Sparse2Act: Learning Action-Aligned Sparse 3D Representations for Cross-Domain Robot Manipulation
Pith reviewed 2026-06-27 09:16 UTC · model grok-4.3
The pith
Robot actions supply geometric supervision that lets sparse 3D encoders transfer across manipulation domains and policy designs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
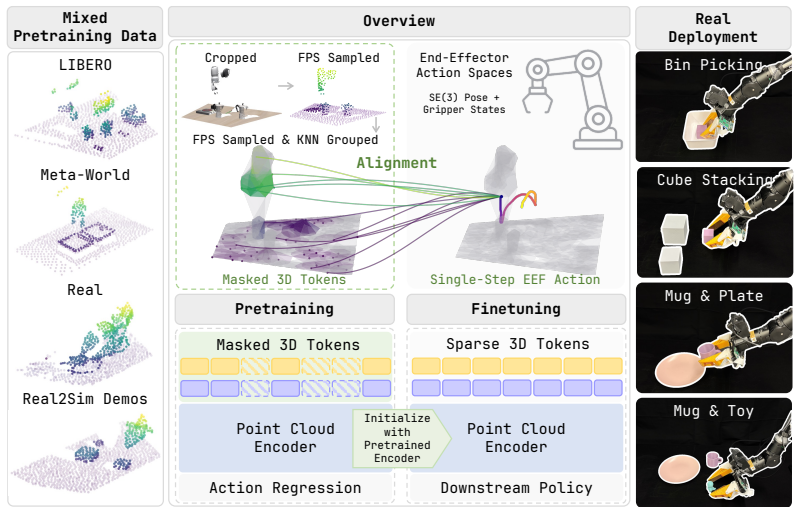
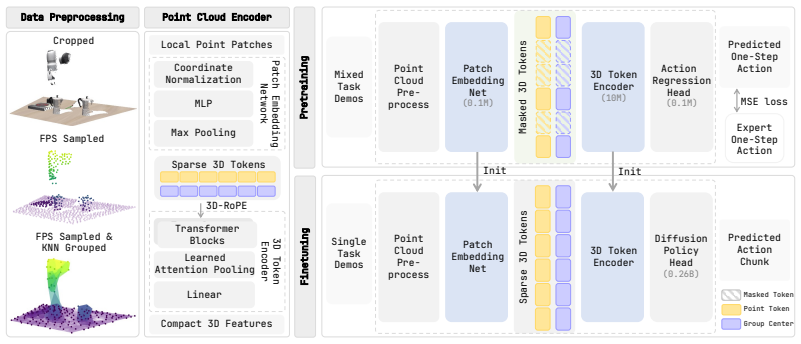
Sparse2Act trains masked sparse 3D tokens to organize features around workspace motions given by end-effector actions, creating encoder initializations that downstream policies can adopt without changing their own architectures or action parameterizations.
What carries the argument
The masked action-alignment objective that uses end-effector actions as geometric supervision for sparse point cloud features.
If this is right
- The pretrained encoder can be plugged into policies with different architectures and action spaces, including joint-space commands.
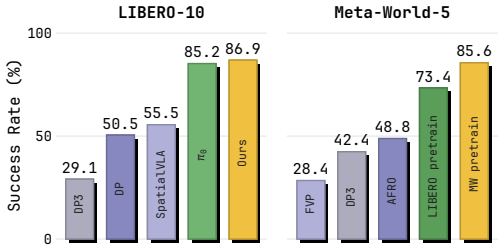
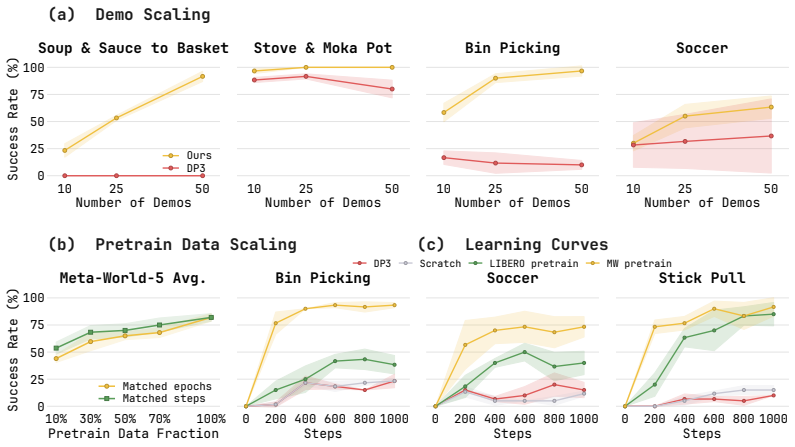
- The method reaches 86.9 percent average success on the LIBERO-10 benchmark after 500 fine-tuning steps.
- The same encoder supports transfer from LIBERO to Meta-World-5, reaching 73.4 percent average success.
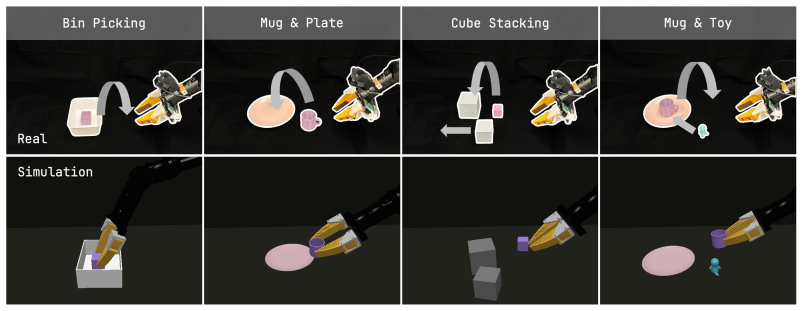
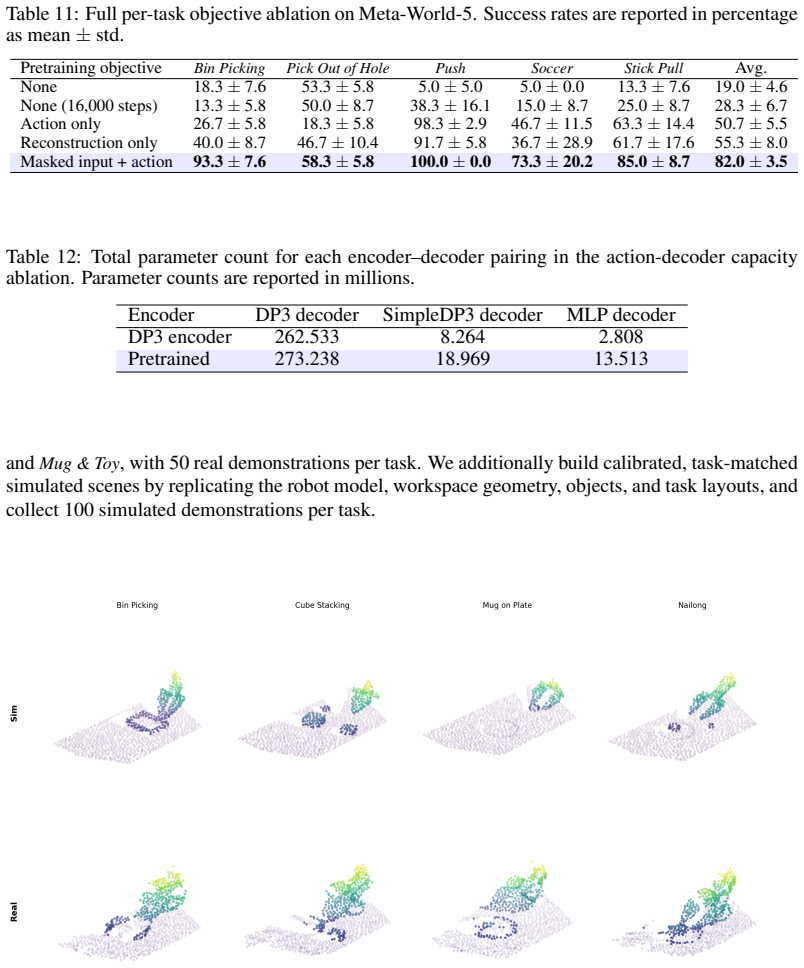
- Simulation pretraining followed by limited real-data fine-tuning yields 72.5 percent average success across four real-world tasks.
Where Pith is reading between the lines
- Action data collected for one set of tasks could bootstrap 3D representations useful for unrelated manipulation problems.
- The approach may reduce the volume of task-specific 3D data needed when moving to new robot hardware.
- Testing the encoder on scenes with multiple interacting objects or deformable items would reveal the limits of the geometric supervision.
Load-bearing premise
The masked action-alignment pretraining signal produces encoder features whose utility is largely independent of the downstream policy architecture and action parameterization.
What would settle it
A direct comparison showing that a randomly initialized encoder matches or exceeds the pretrained one's performance on cross-domain tasks after identical fine-tuning would falsify the claim.
Figures




read the original abstract
Explicit 3D representations are attractive for manipulation because they expose object shape, workspace geometry, and robot-object relations in metric coordinates. However, sparse 3D encoders are often learned through downstream task objectives, tying the representation to a particular data distribution, policy architecture, and action parameterization. We introduce Sparse2Act, an observation-action alignment framework for pretraining sparse point-cloud encoders. The key idea is to use task-space end-effector actions as geometric supervision: masked sparse 3D tokens are trained to organize scene features around the workspace motion paired with the observation. After pretraining, only the encoder initialization is reused by downstream policies, allowing them to retain their own architectures and action spaces, including joint-space commands. On the LIBERO-10 benchmark, our method achieves 86.9% average success after 500 fine-tuning steps. The same pretrained encoder supports LIBERO-to-Meta-World cross-domain transfer, achieving 73.4% average success on the Meta-World-5 benchmark. Ablations on the objective and decoder capacity show that the gains come from the masked action-alignment signal and remain useful across downstream action decoders. In real-world experiments, simulation pretraining followed by limited real-data fine-tuning achieves an average success rate of 72.5% across four tasks, demonstrating effective sim-to-real transfer. These results suggest that robot actions can provide compact geometric supervision for reusable sparse 3D representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Sparse2Act, an observation-action alignment framework for pretraining sparse point-cloud encoders. Task-space end-effector actions serve as geometric supervision via a masked action-alignment objective on sparse 3D tokens. After pretraining, only the encoder is reused to initialize downstream policies that retain their own architectures and action spaces. Reported results include 86.9% average success on LIBERO-10 after 500 fine-tuning steps, 73.4% average success on Meta-World-5 for LIBERO-to-Meta-World cross-domain transfer, and 72.5% average success in sim-to-real transfer across four real-world tasks. Ablations attribute performance gains to the action-alignment signal rather than decoder capacity.
Significance. If the central empirical claims hold after verification, the work would demonstrate that end-effector actions can supply compact geometric supervision for reusable sparse 3D representations that transfer across domains and support varied downstream action parameterizations. This flexibility is a practical strength for manipulation research. The reported cross-domain and sim-to-real numbers, together with ablations isolating the pretraining signal, would position the method as a useful pretraining approach for point-cloud encoders.
major comments (3)
- [Abstract] Abstract: the reported success rates (86.9% LIBERO-10, 73.4% Meta-World-5, 72.5% sim-to-real) and ablation claims are presented without implementation equations, training details, error bars, number of runs, or dataset statistics, rendering the central performance claims unverifiable from the supplied information.
- [Method] Method section (presumed §3): the masked action-alignment objective is described at a high level but the precise loss formulation, masking strategy, and how action tokens are paired with observations are not supplied, which is load-bearing for reproducing the claimed geometric supervision effect.
- [Experiments] Experiments (§4): the ablation attributing gains specifically to the action-alignment signal (rather than decoder capacity) lacks the quantitative breakdown or controls needed to confirm that the downstream policy architecture independence holds across the tested action spaces.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a brief statement of the precise input representation (e.g., point-cloud density or token count) to clarify the sparsity level.
- [Experiments] Figure captions for the real-world experiments should explicitly state the number of trials per task and any failure modes observed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve reproducibility and detail where the points are valid.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported success rates (86.9% LIBERO-10, 73.4% Meta-World-5, 72.5% sim-to-real) and ablation claims are presented without implementation equations, training details, error bars, number of runs, or dataset statistics, rendering the central performance claims unverifiable from the supplied information.
Authors: We agree the abstract would benefit from greater self-containment. In revision we will add error bars, number of evaluation runs, and brief training/dataset statistics to the abstract (or a footnote) while retaining the high-level claims; implementation equations remain in the method section but will be explicitly referenced. revision: yes
-
Referee: [Method] Method section (presumed §3): the masked action-alignment objective is described at a high level but the precise loss formulation, masking strategy, and how action tokens are paired with observations are not supplied, which is load-bearing for reproducing the claimed geometric supervision effect.
Authors: The comment is correct; the current description is high-level. We will expand the method section with the exact loss equation, the token masking ratio and schedule, and the precise pairing procedure between action tokens and sparse 3D observations to enable full reproduction. revision: yes
-
Referee: [Experiments] Experiments (§4): the ablation attributing gains specifically to the action-alignment signal (rather than decoder capacity) lacks the quantitative breakdown or controls needed to confirm that the downstream policy architecture independence holds across the tested action spaces.
Authors: We accept that additional quantitative controls are needed. The revised experiments section will include expanded ablation tables that report success rates for multiple downstream action parameterizations (joint vs. task space) and decoder capacities, with explicit controls isolating the pretraining signal. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central contribution is an empirical pretraining framework (masked action-alignment on sparse 3D tokens using end-effector actions) whose downstream utility is demonstrated via reported success rates on LIBERO-10, Meta-World transfer, ablations, and sim-to-real experiments. No equations, fitted parameters, or predictions are presented that reduce by construction to the training inputs; the claimed reusability across policy architectures follows from the stated separation of encoder pretraining from downstream fine-tuning rather than from any self-definitional or self-citation reduction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Y . Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu. 3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations. InRobotics: Science and Systems XX, volume 20, July 2024. ISBN 979-8-9902848-0-7
2024
-
[2]
S. Chen, R. G. Pinel, C. Schmid, and I. Laptev. PolarNet: 3D Point Clouds for Language- Guided Robotic Manipulation. InProceedings of The 7th Conference on Robot Learning, pages 1761–1781. PMLR, Dec. 2023
2023
-
[3]
Shridhar, L
M. Shridhar, L. Manuelli, and D. Fox. Perceiver-Actor: A Multi-Task Transformer for Robotic Manipulation. InProceedings of The 6th Conference on Robot Learning, pages 785–799. PMLR, Mar. 2023
2023
-
[4]
C. Wang, H. Fang, H.-S. Fang, and C. Lu. RISE: 3D Perception Makes Real-World Robot Imitation Simple and Effective. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2870–2877, Abu Dhabi, United Arab Emirates, Oct. 2024. IEEE. ISBN 979-8-3503-7770-5. doi:10.1109/IROS58592.2024.10801678
-
[5]
Gervet, Z
T. Gervet, Z. Xian, N. Gkanatsios, and K. Fragkiadaki. Act3D: 3D Feature Field Transform- ers for Multi-Task Robotic Manipulation. InProceedings of The 7th Conference on Robot Learning, volume 229, pages 3949–3965. PMLR, 2023
2023
-
[6]
T.-W. Ke, N. Gkanatsios, and K. Fragkiadaki. 3D Diffuser Actor: Policy Diffusion with 3D Scene Representations. InProceedings of The 8th Conference on Robot Learning, pages 1949–
1949
-
[7]
S. Nair, A. Rajeswaran, V . Kumar, C. Finn, and A. Gupta. R3M: A Universal Visual Repre- sentation for Robot Manipulation. InProceedings of The 6th Conference on Robot Learning, pages 892–909. PMLR, Mar. 2023
2023
-
[8]
Y . J. Ma, S. Sodhani, D. Jayaraman, O. Bastani, V . Kumar, and A. Zhang. VIP: Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[9]
Radosavovic, T
I. Radosavovic, T. Xiao, S. James, P. Abbeel, J. Malik, and T. Darrell. Real-World Robot Learning with Masked Visual Pre-training. InProceedings of The 6th Conference on Robot Learning, pages 416–426. PMLR, Mar. 2023
2023
-
[10]
Radosavovic, B
I. Radosavovic, B. Shi, L. Fu, K. Goldberg, T. Darrell, and J. Malik. Robot Learning with Sensorimotor Pre-training. InProceedings of The 7th Conference on Robot Learning, pages 683–693. PMLR, Dec. 2023
2023
-
[11]
S. Qian, K. Mo, V . Blukis, D. F. Fouhey, D. Fox, and A. Goyal. 3D-MVP: 3D Multiview Pretraining for Manipulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22530–22539, 2025
2025
-
[12]
X. Yu, L. Tang, Y . Rao, T. Huang, J. Zhou, and J. Lu. Point-BERT: Pre-Training 3D Point Cloud Transformers With Masked Point Modeling. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 19313–19322, 2022
2022
-
[13]
Y . Pang, W. Wang, F. E. H. Tay, W. Liu, Y . Tian, and L. Yuan. Masked Autoencoders for Point Cloud Self-supervised Learning. In S. Avidan, G. Brostow, M. Ciss ´e, G. M. Farinella, and T. Hassner, editors,Computer Vision – ECCV 2022, pages 604–621, Cham, 2022. Springer Nature Switzerland. ISBN 978-3-031-20086-1. doi:10.1007/978-3-031-20086-1 35
-
[14]
Z. J. Cui, H. Pan, A. Iyer, S. Haldar, and L. Pinto. DynaMo: In-Domain Dynamics Pretraining for Visuo-Motor Control.Advances in Neural Information Processing Systems, 37:33933– 33961, Dec. 2024. doi:10.52202/079017-1069. 9
-
[15]
C. Hou, Y . Ze, Y . Fu, Z. Gao, S. Hu, Y . Yu, S. Zhang, and H. Xu. 4D Visual Pre-training for Robot Learning. InIEEE/CVF International Conference on Computer Vision, 2025
2025
-
[16]
Liang, B
Q. Liang, B. Cai, M. Lai, S. Zhuang, T. Lin, Y . Qin, Y . Ye, J. Liang, and R. Xu. Bootstrap Dynamic-Aware 3D Visual Representation for Scalable Robot Learning, Dec. 2025
2025
-
[17]
T. Yuan, Z. Dong, Y . Liu, and H. Zhao. Fast-W AM: Do World Action Models Need Test-time Future Imagination?, Mar. 2026
2026
-
[18]
Huang, Y .-W
W. Huang, Y .-W. Chao, A. Mousavian, M.-Y . Liu, D. Fox, K. Mo, and L. Fei-Fei. PointWorld: Scaling 3D World Models for In-The-Wild Robotic Manipulation, Jan. 2026
2026
-
[19]
S. Chen, R. Garcia, I. Laptev, and C. Schmid. SUGAR : Pre-training 3D Visual Representations for Robotics. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18049–18060, Seattle, W A, USA, June 2024. IEEE. ISBN 979-8-3503-5300-
2024
-
[20]
doi:10.1109/CVPR52733.2024.01709
-
[21]
H. Zhu, H. Yang, Y . Wang, J. Yang, L. Wang, and T. He. SPA: 3D Spatial-Awareness Enables Effective Embodied Representation. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[22]
I.-C. A. Liu, K. Choromanski, S. Huang, and C. Schenck. CLAMP: Contrastive Learning for 3D Multi-View Action-Conditioned Robotic Manipulation Pretraining, Jan. 2026
2026
-
[23]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, T. Jackson, S. Jesmonth, N. Joshi, R. Ju- lian, D. Kalashnikov, Y . Kuang, I. Leal, K.-H. Lee, S. Levine, Y . Lu, U. Malla, D. Manjunath, I. Mordatch, O. Nachum, C. Parada, J. Peralta, E. Perez, K. Pertsch, ...
2023
-
[24]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. C. Burchfiel, and S. Song. Diffusion Policy: Visuomotor Policy Learning via Action Diffusion. InRobotics: Science and Systems XIX, volume 19, July 2023. ISBN 978-0-9923747-9-2
2023
-
[25]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An Open-Source Vision-Language-Action Model. InProceedings of The 8th Conference on Robot Learning, volume 270, pages 2679–2713. PMLR, 2025
2025
-
[26]
ten Pas, M
A. ten Pas, M. Gualtieri, K. Saenko, and R. Platt. Grasp Pose Detection in Point Clouds. The International Journal of Robotics Research, 36(13–14):1455–1473, 2017. doi:10.1177/ 0278364917735594
2017
-
[27]
Liang, X
H. Liang, X. Ma, S. Li, M. G ¨orner, S. Tang, B. Fang, F. Sun, and J. Zhang. PointNetGPD: De- tecting Grasp Configurations from Point Sets. InIEEE International Conference on Robotics and Automation, 2019
2019
-
[28]
H.-S. Fang, C. Wang, M. Gou, and C. Lu. GraspNet-1Billion: A Large-Scale Benchmark for General Object Grasping. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11444–11453, 2020
2020
-
[29]
Sundermeyer, A
M. Sundermeyer, A. Mousavian, R. Triebel, and D. Fox. Contact-graspnet: Efficient 6-dof grasp generation in cluttered scenes. In2021 IEEE international conference on robotics and automation (ICRA), pages 13438–13444. IEEE, 2021. 10
2021
-
[30]
K. Mo, L. J. Guibas, M. Mukadam, A. Gupta, and S. Tulsiani. Where2act: From pixels to actions for articulated 3d objects. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6813–6823, 2021
2021
-
[31]
Eisner, H
B. Eisner, H. Zhang, and D. Held. FlowBot3D: Learning 3D Articulation Flow to Manipulate Articulated Objects. InRobotics: Science and Systems, 2022
2022
-
[32]
Y . Zhu, Z. Jiang, P. Stone, and Y . Zhu. Learning Generalizable Manipulation Policies with Object-Centric 3D Representations. InProceedings of The 7th Conference on Robot Learning, volume 229, pages 3418–3433. PMLR, 2023
2023
- [33]
-
[34]
C. Bao, H. Xu, Y . Qin, and X. Wang. DexArt: Benchmarking Generalizable Dexterous Manip- ulation with Articulated Objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21190–21200, 2023
2023
-
[35]
Y . Xu, W. Wan, J. Zhang, H. Liu, Z. Shan, H. Shen, R. Wang, H. Geng, Y . Weng, J. Chen, T. Liu, L. Yi, and H. Wang. UniDexGrasp: Universal Robotic Dexterous Grasping via Learning Diverse Proposal Generation and Goal-Conditioned Policy. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4737–4746, 2023
2023
-
[36]
Y . Qin, B. Huang, Z.-H. Yin, H. Su, and X. Wang. DexPoint: Generalizable Point Cloud Reinforcement Learning for Sim-to-Real Dexterous Manipulation. InProceedings of The 6th Conference on Robot Learning, volume 205, pages 594–605. PMLR, 2023
2023
-
[37]
C. Yu, S. Ma, W. Du, Z. Zong, H. Xue, W. Chen, C. Lu, Y . Yang, X. Han, J. Master- john, et al. Right-side-out: Learning zero-shot sim-to-real garment reversal.arXiv preprint arXiv:2509.15953, 2025
arXiv 2025
-
[38]
Seita, Y
D. Seita, Y . Wang, S. J. Shetty, E. Y . Li, Z. Erickson, and D. Held. ToolFlowNet: Robotic Manipulation with Tools via Predicting Tool Flow from Point Clouds. InProceedings of The 6th Conference on Robot Learning, pages 1038–1049. PMLR, Mar. 2023
2023
-
[39]
C. Wen, X. Lin, J. I. R. So, K. Chen, Q. Dou, Y . Gao, and P. Abbeel. Any-point Trajectory Modeling for Policy Learning. InRobotics: Science and Systems XX, volume 20, July 2024. ISBN 979-8-9902848-0-7
2024
-
[40]
Goyal, J
A. Goyal, J. Xu, Y . Guo, V . Blukis, Y .-W. Chao, and D. Fox. RVT: Robotic View Transformer for 3D Object Manipulation. InProceedings of The 7th Conference on Robot Learning, pages 694–710. PMLR, Dec. 2023
2023
-
[41]
Haldar, L
S. Haldar, L. Johannsmeier, L. Pinto, A. Gupta, D. Fox, Y . Narang, and A. Mandlekar. Point Bridge: 3D Representations for Cross Domain Policy Learning, Mar. 2026
2026
-
[42]
R. Yang, G. Chen, C. Wen, and Y . Gao. FP3: A 3D Foundation Policy for Robotic Manipula- tion, Mar. 2025
2025
-
[43]
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, Y . Ding, Z. Wang, J. Gu, B. Zhao, D. Wang, and X. Li. SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model, May 2025
2025
-
[44]
C. Li, J. Wen, Y . Peng, Y . Peng, and Y . Zhu. PointVLA: Injecting the 3D World Into Vision- Language-Action Models.IEEE Robotics and Automation Letters, 11(3):2506–2513, Mar
-
[45]
Pointvla: Injecting the 3d world into vision-language-action models
ISSN 2377-3766. doi:10.1109/LRA.2026.3653303
-
[46]
Jiang, Y
G. Jiang, Y . Sun, T. Huang, H. Li, Y . Liang, and H. Xu. Robots Pre-train Robots: Manipulation- Centric Robotic Representation from Large-Scale Robot Datasets. InThe Thirteenth Interna- tional Conference on Learning Representations, 2025. 11
2025
-
[47]
S. Li, Y . Gao, D. Sadigh, and S. Song. Unified Video Action Model. InRobotics: Science and Systems XXI, volume 21, June 2025. ISBN 979-8-9902848-1-4
2025
-
[48]
C. Zhu, R. Yu, S. Feng, B. Burchfiel, P. Shah, and A. Gupta. Unified World Models: Coupling Video and Action Diffusion for Pretraining on Large Robotic Datasets. InRobotics: Science and Systems XXI, volume 21, June 2025. ISBN 979-8-9902848-1-4
2025
-
[49]
Y . Feng, J. Zheng, Z. Wang, D. Liu, J. Li, J. Pang, T. Wang, and X. Zhan. Demystifying action space design for robotic manipulation policies, 2026
2026
-
[50]
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, and Y . Liu. RoFormer: Enhanced transformer with Rotary Position Embedding.Neurocomputing, 568:127063, Feb. 2024. ISSN 0925-2312. doi: 10.1016/j.neucom.2023.127063
-
[51]
K. He, X. Chen, S. Xie, Y . Li, P. Doll´ar, and R. Girshick. Masked Autoencoders Are Scalable Vision Learners. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16000–16009, 2022
2022
-
[52]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning.Advances in Neural Information Processing Systems, 36:44776–44791, Dec. 2023
2023
-
[53]
T. Yu, D. Quillen, Z. He, R. Julian, K. Hausman, C. Finn, and S. Levine. Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning. InProceedings of the Conference on Robot Learning, pages 1094–1100. PMLR, May 2020
2020
-
[54]
Black, N
K. Black, N. Brown, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, L. Smith, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky. π0: A Vision-Language-Action Flow Model for General Robot Control. InRobotics: ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.