TextDS: Parameter-Efficient Representation Alignment for Scene Text Detection under Distribution Shifts
Pith reviewed 2026-06-30 09:37 UTC · model grok-4.3
The pith
TextDS aligns features from visual foundation models to detect scene text under distribution shifts using only 4.9 million trainable parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
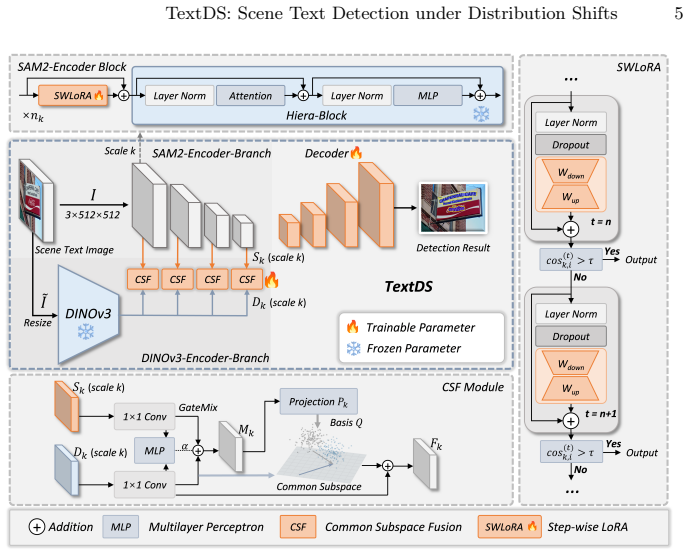
TextDS is a framework that employs a data-efficient dual-encoder design with visual foundation models, applies Step-wise LoRA adaptation (SWLoRA) for progressive refinement with dynamic early-exit, and uses Common Subspace Fusion (CSF) to align the branches while preserving complementary shift-robust information, achieving robustness across domains and adverse conditions.
What carries the argument
Dual-encoder architecture combining visual foundation models with SWLoRA for adaptation and CSF for fusion in a shared subspace.
If this is right
- Detectors can be deployed across varied real-world conditions without large-scale text-specific pretraining.
- Training requires only 4.9 million parameters for effective adaptation.
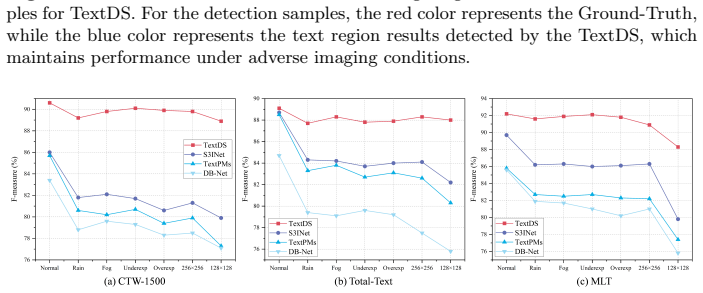
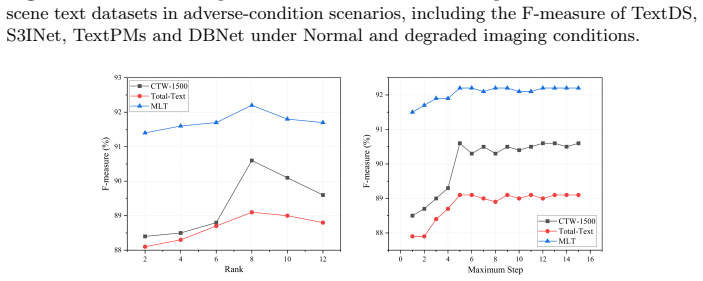
- Evaluation on newly constructed adverse-condition datasets shows maintained performance under imaging degradations.
- Feature alignment in a common subspace retains information that single-branch approaches might lose.
Where Pith is reading between the lines
- Similar alignment techniques could apply to other detection tasks facing domain shifts, such as object detection in medical imaging.
- The dynamic early-exit in SWLoRA suggests potential for variable compute during inference depending on input difficulty.
- By avoiding full pretraining, this approach might lower the barrier for adapting to new languages or scripts in text detection.
Load-bearing premise
That the features from general visual foundation models can be sufficiently adapted and aligned using low-rank updates and subspace fusion to handle text detection shifts without dedicated large-scale pretraining.
What would settle it
If TextDS with its 4.9M parameters underperforms significantly compared to methods using full pretraining on a held-out distribution shift dataset not used in the paper.
Figures



read the original abstract
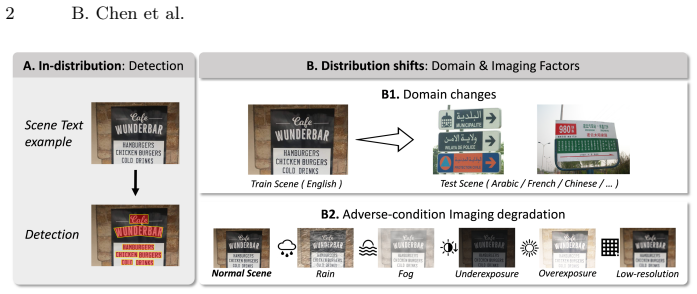
In real-world deployments, scene text detectors inevitably face distribution shifts beyond the training distribution. Prior work often depends on large-scale scene-text pretraining, yet evaluation under cross-domain changes and real-world imaging degradations remains limited. We propose TextDS, an efficient framework for scene text detection under distribution shifts. First, we propose a data-efficient dual-encoder design with visual foundation models, eliminating the reliance on large-scale scene-text pretraining. Second, we introduce Step-wise LoRA adaptation (SWLoRA), which performs progressive low-rank refinement with a dynamic early-exit mechanism for effective feature adaptation. Third, we propose Common Subspace Fusion (CSF) to align and fuse the two branches in a shared subspace while retaining complementary, shift-robust information. Finally, we construct adverse-condition scene text detection datasets to address the gap in evaluating under imaging degradation. Experiments show that TextDS achieves competitive performance in scene text detection, demonstrating robustness across domains and adverse imaging conditions with only 4.9M trainable parameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TextDS, a parameter-efficient framework for scene text detection under distribution shifts. It introduces a dual-encoder architecture that leverages frozen visual foundation models to avoid large-scale scene-text pretraining, Step-wise LoRA (SWLoRA) for progressive low-rank adaptation with a dynamic early-exit mechanism, and Common Subspace Fusion (CSF) to align the encoder branches in a shared subspace while preserving complementary shift-robust features. The authors also construct new adverse-condition scene text detection datasets to evaluate robustness under imaging degradations. The central claim is that TextDS achieves competitive performance and robustness across domains and adverse conditions while training only 4.9M parameters.
Significance. If the experimental results hold, the work would be significant for practical deployment of scene text detectors, as it demonstrates how frozen foundation models combined with targeted low-rank adaptation and subspace fusion can deliver robustness without expensive pretraining or full fine-tuning. The construction of adverse-condition datasets is a concrete contribution that fills an evaluation gap. The emphasis on parameter efficiency (4.9M trainable parameters) and avoidance of large-scale scene-text pretraining aligns with broader needs in efficient computer vision.
minor comments (2)
- [Abstract] Abstract: the claim of 'competitive performance' is stated without any numerical results, baselines, or error bars. Adding at least one key metric (e.g., F-measure on a cross-domain benchmark) would strengthen the abstract.
- [Method (SWLoRA subsection)] The description of SWLoRA mentions a 'dynamic early-exit mechanism' but does not specify the exit criterion or how it interacts with the progressive refinement schedule; a short algorithmic outline or pseudocode would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work, recognition of its significance for practical deployment, and recommendation of minor revision. The referee's description accurately reflects the core contributions of TextDS.
Circularity Check
No significant circularity; derivation is self-contained empirical proposal
full rationale
The provided abstract and description contain no equations, fitted parameters presented as predictions, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled via prior work. The central claims rest on the introduction of three components (dual-encoder with frozen VFM, SWLoRA, CSF) followed by experimental validation on constructed datasets; these are presented as independent engineering choices whose performance is measured externally rather than defined into existence. No reduction of any result to its own inputs by construction is visible.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Visual foundation models supply transferable features for scene text detection without large-scale scene-text pretraining
Reference graph
Works this paper leans on
-
[1]
IET Image Processing16(2), 289–310 (2022) 2
Arif, Z.H., Mahmoud, M.A., Abdulkareem, K.H., Mohammed, M.A., Al-Mhiqani, M.N., Mutlag, A.A., Damaševičius, R.: Comprehensive review of machine learning (ml) in image defogging: Taxonomy of concepts, scenes, feature extraction, and classification techniques. IET Image Processing16(2), 289–310 (2022) 2
2022
-
[2]
In: 2024 IEEE International Symposium on Biomedical Imaging (ISBI)
Ayzenberg, L., Giryes, R., Greenspan, H.: Dinov2 based self supervised learning for few shot medical image segmentation. In: 2024 IEEE International Symposium on Biomedical Imaging (ISBI). pp. 1–5. IEEE (2024) 4 16 B. Chen et al
2024
-
[3]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025) 4, 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
IEEE Access11, 67040–67057 (2023) 2
Brophy, T., Mullins, D., Parsi, A., Horgan, J., Ward, E., Denny, P., Eising, C., Deegan, B., Glavin, M., Jones, E.: A review of the impact of rain on camera-based perception in automated driving systems. IEEE Access11, 67040–67057 (2023) 2
2023
-
[5]
In: Proceedings of the IEEE/CVF international conference on computer vision
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9650–9660 (2021) 4
2021
-
[6]
Medical Image Analysis98, 103310 (2024) 4
Chen, C., Miao, J., Wu, D., Zhong, A., Yan, Z., Kim, S., Hu, J., Liu, Z., Sun, L., Li, X., et al.: Ma-sam: Modality-agnostic sam adaptation for 3d medical image segmentation. Medical Image Analysis98, 103310 (2024) 4
2024
-
[7]
In: 2017 14th IAPR international conference on document analysis and recognition (ICDAR)
Ch’Ng, C.K., Chan, C.S.: Total-text: A comprehensive dataset for scene text de- tection and recognition. In: 2017 14th IAPR international conference on document analysis and recognition (ICDAR). vol. 1, pp. 935–942. IEEE (2017) 2, 10
2017
-
[8]
IEEE Transactions on Circuits and Systems for Video Technology32(9), 6073–6085 (2022) 1
Guan, T., Gu, C., Lu, C., Tu, J., Feng, Q., Wu, K., Guan, X.: Industrial scene text detection with refined feature-attentive network. IEEE Transactions on Circuits and Systems for Video Technology32(9), 6073–6085 (2022) 1
2022
-
[9]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Gupta, A., Vedaldi, A., Zisserman, A.: Synthetic data for text localisation in natu- ral images. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2315–2324 (2016) 2, 4, 11
2016
-
[10]
Iclr1(2), 3 (2022) 5
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. Iclr1(2), 3 (2022) 5
2022
-
[11]
IEEE Transactions on Pattern Anal- ysis and Machine Intelligence (2025) 2
Jiang, J., Zuo, Z., Wu, G., Jiang, K., Liu, X.: A survey on all-in-one image restora- tion: Taxonomy, evaluation and future trends. IEEE Transactions on Pattern Anal- ysis and Machine Intelligence (2025) 2
2025
-
[12]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Jose, C., Moutakanni, T., Kang, D., Baldassarre, F., Darcet, T., Xu, H., Li, D., Szafraniec, M., Ramamonjisoa, M., Oquab, M., et al.: Dinov2 meets text: A unified framework for image-and pixel-level vision-language alignment. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 24905–24916 (2025) 4
2025
-
[13]
In: Proceedings of the IEEE/CVF international conference on computer vision
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4015–4026 (2023) 4
2023
-
[14]
PP-OCRv3: More Attempts for the Improvement of Ultra Lightweight OCR System.arXiv:2206.03001,
Li, C., Liu, W., Guo, R., Yin, X., Jiang, K., Du, Y., Du, Y., Zhu, L., Lai, B., Hu, X., et al.: Pp-ocrv3: More attempts for the improvement of ultra lightweight ocr system. arXiv preprint arXiv:2206.03001 (2022) 4, 14
-
[15]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, F., Zhang, H., Xu, H., Liu, S., Zhang, L., Ni, L.M., Shum, H.Y.: Mask dino: Towards a unified transformer-based framework for object detection and segmenta- tion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3041–3050 (2023) 4
2023
-
[16]
In: Proceedings of the AAAI conference on artificial intelligence
Liao, M., Wan, Z., Yao, C., Chen, K., Bai, X.: Real-time scene text detection with differentiable binarization. In: Proceedings of the AAAI conference on artificial intelligence. pp. 11474–11481 (2020) 2, 3, 10, 11, 12, 14
2020
-
[17]
In: Forty-first International Conference on Machine Learning (2024) 5
Liu, S.Y., Wang, C.Y., Yin, H., Molchanov, P., Wang, Y.C.F., Cheng, K.T., Chen, M.H.: Dora: Weight-decomposed low-rank adaptation. In: Forty-first International Conference on Machine Learning (2024) 5
2024
-
[18]
International Journal of Computer Vision129(1), 161–184 (2021) 2 TextDS: Scene Text Detection under Distribution Shifts 17
Long, S., He, X., Yao, C.: Scene text detection and recognition: The deep learning era. International Journal of Computer Vision129(1), 161–184 (2021) 2 TextDS: Scene Text Detection under Distribution Shifts 17
2021
-
[19]
IEEE Transactions on Intelligent Vehicles (2024) 2
Luo, S., Chen, W., Tian, W., Liu, R., Hou, L., Zhang, X., Shen, H., Wu, R., Geng, S., Zhou, Y., et al.: Delving into multi-modal multi-task foundation models for road scene understanding: From learning paradigm perspectives. IEEE Transactions on Intelligent Vehicles (2024) 2
2024
-
[20]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Luo, Y., Feinglass, J., Gokhale, T., Lee, K.C., Baral, C., Yang, Y.: Grounding stylistic domain generalization with quantitative domain shift measures and syn- thetic scene images. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7303–7313 (2024) 2
2024
-
[21]
IEEE Transactions on Geoscience and Remote Sensing62, 1–16 (2024) 4
Ma, X., Wu, Q., Zhao, X., Zhang, X., Pun, M.O., Huang, B.: Sam-assisted remote sensing imagery semantic segmentation with object and boundary constraints. IEEE Transactions on Geoscience and Remote Sensing62, 1–16 (2024) 4
2024
-
[22]
Frontiers of Computer Science19(7), 197605 (2025) 5
Mao, Y., Ge, Y., Fan, Y., Xu, W., Mi, Y., Hu, Z., Gao, Y.: A survey on lora of large language models. Frontiers of Computer Science19(7), 197605 (2025) 5
2025
-
[23]
Medical Image Analysis p
Miao, J., Chen, C., Yuan, Y., Li, Q., Heng, P.A.: Sam-driven cross prompting with adaptive sampling consistency for semi-supervised medical image segmentation. Medical Image Analysis p. 103973 (2026) 4
2026
-
[24]
Multimedia Tools and Applications81(14), 20255–20290 (2022) 1
Naiemi, F., Ghods, V., Khalesi, H.: Scene text detection and recognition: a survey. Multimedia Tools and Applications81(14), 20255–20290 (2022) 1
2022
-
[25]
In: 2017 14th IAPR inter- national conference on document analysis and recognition (ICDAR)
Nayef, N., Yin, F., Bizid, I., Choi, H., Feng, Y., Karatzas, D., Luo, Z., Pal, U., Rigaud,C.,Chazalon,J.,etal.:Icdar2017robustreadingchallengeonmulti-lingual scene text detection and script identification-rrc-mlt. In: 2017 14th IAPR inter- national conference on document analysis and recognition (ICDAR). vol. 1, pp. 1454–1459. IEEE (2017) 10
2017
-
[26]
In: Proceedings of the 24th International Conference on Intelligent User Interfaces
Neat, L., Peng, R., Qin, S., Manduchi, R.: Scene text access: A comparison of mobile ocr modalities for blind users. In: Proceedings of the 24th International Conference on Intelligent User Interfaces. pp. 197–207 (2019) 1
2019
-
[27]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023) 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al.: Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024) 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
IEEE Transactions on Circuits and Systems for Video Technology34(3), 1815–1826 (2023) 10, 11
Shao, Z., Su, Y., Zhou, Y., Meng, F., Zhu, H., Liu, B., Yao, R.: Ct-net: Arbitrary- shaped text detection via contour transformer. IEEE Transactions on Circuits and Systems for Video Technology34(3), 1815–1826 (2023) 10, 11
2023
-
[30]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025) 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
IEEE Transactions on Knowledge and Data Engineering36(11), 6962–6976 (2024) 1
Song, Y., Sun, P., Liu, H., Li, Z., Song, W., Xiao, Y., Zhou, X.: Scene-driven multimodal knowledge graph construction for embodied ai. IEEE Transactions on Knowledge and Data Engineering36(11), 6962–6976 (2024) 1
2024
-
[32]
Pattern Recognition157, 110935 (2025) 2
Su, H., Li, Y., Xu, Y., Fu, X., Liu, S.: A review of deep-learning-based super- resolution: From methods to applications. Pattern Recognition157, 110935 (2025) 2
2025
-
[33]
Su, Y., Chen, Z., Du, Y., Ji, Z., Hu, K., Bai, J., Gao, X.: Explicit relational reasoningnetworkforscenetextdetection.In:ProceedingsoftheAAAIConference on Artificial Intelligence. pp. 7069–7077 (2025) 2, 4, 10, 11
2025
-
[34]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Su, Y., Chen, Z., Shao, Z., Du, Y., Ji, Z., Bai, J., Zhou, Y., Jiang, Y.G.: Lranet: Towards accurate and efficient scene text detection with low-rank approximation network. In: Proceedings of the AAAI Conference on Artificial Intelligence. pp. 4979–4987 (2024) 2, 4, 10, 11, 12 18 B. Chen et al
2024
-
[35]
IEEE Transactions on Multimedia25, 5030–5042 (2022) 10, 11
Su, Y., Shao, Z., Zhou, Y., Meng, F., Zhu, H., Liu, B., Yao, R.: Textdct: Arbitrary- shaped text detection via discrete cosine transform mask. IEEE Transactions on Multimedia25, 5030–5042 (2022) 10, 11
2022
-
[36]
arXiv preprint arXiv:2510.16442 (2025) 14
Sun, H., Cai, C., Zhuang, H., Lee, K.A., Chau, L.P., Wang, Y.: Edvd-llama: Ex- plainable deepfake video detection via multimodal large language model reasoning. arXiv preprint arXiv:2510.16442 (2025) 14
-
[37]
In: International Conference on Pattern Recognition
Vaidya, S., Sharma, A.K., Gatti, P., Mishra, A.: Show me the world in my lan- guage: Establishing the first baseline for scene-text to scene-text translation. In: International Conference on Pattern Recognition. pp. 312–328. Springer (2024) 1
2024
-
[38]
IEEE Transactions on Neural Networks and Learning Systems (2025) 2, 3, 10, 11, 12, 14
Wang, R., Chen, H., Zhu, Y., Xu, J., Cao, X., Zhu, Z., Qian, S., Gao, C., Liu, L., Sang, N.: S3inet: Semantic-information space sharing interaction network for arbi- trary shape text detection. IEEE Transactions on Neural Networks and Learning Systems (2025) 2, 3, 10, 11, 12, 14
2025
-
[39]
IEEE Transactions on Neural Networks and Learning Sys- tems32(5), 2299–2304 (2020) 2
Wang, Y., Bian, Z.P., Hou, J., Chau, L.P.: Convolutional neural networks with dynamic regularization. IEEE Transactions on Neural Networks and Learning Sys- tems32(5), 2299–2304 (2020) 2
2020
-
[40]
IEEE transactions on intelligent transportation systems23(7), 8868–8880 (2021) 2
Wang, Y., Bian, Z.P., Zhou, Y., Chau, L.P.: Rethinking and designing a high- performing automatic license plate recognition approach. IEEE transactions on intelligent transportation systems23(7), 8868–8880 (2021) 2
2021
-
[41]
IEEE Transactions on Image Processing30, 2876–2887 (2021) 2
Wang, Y., Hou, J., Hou, X., Chau, L.P.: A self-training approach for point- supervised object detection and counting in crowds. IEEE Transactions on Image Processing30, 2876–2887 (2021) 2
2021
-
[42]
DeepSeek-OCR: Contexts Optical Compression
Wei, H., Sun, Y., Li, Y.: Deepseek-ocr: Contexts optical compression. arXiv preprint arXiv:2510.18234 (2025) 4, 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Xiong, Y., Zhou, C., Xiang, X., Wu, L., Zhu, C., Liu, Z., Suri, S., Varadarajan, B., Akula, R., Iandola, F., et al.: Efficient track anything. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 11513–11524 (2025) 4
2025
-
[44]
In: European Conference on Computer Vision
Xue, C., Zhang, W., Hao, Y., Lu, S., Torr, P.H., Bai, S.: Language matters: A weakly supervised vision-language pre-training approach for scene text detection and spotting. In: European Conference on Computer Vision. pp. 284–302. Springer (2022) 2
2022
-
[45]
IEEE Transactions on Geoscience and Remote Sensing61, 1–16 (2023) 4
Yan, Z., Li, J., Li, X., Zhou, R., Zhang, W., Feng, Y., Diao, W., Fu, K., Sun, X.: Ringmo-sam: A foundation model for segment anything in multimodal remote- sensing images. IEEE Transactions on Geoscience and Remote Sensing61, 1–16 (2023) 4
2023
-
[46]
Knowledge-Based Systems285, 111349 (2024) 2
Yang, S., Xie, L., Ran, X., Lei, J., Qian, X.: Pragmatic degradation learning for scene text image super-resolution with data-training strategy. Knowledge-Based Systems285, 111349 (2024) 2
2024
-
[47]
Detecting Curve Text in the Wild: New Dataset and New Solution
Yuliang, L., Lianwen, J., Shuaitao, Z., Sheng, Z.: Detecting curve text in the wild: New dataset and new solution. arXiv preprint arXiv:1712.02170 (2017) 2, 9
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[48]
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
Zhang, Q., Chen, M., Bukharin, A., Karampatziakis, N., He, P., Cheng, Y., Chen, W., Zhao, T.: Adalora: Adaptive budget allocation for parameter-efficient fine- tuning. arXiv preprint arXiv:2303.10512 (2023) 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
IEEE transactions on pattern analysis and machine intelligence45(3), 2736–2750 (2022) 2, 3, 10, 11, 12, 14
Zhang, S.X., Zhu, X., Chen, L., Hou, J.B., Yin, X.C.: Arbitrary shape text de- tection via segmentation with probability maps. IEEE transactions on pattern analysis and machine intelligence45(3), 2736–2750 (2022) 2, 3, 10, 11, 12, 14
2022
-
[50]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhang, S.X., Zhu, X., Yang, C., Wang, H., Yin, X.C.: Adaptive boundary proposal network for arbitrary shape text detection. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 1305–1314 (2021) 2, 4, 10, 11, 12 TextDS: Scene Text Detection under Distribution Shifts 19
2021
-
[51]
IEEE Transactions on Neural Networks and Learning Systems (2025) 2
Zhao, Q., Li, G., He, B., Shen, R.: Deep learning for low-light vision: A comprehen- sive survey. IEEE Transactions on Neural Networks and Learning Systems (2025) 2
2025
-
[52]
International Journal of Computer Vision132(8), 3119–3138 (2024) 10, 11, 12
Zhao, X., Feng, W., Zhang, Z., Lv, J., Zhu, X., Lin, Z., Hu, J., Shao, J.: Cbnet: A plug-and-play network for segmentation-based scene text detection. International Journal of Computer Vision132(8), 3119–3138 (2024) 10, 11, 12
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.