Neural CSI Compression Fine-Tuning: Taming the Communication Cost of Model Updates
Pith reviewed 2026-05-23 04:46 UTC · model grok-4.3
The pith
Full-model fine-tuning improves neural CSI compression rate-distortion even after paying for decoder updates via joint entropy coding and sparse priors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By explicitly including the bit rate of model updates in the fine-tuning loss, jointly entropy-coding those updates with the compressed CSI, and applying a structured prior that encourages sparse and selective parameter changes, full-model fine-tuning on a modest number of recent target-domain CSI samples yields substantial gains in overall rate-distortion performance of the neural compressor across several datasets, even after subtracting the communication cost of the updates.
What carries the argument
Structured prior on decoder parameters that promotes sparse and selective updates, combined with joint rate optimization and entropy coding of CSI feedback plus model updates.
If this is right
- The net feedback efficiency improves when the evaluation horizon, quantization of updates, and size of the target dataset are varied within the ranges tested.
- Performance gains hold across multiple independent CSI datasets.
- Joint entropy coding of CSI and model updates is feasible without separate overhead channels.
Where Pith is reading between the lines
- The same joint-rate-plus-sparse-prior technique could be tested on other neural compression tasks where the decoder must be updated over a rate-limited link.
- If the sparsity pattern learned by the prior turns out to be stable across environments, the method might support incremental updates with even lower cost than full re-transmission.
- One could measure whether the same fine-tuning budget yields larger gains when the structured prior is replaced by standard L1 regularization.
Load-bearing premise
The structured prior is able to produce sparse enough parameter updates that the model-update bit rate stays low while most of the fine-tuning performance gain is preserved.
What would settle it
An experiment on the same CSI datasets where the overall rate-distortion curve after fine-tuning lies above the no-fine-tuning baseline once model-update bits are included.
Figures






read the original abstract
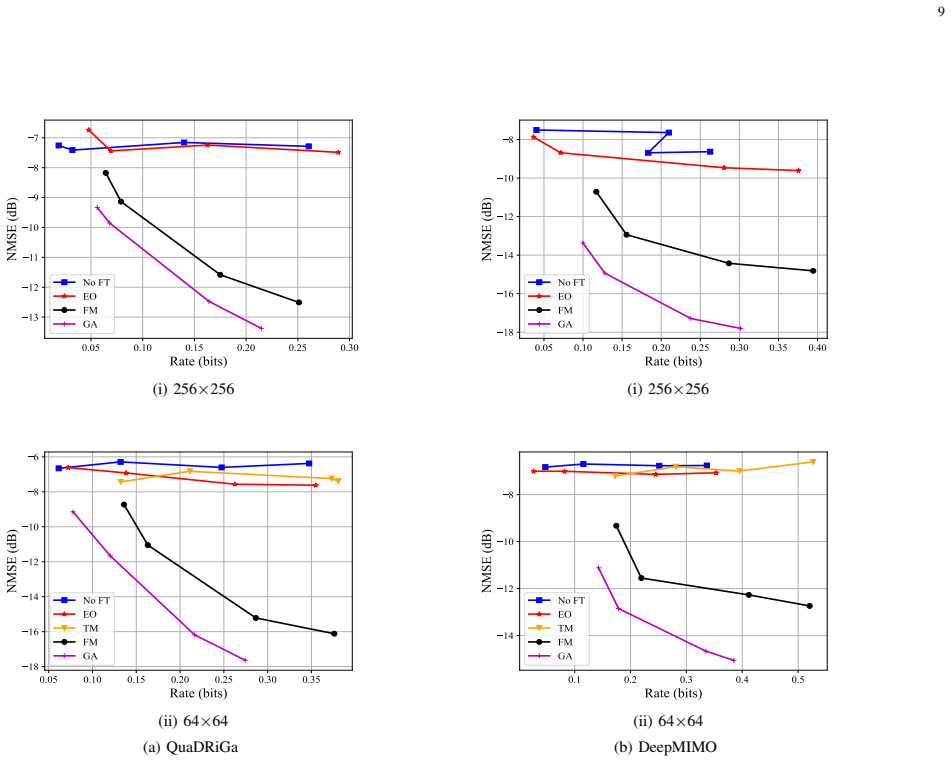
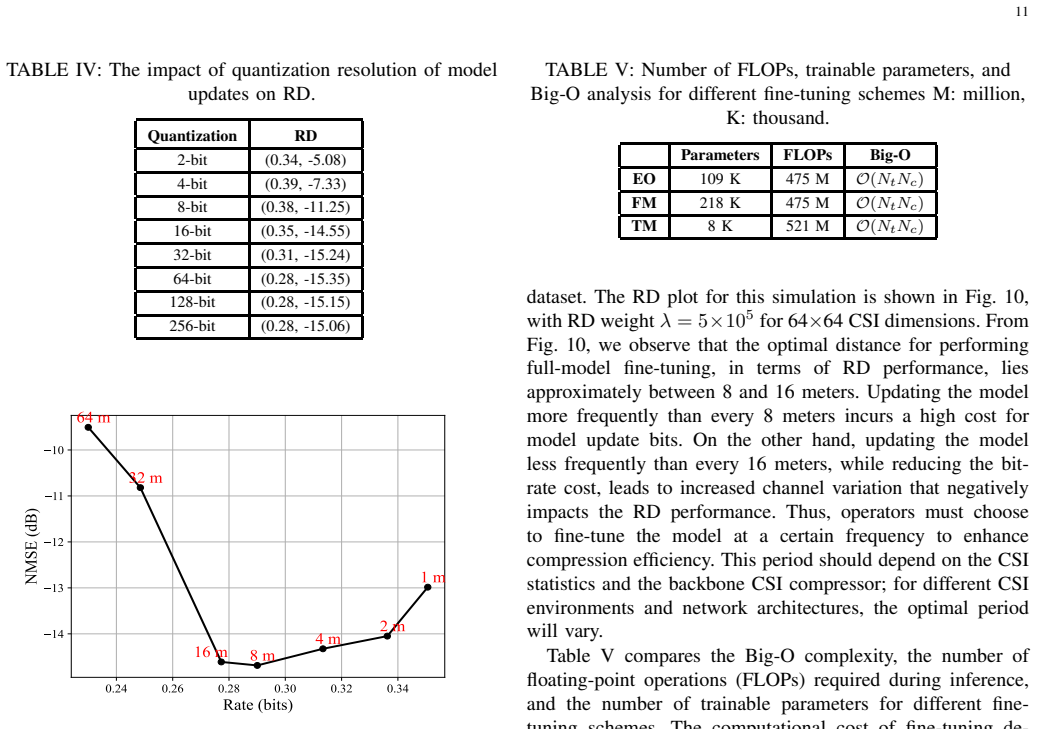
Efficient channel state information (CSI) compression is essential in frequency division duplexing (FDD) massive multiple-input multiple-output (MIMO) systems due to the substantial feedback overhead. Recently, deep learning-based compression techniques have demonstrated superior performance for CSI feedback. However, their performance often degrades under distribution shifts across wireless environments, largely due to limited generalization capability. To address this challenge, we consider a full-model fine-tuning scheme, in which both the encoder and decoder are jointly updated using a small number of recent CSI samples from the target environment. A key challenge in this setting is the transmission of updated decoder parameters to the receiver, which introduces additional communication overhead. To mitigate this bottleneck, we explicitly incorporate the bit rate of model updates into the fine-tuning objective and entropy-code the model updates jointly with the compressed CSI. Furthermore, we employ a structured prior that promotes sparse and selective parameter updates, thereby significantly reducing the model-update communication cost. Simulation results across multiple CSI datasets demonstrate that full-model fine-tuning substantially improves the rate-distortion performance of neural CSI compression, despite the additional cost of model updates. We further analyze the impact of the evaluation horizon, the quantization resolution of model updates, and the size of the target-domain dataset on the overall feedback efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a full-model fine-tuning scheme for neural CSI compression in FDD massive MIMO systems to mitigate performance degradation under distribution shifts. Both encoder and decoder are updated on a small set of target-environment CSI samples; the bit rate of the resulting model updates is explicitly folded into the fine-tuning objective, the updates are entropy-coded jointly with the CSI, and a structured prior is used to encourage sparse and selective parameter changes. Simulation results across multiple CSI datasets are reported to show that the net rate-distortion performance improves despite the added update overhead, with further analysis of evaluation horizon, quantization resolution, and target-dataset size.
Significance. If the empirical claims hold, the work addresses a practically important barrier to deploying learned CSI compressors in time-varying wireless environments. Explicitly penalizing model-update rate and employing a structured prior to control communication cost constitute a direct and relevant engineering contribution. The multi-dataset simulation campaign is a positive feature.
major comments (2)
- [Method section describing the structured prior and fine-tuning objective] The central claim that full-model fine-tuning yields net rate-distortion gains rests on the structured prior successfully producing sufficiently sparse/selective updates so that the added communication cost is amortized. The manuscript states that the prior 'promotes sparse and selective parameter updates' and incorporates update bit rate into the objective, yet supplies no ablation that isolates the prior, no sparsity statistics (fraction of non-zero deltas, effective coded parameter count), and no comparison against an unstructured Gaussian prior baseline. Without these, it is impossible to determine whether the reported net improvement is a general consequence of the prior or an artifact of the chosen datasets and horizons.
- [Abstract and simulation-results section] The abstract and simulation results assert that full-model fine-tuning 'substantially improves' rate-distortion performance, but the provided description contains no quantitative deltas, no explicit baseline comparisons, and no implementation details on the joint entropy coding of CSI and model updates. These omissions make it difficult to gauge the magnitude and robustness of the claimed gains.
minor comments (2)
- [Abstract] The abstract would be strengthened by including at least one concrete performance number (e.g., NMSE or rate reduction) to support the qualitative claim of substantial improvement.
- [Notation and objective-function definitions] Notation for bit-rate and distortion terms should be checked for consistency between the objective function and the reported simulation metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight areas where the manuscript can be strengthened with additional analysis and details. We address each major comment below and will incorporate the suggested revisions.
read point-by-point responses
-
Referee: [Method section describing the structured prior and fine-tuning objective] The central claim that full-model fine-tuning yields net rate-distortion gains rests on the structured prior successfully producing sufficiently sparse/selective updates so that the added communication cost is amortized. The manuscript states that the prior 'promotes sparse and selective parameter updates' and incorporates update bit rate into the objective, yet supplies no ablation that isolates the prior, no sparsity statistics (fraction of non-zero deltas, effective coded parameter count), and no comparison against an unstructured Gaussian prior baseline. Without these, it is impossible to determine whether the reported net improvement is a general consequence of the prior or an artifact of the chosen datasets and horizons.
Authors: We agree that the manuscript would benefit from explicit ablations and statistics to isolate the structured prior's contribution. In the revised version, we will add: (i) an ablation comparing the structured prior to an unstructured Gaussian prior baseline, (ii) sparsity statistics including the fraction of non-zero parameter deltas and effective coded parameter counts after entropy coding, and (iii) discussion of how these elements enable amortization of update costs across the evaluated datasets and horizons. This will strengthen the evidence that the net gains stem from the proposed prior. revision: yes
-
Referee: [Abstract and simulation-results section] The abstract and simulation results assert that full-model fine-tuning 'substantially improves' rate-distortion performance, but the provided description contains no quantitative deltas, no explicit baseline comparisons, and no implementation details on the joint entropy coding of CSI and model updates. These omissions make it difficult to gauge the magnitude and robustness of the claimed gains.
Authors: We acknowledge the need for more explicit quantification and details. The revised manuscript will update the abstract to include specific quantitative deltas (e.g., rate-distortion improvements in dB or percentage terms), expand the simulation-results section with explicit baseline comparisons (including no-fine-tuning and partial-update cases), and add implementation details on the joint entropy coding of CSI and model updates, such as the entropy model architecture, coding procedure, and quantization scheme. revision: yes
Circularity Check
No circularity: empirical method with direct rate incorporation and simulation validation
full rationale
The paper proposes a fine-tuning scheme for neural CSI compression that explicitly adds the measured bit rate of model updates to the training objective and employs a structured prior as a modeling choice. Performance gains are shown via simulations on multiple CSI datasets. No step reduces a claimed prediction or result to a fitted parameter or self-citation by construction; the central claims rest on external empirical benchmarks rather than tautological definitions or load-bearing self-references.
Axiom & Free-Parameter Ledger
free parameters (2)
- weight on model-update rate term in fine-tuning objective
- sparsity strength in structured prior
axioms (2)
- domain assumption A small number of recent CSI samples from the target environment are sufficient to adapt the model without overfitting or requiring large target-domain data.
- domain assumption The entropy coder can jointly compress the sparse model updates and the CSI payload without significant rate overhead beyond the modeled cost.
Reference graph
Works this paper leans on
-
[1]
Noncooperative cellular wireless with unlimited num- bers of base station antennas,
T. L. Marzetta, “Noncooperative cellular wireless with unlimited num- bers of base station antennas,”IEEE Trans. Wireless Commun., vol. 9, no. 11, pp. 3590–3600, 2010
work page 2010
-
[2]
Massive MIMO for next generation wireless systems,
E. G. Larsson, O. Edfors, F. Tufvesson, and T. L. Marzetta, “Massive MIMO for next generation wireless systems,”IEEE Commun. Mag., vol. 52, no. 2, pp. 186–195, 2014
work page 2014
-
[3]
Distributed compressive CSIT estimation and feedback for FDD multi-user massive MIMO systems,
X. Rao and V . K. N. Lau, “Distributed compressive CSIT estimation and feedback for FDD multi-user massive MIMO systems,”IEEE Trans. Signal Process., vol. 62, no. 12, pp. 3261–3271, 2014
work page 2014
-
[4]
Rate- adaptive feedback with bayesian compressive sensing in multiuser MIMO beamforming systems,
X.-L. Huang, J. Wu, Y . Wen, F. Hu, Y . Wang, and T. Jiang, “Rate- adaptive feedback with bayesian compressive sensing in multiuser MIMO beamforming systems,”IEEE Trans. Wireless Commun., vol. 15, no. 7, pp. 4839–4851, 2016
work page 2016
-
[5]
User- driven adaptive CSI feedback with ordered vector quantization,
V . Rizzello, M. Nerini, M. Joham, B. Clerckx, and W. Utschick, “User- driven adaptive CSI feedback with ordered vector quantization,”IEEE Wireless Commun. Lett., vol. 12, no. 11, pp. 1956–1960, 2023
work page 1956
-
[6]
Predictive vector quantization for multicell cooperation with delayed limited feedback,
R. Bhagavatula and R. W. Heath, “Predictive vector quantization for multicell cooperation with delayed limited feedback,”IEEE Trans. Wireless Commun., vol. 12, no. 6, pp. 2588–2597, 2013
work page 2013
-
[7]
Deep learning for massive MIMO CSI feedback,
C. Wen, W. Shih, and S. Jin, “Deep learning for massive MIMO CSI feedback,”IEEE Wireless Commun. Lett., vol. 7, no. 5, pp. 748–751, Mar. 2018
work page 2018
-
[8]
J. Guo, C.-K. Wen, S. Jin, and G. Y . Li, “Convolutional neural network- based multiple-rate compressive sensing for massive MIMO CSI feed- back: Design, simulation, and analysis,”IEEE Trans. Wireless Commun., vol. 19, no. 4, pp. 2827–2840, 2020
work page 2020
-
[9]
Multi-resolution CSI feedback with deep learning in massive MIMO system,
Z. Lu, J. Wang, and J. Song, “Multi-resolution CSI feedback with deep learning in massive MIMO system,” inProc. IEEE Int. Conf. Commun. (ICC), 2020, pp. 1–6
work page 2020
-
[10]
Dilated convolution based CSI feedback compression for massive MIMO sys- tems,
S. Tang, J. Xia, L. Fan, X. Lei, W. Xu, and A. Nallanathan, “Dilated convolution based CSI feedback compression for massive MIMO sys- tems,”IEEE Trans. V eh. Technol., vol. 71, no. 10, pp. 11 216–11 221, 2022
work page 2022
-
[11]
Transnet: Full attention network for CSI feedback in FDD massive MIMO system,
Y . Cui, A. Guo, and C. Song, “Transnet: Full attention network for CSI feedback in FDD massive MIMO system,”IEEE Wireless Commun. Lett., vol. 11, no. 5, pp. 903–907, 2022
work page 2022
-
[12]
A learn- able optimization and regularization approach to massive MIMO CSI feedback,
Z. Hu, G. Liu, Q. Xie, J. Xue, D. Meng, and D. G ¨und¨uz, “A learn- able optimization and regularization approach to massive MIMO CSI feedback,”IEEE Trans. Wireless Commun., vol. 23, no. 1, pp. 104–116, 2024
work page 2024
-
[13]
H. Wu, M. Zhang, Y . Shao, K. Mikolajczyk, and D. G ¨und¨uz, “MIMO channel as a neural function: Implicit neural representations for extreme CSI compression in massive MIMO systems,” 2024. [Online]. Available: https://arxiv.org/abs/2403.13615
-
[14]
Distributed deep convo- lutional compression for massive MIMO CSI feedback,
M. B. Mashhadi, Q. Yang, and D. G ¨und¨uz, “Distributed deep convo- lutional compression for massive MIMO CSI feedback,”IEEE Trans. Wireless Commun., vol. 20, no. 4, pp. 2621–2633, 2021
work page 2021
-
[15]
CSI-PPPNet: A one-sided one-for-all deep learning framework for massive MIMO CSI feedback,
W. Chen, W. Wan, S. Wang, P. Sun, G. Y . Li, and B. Ai, “CSI-PPPNet: A one-sided one-for-all deep learning framework for massive MIMO CSI feedback,” 2023. [Online]. Available: https://arxiv.org/abs/2211.15851
-
[16]
An introduction to neural data compression,
Y . Yang, S. Mandt, and L. Theis, “An introduction to neural data compression,”F ound. Trends. Comput. Graph. Vis., vol. 15, no. 2, p. 113–200, apr 2023. [Online]. Available: https://doi.org/10.1561/ 0600000107
work page 2023
-
[17]
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial nets,” in Adv. Neural Inf. Process. Syst., Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, and K. Weinberger, Eds., vol. 27. Curran Associates, Inc., 2014. [Online]. Available: https://proceedings.neurips.cc/paper files/pap...
work page 2014
-
[18]
Auto-Encoding Variational Bayes,
D. P. Kingma and M. Welling, “Auto-Encoding Variational Bayes,” in 2nd Int. Conf. Learn. Represent. (ICLR) 2014, Banff, AB, Canada, Apr . 14-16, 2014, Conf. Track Proc., 2014
work page 2014
-
[19]
The neural autoregressive distribution estimator,
H. Larochelle and I. Murray, “The neural autoregressive distribution estimator,” inProc. 14th Int. Conf. Artif. Intell. Stat. (AISTATS), ser. Proc. Mach. Learn. Res., G. Gordon, D. Dunson, and M. Dud ´ık, Eds., vol. 15. Fort Lauderdale, FL, USA: PMLR, 11–13 Apr 2011, pp. 29–37. [Online]. Available: https://proceedings.mlr.press/v15/larochelle11a.html
work page 2011
-
[20]
Pixel recurrent neural networks,
A. van den Oord, N. Kalchbrenner, and K. Kavukcuoglu, “Pixel recurrent neural networks,” inProc. 33rd Int. Conf. Mach. Learn. (ICML), ser. Proc. Mach. Learn. Res., M. F. Balcan and K. Q. Weinberger, Eds., vol. 48. New York, NY , USA: PMLR, 20–22 Jun 2016, pp. 1747–1756. [Online]. Available: https://proceedings.mlr.press/v48/oord16.html
work page 2016
-
[21]
Deep convolutional com- pression for massive MIMO CSI feedback,
Q. Yang, M. B. Mashhadi, and D. G ¨und¨uz, “Deep convolutional com- pression for massive MIMO CSI feedback,” inProc. IEEE 29th Int. Workshop Mach. Learn. Signal Process. (MLSP), 2019, pp. 1–6
work page 2019
-
[22]
J. Qui ˜nonero-Candela, M. Sugiyama, A. Schwaighofer, and N. D. Lawrence,Dataset Shift in Machine Learning. MIT Press, 2022
work page 2022
-
[23]
A comprehensive survey on transfer learning,
F. Zhuang, Z. Qi, K. Duan, D. Xi, Y . Zhu, H. Zhu, H. Xiong, and Q. He, “A comprehensive survey on transfer learning,”Proc. IEEE, vol. 109, no. 1, pp. 43–76, 2020
work page 2020
-
[24]
Generalizing to unseen domains via adversarial data augmentation,
R. V olpi, H. Namkoong, O. Sener, J. C. Duchi, V . Murino, and S. Savarese, “Generalizing to unseen domains via adversarial data augmentation,” inAdv. Neural Inf. Process. Syst. (NeurIPS), S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa- Bianchi, and R. Garnett, Eds., vol. 31. Curran Associates, Inc.,
-
[25]
[Online]. Available: https://proceedings.neurips.cc/paper files/ paper/2018/file/1d94108e907bb8311d8802b48fd54b4a-Paper.pdf
work page 2018
-
[26]
Unsupervised domain adaptation by backpropagation,
Y . Ganin and V . Lempitsky, “Unsupervised domain adaptation by backpropagation,” inInt. Conf. Mach. Learn. (ICML). PMLR, 2015, pp. 1180–1189
work page 2015
-
[27]
Full- duplex millimeter wave MIMO channel estimation: A neural network approach,
M. Sattari, H. Guo, D. G ¨und¨uz, A. Panahi, and T. Svensson, “Full- duplex millimeter wave MIMO channel estimation: A neural network approach,”IEEE Trans. Mach. Learn. Commun. Netw., vol. 2, pp. 1093– 1108, 2024
work page 2024
-
[28]
Adaptive neural signal detection for massive MIMO,
M. Khani, M. Alizadeh, J. Hoydis, and P. Fleming, “Adaptive neural signal detection for massive MIMO,”IEEE Trans. Wirel. Commun., vol. 19, no. 8, pp. 5635–5648, May. 2020
work page 2020
-
[29]
Airnet: Neural network transmission over the air,
M. Jankowski, D. G ¨und¨uz, and K. Mikolajczyk, “Airnet: Neural network transmission over the air,” in2022 IEEE Int. Symp. Inf. Theory (ISIT), 2022, pp. 2451–2456
work page 2022
-
[30]
Downlink CSI feedback algorithm with deep transfer learning for FDD massive MIMO systems,
J. Zeng, J. Sun, G. Gui, B. Adebisi, T. Ohtsuki, H. Gacanin, and H. Sari, “Downlink CSI feedback algorithm with deep transfer learning for FDD massive MIMO systems,”IEEE Trans. Cogn. Commun. Netw., vol. 7, no. 4, pp. 1253–1265, 2021. 13
work page 2021
-
[31]
Z. Liu, L. Wang, L. Xu, and Z. Ding, “Deep learning for efficient CSI feedback in massive MIMO: Adapting to new environments and small datasets,”IEEE Trans. Wireless Commun., pp. 1–1, 2024
work page 2024
-
[32]
Multi-task learning-based CSI feedback design in multiple scenarios,
X. Li, J. Guo, C.-K. Wen, S. Jin, S. Han, and X. Wang, “Multi-task learning-based CSI feedback design in multiple scenarios,”IEEE Trans. Commun., vol. 71, no. 12, pp. 7039–7055, 2023
work page 2023
-
[33]
Model transmission- based online updating approach for massive mimo csi feedback,
B. Zhang, H. Li, X. Liang, X. Gu, and L. Zhang, “Model transmission- based online updating approach for massive mimo csi feedback,”IEEE Communications Letters, vol. 27, no. 6, pp. 1609–1613, 2023
work page 2023
-
[34]
Continuous online learning- based csi feedback in massive mimo systems,
X. Zhang, J. Wang, Z. Lu, and H. Zhang, “Continuous online learning- based csi feedback in massive mimo systems,”IEEE Communications Letters, vol. 28, no. 3, pp. 557–561, 2024
work page 2024
-
[35]
Communication-efficient personalized federated edge learning for massive mimo csi feedback,
Y . Cui, J. Guo, C.-K. Wen, and S. Jin, “Communication-efficient personalized federated edge learning for massive mimo csi feedback,” IEEE Transactions on Wireless Communications, vol. 23, no. 7, pp. 7362–7375, 2024
work page 2024
-
[36]
User-centric online gossip training for autoencoder-based csi feedback,
J. Guo, Y . Zuo, C.-K. Wen, and S. Jin, “User-centric online gossip training for autoencoder-based csi feedback,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 3, pp. 559–572, 2022
work page 2022
-
[37]
On the advantages of stochastic encoders,
L. Theis and E. Agustsson, “On the advantages of stochastic encoders,”CoRR, vol. abs/2102.09270, 2021. [Online]. Available: https://arxiv.org/abs/2102.09270
-
[38]
Towards empirical sandwich bounds on the rate-distortion function,
Y . Yang and S. Mandt, “Towards empirical sandwich bounds on the rate-distortion function,”ArXiv, vol. abs/2111.12166, 2021. [Online]. Available: https://api.semanticscholar.org/CorpusID:244527239
-
[39]
Variational image compression with a scale hyperprior,
J. Ball ´e, D. Minnen, S. Singh, S. J. Hwang, and N. Johnston, “Variational image compression with a scale hyperprior,” inInt. Conf. Learn. Represent. (ICLR), 2018. [Online]. Available: https: //openreview.net/forum?id=rkcQFMZRb
work page 2018
- [40]
-
[41]
Quadriga: A 3-d multi-cell channel model with time evolution for enabling virtual field trials,
S. Jaeckel, L. Raschkowski, K. B ¨orner, and L. Thiele, “Quadriga: A 3-d multi-cell channel model with time evolution for enabling virtual field trials,”IEEE Trans. Antennas Propag., vol. 62, no. 6, pp. 3242–3256, 2014
work page 2014
-
[42]
DeepMIMO: A generic deep learning dataset for mil- limeter wave and massive MIMO applications,
A. Alkhateeb, “DeepMIMO: A generic deep learning dataset for mil- limeter wave and massive MIMO applications,” inProc. Inf. Theory Appl. Workshop (ITA), San Diego, CA, Feb 2019, pp. 1–8
work page 2019
-
[43]
Overfitting for fun and profit: Instance-adaptive data compression,
T. van Rozendaal, I. A. Huijben, and T. Cohen, “Overfitting for fun and profit: Instance-adaptive data compression,” inInt. Conf. Learn. Represent. (ICLR), 2021. [Online]. Available: https: //openreview.net/forum?id=oFp8Mx V5FL
work page 2021
-
[44]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Y . Bengio, N. L ´eonard, and A. C. Courville, “Estimating or propagating gradients through stochastic neurons for conditional computation,” CoRR, vol. abs/1308.3432, 2013, accessed: 2025-01-27. [Online]. Available: http://arxiv.org/abs/1308.3432
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[45]
V . Roˇckov´a and E. I. G. and, “The spike-and-slab lasso,”Journal of the American Statistical Association, vol. 113, no. 521, pp. 431–444, 2018. [Online]. Available: https://doi.org/10.1080/01621459.2016.1260469
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.