, Matthias and Pei, Jiaxin and R. Beyond Demographics: Fine-tuning Large Language Models to Predict Individuals' Subjective Text Perceptions. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.104
-
[15]
Gender Differences in Conversational Interaction
Gender differences in conversational coherence: Physical alignment and topical cohesion. , author=. This chapter is a slightly revised and shortened version of a paper presented at the" Gender Differences in Conversational Interaction" panel at the 1988 Georgetown University Round Table on Languages and Linguistics, Washington, DC, Mar 1988. , year=
1988
-
[16]
Proceedings of the 2011 ACM SIGCOMM conference on Internet measurement conference , pages=
Counting youtube videos via random prefix sampling , author=. Proceedings of the 2011 ACM SIGCOMM conference on Internet measurement conference , pages=
2011
-
[17]
Communications of the ACM , volume=
Datasheets for datasets , author=. Communications of the ACM , volume=. 2021 , publisher=
2021
-
[18]
Subjective Natural Language Problems: Motivations, Applications, Characterizations, and Implications
Ovesdotter Alm, Cecilia. Subjective Natural Language Problems: Motivations, Applications, Characterizations, and Implications. Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. 2011
2011
-
[19]
Proceedings of the 1st Workshop on Benchmarking: Past, Present and Future , year =
We Need to Consider Disagreement in Evaluation , author =. Proceedings of the 1st Workshop on Benchmarking: Past, Present and Future , year =. doi:10.18653/v1/2021.bppf-1.3 , pages =
-
[20]
URLhttps://doi.org/10.1613/jair.1.12752
Learning from Disagreement: A Survey , author =. Journal of Artificial Intelligence Research , volume =. 2021 , pages =. doi:10.1613/jair.1.12752 , url =
-
[21]
Proceedings of The Web Conference 2020 , year =
Ten Social Dimensions of Conversations and Relationships , author =. Proceedings of The Web Conference 2020 , year =
2020
-
[22]
Scientific Reports , volume =
The Language of Opinion Change on Social Media under the Lens of Communicative Action , author =. Scientific Reports , volume =. 2022 , doi =
2022
-
[23]
From Reddit to
Lucchini, Lorenzo and Aiello, Luca Maria and Alessandretti, Laura and De Francisci Morales, Gianmarco and Starnini, Michele and Baronchelli, Andrea , journal =. From Reddit to. 2022 , doi =
2022
-
[24]
How Epidemic Psychology Works on
Aiello, Luca Maria and Quercia, Daniele and Zhou, Ke and Constantinides, Marios and. How Epidemic Psychology Works on. Humanities and Social Sciences Communications , volume =. 2021 , doi =
2021
-
[25]
The Pursuit of Peer Support for Opioid Use Recovery on
Balsamo, Duilio and Bajardi, Paolo and De Francisci Morales, Gianmarco and Monti, Corrado and Schifanella, Rossano , booktitle =. The Pursuit of Peer Support for Opioid Use Recovery on. 2023 , pages =
2023
-
[26]
Waseem, Zeerak , booktitle =. Are You a Racist or Am. 2016 , address =. doi:10.18653/v1/W16-5618 , pages =
-
[27]
Annotators with Attitudes: How Annotator Beliefs And Identities Bias Toxic Language Detection
Annotators with Attitudes: How Annotator Beliefs And Identities Bias Toxic Language Detection , author =. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , year =. doi:10.18653/v1/2022.naacl-main.431 , pages =
-
[28]
Dealing with Disagreements: Looking Beyond the Majority Vote in Subjective Annotations
Dealing with Disagreements: Looking Beyond the Majority Vote in Subjective Annotations , author =. Transactions of the Association for Computational Linguistics , volume =. 2022 , address =. doi:10.1162/tacl_a_00449 , pages =
-
[29]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , year =
The Ecological Fallacy in Annotation: Modeling Human Label Variation goes beyond Sociodemographics , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , year =
-
[30]
The Importance of Modeling Social Factors of Language: Theory and Practice , author =. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , year =. doi:10.18653/v1/2021.naacl-main.49 , pages =
-
[31]
2019 , url =
Liu, Yinhan and Ott, Myle and Goyal, Naman and Du, Jingfei and Joshi, Mandar and Chen, Danqi and Levy, Omer and Lewis, Mike and Zettlemoyer, Luke and Stoyanov, Veselin , journal =. 2019 , url =
2019
-
[32]
and Rosen, Rachel and Vasserman, Lucy , title =
Goyal, Nitesh and Kivlichan, Ian D. and Rosen, Rachel and Vasserman, Lucy , title =. Proc. ACM Hum.-Comput. Interact. , month = nov, articleno =. 2022 , issue_date =. doi:10.1145/3555088 , abstract =
-
[33]
2026 , eprint=
P1SCO: Social Dimensions from a Perspectivist Lens , author=. 2026 , eprint=
2026
-
[34]
Pei, Jiaxin and Jurgens, David. When Do Annotator Demographics Matter? Measuring the Influence of Annotator Demographics with the POPQUORN Dataset. Proceedings of the 17th Linguistic Annotation Workshop (LAW-XVII). 2023. doi:10.18653/v1/2023.law-1.25
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.