LL-Bench: Rethinking Low-Level Vision Evaluation in the Era of Large-Scale Generative Models
Pith reviewed 2026-06-28 14:39 UTC · model grok-4.3
The pith
LL-Bench shows generative models add hallucinations during image restoration while conventional methods better preserve accurate details.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
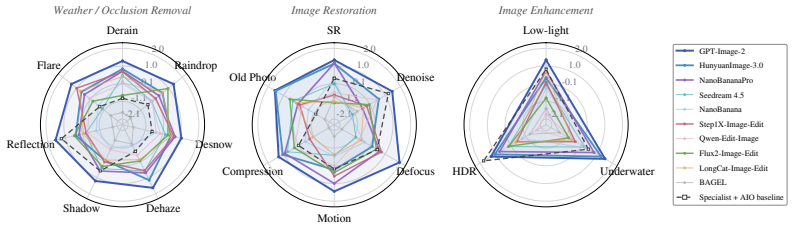
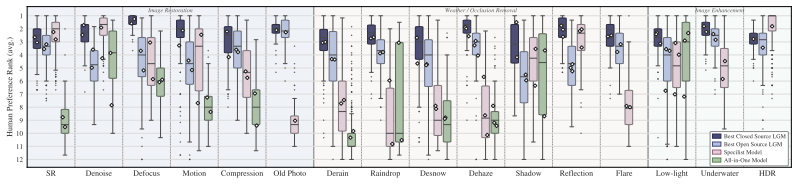
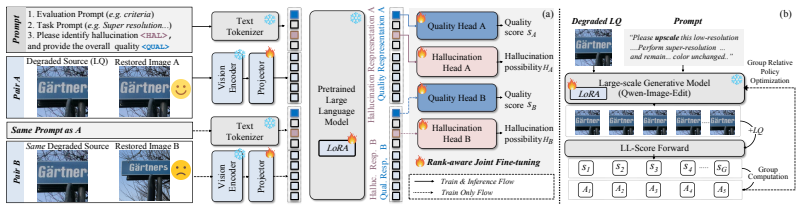
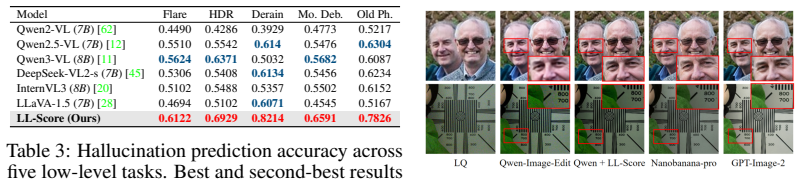
LL-Bench supplies the first large-scale human-annotated dataset for low-level vision evaluation of generative models and reveals their systematic failure modes, including hallucination of nonexistent content. LL-Score, an MLLM-based evaluator, captures both restoration quality and hallucination existence more reliably than prior image quality assessment metrics and doubles as a reward model for training.
What carries the argument
LL-Score, an MLLM-based evaluator that jointly scores restoration quality and detects hallucination existence.
If this is right
- Generative models require additional constraints to avoid introducing false content in pixel-precise restoration tasks.
- Standard image quality assessment metrics cannot be trusted for ranking generative outputs on low-level vision problems.
- LL-Score can be inserted directly into reinforcement learning loops to train generative models that produce fewer hallucinations.
- Future low-level benchmarks must separately measure hallucination in addition to overall visual quality.
Where Pith is reading between the lines
- Hybrid systems that combine generative priors with conventional restoration priors may close the observed performance gap.
- The same MLLM evaluation approach could transfer to video restoration or other domains where detail accuracy matters.
- Scaling laws for generative models may not hold for tasks that demand strict fidelity to input pixels.
Load-bearing premise
The 152,020 expert pairwise preferences and 28,334 quality scores form reliable, unbiased ground truth for restoration quality and hallucination detection.
What would settle it
A second independent collection of expert annotations on the identical set of restored images that produces substantially different preference orderings or quality score distributions.
Figures

read the original abstract
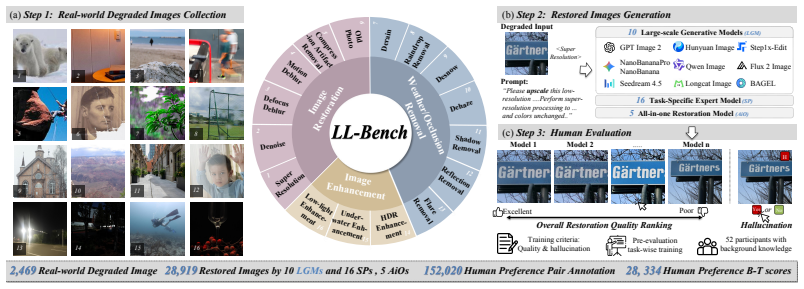
Large-scale generative models have demonstrated remarkable capabilities across image generation and editing tasks. However, their performance in low-level vision tasks, which require pixel-wise control, remains insufficiently studied. To address this gap, we introduce \textbf{LL-Bench}, a comprehensive \textbf{Benchmark} for evaluating the capabilities of large-scale generative models on \textbf{L}ow-\textbf{L}evel vision tasks. The benchmark comprises 2,469 real-world degraded images covering 16 low-level degradation tasks, and 28,919 restored images produced by 10 state-of-the-art large-scale generative models and 21 conventional restoration models, which are annotated with 152,020 expert-level pairwise human preferences and 28,334 quality scores. Built upon LL-Bench, we present a systematic diagnosis that reveals the performance boundaries and unique failure modes of large-scale generative models across diverse low-level vision tasks, compared with conventional representative restoration approaches. Moreover, we investigate the effectiveness of current quality evaluation metrics on LL-Bench, which exhibit significant discrepancy with human ratings. To better align restored-image quality assessment with human preferences, we further propose \textbf{LL-Score}, an MLLM-based evaluator that captures both restoration quality and hallucination existence. Extensive experiments demonstrate that LL-score not only outperforms existing image quality assessment metrics, but also serves as a promising reward model for training generative models on low-level vision tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LL-Bench, a benchmark comprising 2,469 real-world degraded images across 16 low-level tasks and 28,919 restored images generated by 10 large-scale generative models plus 21 conventional restorers. These are annotated with 152,020 expert pairwise human preferences and 28,334 quality scores. The work diagnoses performance boundaries and failure modes (including hallucinations) of generative models versus conventional approaches, shows that existing IQA metrics disagree with human ratings, and proposes LL-Score, an MLLM-based evaluator that jointly assesses restoration quality and hallucination presence, claiming superior alignment with humans and utility as a reward model for training.
Significance. If the human annotations are shown to be reliable, LL-Bench would provide a valuable large-scale resource for evaluating low-level vision capabilities of generative models, and LL-Score could offer a practical human-aligned alternative to existing IQA metrics with additional utility in reward modeling. The scale of the collected preferences and the explicit inclusion of hallucination detection are concrete strengths that go beyond typical IQA benchmarks.
major comments (3)
- [§3.2] Human annotation protocol (Section 3.2): The manuscript states that 152,020 pairwise preferences and 28,334 quality scores were collected from experts but supplies no information on inter-rater agreement, statistical testing, data splits, annotation guidelines for distinguishing hallucinations from artifacts, or bias controls. This is load-bearing because every claim that LL-Score outperforms existing IQA metrics and functions as a reward model rests on these annotations constituting reliable, unbiased ground truth.
- [§5] LL-Score evaluation experiments (Section 5): The reported superiority of LL-Score is presented without specifying the exact correlation coefficients (PLCC/SRCC/KRCC), whether evaluation was performed on held-out images never seen during any MLLM adaptation, or the precise prompting strategy used to elicit quality and hallucination scores. These omissions prevent verification that the alignment is not an artifact of the same data used to construct the benchmark.
- [§6] Reward-model experiments (Section 6): The claim that LL-Score is a "promising reward model" is supported only by qualitative statements; no quantitative results (e.g., improvement in downstream restoration metrics, comparison against standard reward baselines, or statistical significance) are provided to substantiate the utility for training generative models.
minor comments (3)
- [Abstract] The abstract lists 28,919 restored images while the introduction states 28,919; ensure exact consistency with the tables that enumerate per-model outputs.
- [§3.1] Clarify whether the 2,469 degraded images are partitioned into training/validation/test splits for the LL-Score experiments or whether all annotations are used for both benchmark construction and metric validation.
- [Figure 4] Figure captions for the qualitative examples should explicitly label which images contain hallucinations versus restoration artifacts according to the human guidelines.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will incorporate revisions to improve the clarity and completeness of the manuscript.
read point-by-point responses
-
Referee: [§3.2] Human annotation protocol (Section 3.2): The manuscript states that 152,020 pairwise preferences and 28,334 quality scores were collected from experts but supplies no information on inter-rater agreement, statistical testing, data splits, annotation guidelines for distinguishing hallucinations from artifacts, or bias controls. This is load-bearing because every claim that LL-Score outperforms existing IQA metrics and functions as a reward model rests on these annotations constituting reliable, unbiased ground truth.
Authors: We agree that the current manuscript lacks sufficient detail on the annotation protocol. In the revised version, we will add inter-rater agreement metrics (e.g., Fleiss' kappa computed across experts for pairwise preferences), descriptions of statistical testing, explicit data splits, expanded annotation guidelines that define criteria for distinguishing hallucinations from other artifacts, and bias mitigation steps such as randomized image ordering and expert screening procedures. These additions will directly support the reliability of the annotations as ground truth. revision: yes
-
Referee: [§5] LL-Score evaluation experiments (Section 5): The reported superiority of LL-Score is presented without specifying the exact correlation coefficients (PLCC/SRCC/KRCC), whether evaluation was performed on held-out images never seen during any MLLM adaptation, or the precise prompting strategy used to elicit quality and hallucination scores. These omissions prevent verification that the alignment is not an artifact of the same data used to construct the benchmark.
Authors: We will revise Section 5 to explicitly report the PLCC, SRCC, and KRCC values. All correlation evaluations were performed on held-out images that were never used for MLLM adaptation or prompt design. The revised manuscript will also include the exact prompting templates employed for joint quality and hallucination scoring. These clarifications will enable full verification that the reported gains reflect genuine alignment rather than data overlap. revision: yes
-
Referee: [§6] Reward-model experiments (Section 6): The claim that LL-Score is a "promising reward model" is supported only by qualitative statements; no quantitative results (e.g., improvement in downstream restoration metrics, comparison against standard reward baselines, or statistical significance) are provided to substantiate the utility for training generative models.
Authors: We acknowledge that the current presentation of the reward-model experiments is limited to qualitative observations. In the revision, we will augment Section 6 with quantitative results, including measured improvements in downstream low-level restoration metrics when LL-Score is used as a reward versus standard baselines, direct comparisons against alternative reward models, and statistical significance testing. This will provide concrete evidence supporting the utility claim. revision: yes
Circularity Check
No circularity: empirical benchmark construction and evaluator validation
full rationale
The paper constructs LL-Bench from real-world images, generates restorations, and collects independent human pairwise preferences (152,020) and quality scores (28,334) as ground truth. LL-Score is proposed as an MLLM-based evaluator and validated empirically by direct comparison against existing IQA metrics on this held-out annotation set. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The superiority claims rest on external human judgments rather than reducing to quantities defined or fitted from the same inputs by construction. This is standard empirical benchmark work and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert pairwise human preferences reliably capture restoration quality and hallucination presence across diverse degradation types.
invented entities (2)
-
LL-Bench
no independent evidence
-
LL-Score
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Bagel.https://huggingface.co/ByteDance-Seed/BAGEL-7B-MoT/tree/main
-
[2]
https://huggingface.co/black-forest-labs/FLUX.2-dev/tree/ main
Flux2-image-edit. https://huggingface.co/black-forest-labs/FLUX.2-dev/tree/ main
-
[3]
Gpt-image-2.https://openai.com/index/introducing-chatgpt-images-2-0/
-
[4]
https://huggingface.co/tencent/HunyuanImage-3.0-Instruc t-Distil
Hunyuan-image-3.0. https://huggingface.co/tencent/HunyuanImage-3.0-Instruc t-Distil
-
[5]
Longcat-image-edit.https://huggingface.co/meituan-longcat
-
[6]
https://ai.google.dev/gemini-api/docs/models/gemini-2.5-fla sh-image,
Nanobanana. https://ai.google.dev/gemini-api/docs/models/gemini-2.5-fla sh-image,
-
[7]
Nanobananapro.https://aistudio.google.com/models/gemini-3-pro-image,
-
[8]
https://huggingface.co/Qwen/Qwen-Image-Edit/tree/mai n
Qwen-image-edit-2511. https://huggingface.co/Qwen/Qwen-Image-Edit/tree/mai n
-
[9]
Seedream 4.5.https://modelslab.com/seedream-45
-
[10]
Step1x-image-edit.https://huggingface.co/stepfun-ai/Step1X-Edit/tree/main
-
[11]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[12]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report, 2025.URL https://arxiv. org/abs/2502.13923, 6:13–23, 2025
Pith/arXiv arXiv 2025
-
[13]
The perception-distortion tradeoff
Yochai Blau and Tomer Michaeli. The perception-distortion tradeoff. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6228–6237, 2018. doi: 10.1109/CVPR.2018.00652
-
[14]
Rank analysis of incomplete block designs: I
Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39(3/4):324–345, 1952
1952
-
[15]
Toward real-world single image super-resolution: A new benchmark and a new model
Jianrui Cai, Hui Zeng, Hongwei Yong, Zisheng Cao, and Lei Zhang. Toward real-world single image super-resolution: A new benchmark and a new model. InProceedings of the IEEE/CVF international conference on computer vision, pages 3086–3095, 2019
2019
-
[16]
Topiq: A top-down approach from semantics to distortions for image quality assessment.IEEE Transactions on Image Processing, 33:2404–2418, 2024
Chaofeng Chen, Jiadi Mo, Jingwen Hou, Haoning Wu, Liang Liao, Wenxiu Sun, Qiong Yan, and Weisi Lin. Topiq: A top-down approach from semantics to distortions for image quality assessment.IEEE Transactions on Image Processing, 33:2404–2418, 2024
2024
-
[17]
Toward generalized image quality assessment: Relaxing the perfect reference quality assumption
Du Chen, Tianhe Wu, Kede Ma, and Lei Zhang. Toward generalized image quality assessment: Relaxing the perfect reference quality assumption. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12742–12752, 2025
2025
-
[18]
Unirestore: Unified perceptual and task-oriented image restoration model using diffusion prior
I Chen, Wei-Ting Chen, Yu-Wei Liu, Yuan-Chun Chiang, Sy-Yen Kuo, Ming-Hsuan Yang, et al. Unirestore: Unified perceptual and task-oriented image restoration model using diffusion prior. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17969–17979, 2025
2025
-
[19]
Tokenize image patches: Global context fusion for effective haze removal in large images
Jiuchen Chen, Xinyu Yan, Qizhi Xu, and Kaiqi Li. Tokenize image patches: Global context fusion for effective haze removal in large images. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2258–2268, 2025
2025
-
[20]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024. 10
2024
-
[21]
Hierarchical integration diffusion model for realistic image deblurring.Advances in neural information processing systems, 36:29114–29125, 2023
Zheng Chen, Yulun Zhang, Ding Liu, Jinjin Gu, Linghe Kong, Xin Yuan, et al. Hierarchical integration diffusion model for realistic image deblurring.Advances in neural information processing systems, 36:29114–29125, 2023
2023
-
[22]
Instructir: High-quality image restoration following human instructions
Marcos V Conde, Gregor Geigle, and Radu Timofte. Instructir: High-quality image restoration following human instructions. InEuropean Conference on Computer Vision, pages 1–21. Springer, 2024
2024
-
[23]
Image quality assessment: Unifying structure and texture similarity.IEEE transactions on pattern analysis and machine intelligence, 44(5):2567–2581, 2020
Keyan Ding, Kede Ma, Shiqi Wang, and Eero P Simoncelli. Image quality assessment: Unifying structure and texture similarity.IEEE transactions on pattern analysis and machine intelligence, 44(5):2567–2581, 2020
2020
-
[24]
Learning a deep convolutional network for image super-resolution
Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang. Learning a deep convolutional network for image super-resolution. InProceedings of the European Conference on Computer Vision, pages 184–199, 2014
2014
-
[25]
Channel consistency prior and self-reconstruction strategy based unsupervised image deraining
Guanglu Dong, Tianheng Zheng, Yuanzhouhan Cao, Linbo Qing, and Chao Ren. Channel consistency prior and self-reconstruction strategy based unsupervised image deraining. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 7469–7479, 2025
2025
-
[26]
Dit4sr: Taming diffusion transformer for real-world image super-resolution
Zheng-Peng Duan, Jiawei Zhang, Xin Jin, Ziheng Zhang, Zheng Xiong, Dongqing Zou, Jimmy S Ren, Chunle Guo, and Chongyi Li. Dit4sr: Taming diffusion transformer for real-world image super-resolution. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18948–18958, 2025
2025
-
[27]
Yushun Fang, Yuxiang Chen, Shibo Yin, Qiang Hu, Jiangchao Yao, Ya Zhang, Xiaoyun Zhang, and Yanfeng Wang. One-step diffusion transformer for controllable real-world image super- resolution.arXiv preprint arXiv:2511.17138, 2025
arXiv 2025
-
[28]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[29]
Compression-aware one-step diffusion model for jpeg artifact removal
Jinpei Guo, Zheng Chen, Wenbo Li, Yong Guo, and Yulun Zhang. Compression-aware one-step diffusion model for jpeg artifact removal. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14930–14939, 2025
2025
-
[30]
Answering the call for a standard reliability measure for coding data.Communication methods and measures, 1(1):77–89, 2007
Andrew F Hayes and Klaus Krippendorff. Answering the call for a standard reliability measure for coding data.Communication methods and measures, 1(1):77–89, 2007
2007
-
[31]
Global structure- aware diffusion process for low-light image enhancement.Advances in Neural Information Processing Systems, 36:79734–79747, 2023
Jinhui Hou, Zhiyu Zhu, Junhui Hou, Hui Liu, Huanqiang Zeng, and Hui Yuan. Global structure- aware diffusion process for low-light image enhancement.Advances in Neural Information Processing Systems, 36:79734–79747, 2023
2023
-
[32]
Deflaremamba: Hierarchical vision mamba for contextually consistent lens flare removal
Yihang Huang, Yuanfei Huang, Junhui Lin, and Hua Huang. Deflaremamba: Hierarchical vision mamba for contextually consistent lens flare removal. InProceedings of the 33rd ACM International Conference on Multimedia, pages 8028–8037, 2025
2025
-
[33]
Single image super-resolution quality assessment: A real-world dataset, subjective studies, and an objective metric.IEEE Transactions on Image Processing, 31:2279–2294, 2022
Qiuping Jiang, Zhentao Liu, Ke Gu, Feng Shao, Xinfeng Zhang, Hantao Liu, and Weisi Lin. Single image super-resolution quality assessment: A real-world dataset, subjective studies, and an objective metric.IEEE Transactions on Image Processing, 31:2279–2294, 2022
2022
-
[34]
Pipal: a large-scale image quality assessment dataset for perceptual image restoration
Gu Jinjin, Cai Haoming, Chen Haoyu, Ye Xiaoxing, Jimmy S Ren, and Dong Chao. Pipal: a large-scale image quality assessment dataset for perceptual image restoration. InEuropean conference on computer vision, pages 633–651. Springer, 2020
2020
-
[35]
Musiq: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 5148–5157, 2021
2021
-
[36]
Idf: Iterative dy- namic filtering networks for generalizable image denoising
Dongjin Kim, Jaekyun Ko, Muhammad Kashif Ali, and Tae Hyun Kim. Idf: Iterative dy- namic filtering networks for generalizable image denoising. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12180–12190, 2025. 11
2025
-
[37]
Efficient visual state space model for image deblurring
Lingshun Kong, Jiangxin Dong, Jinhui Tang, Ming-Hsuan Yang, and Jinshan Pan. Efficient visual state space model for image deblurring. InProceedings of the computer vision and pattern recognition conference, pages 12710–12719, 2025
2025
-
[38]
Snowmaster: Comprehensive real-world image desnowing via mllm with multi-model feedback optimization
Jianyu Lai, Sixiang Chen, Yunlong Lin, Tian Ye, Yun Liu, Song Fei, Zhaohu Xing, Hongtao Wu, Weiming Wang, and Lei Zhu. Snowmaster: Comprehensive real-world image desnowing via mllm with multi-model feedback optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4302–4312, 2025
2025
-
[39]
Iterative filter adaptive network for single image defocus deblurring
Junyong Lee, Hyeongseok Son, Jaesung Rim, Sunghyun Cho, and Seungyong Lee. Iterative filter adaptive network for single image defocus deblurring. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2034–2042, 2021
2034
-
[40]
Foundir: Unleashing million-scale training data to advance foundation models for image restoration
Hao Li, Xiang Chen, Jiangxin Dong, Jinhui Tang, and Jinshan Pan. Foundir: Unleashing million-scale training data to advance foundation models for image restoration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12626–12636, 2025
2025
-
[41]
Swinir: Image restoration using swin transformer
Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration using swin transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision Workshops, pages 1833–1844, 2021
2021
-
[42]
Kadid-10k: A large-scale artificially distorted iqa database
Hanhe Lin, Vlad Hosu, and Dietmar Saupe. Kadid-10k: A large-scale artificially distorted iqa database. In2019 Eleventh International Conference on Quality of Multimedia Experience (QoMEX), pages 1–3. IEEE, 2019
2019
-
[43]
In: Mulder, V., Mermoud, A., Lenders, V., Tellenbach, B
Xinqi Lin, Jingwen He, Ziyan Chen, Zhaoyang Lyu, Bo Dai, Fanghua Yu, Yu Qiao, Wanli Ouyang, and Chao Dong. Diffbir: Toward blind image restoration with generative diffusion prior. InProceedings of the European Conference on Computer Vision, 2024. doi: 10.1007/97 8-3-031-73202-7_25
work page doi:10.1007/97 2024
-
[44]
Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470, 2025
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470, 2025
Pith/arXiv arXiv 2025
-
[45]
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Hao Yang, et al. Deepseek-vl: towards real-world vision-language under- standing.arXiv preprint arXiv:2403.05525, 2024
Pith/arXiv arXiv 2024
-
[46]
Ziwei Luo, Fredrik K Gustafsson, Zheng Zhao, Jens Sjölund, and Thomas B Schön. Controlling vision-language models for universal image restoration.arXiv preprint arXiv:2310.01018, 3(8), 2023
arXiv 2023
-
[47]
Hpsv3: Towards wide-spectrum hu- man preference score
Yuhang Ma, Xiaoshi Wu, Keqiang Sun, and Hongsheng Li. Hpsv3: Towards wide-spectrum hu- man preference score. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15086–15095, 2025
2025
-
[48]
No-reference image quality assessment in the spatial domain.IEEE Transactions on image processing, 21(12):4695–4708, 2012
Anish Mittal, Anush Krishna Moorthy, and Alan Conrad Bovik. No-reference image quality assessment in the spatial domain.IEEE Transactions on image processing, 21(12):4695–4708, 2012
2012
-
[49]
completely blind
Anish Mittal, Rajiv Soundararajan, and Alan C Bovik. Making a “completely blind” image quality analyzer.IEEE Signal Processing Letters, 20(3):209–212, 2012
2012
-
[50]
Khan, and Fahad Shahbaz Khan
Vaishnav Potlapalli, Syed Waqas Zamir, Salman H. Khan, and Fahad Shahbaz Khan. Promptir: Prompting for all-in-one image restoration. InAdvances in Neural Information Processing Systems, volume 36, pages 71275–71293, 2023
2023
-
[51]
Attentive generative adversarial network for raindrop removal from a single image
Rui Qian, Robby T Tan, Wenhan Yang, Jiajun Su, and Jiaying Liu. Attentive generative adversarial network for raindrop removal from a single image. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2482–2491, 2018. 12
2018
-
[52]
Neumann network with recursive kernels for single image defocus deblurring
Yuhui Quan, Zicong Wu, and Hui Ji. Neumann network with recursive kernels for single image defocus deblurring. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5754–5763, 2023
2023
-
[53]
Real-world blur dataset for learning and benchmarking deblurring algorithms
Jaesung Rim, Haeyun Lee, Jucheol Won, and Sunghyun Cho. Real-world blur dataset for learning and benchmarking deblurring algorithms. InEuropean conference on computer vision, pages 184–201. Springer, 2020
2020
-
[54]
Chitwan Saharia, Jonathan Ho, William Chan, Tim Salimans, David J. Fleet, and Mohammad Norouzi. Image super-resolution via iterative refinement.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(4):4713–4726, 2023. doi: 10.1109/TPAMI.2022.3204461
-
[55]
Methodology for the subjective assessment of the quality of television pictures
B Series. Methodology for the subjective assessment of the quality of television pictures. Recommendation ITU-R BT, 500(13), 2012
2012
-
[56]
Fine-grained image quality assessment for perceptual image restoration
Xiangfei Sheng, Xiaofeng Pan, Zhichao Yang, Pengfei Chen, and Leida Li. Fine-grained image quality assessment for perceptual image restoration. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 8914–8922, 2026
2026
-
[57]
Blindly assess image quality in the wild guided by a self-adaptive hyper network
Shaolin Su, Qingsen Yan, Yu Zhu, Cheng Zhang, Xin Ge, Jinqiu Sun, and Yanning Zhang. Blindly assess image quality in the wild guided by a self-adaptive hyper network. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3664–3673,
-
[58]
doi: 10.1109/CVPR42600.2020.00372
-
[59]
Underwater image enhancement by transformer-based diffusion model with non-uniform sampling for skip strategy
Yi Tang, Hiroshi Kawasaki, and Takafumi Iwaguchi. Underwater image enhancement by transformer-based diffusion model with non-uniform sampling for skip strategy. InProceedings of the 31st ACM international conference on multimedia, pages 5419–5427, 2023
2023
-
[60]
Degradation-aware feature perturbation for all-in-one image restoration
Xiangpeng Tian, Xiangyu Liao, Xiao Liu, Meng Li, and Chao Ren. Degradation-aware feature perturbation for all-in-one image restoration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 28165–28175, 2025
2025
-
[61]
Old photo restora- tion via deep latent space translation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(2):2071–2087, 2022
Ziyu Wan, Bo Zhang, Dong Chen, Pan Zhang, Fang Wen, and Jing Liao. Old photo restora- tion via deep latent space translation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(2):2071–2087, 2022
2071
-
[62]
Exploring clip for assessing the look and feel of images
Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. Exploring clip for assessing the look and feel of images. InProceedings of the AAAI conference on artificial intelligence, volume 37, pages 2555–2563, 2023
2023
-
[63]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
Pith/arXiv arXiv 2024
-
[64]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4): 600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4): 600–612, 2004
2004
-
[65]
Deep retinex decomposition for low-light enhancement.arXiv preprint arXiv:1808.04560, 2018
Chen Wei, Wenjing Wang, Wenhan Yang, and Jiaying Liu. Deep retinex decomposition for low-light enhancement.arXiv preprint arXiv:1808.04560, 2018
Pith/arXiv arXiv 2018
-
[66]
Component divide-and-conquer for real-world image super-resolution
Pengxu Wei, Ziwei Xie, Hannan Lu, Zongyuan Zhan, Qixiang Ye, Wangmeng Zuo, and Liang Lin. Component divide-and-conquer for real-world image super-resolution. InEuropean conference on computer vision, pages 101–117. Springer, 2020
2020
-
[67]
Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
Pith/arXiv arXiv 2025
-
[68]
Haoning Wu, Zicheng Zhang, Weixia Zhang, Chaofeng Chen, Liang Liao, Chunyi Li, Yixuan Gao, Annan Wang, Erli Zhang, Wenxiu Sun, et al. Q-align: Teaching lmms for visual scoring via discrete text-defined levels.arXiv preprint arXiv:2312.17090, 2023. 13
Pith/arXiv arXiv 2023
-
[69]
Keming Wu, Sicong Jiang, Max Ku, Ping Nie, Minghao Liu, and Wenhu Chen. Editre- ward: A human-aligned reward model for instruction-guided image editing.arXiv preprint arXiv:2509.26346, 2025
arXiv 2025
-
[70]
Detail-preserving latent diffusion for stable shadow removal
Jiamin Xu, Yuxin Zheng, Zelong Li, Chi Wang, Renshu Gu, Weiwei Xu, and Gang Xu. Detail-preserving latent diffusion for stable shadow removal. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7592–7602, 2025
2025
-
[71]
Imagereward: Learning and evaluating human preferences for text-to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems, 36:15903–15935, 2023
2023
-
[72]
Hvi: A new color space for low-light image enhancement.(2025)
Qingsen YAN, Yixu FENG, Cheng ZHANG, Guansong PANG, Kangbiao SHI, Peng WU, Wei DONG, Jinqiu SUN, and Yanning ZHANG. Hvi: A new color space for low-light image enhancement.(2025). 2025 ieee. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11–15, 2025
2025
-
[73]
Qianfeng Yang, Qiyuan Guan, Xiang Chen, Jiyu Jin, Guiyue Jin, and Jiangxin Dong. Unirain: Unified image deraining with rag-based dataset distillation and multi-objective reweighted optimization.arXiv preprint arXiv:2603.03967, 2026
arXiv 2026
-
[74]
Maniqa: Multi-dimension attention network for no-reference image quality assessment
Sidi Yang, Tianhe Wu, Shuwei Shi, Shanshan Lao, Yuan Gong, Mingdeng Cao, Jiahao Wang, and Yujiu Yang. Maniqa: Multi-dimension attention network for no-reference image quality assessment. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1191–1200, 2022
2022
-
[75]
Xiang Yin, Jinfan Hu, Zhiyuan You, Kainan Yan, Yu Tang, Chao Dong, and Jinjin Gu. How far have we gone in generative image restoration? a study on its capability, limitations and evaluation practices.arXiv preprint arXiv:2603.05010, 2026
Pith/arXiv arXiv 2026
-
[76]
Teaching large language models to regress accurate image quality scores using score distribution
Zhiyuan You, Xin Cai, Jinjin Gu, Tianfan Xue, and Chao Dong. Teaching large language models to regress accurate image quality scores using score distribution. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14483–14494, 2025
2025
-
[77]
Daniyar Zakarin, Thiemo Wandel, Anton Obukhov, and Dengxin Dai. Reflection removal through efficient adaptation of diffusion transformers.arXiv preprint arXiv:2512.05000, 2025
arXiv 2025
-
[78]
Restormer: Efficient transformer for high-resolution image restoration
Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, and Ming-Hsuan Yang. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5728–5739, 2022
2022
-
[79]
Lookup table meets local laplacian filter: pyramid reconstruction network for tone mapping
Feng Zhang, Ming Tian, Zhiqiang Li, Bin Xu, Qingbo Lu, Changxin Gao, and Nong Sang. Lookup table meets local laplacian filter: pyramid reconstruction network for tone mapping. Advances in Neural Information Processing Systems, 36:57558–57569, 2023
2023
-
[80]
Clut-net: Learning adaptively compressed representations of 3dluts for lightweight image enhancement
Fengyi Zhang, Hui Zeng, Tianjun Zhang, and Lin Zhang. Clut-net: Learning adaptively compressed representations of 3dluts for lightweight image enhancement. InProceedings of the 30th ACM International Conference on Multimedia, pages 6493–6501, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.