Learning-Based Decision Making for Combustion Phasing Control in Multi-Fuel CI Engines with Latent Fuel Reactivity Estimation
Pith reviewed 2026-06-26 22:35 UTC · model grok-4.3
The pith
Training an RL policy on estimated rather than true fuel reactivity produces stable CA50 regulation under unknown cetane number variation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
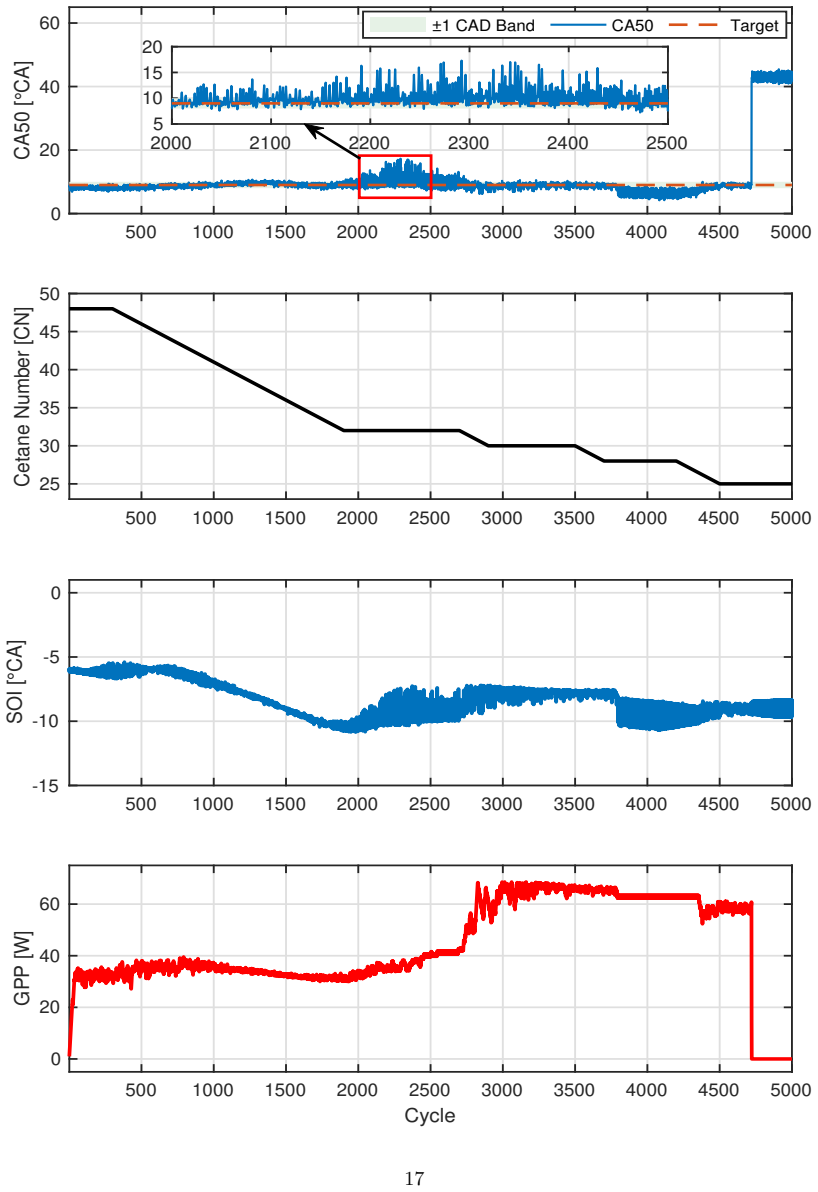
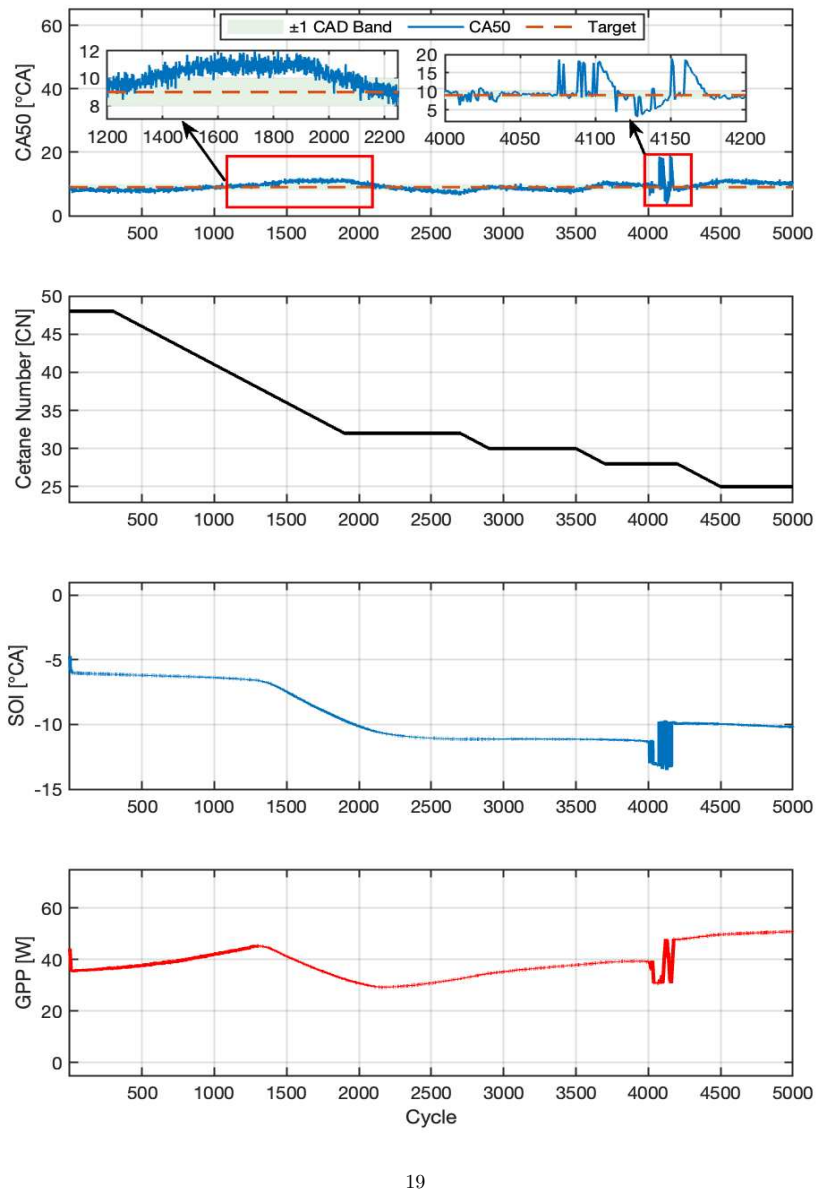
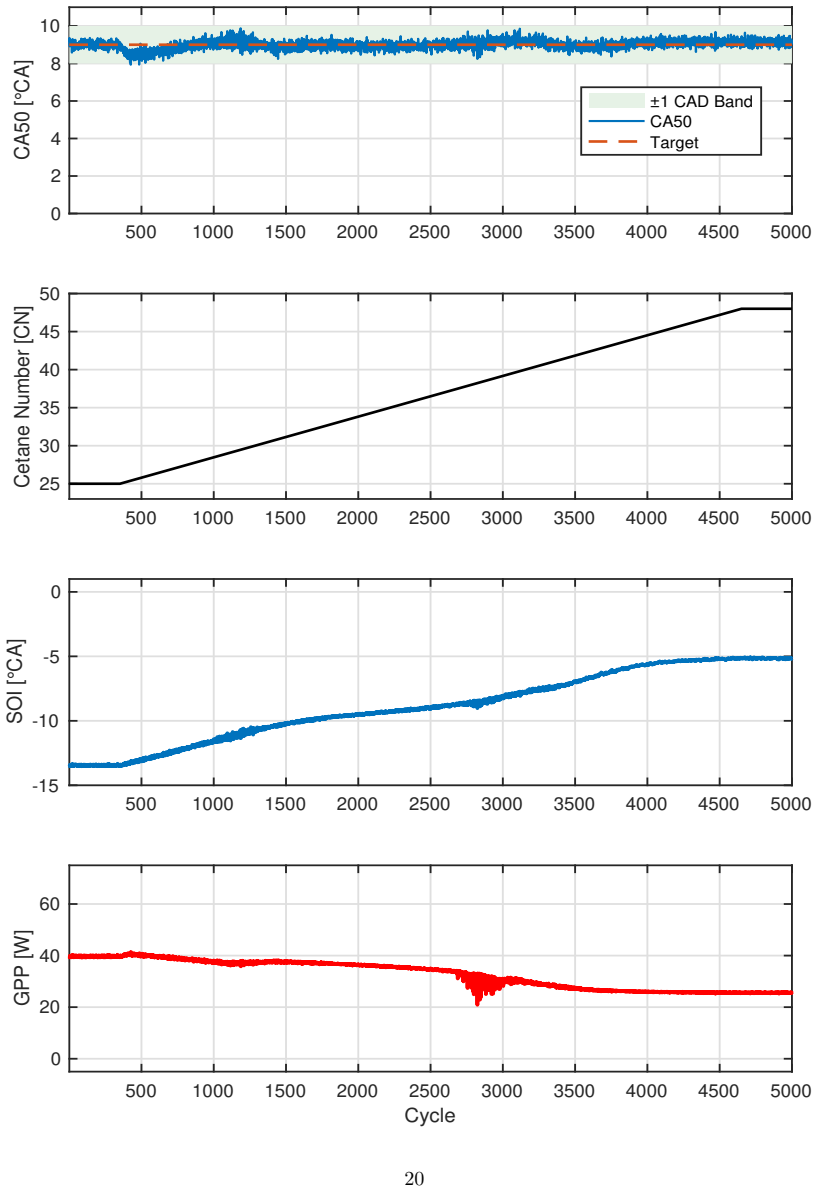
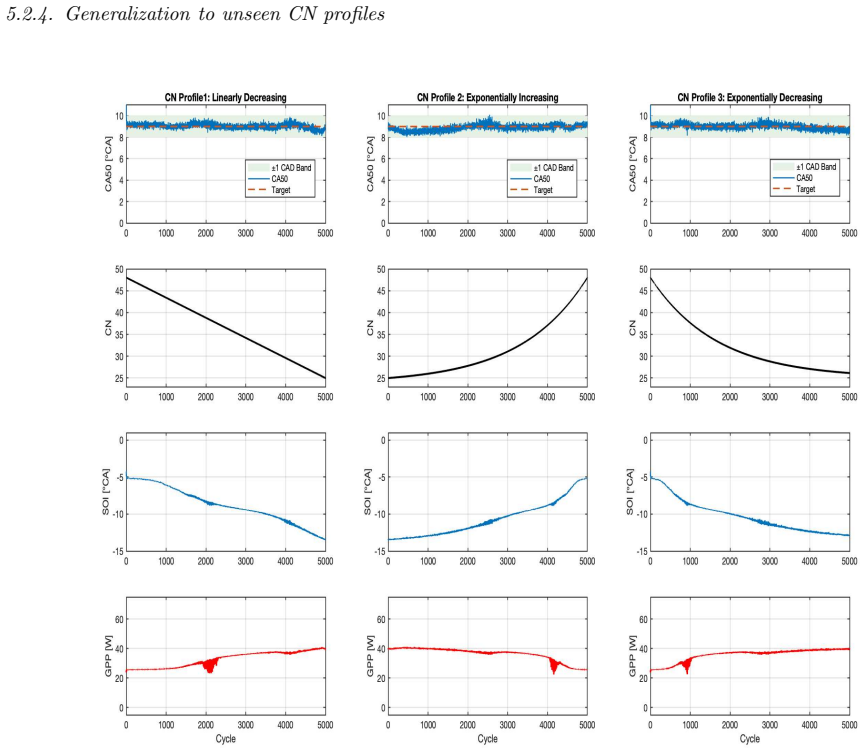
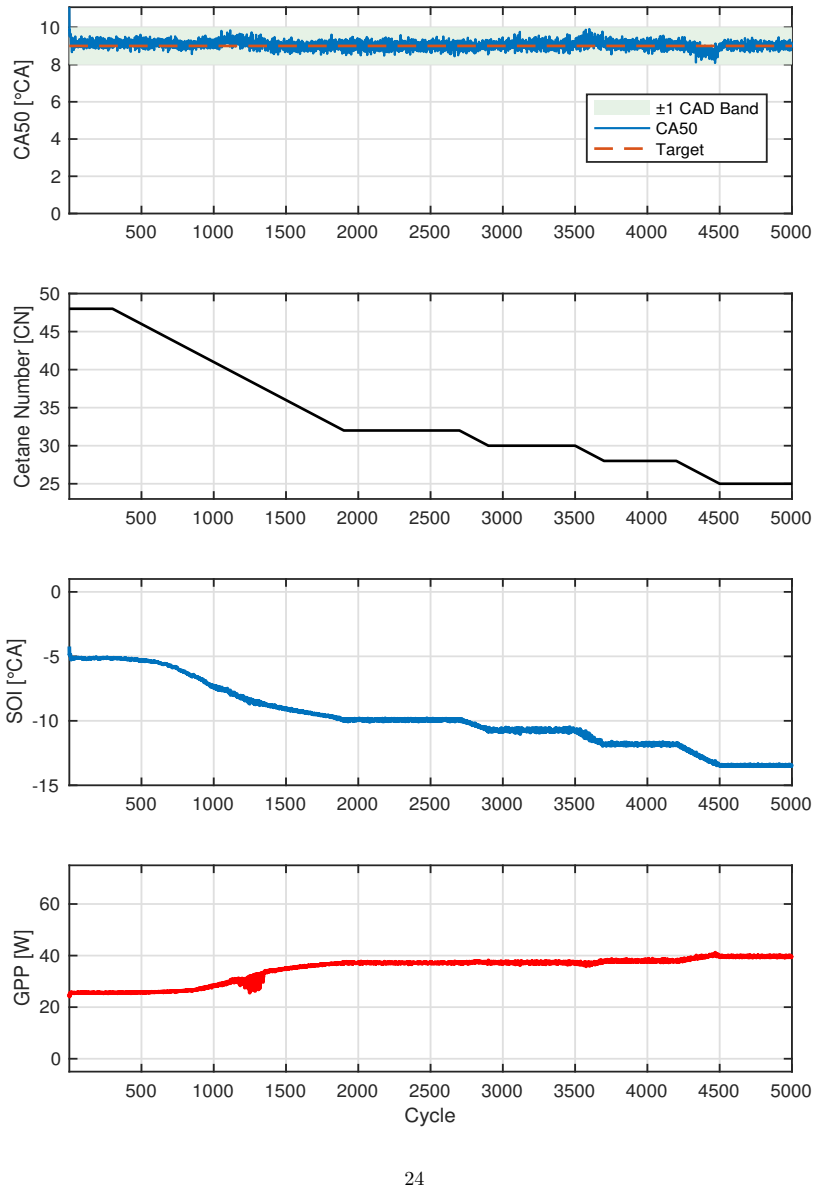
The proposed GRU-guided RL framework learns a compact GRU-based representation of fuel reactivity from combustion history and conditions both actor and critic on this estimated signal rather than oracle CN. By training the policy on the same imperfect fuel-reactivity information available at deployment, the controller avoids train-deploy inconsistency in conventional online estimate-then-control pipelines. Across unseen CN trajectories, the policy achieves stable CA50 regulation with mean absolute tracking error below 0.25° CA at the training setpoint, while producing smooth, physically consistent SOI and glow-plug-power actuation.
What carries the argument
GRU-guided RL framework that extracts a latent fuel-reactivity estimate from combustion history to condition the actor and critic networks.
If this is right
- Myopic and fixed-history bandit methods degrade under CN variation.
- Observation-only RL suffers from latent-state aliasing.
- Generic recurrence is insufficient when CN evolves rapidly.
- The framework enables reactivity-aware decision-making using only the estimated state available during deployment.
Where Pith is reading between the lines
- The same training-on-estimate principle could be tested on other partially observable engine or process-control tasks where a hidden parameter drifts over time.
- End-to-end learning of state representation and control may reduce the need for separate online estimators in time-varying systems.
- Hardware experiments with real fuel switches would directly test whether the surrogate-to-real transfer holds.
- The method suggests that explicit conditioning of the policy on a learned latent state can outperform both pure model-free RL and modular estimation-plus-control pipelines.
Load-bearing premise
The Gaussian-process surrogate trained on experimental multi-fuel engine data accurately captures real engine dynamics under varying cetane numbers so that simulation performance transfers to physical hardware.
What would settle it
Deploy the trained controller on a physical multi-fuel CI engine, apply continuously varying cetane-number trajectories, and measure whether mean absolute CA50 tracking error stays below 0.25 degrees.
Figures
read the original abstract
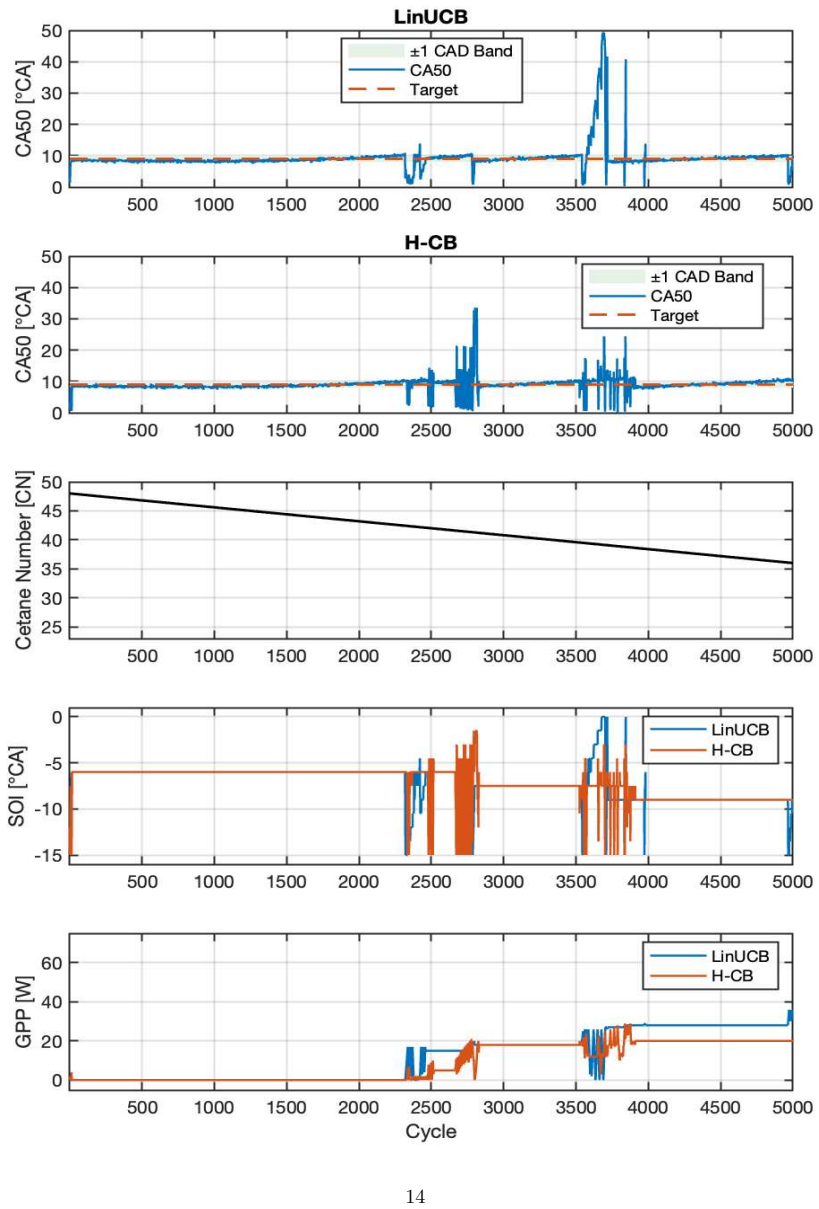
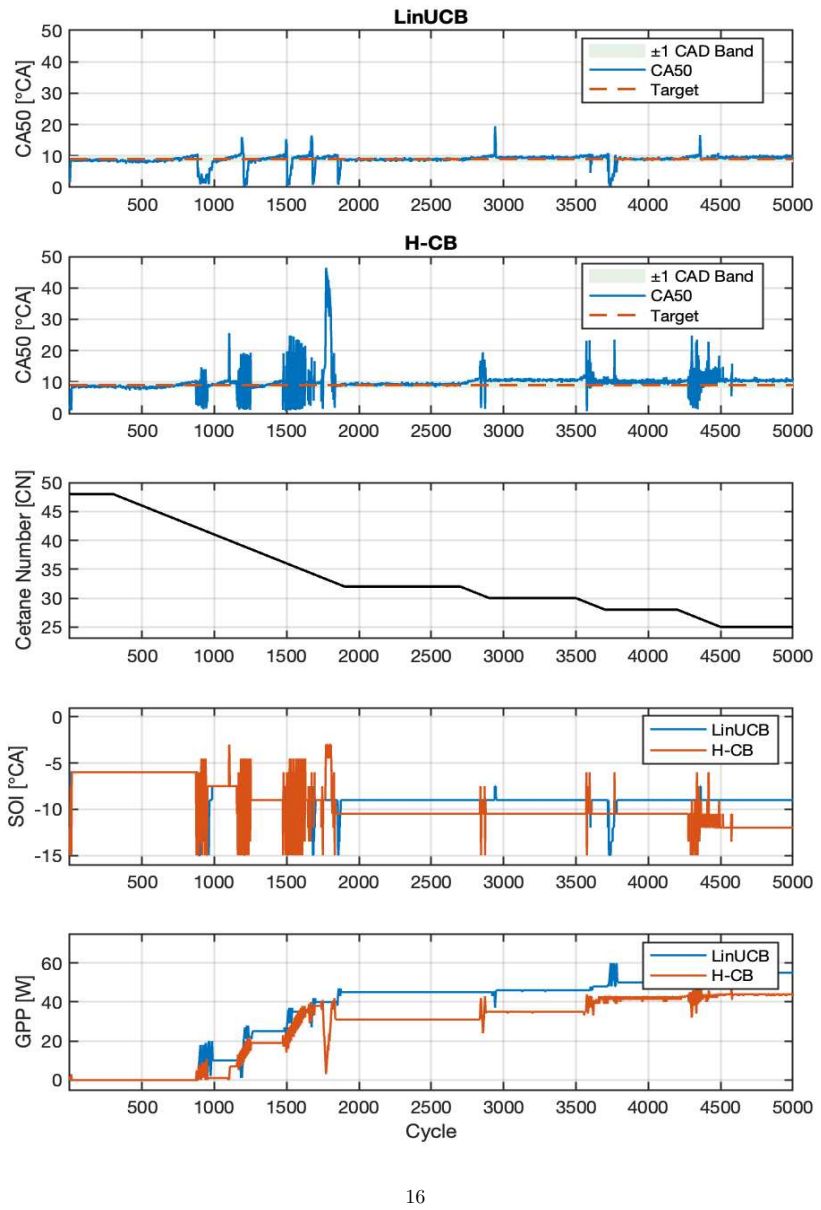
Multi-fuel compression-ignition engines offer fuel flexibility but introduce uncertain, time-varying fuel reactivity, represented by cetane number (CN), which complicates cycle-to-cycle combustion-phasing control. This work formulates CA50 regulation under latent CN variation as a partially observable sequential decision problem and systematically evaluates controllers with increasing temporal and representational capacity, including LinUCB, history-augmented contextual bandits, observation-only DDPG, recurrent DDPG, and a proposed GRU-guided RL framework. A Gaussian-process surrogate trained on experimental multi-fuel engine data provides a controlled and reproducible evaluation environment. Results show that myopic and fixed-history bandit methods degrade under CN variation, observation-only RL suffers from latent-state aliasing, and generic recurrence is insufficient when CN evolves rapidly. The proposed framework learns a compact GRU-based representation of fuel reactivity from combustion history and conditions both actor and critic on this estimated signal rather than oracle CN. By training the policy on the same imperfect fuel-reactivity information available at deployment, the controller avoids train-deploy inconsistency in conventional online estimate-then-control pipelines. Across unseen CN trajectories, the policy achieves stable CA50 regulation with mean absolute tracking error below 0.25{\deg} CA at the training setpoint, while producing smooth, physically consistent SOI and glow-plug-power actuation. These results show that combustion control under latent, continuously evolving fuel dynamics requires more than standalone estimation or generic recurrence. By aligning fuel-reactivity inference with control policy learning, the proposed framework enables reactivity-aware decision-making using the same estimated state available during deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates CA50 regulation in multi-fuel CI engines under latent, time-varying cetane number (CN) as a POMDP and compares controllers of increasing capacity (LinUCB, history-augmented bandits, observation-only DDPG, recurrent DDPG, and a proposed GRU-guided RL policy). A Gaussian-process surrogate trained on experimental multi-fuel engine data serves as the evaluation environment. The central claim is that the GRU-guided policy, by conditioning actor and critic on a learned reactivity estimate rather than oracle CN, avoids train-deploy inconsistency and achieves stable regulation (mean absolute tracking error below 0.25° CA) with smooth actuation on unseen CN trajectories.
Significance. If the surrogate results transfer, the work would usefully demonstrate that integrated representation learning and policy optimization outperform separate estimation-then-control pipelines or generic recurrence for latent-state engine control. The systematic controller comparison and use of experimental data to build the surrogate are constructive elements.
major comments (2)
- [Abstract and Evaluation] Abstract and results sections: All reported performance metrics (including the <0.25° CA mean absolute tracking error, actuation smoothness, and superiority over LinUCB/DDPG variants) are generated exclusively inside the GP surrogate. No closed-loop deployment on the physical engine, nor any hold-out experimental validation of surrogate fidelity under the tested unseen CN trajectories, is described. Because the central claim concerns train-deploy consistency and reactivity-aware decision-making that works with the same imperfect information available at deployment, the absence of hardware evidence is load-bearing.
- [Results] Results section: The quantitative claims lack error bars, statistical tests across multiple random seeds or CN realizations, and ablation studies isolating the contribution of the GRU representation versus generic recurrence. These omissions make it difficult to assess whether the reported advantage is robust or sensitive to surrogate hyperparameters.
minor comments (2)
- [Surrogate Model] The surrogate is described as providing a 'controlled and reproducible evaluation environment,' but no quantitative metrics of its open-loop or closed-loop prediction accuracy on held-out experimental cycles are supplied.
- [Method] Notation for the GRU hidden state and how it is fed to actor/critic could be clarified with an explicit diagram or equations.
Simulated Author's Rebuttal
Thank you for the referee's constructive feedback. We address each major comment below, clarifying the role of the surrogate evaluation and committing to added statistical analysis and ablations where feasible.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and results sections: All reported performance metrics (including the <0.25° CA mean absolute tracking error, actuation smoothness, and superiority over LinUCB/DDPG variants) are generated exclusively inside the GP surrogate. No closed-loop deployment on the physical engine, nor any hold-out experimental validation of surrogate fidelity under the tested unseen CN trajectories, is described. Because the central claim concerns train-deploy consistency and reactivity-aware decision-making that works with the same imperfect information available at deployment, the absence of hardware evidence is load-bearing.
Authors: We acknowledge that all quantitative results are obtained within the GP surrogate trained on experimental multi-fuel engine data. This surrogate enables reproducible, controlled evaluation of controller behavior under precisely specified latent CN trajectories that would be difficult to realize repeatably on hardware. The central methodological claim—that conditioning the policy on a learned reactivity estimate avoids train-deploy mismatch—is directly testable in this setting because the same imperfect observations are used at both training and test time. We will revise the manuscript to include additional details on surrogate validation against available experimental hold-out sets for the CN trajectories considered. We agree that closed-loop hardware results would provide further support; such experiments lie outside the present scope focused on the learning formulation and will be noted as future work. revision: partial
-
Referee: [Results] Results section: The quantitative claims lack error bars, statistical tests across multiple random seeds or CN realizations, and ablation studies isolating the contribution of the GRU representation versus generic recurrence. These omissions make it difficult to assess whether the reported advantage is robust or sensitive to surrogate hyperparameters.
Authors: We agree that the results section would benefit from greater statistical rigor. In the revised manuscript we will report mean and standard deviation across at least five random seeds for all RL policies, include paired statistical tests comparing the GRU-guided policy against the recurrent DDPG baseline across multiple CN trajectory realizations, and add an ablation that replaces the GRU reactivity estimator with a generic LSTM while keeping the rest of the architecture fixed. These additions will quantify robustness to initialization and isolate the benefit of the learned reactivity representation. revision: yes
Circularity Check
No circularity in derivation or evaluation chain
full rationale
The paper formulates CA50 regulation as a POMDP and compares RL controllers (including the proposed GRU-guided framework) inside a fixed GP surrogate trained on prior experimental data. The central methodological claim—that training on the same imperfect reactivity estimate avoids train-deploy mismatch—is a design choice, not a mathematical derivation. All reported metrics (tracking error <0.25° CA on unseen CN trajectories) are generated by forward simulation in that external surrogate; no step reduces a prediction to a fitted target by construction, invokes a self-citation as a uniqueness theorem, or renames an input as an output. The evaluation remains independent of the policy's own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A. Pal, A. Cornelius, Z. Sun, K. Kim, C.-B. M. Kweon, Data- driven real-time fuel cetane estimation and control design for multifuel uavs, Applied Energy 367 (2024) 123336
2024
-
[2]
D. A. Splitter, R. D. Reitz, Fuel reactivity effects on the efficiency and operational window of dual-fuel compression ignition engines, Fuel 118 (2014) 163–175
2014
-
[3]
X. Dong, C. Goertemiller, A. Pal, Z. Sun, K. Kim, C.-B. M. K weon, Data driven feedforward control strategy for multi-f uel uas engine, IF AC-PapersOnLine 55 (37) (2022) 627–632
2022
-
[4]
M. H. Halbe, D. J. Fain, G. M. Shaver, L. Kocher, D. Koeberl ein, Control-oriented premixed charge compression igniti on ca50 model for a diesel engine utilizing variable valve actu ation, International Journal of Engine Research 18 (8) (201 7) 847–857
-
[5]
Z. Yang, R. Stobart, E. Winward, Online adjustment of sta rt of injection and fuel rail pressure based on combustion process parameters of diesel engine, in: SAE 2013 W orld Cong ress & Exhibition, SAE Technical paper, 2013
2013
-
[6]
M. Yoon, K. Lee, M. Sunwoo, A method for combustion phasin g control using cylinder pressure measurement in a crdi diesel engine, Mechatronics 17 (9) (2007) 469–479
2007
-
[7]
Willems, E
F. Willems, E. Doosje, F. Engels, X. Seykens, Cylinder pr essure-based control in heavy-duty egr diesel engines usin g a virtual heat release and emission sensor, Tech. rep. (2010)
2010
-
[8]
Zurbriggen, T
F. Zurbriggen, T. Ott, C. Onder, L. Guzzella, Optimal con trol of the heat release rate of an internal combustion engin e with pressure gradient, maximum pressure, and knock constraint s, Journal of Dynamic Systems, Measurement, and Control 136 (6) (2014) 061006. 25
2014
-
[9]
N. J. Killingsworth, S. M. Aceves, D. L. Flowers, F. Espin osa-Loza, M. Krstic, Hcci engine combustion-timing contro l: Optimizing gains and fuel consumption via extremum seeking , IEEE Transactions on Control Systems Technology 17 (6) (2009) 1350–1361
2009
-
[10]
J. K. Arora, M. Shahbakhti, Real-time closed-loop cont rol of a light-duty rcci engine during transient operations , in: WCX™ 17: SAE W orld Congress Experience, SAE Technical Paper, 201 7
-
[11]
A. Raut, B. K. Irdmousa, M. Shahbakhti, Dynamic modelin g and model predictive control of an rcci engine, Control Engineering Practice 81 (2018) 129–144
2018
-
[12]
Pamminger, C
M. Pamminger, C. M. Hall, T. W allner, Model predictive c ombustion control of a gasoline compression ignition engin e, Control Engineering Practice 119 (2022) 104977
2022
-
[13]
Mishra, P
C. Mishra, P. Subbarao, Design, development and testin g a hybrid control model for rcci engine using double wiebe function and random forest machine learning, Control Engin eering Practice 113 (2021) 104857
2021
-
[14]
Q. Peng, T. Rockstroh, M. Pamminger, C. Hall, Model pred ictive control of mixing controlled compression ignition operation for low reactivity fuels, Control Engineering Pr actice 139 (2023) 105631
2023
-
[15]
Ansari, T
E. Ansari, T. Menucci, M. Shahbakhti, J. Naber, Experim ental investigation into effects of high reactive fuel on com bustion and emission characteristics of the diesel-natural gas rea ctivity controlled compression ignition engine, Applied E nergy 239 (2019) 948–956
2019
-
[16]
Larimore, S
J. Larimore, S. Jade, E. Hellstr¨ om, L. Jiang, A. G. Stef anopoulou, Adaptive control of a recompression four-cylin der hcci engine, IEEE Transactions on Control Systems Technology 23 (6) (2015) 2144–2154
2015
-
[17]
B. Pla, P. Bares, A. Barbier, C. Guardiola, On-line opti mization of dual-fuel combustion operation by extremum see king techniques, Tech. rep., SAE Technical Paper (2021)
2021
-
[18]
Banerjee, R
A. Banerjee, R. Sarkar, I. B. Altiner, S. A. Govind Raju, Z. Sun, K. Kim, C.-B. M. Kweon, Data-driven modeling and control framework under partial state measurements with ex perimental validation on multi-fuel engines, Proceedings of the Institution of Mechanical Engineers, Part I: Journal of Systems and Control Engineering (2025) 09596518251399937
2025
-
[19]
M. T. Henry de Frahan, N. T. Wimer, S. Yellapantula, R. W. Grout, Deep reinforcement learning for dynamic control of fuel injection timing in multi-pulse compression ignition engines, International Journal of Engine Research 23 (9) (2 022) 1503–1521
-
[20]
N. T. Wimer, M. T. Henry de Frahan, S. Yellapantula, Deep reinforcement learning to discover multi-fuel injection strategies for compression ignition engines, Internation al Journal of Engine Research 24 (9) (2023) 3985–4007
2023
-
[21]
Norouzi, S
A. Norouzi, S. Shahpouri, D. Gordon, M. Shahbakhti, C. R . Koch, Safe deep reinforcement learning in diesel engine em ission control, Proceedings of the Institution of Mechanical Engi neers, Part I: Journal of Systems and Control Engineering 23 7 (8) (2023) 1440–1453
2023
-
[22]
B. P. Maldonado, B. C. Kaul, C. D. Schuman, S. R. Young, Re inforcement learning applied to dilute combustion control for increased fuel efficiency, International Journal of Engi ne Research 25 (6) (2024) 1157–1173
2024
- [23]
-
[24]
Sharma, A
V. Sharma, A. Winkler, A. Norouzi, H. Guo, J. Andert, D. G ordon, Safe reinforcement learning-based control for hydr ogen diesel dual-fuel engines, IF AC-PapersOnLine 59 (5) (2025) 19–24
2025
-
[25]
Ghosh, J
D. Ghosh, J. Rahme, A. Kumar, A. Zhang, R. P. Adams, S. Lev ine, Why generalization in rl is difficult: Epistemic pomdps and implicit partial observability, Advances in neural inf ormation processing systems 34 (2021) 25502–25515
2021
-
[26]
Q. Liu, A. Chung, C. Szepesv´ ari, C. Jin, When is partial ly observable reinforcement learning not scary?, in: Confe rence on Learning Theory, PMLR, 2022, pp. 5175–5220
2022
-
[27]
Omidshafiei, J
S. Omidshafiei, J. Pazis, C. Amato, J. P. How, J. Vian, Dee p decentralized multi-task multi-agent reinforcement lea rning under partial observability, in: International conferenc e on machine learning, PMLR, 2017, pp. 2681–2690
2017
-
[28]
L. Li, W. Chu, J. Langford, R. E. Schapire, A contextual- bandit approach to personalized news article recommendati on, in: Proceedings of the 19th international conference on W or ld wide web, 2010, pp. 661–670
2010
-
[29]
W. Chu, L. Li, L. Reyzin, R. Schapire, Contextual bandit s with linear payoff functions, in: Proceedings of the fourte enth international conference on artificial intelligence and st atistics, JMLR W orkshop and Conference Proceedings, 2011, pp. 208–214
2011
-
[30]
Bouneffouf, A
D. Bouneffouf, A. Bouzeghoub, A. L. Gan¸ carski, A contex tual-bandit algorithm for mobile context-aware recommend er system, in: International conference on neural informatio n processing, Springer, 2012, pp. 324–331
2012
-
[31]
Abbasi-Yadkori, D
Y. Abbasi-Yadkori, D. P´ al, C. Szepesv´ ari, Improved algorithms for linear stochastic bandits, Advances in neura l informa- tion processing systems 24 (2011)
2011
-
[32]
Lattimore, C
T. Lattimore, C. Szepesvari, G. W eisz, Learning with go od feature representations in bandits and in rl with a genera tive model, in: International conference on machine learning, P MLR, 2020, pp. 5662–5670
2020
-
[33]
J. A. Ayala-Romero, A. Garcia-Saavedra, X. Costa-Pere z, Risk-aware continuous control with neural contextual ba ndits, in: Proceedings of the AAAI Conference on Artificial Intelli gence, Vol. 38, 2024, pp. 20930–20938
2024
-
[34]
Br´ eg` ere, P
M. Br´ eg` ere, P. Gaillard, Y. Goude, G. Stoltz, Target t racking for contextual bandits: Application to demand side man- agement, in: International Conference on Machine Learning , PMLR, 2019, pp. 754–763
2019
-
[35]
Vapnik, R
V. Vapnik, R. Izmailov, Learning using privileged info rmation: similarity control and knowledge transfer, The Jo urnal of Machine Learning Research 16 (1) (2015) 2023–2049
2015
-
[36]
A. Baisero, C. Amato, Unbiased asymmetric reinforceme nt learning under partial observability, arXiv preprint arXiv:2105.11674 (2021)
arXiv 2021
-
[37]
D. Ebi, G. Lambrechts, D. Ernst, K. B¨ ohm, Informed asym metric actor-critic: Theoretical insights and open questi ons, in: Eighteenth European W orkshop on Reinforcement Learnin g, 2025. 26
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.