AlgoEvolve: LLM-driven Meta-evolution of Algorithmic Trading Programs
Pith reviewed 2026-06-26 01:51 UTC · model grok-4.3
The pith
LLMs can evolve executable trading strategies as Python code and also evolve the prompts that guide that evolution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
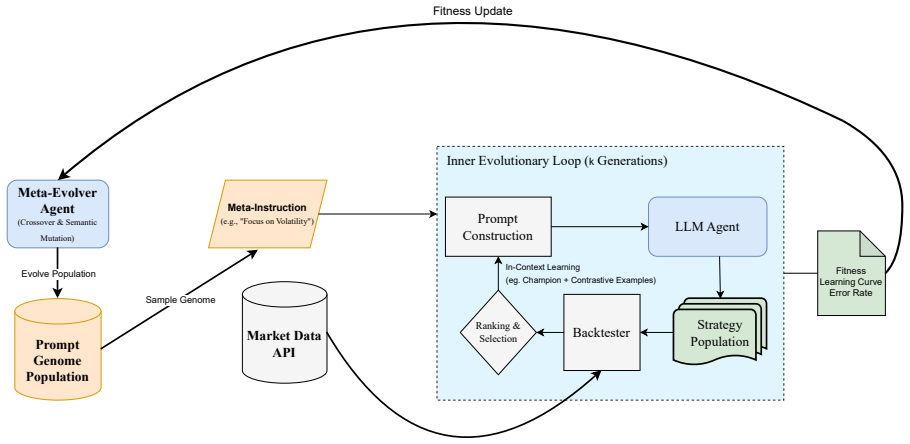
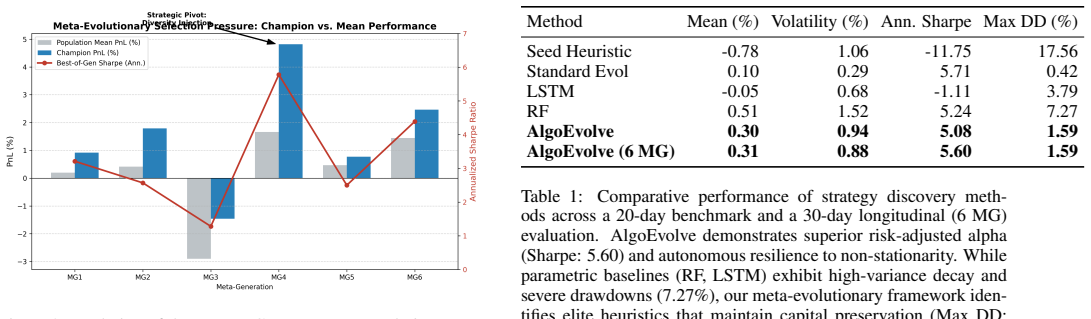
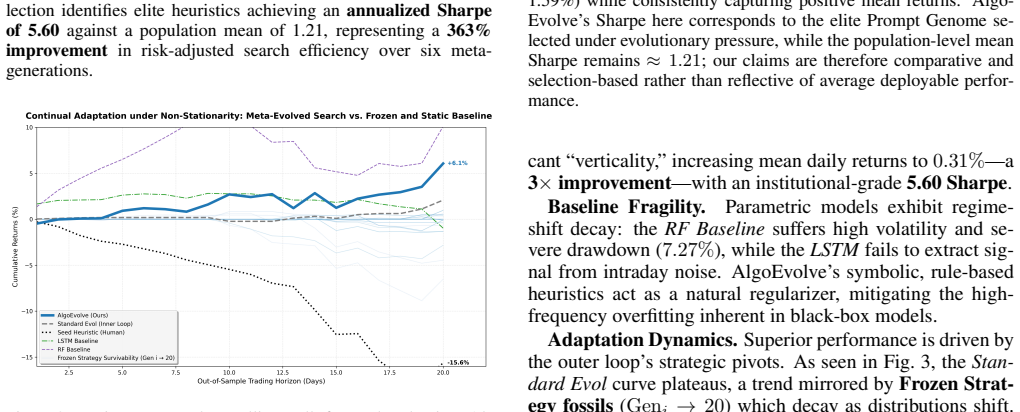
AlgoEvolve generates trading strategies as Python code, evaluates them with a rigorous protocol, and applies LLM-driven semantic mutations to improve them across iterations. The system produces emergent regime-adaptive logic that shifts trading rules autonomously. A meta-evolutionary outer loop then evolves the prompts used for the inner synthesis, yielding search heuristics that balance exploration and exploitation, reduce zero-trade failures, and consistently outperform the original human-designed instructions.
What carries the argument
The meta-evolutionary outer loop that refines the prompts directing the inner LLM-based evolutionary synthesis of trading programs.
If this is right
- Trading strategies can develop autonomous rule changes in response to different market regimes.
- Search heuristics emerge that reduce unproductive zero-trade outcomes compared with fixed human prompts.
- The same LLM mutation mechanism can be applied to continual program improvement beyond static coding tasks.
- Meta-evolution of prompts can discover better balance between exploration and exploitation than manual design.
Where Pith is reading between the lines
- The method may transfer to other noisy, non-stationary optimization domains such as robotics control or energy scheduling.
- If the outer loop reliably improves the inner search, similar meta-loops could reduce reliance on expert-crafted prompts in other LLM-driven synthesis systems.
- The observed regime-adaptive behavior suggests the approach could be tested for automatic detection of structural breaks in time-series data.
Load-bearing premise
The described testing protocol can separate genuine performance gains from overfitting or data-snooping effects in non-stationary financial time series.
What would settle it
Evolved strategies showing no statistically significant outperformance over baselines when evaluated on market data after the training window used in the experiments.
Figures
read the original abstract
Recent work shows that Large Language Models (LLMs) can act as semantic mutation operators for the evolutionary discovery of programs and proofs. Most current applications focus on static coding benchmarks. We extend this paradigm to algorithmic trading. This domain is uniquely challenging because it is noisy, non-stationary, and highly discontinuous. We present AlgoEvolve, an LLM-driven evolutionary framework that generates, evaluates, and iteratively improves executable trading strategies. These strategies are expressed as Python code and evaluated through a rigorous testing protocol. Across multiple experiments, the system exhibits emergent regime-adaptive strategy logic, including autonomous shifts in trading rules. We further introduce a meta-evolutionary outer loop that evolves the prompts guiding program synthesis in the inner loop. This outer loop discovers improved search heuristics. These heuristics balance exploration and exploitation while reducing zero-trade failures. They consistently outperform initial human-designed instructions. The results demonstrate that LLM-based semantic evolution provides a viable approach for continual program synthesis in complex environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AlgoEvolve, an LLM-driven evolutionary framework that generates, evaluates, and iteratively improves executable Python trading strategies. It claims the system exhibits emergent regime-adaptive strategy logic with autonomous shifts in trading rules, and introduces a meta-evolutionary outer loop that evolves prompts to discover improved search heuristics balancing exploration/exploitation and reducing zero-trade failures, consistently outperforming initial human-designed instructions.
Significance. If the experimental claims hold under rigorous controls, the work would demonstrate a viable LLM-based semantic evolution approach for continual program synthesis in noisy, non-stationary environments, extending the paradigm from static coding benchmarks to a challenging real-world domain.
major comments (2)
- [Abstract] Abstract: the central claims of outperformance, emergent adaptive logic, and meta-evolution gains rest on asserted experimental outcomes with no reported metrics, baselines, statistical tests, or testing-protocol description, rendering the results impossible to evaluate.
- [Abstract] Abstract/Methods: the 'rigorous testing protocol' for executable strategies on non-stationary financial series is invoked but not specified, leaving open whether it incorporates purged k-fold CV, walk-forward analysis across regimes, or correction for the large search space induced by LLM mutations; without these, regime-adaptive behavior cannot be distinguished from data-snooping artifacts.
minor comments (1)
- [Abstract] Abstract: the distinction between the inner evolutionary loop and the outer meta-evolutionary loop on prompts is stated but not formalized (e.g., no pseudocode or fitness definitions for the outer loop).
Simulated Author's Rebuttal
Thank you for the constructive feedback. We agree that the abstract requires quantitative details to support its claims and that the testing protocol needs explicit elaboration in the methods to address concerns about non-stationarity and data snooping. We will make these revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of outperformance, emergent adaptive logic, and meta-evolution gains rest on asserted experimental outcomes with no reported metrics, baselines, statistical tests, or testing-protocol description, rendering the results impossible to evaluate.
Authors: We acknowledge this limitation in the current abstract. In revision, we will incorporate specific metrics (e.g., annualized returns, Sharpe ratios, maximum drawdown), baselines (buy-and-hold, static LLM prompts, and traditional genetic programming), and references to statistical tests from the results sections. A concise description of the evaluation protocol will also be added to make the abstract self-contained. revision: yes
-
Referee: [Abstract] Abstract/Methods: the 'rigorous testing protocol' for executable strategies on non-stationary financial series is invoked but not specified, leaving open whether it incorporates purged k-fold CV, walk-forward analysis across regimes, or correction for the large search space induced by LLM mutations; without these, regime-adaptive behavior cannot be distinguished from data-snooping artifacts.
Authors: The protocol is outlined in Section 3.2 as walk-forward analysis with regime-stratified out-of-sample testing. We will expand this section to explicitly detail purged cross-validation elements, the regime detection approach, and adjustments for multiple testing arising from LLM mutations. This revision will clarify how adaptive behavior is distinguished from overfitting. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents an empirical LLM-driven evolutionary framework for generating and testing trading strategies, with viability demonstrated via experiments rather than any mathematical derivation, equations, or first-principles results. No load-bearing steps reduce to inputs by construction, self-citation, or fitted parameters renamed as predictions; the abstract and description contain no such chain. Concerns about the testing protocol relate to empirical validity in non-stationary data, not circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can act as semantic mutation operators for evolutionary discovery of programs
Reference graph
Works this paper leans on
-
[1]
Hoff- man, David Pfau, Tom Schaul, Brendan Shillingford, and Nando de Freitas
[Andrychowiczet al., 2016 ] Marcin Andrychowicz, Misha Denil, Sergio Gomez Colmenarejo, Matthew W. Hoff- man, David Pfau, Tom Schaul, Brendan Shillingford, and Nando de Freitas. Learning to learn by gradient descent by gradient descent. InProceedings of the 30th Interna- tional Conference on Neural Information Processing Sys- tems, pages 3988–3996. Curran...
2016
-
[2]
FinBERT: Financial Sentiment Analysis with Pre-trained Language Models
[Araci, 2019] Dogu Araci. Finbert: Financial sentiment analysis with pre-trained language models.arXiv preprint arXiv:1908.10063,
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[3]
A survey of explainable artificial intelligence (xai) in financial time series forecast- ing.ACM Computing Surveys, 57(10):1–37,
[Arsenaultet al., 2025 ] Pierre-Daniel Arsenault, Shengrui Wang, and Jean-Marc Patenaude. A survey of explainable artificial intelligence (xai) in financial time series forecast- ing.ACM Computing Surveys, 57(10):1–37,
2025
-
[4]
[Barkeet al., 2022 ] Shraddha Barke, Michael B. James, and Nadia Polikarpova. Grounded copilot: How program- mers interact with code-generating models.arXiv preprint arXiv:2206.15000,
-
[5]
Springer-Verlag, Berlin, Heidelberg,
[Brabazon and O’Neill, 2006] Anthony Brabazon and Michael O’Neill.Biologically inspired algorithms for financial modelling. Springer-Verlag, Berlin, Heidelberg,
2006
-
[6]
An introduction to evolu- tionary computation in finance.IEEE Computational Intelligence Magazine, 3(4):42–55,
[Brabazonet al., 2008 ] Anthony Brabazon, Michael O’Neill, and Ian Dempsey. An introduction to evolu- tionary computation in finance.IEEE Computational Intelligence Magazine, 3(4):42–55,
2008
-
[7]
Chang, N
[Changet al., 2000 ] T.-J. Chang, N. Meade, J. E. Beasley, and Y . M. Sharaiha. Heuristics for cardinality constrained portfolio optimisation.Computers and Operations Re- search, 27(13):1271–1302, November
2000
-
[8]
Decision Transformer: Reinforcement Learning via Sequence Modeling
[Chenet al., 2021 ] Lili Chen, Kevin Lu, Aravind Ra- jeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. De- cision transformer: Reinforcement learning via sequence modeling.arXiv preprint arXiv:2106.01345,
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
John Wiley & Sons,
[De Prado, 2018] Marcos Lopez De Prado.Advances in fi- nancial machine learning. John Wiley & Sons,
2018
-
[10]
Codemonkeys: Scaling test-time compute for software engineering.arXiv preprint arXiv:2501.14723,
[Ehrlichet al., 2025 ] Ryan Ehrlich, Bradley Brown, Jor- dan Juravsky, Ronald Clark, Christopher R ´e, and Azalia Mirhoseini. Codemonkeys: Scaling test-time compute for software engineering.arXiv preprint arXiv:2501.14723,
-
[11]
Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution
[Fernandoet al., 2023 ] Chrisantha Fernando, Dylan Ba- narse, Henryk Michalewski, Simon Osindero, and Tim Rockt¨aschel. Promptbreeder: Self-referential self- improvement via prompt evolution.arXiv preprint arXiv:2309.16797,
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Recent advances in reinforcement learning in finance.Mathematical Finance, 33(3):437–503,
[Hamblyet al., 2023 ] Ben Hambly, Renyuan Xu, and Huin- ing Yang. Recent advances in reinforcement learning in finance.Mathematical Finance, 33(3):437–503,
2023
-
[13]
Meta-learning in neural networks: A survey.IEEE Transactions on Pat- tern Analysis and Machine Intelligence, 44(9):5149–5169,
[Hospedaleset al., 2022 ] Timothy Hospedales, Antreas An- toniou, Paul Micaelli, and Amos Storkey. Meta-learning in neural networks: A survey.IEEE Transactions on Pat- tern Analysis and Machine Intelligence, 44(9):5149–5169,
2022
-
[14]
Population Based Training of Neural Networks
[Jaderberget al., 2017 ] Max Jaderberg, Valentin Dalibard, Simon Osindero, Wojciech M. Czarnecki, Jeff Don- ahue, Ali Razavi, Oriol Vinyals, Tim Green, Iain Dun- ning, Karen Simonyan, Chrisantha Fernando, and Koray Kavukcuoglu. Population based training of neural net- works.arXiv preprint arXiv:1711.09846,
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[15]
Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
[Jinet al., 2023 ] Ming Jin, Shifan Wang, Lintao Ma, Zhix- uan Chu, James Y Zhang, Xiaoming Shi, Pin-Yu Chen, and Shirui Pan. Time-llm: Time series forecasting by reprogramming large language models.arXiv preprint arXiv:2310.01728,
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
MIT Press,
[Koza, 1992] John R Koza.Genetic Programming: On the Programming of Computers by Means of Natural Selec- tion. MIT Press,
1992
-
[17]
[Liet al., 2023 ] Yang Li, Yangyang Yu, Haohang Li, Zhi Chen, and Khaldoun Khashanah. Tradinggpt: multi-agent system with layered memory and distinct characters for enhanced financial trading performance.arXiv preprint arXiv:2309.03736,
-
[18]
Guiding enumerative program synthesis with large language models
[Liet al., 2024 ] Yixuan Li, Julian Parsert, and Elizabeth Pol- green. Guiding enumerative program synthesis with large language models. InProceedings of the International Con- ference on Computer Aided Verification,
2024
-
[19]
Time-series forecasting with deep learning: a sur- vey.Philosophical Transactions of the Royal Society A, 379(2194):20200209,
[Lim and Zohren, 2021] Bryan Lim and Stefan Zohren. Time-series forecasting with deep learning: a sur- vey.Philosophical Transactions of the Royal Society A, 379(2194):20200209,
2021
-
[20]
High-frequency trading from an evolutionary perspective: Financial markets as adaptive systems.International Journal of Finance & Economics, 24(2):943–962,
[Manahovet al., 2019 ] Viktor Manahov, Robert Hudson, and Andrew Urquhart. High-frequency trading from an evolutionary perspective: Financial markets as adaptive systems.International Journal of Finance & Economics, 24(2):943–962,
2019
-
[21]
Codegen: An open large language model for code with multi-turn program synthe- sis
[Nijkampet al., 2023 ] Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. Codegen: An open large language model for code with multi-turn program synthe- sis. InProceedings of the International Conference on Learning Representations,
2023
-
[22]
[Novikovet al., 2025 ] Alexander Novikov, Ngan Vu, Mar- vin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Ko- zlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. Alphaevolve: A coding agen...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Generating trading rules on the stock mar- kets with genetic programming.Computers and Opera- tions Research, 31(7):1033–1047,
[Potvinet al., 2004 ] Jean-Yves Potvin, Patrick Soriano, and Maxime Vall´ee. Generating trading rules on the stock mar- kets with genetic programming.Computers and Opera- tions Research, 31(7):1033–1047,
2004
-
[24]
So, and Quoc V
[Realet al., 2020 ] Esteban Real, Chen Liang, David R. So, and Quoc V . Le. Automl-zero: Evolving machine learning algorithms from scratch. InProceedings of the 37th Inter- national Conference on Machine Learning, pages 8007–
2020
-
[25]
Pawan Kumar, Emilien Dupont, Francisco J
[Romera-Paredeset al., 2024 ] Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M. Pawan Kumar, Emilien Dupont, Francisco J. R. Ruiz, Jordan S. Ellenberg, Pengming Wang, Omar Fawzi, Pushmeet Kohli, and Alhussein Fawzi. Mathematical dis- coveries from program search with large language models. Nature, 625:468–475,
2024
-
[26]
[Songet al., 2025 ] Zifan Song, Kaitao Song, Guosheng Hu, Ding Qi, Junyao Gao, Xiaohua Wang, Dongsheng Li, and Cairong Zhao. Trade in minutes!: Rationality-driven agen- tic system for quantitative financial trading.arXiv preprint arXiv:2510.04787,
-
[27]
Stanley and Risto Miikkulainen
[Stanley and Miikkulainen, 2002] Kenneth O. Stanley and Risto Miikkulainen. Evolving neural networks through augmenting topologies.Evolutionary Computation, 10(2):99–127,
2002
-
[28]
Chi, Quoc V
[Weiet al., 2022 ] Jason Wei, Xuezhi Wang, Dale Schuur- mans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompt- ing elicits reasoning in large language models. InAd- vances in Neural Information Processing Systems, vol- ume 35, pages 24824–24837,
2022
-
[29]
BloombergGPT: A Large Language Model for Finance
[Wuet al., 2023 ] Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prab- hanjan Kambadur, David Rosenberg, and Gideon Mann. Bloomberggpt: A large language model for finance.arXiv preprint arXiv:2303.17564,
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
[Wuet al., 2025 ] Siyi Wu, Junqiao Wang, Zhaoyang Guan, Leyi Zhao, Xinyuan Song, Xinyu Ying, Dexu Yu, Jin- hao Wang, Hanlin Zhang, Michele Pak, Yangfan He, Yi Xin, Jianhui Wang, and Tianyu Shi. Mountain- lion: A multi-modal LLM-based agent system for inter- pretable and adaptive financial trading.arXiv preprint arXiv:2507.20474,
-
[31]
Smith, Xiao-Yang Liu, Jimin Huang, Sophia Ananiadou, and Qianqian Xie
[Xionget al., 2025 ] Guojun Xiong, Zhiyang Deng, Keyi Wang, Yupeng Cao, Haohang Li, Yangyang Yu, Xueqing Peng, Mingquan Lin, Kaleb E. Smith, Xiao-Yang Liu, Jimin Huang, Sophia Ananiadou, and Qianqian Xie. Flag- trader: Fusion llm-agent with gradient-based reinforce- ment learning for financial trading. InFindings of the As- sociation for Computational Lin...
2025
-
[32]
Large Language Models as Optimizers
[Yanget al., 2023a ] Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V . Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers.arXiv preprint arXiv:2309.03409,
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
arXiv preprint arXiv:2306.06031 , year=
[Yanget al., 2023b ] Hongyang Yang, Xiao-Yang Liu, and Christina Dan Wang. Fingpt: Open-source financial large language models.arXiv preprint arXiv:2306.06031,
-
[34]
[Yuet al., 2023 ] Yangyang Yu, Zhiyuan Yao, Haohang Li, et al. Finmem: A multimodal agent with hierarchical memory for financial decision making.arXiv preprint arXiv:2311.11300,
-
[35]
Suchow, Zhenyu Cui, Rong Liu, Zhaozhuo Xu, Denghui Zhang, Koduvayur Subbalakshmi, Guojun Xiong, Yueru He, Jimin Huang, Dong Li, and Qianqian Xie
[Yuet al., 2025 ] Yangyang Yu, Zhiyuan Yao, Haohang Li, Zhiyang Deng, Yuechen Jiang, Yupeng Cao, Zhi Chen, Jordan W. Suchow, Zhenyu Cui, Rong Liu, Zhaozhuo Xu, Denghui Zhang, Koduvayur Subbalakshmi, Guojun Xiong, Yueru He, Jimin Huang, Dong Li, and Qianqian Xie. FinCon: A synthesized LLM multi-agent system with conceptual verbal reinforcement for enhanced...
2025
-
[36]
[Zhanget al., 2020 ] Zihao Zhang, Stefan Zohren, and Stephen J. Roberts. Deep reinforcement learning for trad- ing.The Journal of Financial Data Science, 2(2):25–40,
2020
-
[37]
A multimodal foundation agent for financial trading: Tool-augmented, diversified, and gen- eralist
[Zhanget al., 2024 ] Wentao Zhang, Lingxuan Zhao, Hao- chong Xia, Shuo Sun, Jiaze Sun, Molei Qin, Xinyi Li, Yuqing Zhao, Yilei Zhao, Xinyu Cai, Yifan Zhang, Xin- run Wang, and Bo An. A multimodal foundation agent for financial trading: Tool-augmented, diversified, and gen- eralist. InProceedings of the 30th ACM SIGKDD Con- ference on Knowledge Discovery a...
2024
-
[38]
[Zhaoet al., 2025 ] Li Zhao, Rui Sun, Zuoyou Jiang, Bo Yang, Yuxiao Bai, Mengting Chen, Xinyang Wang, Jing Li, and Zuo Bai. Contesttrade: A multi-agent trad- ing system based on internal contest mechanism.arXiv preprint arXiv:2508.00554, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.