FLAT: Feedforward Latent Triangle Splatting for Geometrically Accurate Scene Generation
Pith reviewed 2026-06-26 00:09 UTC · model grok-4.3
The pith
Video diffusion latents can be decoded directly into oriented triangle splats for 3D scenes with improved geometry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
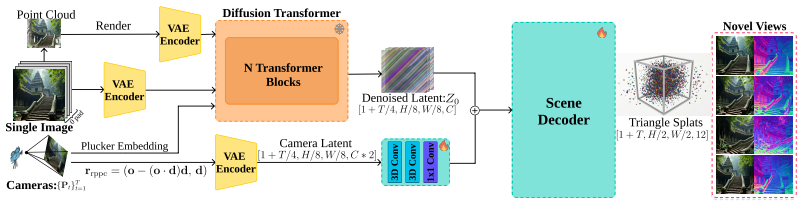
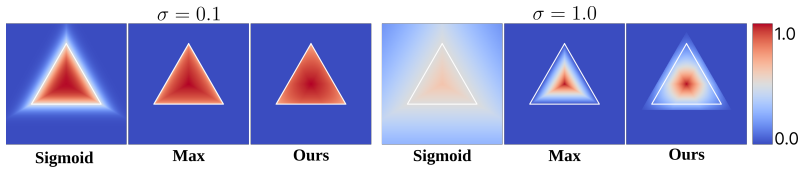
Triangle splats can be decoded directly from video diffusion latents for the first time. A ray-centered rotation parameterization handles the high sensitivity of flat primitive orientations, while a novel product window function improves gradient flow during differentiable triangle rendering. When trained under the same conditions as 3DGS and 2DGS variants, the resulting scenes show significantly better geometric accuracy with competitive visual quality, and a lightweight refinement converts the triangle soup into fully opaque assets.
What carries the argument
Ray-centered rotation parameterization for triangle orientation regression, combined with a product window function for stable differentiable rendering of flat primitives.
If this is right
- Feedforward single-image scene generation produces outputs with measurably higher geometric accuracy than Gaussian splatting baselines.
- Surface-aligned triangle primitives integrate more directly into standard graphics pipelines and simulation tools than volumetric representations.
- A lightweight test-time refinement converts the predicted triangles into opaque meshes that support real-time rendering.
- Systematic comparison under identical training reveals concrete tradeoffs among 3DGS, 2DGS, and triangle splatting representations.
Where Pith is reading between the lines
- The approach could extend to other latent diffusion backbones if their latents prove similarly rich in geometric cues.
- Surface primitives may simplify downstream tasks such as collision detection or texture baking that currently require extra post-processing of Gaussian outputs.
- Testing whether the same parameterization works when the input is a short video clip rather than a single image would clarify how much multi-view information the latents must contain.
Load-bearing premise
The compressed latents of existing video diffusion models already encode sufficient explicit multi-view geometric structure to support direct regression of oriented triangle primitives without additional geometric supervision or iterative refinement during training.
What would settle it
An ablation that trains the identical decoder architecture on the same latents but outputs 3D Gaussians instead of triangles and measures no geometric accuracy improvement, or removal of the rotation parameterization that causes training to fail to converge on flat primitives.
Figures










read the original abstract
Generating explorable 3D scenes from a single image requires strong generative priors and accurate geometric representations suitable for downstream use. Current video diffusion models offer high-quality generation and implicitly encode multi-view geometric structure in latent space. However, existing feedforward latent scene decoders typically output volumetric 3D Gaussians that lack a well-defined surface, limiting their use in simulation or standard graphics pipelines. This motivates decoding surface-aligned primitives that are not only renderable but also closer to explicit geometric assets. We ask whether compressed video diffusion latents can be mapped directly to explicit surface primitives in a single pass. To this end, we introduce FLAT and, for the first time, show that triangle splats can be decoded directly from video diffusion latents. Compared with decoding 3D Gaussians, predicting flat primitives is notoriously more challenging due to high sensitivity to primitive orientations, oftentimes leading to poor gradient flow. FLAT solves with two key ingredients: a ray-centered rotation parameterization for triangle regression and a novel product window function that improves gradient flow during differentiable triangle rendering. On standard benchmarks, FLAT achieves significantly better geometric accuracy while maintaining competitive visual quality compared to state-of-the-art feedforward baselines. We further show that a lightweight test-time refinement step converts the predicted triangle soup into a fully opaque, game-engine-ready representation that supports real-time rendering. By evaluating 3DGS, 2DGS, and triangle splatting variants under an identical training setup, we provide the first systematic analysis of representation tradeoffs in feedforward scene generation. The project page is available at https://flat-splat.github.io
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FLAT, a feedforward decoder that maps compressed latents from video diffusion models directly to oriented triangle splats for single-image 3D scene generation. It proposes a ray-centered rotation parameterization and a product window function to mitigate poor gradient flow when regressing flat primitives, claims significantly improved geometric accuracy over 3D/2D Gaussian baselines under identical training, and adds a lightweight test-time refinement step to produce opaque, real-time renderable assets. A systematic comparison of representation tradeoffs (3DGS, 2DGS, triangle splatting) is also presented.
Significance. If the geometric accuracy gains are substantiated by the experiments, the work would advance feedforward scene generation by shifting from volumetric to surface-aligned primitives that are closer to explicit assets usable in simulation and graphics pipelines. The identical-training-setup comparison of representations is a clear strength that enables fair tradeoff analysis.
major comments (2)
- [Abstract] Abstract and § on method: The claim that existing video diffusion latents already embed sufficient explicit multi-view geometric structure for single-pass oriented-triangle regression is load-bearing for the 'direct decoding' premise, yet the provided text gives no direct measurement (e.g., latent-to-geometry probe accuracy or ablation that removes geometric cues from the diffusion prior). Decoder-side fixes alone cannot supply absent information.
- [Abstract] Abstract: The statement that triangle splats achieve 'significantly better geometric accuracy' while remaining competitive in visual quality requires the quantitative tables and error analysis that are referenced but not visible in the supplied text; without those numbers the central empirical claim cannot be evaluated.
minor comments (1)
- The project page URL is given but the abstract contains no numerical results, benchmark names, or ablation tables, making it difficult to assess the scale of the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below, with planned revisions where the concerns are valid.
read point-by-point responses
-
Referee: [Abstract] Abstract and § on method: The claim that existing video diffusion latents already embed sufficient explicit multi-view geometric structure for single-pass oriented-triangle regression is load-bearing for the 'direct decoding' premise, yet the provided text gives no direct measurement (e.g., latent-to-geometry probe accuracy or ablation that removes geometric cues from the diffusion prior). Decoder-side fixes alone cannot supply absent information.
Authors: We agree that a direct probe or ablation isolating the geometric content of the latents would provide stronger support for the premise. The current evidence is indirect via the decoder's superior geometric metrics relative to Gaussian baselines under identical training. We will add a linear probe experiment on the latents for depth/normal prediction and a control ablation using a non-geometric encoder in the revised Section 4 to quantify the prior's contribution. revision: yes
-
Referee: [Abstract] Abstract: The statement that triangle splats achieve 'significantly better geometric accuracy' while remaining competitive in visual quality requires the quantitative tables and error analysis that are referenced but not visible in the supplied text; without those numbers the central empirical claim cannot be evaluated.
Authors: The supporting numbers appear in the full manuscript's Tables 1–3 and Figures 4–6 (Section 4), which report depth error, normal consistency, PSNR/SSIM/LPIPS, and error distributions for all representations under matched training. We will revise the abstract to include one or two key quantitative deltas and ensure explicit table references appear in the method and results sections. revision: partial
Circularity Check
No circularity: novel decoder components and empirical comparisons are independent of inputs
full rationale
The paper's core contribution consists of two explicitly introduced decoder innovations (ray-centered rotation parameterization and product window function) that address gradient issues in triangle regression from external video diffusion latents. These are not derived from or equivalent to the target outputs by construction, nor do any equations reduce fitted parameters to predictions. The evaluation compares representations under identical training setups using external priors, with no load-bearing self-citations or ansatzes imported from prior author work. The assumption that latents contain usable geometry is tested empirically rather than presupposed definitionally, making the derivation chain self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Onestory: Coherent multi-shot video generation with adaptive memory
Zhaochong An, Menglin Jia, Haonan Qiu, Zijian Zhou, Xiaoke Huang, Zhiheng Liu, Weiming Ren, Kumara Kahatapitiya, Ding Liu, Sen He, et al. Onestory: Coherent multi-shot video generation with adaptive memory. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16173–16184, 2026
2026
-
[2]
Zhaochong An, Orest Kupyn, Théo Uscidda, Andrea Colaco, Karan Ahuja, Serge Belongie, Mar Gonzalez-Franco, and Marta Tintore Gazulla. Vggrpo: Towards world-consistent video generation with 4d latent reward.arXiv preprint arXiv:2603.26599, 2026
arXiv 2026
-
[3]
Lindell, Zan Gojcic, Sanja Fidler, Huan Ling, Jun Gao, and Xu- anchi Ren
Sherwin Bahmani, Tianchang Shen, Jiawei Ren, Jiahui Huang, Yifeng Jiang, Haithem Turki, Andrea Tagliasacchi, David B. Lindell, Zan Gojcic, Sanja Fidler, Huan Ling, Jun Gao, and Xu- anchi Ren. Lyra: Generative 3d scene reconstruction via video diffusion model self-distillation. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[4]
Normalcrafter: Learning temporally consistent normals from video diffusion priors
Yanrui Bin, Wenbo Hu, Haoyuan Wang, Xinya Chen, and Bing Wang. Normalcrafter: Learning temporally consistent normals from video diffusion priors. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8330–8339, 2025
2025
-
[5]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InForty-first International Conference on Machine Learning, 2024
2024
-
[6]
Baking gaussian splatting into diffusion denoiser for fast and scalable single-stage image-to-3d generation and reconstruction
Yuanhao Cai, He Zhang, Kai Zhang, Yixun Liang, Mengwei Ren, Fujun Luan, Qing Liu, Soo Ye Kim, Jianming Zhang, Zhifei Zhang, et al. Baking gaussian splatting into diffusion denoiser for fast and scalable single-stage image-to-3d generation and reconstruction. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 25062–25072, 2025
2025
-
[7]
Uni3c: Unifying precisely 3d-enhanced camera and human motion controls for video generation
Chenjie Cao, Jingkai Zhou, Shikai Li, Jingyun Liang, Chaohui Yu, Fan Wang, Xiangyang Xue, and Yanwei Fu. Uni3c: Unifying precisely 3d-enhanced camera and human motion controls for video generation. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–12, 2025
2025
-
[8]
pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction
David Charatan, Sizhe Lester Li, Andrea Tagliasacchi, and Vincent Sitzmann. pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19457–19467, 2024
2024
-
[9]
Beyond gaussians: Fast and high-fidelity 3d splatting with linear kernels
Haodong Chen, Runnan Chen, Qiang Qu, Zhaoqing Wang, Tongliang Liu, Xiaoming Chen, and Yuk Ying Chung. Beyond gaussians: Fast and high-fidelity 3d splatting with linear kernels. arXiv preprint arXiv:2411.12440, 2024. 10
arXiv 2024
-
[10]
Learning to predict 3d objects with an interpolation-based differentiable renderer
Wenzheng Chen, Huan Ling, Jun Gao, Edward Smith, Jaakko Lehtinen, Alec Jacobson, and Sanja Fidler. Learning to predict 3d objects with an interpolation-based differentiable renderer. Advances in neural information processing systems, 32, 2019
2019
-
[11]
Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images
Yuedong Chen, Haofei Xu, Chuanxia Zheng, Bohan Zhuang, Marc Pollefeys, Andreas Geiger, Tat-Jen Cham, and Jianfei Cai. Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images. InEuropean conference on computer vision, pages 370–386. Springer, 2024
2024
-
[12]
Wan-move: Motion-controllable video generation via latent trajectory guidance.Advances in Neural Information Processing Systems, 38:404–432, 2026
Ruihang Chu, Yefei He, Zhekai Chen, Shiwei Zhang, Xiaogang Xu, Dingdong W ANG, Hong- wei Yi, Xihui Liu, Hengshuang Zhao, Yu Liu, et al. Wan-move: Motion-controllable video generation via latent trajectory guidance.Advances in Neural Information Processing Systems, 38:404–432, 2026
2026
-
[13]
Justin Cui, Jie Wu, Ming Li, Tao Yang, Xiaojie Li, Rui Wang, Andrew Bai, Yuanhao Ban, and Cho-Jui Hsieh. Self-forcing++: Towards minute-scale high-quality video generation.arXiv preprint arXiv:2510.02283, 2025
Pith/arXiv arXiv 2025
-
[14]
Cvxnet: Learnable convex decomposition
Boyang Deng, Kyle Genova, Soroosh Yazdani, Sofien Bouaziz, Geoffrey Hinton, and Andrea Tagliasacchi. Cvxnet: Learnable convex decomposition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 31–44, 2020
2020
-
[15]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
Pith/arXiv arXiv 2010
-
[16]
Hongyang Du, Junjie Ye, Xiaoyan Cong, Runhao Li, Jingcheng Ni, Aman Agarwal, Zeqi Zhou, Zekun Li, Randall Balestriero, and Yue Wang. Videogpa: Distilling geometry priors for 3d-consistent video generation.arXiv preprint arXiv:2601.23286, 2026
Pith/arXiv arXiv 2026
-
[17]
Cat3d: Create anything in 3d with multi-view diffusion models.arXiv preprint arXiv:2405.10314, 2024
Ruiqi Gao, Aleksander Holynski, Philipp Henzler, Arthur Brussee, Ricardo Martin-Brualla, Pratul Srinivasan, Jonathan T Barron, and Ben Poole. Cat3d: Create anything in 3d with multi-view diffusion models.arXiv preprint arXiv:2405.10314, 2024
Pith/arXiv arXiv 2024
-
[18]
Shenyuan Gao, William Liang, Kaiyuan Zheng, Ayaan Malik, Seonghyeon Ye, Sihyun Yu, Wei-Cheng Tseng, Yuzhu Dong, Kaichun Mo, Chen-Hsuan Lin, et al. Dreamdojo: A generalist robot world model from large-scale human videos.arXiv preprint arXiv:2602.06949, 2026
Pith/arXiv arXiv 2026
-
[19]
Radiant foam: Real-time differentiable ray tracing
Shrisudhan Govindarajan, Daniel Rebain, Kwang Moo Yi, and Andrea Tagliasacchi. Radiant foam: Real-time differentiable ray tracing. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4135–4145, 2025
2025
-
[20]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2023
Pith/arXiv arXiv 2023
-
[21]
Yuchao Gu, Guian Fang, Yuxin Jiang, Weijia Mao, Song Han, Han Cai, and Mike Zheng Shou. Anyflow: Any-step video diffusion model with on-policy flow map distillation.arXiv preprint arXiv:2605.13724, 2026
Pith/arXiv arXiv 2026
-
[22]
Milo: Mesh-in-the-loop gaussian splatting for detailed and efficient surface reconstruction.ACM Transactions on Graphics (TOG), 44(6):1–15, 2025
Antoine Guédon, Diego Gomez, Nissim Maruani, Bingchen Gong, George Drettakis, and Maks Ovsjanikov. Milo: Mesh-in-the-loop gaussian splatting for detailed and efficient surface reconstruction.ACM Transactions on Graphics (TOG), 44(6):1–15, 2025
2025
-
[23]
Ges: Generalized exponential splatting for efficient radiance field rendering
Abdullah Hamdi, Luke Melas-Kyriazi, Jinjie Mai, Guocheng Qian, Ruoshi Liu, Carl V ondrick, Bernard Ghanem, and Andrea Vedaldi. Ges: Generalized exponential splatting for efficient radiance field rendering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19812–19822, 2024
2024
-
[24]
Meshsplatting: Differentiable rendering with opaque meshes.arXiv preprint arXiv:2512.06818, 2025
Jan Held, Sanghyun Son, Renaud Vandeghen, Daniel Rebain, Matheus Gadelha, Yi Zhou, An- thony Cioppa, Ming C Lin, Marc Van Droogenbroeck, and Andrea Tagliasacchi. Meshsplatting: Differentiable rendering with opaque meshes.arXiv preprint arXiv:2512.06818, 2025. 11
arXiv 2025
-
[25]
Triangle splatting for real-time radiance field rendering
Jan Held, Renaud Vandeghen, Adrien Deliege, Abdullah Hamdi, Daniel Rebain, Silvio Giancola, Anthony Cioppa, Andrea Vedaldi, Bernard Ghanem, Andrea Tagliasacchi, et al. Triangle splatting for real-time radiance field rendering. InThirteenth International Conference on 3D Vision, 2025
2025
-
[26]
3d convex splatting: Radiance field rendering with 3d smooth convexes
Jan Held, Renaud Vandeghen, Abdullah Hamdi, Adrien Deliege, Anthony Cioppa, Silvio Giancola, Andrea Vedaldi, Bernard Ghanem, and Marc Van Droogenbroeck. 3d convex splatting: Radiance field rendering with 3d smooth convexes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21360–21369, 2025
2025
-
[27]
Mu Hu, Wei Yin, Chi Zhang, Zhipeng Cai, Xiaoxiao Long, Hao Chen, Kaixuan Wang, Gang Yu, Chunhua Shen, and Shaojie Shen. Metric3d v2: A versatile monocular geometric foundation model for zero-shot metric depth and surface normal estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[28]
2d gaussian splatting for geometrically accurate radiance fields
Binbin Huang, Zehao Yu, Anpei Chen, Andreas Geiger, and Shenghua Gao. 2d gaussian splatting for geometrically accurate radiance fields. InACM SIGGRAPH 2024 conference papers, pages 1–11, 2024
2024
-
[29]
Self forcing: Bridging the train-test gap in autoregressive video diffusion.Advances in Neural Information Processing Systems, 38:167283–167308, 2026
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.Advances in Neural Information Processing Systems, 38:167283–167308, 2026
2026
-
[30]
Deformable radial kernel splatting
Yi-Hua Huang, Ming-Xian Lin, Yang-Tian Sun, Ziyi Yang, Xiaoyang Lyu, Yan-Pei Cao, and Xiaojuan Qi. Deformable radial kernel splatting. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21513–21523, 2025
2025
-
[31]
Lvsm: A large view synthesis model with minimal 3d inductive bias
Haian Jin, Hanwen Jiang, Hao Tan, Kai Zhang, Sai Bi, Tianyuan Zhang, Fujun Luan, Noah Snavely, and Zexiang Xu. Lvsm: A large view synthesis model with minimal 3d inductive bias. arXiv preprint arXiv:2410.17242, 2024
arXiv 2024
-
[32]
Mapanything: Universal feed-forward metric 3d reconstruction.arXiv preprint arXiv:2509.13414, 2025
Nikhil Keetha, Norman Müller, Johannes Schönberger, Lorenzo Porzi, Yuchen Zhang, Tobias Fischer, Arno Knapitsch, Duncan Zauss, Ethan Weber, Nelson Antunes, et al. Mapanything: Universal feed-forward metric 3d reconstruction.arXiv preprint arXiv:2509.13414, 2025
Pith/arXiv arXiv 2025
-
[33]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023
2023
-
[34]
Neuralfield-ldm: Scene generation with hierarchical latent diffusion models
Seung Wook Kim, Bradley Brown, Kangxue Yin, Karsten Kreis, Katja Schwarz, Daiqing Li, Robin Rombach, Antonio Torralba, and Sanja Fidler. Neuralfield-ldm: Scene generation with hierarchical latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8496–8506, 2023
2023
-
[35]
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
Pith/arXiv arXiv 2024
-
[36]
Epipolar geometry improves video generation models.arXiv preprint arXiv:2510.21615, 2025
Orest Kupyn, Fabian Manhardt, Federico Tombari, and Christian Rupprecht. Epipolar geometry improves video generation models.arXiv preprint arXiv:2510.21615, 2025
Pith/arXiv arXiv 2025
-
[37]
S3od: Towards generalizable salient object detection with synthetic data
Orest Kupyn, Hirokatsu Kataoka, and Christian Rupprecht. S3od: Towards generalizable salient object detection with synthetic data. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[38]
Wonderland: Navigating 3d scenes from a single image
Hanwen Liang, Junli Cao, Vidit Goel, Guocheng Qian, Sergei Korolev, Demetri Terzopoulos, Konstantinos N Plataniotis, Sergey Tulyakov, and Jian Ren. Wonderland: Navigating 3d scenes from a single image. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 798–810, 2025
2025
-
[39]
Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025. 12
Pith/arXiv arXiv 2025
-
[40]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22160–22169, 2024
2024
-
[41]
Zero-1-to-3: Zero-shot one image to 3d object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl V ondrick. Zero-1-to-3: Zero-shot one image to 3d object. InProceedings of the IEEE/CVF international conference on computer vision, pages 9298–9309, 2023
2023
-
[42]
Soft rasterizer: A differentiable renderer for image-based 3d reasoning
Shichen Liu, Tianye Li, Weikai Chen, and Hao Li. Soft rasterizer: A differentiable renderer for image-based 3d reasoning. InProceedings of the IEEE/CVF international conference on computer vision, pages 7708–7717, 2019
2019
-
[43]
Dreamdrive: Generative 4d scene modeling from street view images
Jiageng Mao, Boyi Li, Boris Ivanovic, Yuxiao Chen, Yan Wang, Yurong You, Chaowei Xiao, Danfei Xu, Marco Pavone, and Yue Wang. Dreamdrive: Generative 4d scene modeling from street view images. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 367–374. IEEE, 2025
2025
-
[44]
Xiaofeng Mao, Zhen Li, Chuanhao Li, Xiaojie Xu, Kaining Ying, and Kaipeng Zhang. Yume1. 5: A text-controlled interactive world generation model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7752–7761, 2026
2026
-
[45]
Nerf: Representing scenes as neural radiance fields for view synthesis
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoor- thi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1):99–106, 2021
2021
-
[46]
Video generation models as world simulators, 2024
OpenAI. Video generation models as world simulators, 2024. URL https://openai.com/ index/video-generation-models-as-world-simulators/. Accessed: 2024
2024
-
[47]
Movie gen: A cast of media foundation models, 2025
Adam Polyak et al. Movie gen: A cast of media foundation models, 2025. URL https: //arxiv.org/abs/2410.13720
Pith/arXiv arXiv 2025
-
[48]
René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.IEEE transactions on pattern analysis and machine intelligence, 44(3):1623–1637, 2020
2020
-
[49]
Generative gaussian splatting: Generating 3d scenes with video diffusion priors
Katja Schwarz, Norman Mueller, and Peter Kontschieder. Generative gaussian splatting: Generating 3d scenes with video diffusion priors. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 27510–27520, 2025
2025
-
[50]
Lyra 2.0: Explorable generative 3d worlds.arXiv preprint arXiv:2604.13036, 2026
Tianchang Shen, Sherwin Bahmani, Kai He, Sangeetha Grama Srinivasan, Tianshi Cao, Jiawei Ren, Ruilong Li, Zian Wang, Nicholas Sharp, Zan Gojcic, Sanja Fidler, Jiahui Huang, Huan Ling, Jun Gao, and Xuanchi Ren. Lyra 2.0: Explorable generative 3d worlds.arXiv preprint arXiv:2604.13036, 2026
Pith/arXiv arXiv 2026
-
[51]
Mvdream: Multi- view diffusion for 3d generation.arXiv preprint arXiv:2308.16512, 2023
Yichun Shi, Peng Wang, Jianglong Ye, Mai Long, Kejie Li, and Xiao Yang. Mvdream: Multi- view diffusion for 3d generation.arXiv preprint arXiv:2308.16512, 2023
Pith/arXiv arXiv 2023
-
[52]
Splatter image: Ultra-fast single-view 3d reconstruction
Stanislaw Szymanowicz, Chrisitian Rupprecht, and Andrea Vedaldi. Splatter image: Ultra-fast single-view 3d reconstruction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10208–10217, 2024
2024
-
[53]
Bolt3d: Generating 3d scenes in seconds
Stanislaw Szymanowicz, Jason Y Zhang, Pratul Srinivasan, Ruiqi Gao, Arthur Brussee, Alek- sander Holynski, Ricardo Martin-Brualla, Jonathan T Barron, and Philipp Henzler. Bolt3d: Generating 3d scenes in seconds. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 24846–24857, 2025
2025
-
[54]
Maria Taktasheva, Lily Goli, Alessandro Fiorini, Zhen Li, Daniel Rebain, and Andrea Tagliasac- chi. 3d gaussian flats: Hybrid 2d/3d photometric scene reconstruction.arXiv preprint arXiv:2509.16423, 2025
arXiv 2025
-
[55]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. 13
Pith/arXiv arXiv 2025
-
[56]
Angtian Wang, Haibin Huang, Jacob Zhiyuan Fang, Yiding Yang, and Chongyang Ma. Ati: Any trajectory instruction for controllable video generation.arXiv preprint arXiv:2505.22944, 2025
arXiv 2025
-
[57]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[58]
Imagedream: Image-prompt multi-view diffusion for 3d generation
Peng Wang and Yichun Shi. Imagedream: Image-prompt multi-view diffusion for 3d generation. arXiv preprint arXiv:2312.02201, 2023
arXiv 2023
-
[59]
Video models are zero-shot learners and reasoners,
Thaddäus Wiedemer, Yuxuan Li, Paul Vicol, Shixiang Shane Gu, Nick Matarese, Kevin Swersky, Been Kim, Priyank Jaini, and Robert Geirhos. Video models are zero-shot learners and reasoners,
-
[60]
URLhttps://arxiv.org/abs/2509.20328
-
[61]
Gs2mesh: Surface reconstruction from gaussian splatting via novel stereo views
Yaniv Wolf, Amit Bracha, and Ron Kimmel. Gs2mesh: Surface reconstruction from gaussian splatting via novel stereo views. InEuropean Conference on Computer Vision, pages 207–224. Springer, 2024
2024
-
[62]
Depthsplat: Connecting gaussian splatting and depth
Haofei Xu, Songyou Peng, Fangjinhua Wang, Hermann Blum, Daniel Barath, Andreas Geiger, and Marc Pollefeys. Depthsplat: Connecting gaussian splatting and depth. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 16453–16463, 2025
2025
-
[63]
Yongzhi Xu, Yonhon Ng, Yifu Wang, Inkyu Sa, Yunfei Duan, Zhenhong Sun, Yang Li, Pan Ji, and Hongdong Li. Sketch2scene: Automatic generation of interactive 3d game scenes from user’s casual sketches.arXiv preprint arXiv:2408.04567, 2024
arXiv 2024
-
[64]
Longlive: Real-time interactive long video generation.arXiv preprint arXiv:2509.22622, 2025
Shuai Yang, Wei Huang, Ruihang Chu, Yicheng Xiao, Yuyang Zhao, Xianbang Wang, Muyang Li, Enze Xie, Yingcong Chen, Yao Lu, et al. Longlive: Real-time interactive long video generation.arXiv preprint arXiv:2509.22622, 2025
Pith/arXiv arXiv 2025
-
[65]
Yu Yang, Alan Liang, Jianbiao Mei, Yukai Ma, Yong Liu, and Gim Hee Lee. X-scene: Large- scale driving scene generation with high fidelity and flexible controllability.arXiv preprint arXiv:2506.13558, 2025
arXiv 2025
-
[66]
Holodeck: Language guided generation of 3d embodied ai environments
Yue Yang, Fan-Yun Sun, Luca Weihs, Eli VanderBilt, Alvaro Herrasti, Winson Han, Jiajun Wu, Nick Haber, Ranjay Krishna, Lingjie Liu, et al. Holodeck: Language guided generation of 3d embodied ai environments. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16227–16237, 2024
2024
-
[67]
Botao Ye, Boqi Chen, Haofei Xu, Daniel Barath, and Marc Pollefeys. Yonosplat: You only need one model for feedforward 3d gaussian splatting.arXiv preprint arXiv:2511.07321, 2025
arXiv 2025
-
[68]
Wangbo Yu, Jinbo Xing, Li Yuan, Wenbo Hu, Xiaoyu Li, Zhipeng Huang, Xiangjun Gao, Tien-Tsin Wong, Ying Shan, and Yonghong Tian. Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis.arXiv preprint arXiv:2409.02048, 2024
Pith/arXiv arXiv 2024
-
[69]
Immersegen: Agent-guided immersive world generation with alpha-textured proxies.IEEE Transactions on Visualization and Computer Graphics, 2026
Jinyan Yuan, Bangbang Yang, Keke Wang, Panwang Pan, Lin Ma, Xuehai Zhang, Xiao Liu, Zhaopeng Cui, and Yuewen Ma. Immersegen: Agent-guided immersive world generation with alpha-textured proxies.IEEE Transactions on Visualization and Computer Graphics, 2026
2026
-
[70]
Helios: Real real-time long video generation model.arXiv preprint arXiv:2603.04379, 2026
Shenghai Yuan, Yuanyang Yin, Zongjian Li, Xinwei Huang, Xiao Yang, and Li Yuan. Helios: Real real-time long video generation model.arXiv preprint arXiv:2603.04379, 2026
arXiv 2026
-
[71]
Gs-lrm: Large reconstruction model for 3d gaussian splatting
Kai Zhang, Sai Bi, Hao Tan, Yuanbo Xiangli, Nanxuan Zhao, Kalyan Sunkavalli, and Zexiang Xu. Gs-lrm: Large reconstruction model for 3d gaussian splatting. InEuropean Conference on Computer Vision, pages 1–19. Springer, 2024
2024
-
[72]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018. 14
2018
-
[73]
Flare: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views
Shangzhan Zhang, Jianyuan Wang, Yinghao Xu, Nan Xue, Christian Rupprecht, Xiaowei Zhou, Yujun Shen, and Gordon Wetzstein. Flare: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21936–21947, 2025
2025
-
[74]
Yisu Zhang, Chenjie Cao, Tengfei Wang, Xuhui Zuo, Junta Wu, Jianke Zhu, and Chunchao Guo. Worldstereo: Bridging camera-guided video generation and scene reconstruction via 3d geometric memories.arXiv preprint arXiv:2603.02049, 2026
arXiv 2026
-
[75]
Guangcong Zheng, Teng Li, Xianpan Zhou, and Xi Li. Realcam-vid: High-resolution video dataset with dynamic scenes and metric-scale camera movements.arXiv preprint arXiv:2504.08212, 2025
arXiv 2025
-
[76]
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnifi- cation: Learning view synthesis using multiplane images.arXiv preprint arXiv:1805.09817, 2018
Pith/arXiv arXiv 2018
-
[77]
Long-lrm: Long-sequence large reconstruction model for wide-coverage gaussian splats
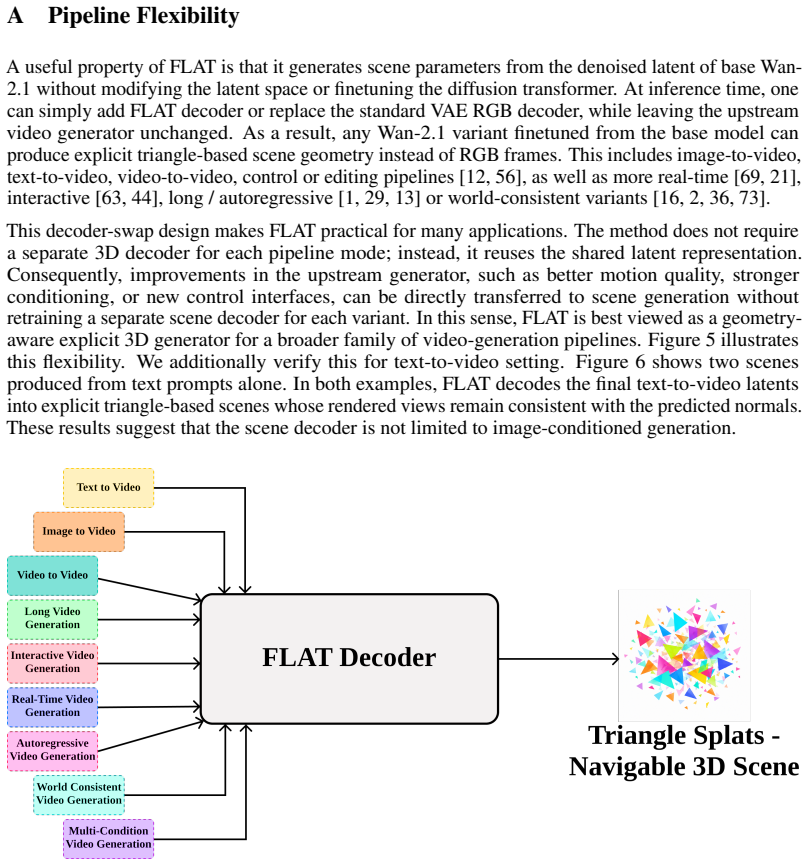
Chen Ziwen, Hao Tan, Kai Zhang, Sai Bi, Fujun Luan, Yicong Hong, Li Fuxin, and Zexiang Xu. Long-lrm: Long-sequence large reconstruction model for wide-coverage gaussian splats. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4349–4359, 2025. 15 A Pipeline Flexibility A useful property of FLAT is that it generates scene pa...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.