Dual-State Slot Attention: Decoupling Appearance and Identity for Video Object-Centric Learning
Pith reviewed 2026-06-27 09:48 UTC · model grok-4.3
The pith
Dual-State Slot Attention separates per-frame appearance from stable identity to prevent slot swapping in unsupervised video object learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
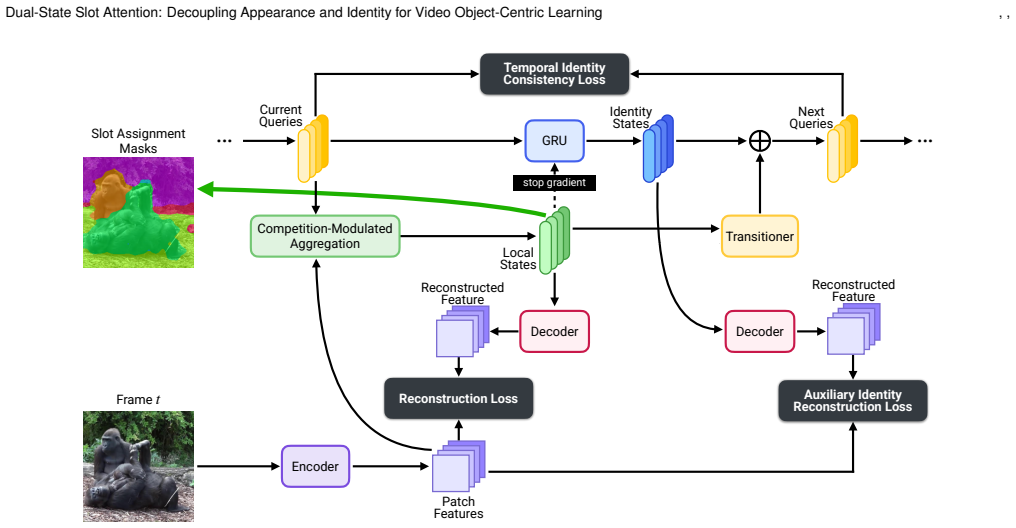
DSSA decomposes each slot into a local state for per-frame appearance and an identity state for temporally stable object information. The identity state is updated through a learned recurrent transition that acts as a temporal filter on the local state, while competition-modulated aggregation down-weights updates from weakly matching slots and prevents them from absorbing tokens from other objects.
What carries the argument
Dual-state slot decomposition into local appearance state and identity state, maintained by recurrent transition and competition-modulated aggregation.
If this is right
- Segmentation quality and temporal consistency improve over prior slot methods on MOVi-C, MOVi-D, and YouTube-VIS.
- Downstream object recognition and video dynamics prediction tasks become stronger.
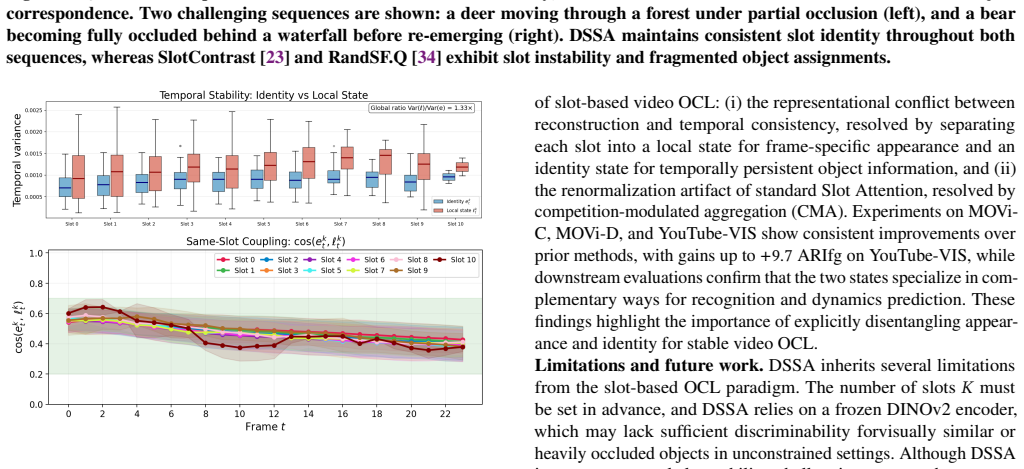
- Slot swapping from objective conflict is reduced by aligning reconstruction with the local state and consistency with the identity state.
- Weakly matching slots are prevented from destabilizing correspondence through modulated aggregation.
Where Pith is reading between the lines
- The dual-state split may reduce reliance on post-hoc tracking modules when building video models for long sequences.
- Competition-modulated aggregation could stabilize other attention-based decompositions that suffer from token absorption.
- If the recurrent filter proves robust, similar state separation might address conflicting objectives in non-video unsupervised settings such as audio scene analysis.
Load-bearing premise
The learned recurrent transition can effectively act as a temporal filter on the local state to maintain identity without supervision, and competition-modulated aggregation prevents slot destabilization.
What would settle it
An ablation that removes the identity state or the recurrent transition and shows no gain in temporal consistency metrics on MOVi-C or MOVi-D would falsify the central mechanism.
Figures



read the original abstract
Unsupervised video object-centric learning aims to decompose dynamic scenes into persistent, object-level representations without supervision. However, existing slot-based methods struggle to maintain stable object identity in challenging settings such as rapid motion and partial occlusion. First, they typically encode both the per-frame appearance of an object and its identity across frames in a single slot vector, creating an objective conflict that leads to slot swapping: reconstruction requires sensitivity to transient visual changes, whereas temporal consistency requires invariance to them. Second, the token renormalization used in Slot Attention can amplify weakly attending slots, allowing them to absorb tokens from other objects and destabilize slot-to-object correspondence. We propose Dual-State Slot Attention (DSSA), a fully self-supervised framework that addresses these limitations by separating appearance from identity and by reducing spurious updates from weakly matching slots. DSSA decomposes each slot into a local state for per-frame appearance and an identity state for temporally stable object information, thereby aligning reconstruction and temporal consistency with separate representations. The identity state is updated through a learned recurrent transition that acts as a temporal filter on the local state, while competition-modulated aggregation (CMA) down-weights updates from weakly matching slots and prevents them from absorbing tokens from other objects. Experiments on MOVi-C, MOVi-D, and YouTube-VIS demonstrate that DSSA consistently improves segmentation quality and temporal consistency over prior methods, while also yielding stronger downstream object recognition and video dynamics prediction. Code and models will be made publicly available upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Dual-State Slot Attention (DSSA), a self-supervised framework for video object-centric learning. It decomposes each slot into a local state for per-frame appearance and an identity state for temporally stable object information. The identity state is updated via a learned recurrent transition acting as a temporal filter, while competition-modulated aggregation (CMA) down-weights updates from weakly matching slots to prevent destabilization and slot swapping. Experiments on MOVi-C, MOVi-D, and YouTube-VIS report consistent improvements in segmentation quality and temporal consistency over prior methods, with benefits for downstream object recognition and video dynamics prediction.
Significance. If the empirical claims hold under rigorous controls, the separation of appearance and identity objectives could address a core limitation in slot-based video decomposition methods. The self-supervised design and promised public code release are strengths. However, without the full manuscript, the magnitude of the advance and robustness of the evidence cannot be determined.
Simulated Author's Rebuttal
We thank the referee for their review and summary of our work on Dual-State Slot Attention. The report does not list any specific major comments under the MAJOR COMMENTS section, so we provide no point-by-point responses below. We note the referee's uncertainty regarding the magnitude of the advance due to lack of the full manuscript at the time of review; the complete manuscript text is now available.
Circularity Check
No significant circularity; derivation self-contained
full rationale
The abstract presents DSSA as a new architecture that decomposes slots into local and identity states, with a learned recurrent transition and competition-modulated aggregation as explicit mechanisms. No equations or claims reduce a result to its own inputs by construction, no self-citation chains are invoked as load-bearing uniqueness theorems, and no fitted parameters are relabeled as predictions. The framework is positioned as addressing objective conflicts via architectural separation, with validation on external datasets (MOVi-C, MOVi-D, YouTube-VIS). Absent any quoted reduction of the central claim to a tautology or self-referential fit, the derivation chain is independent.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2209.14860 , year=
Bridging the gap to real-world object-centric learning , author=. arXiv preprint arXiv:2209.14860 , year=
-
[2]
Advances in Neural Information Processing Systems , volume=
Slotdiffusion: Object-centric generative modeling with diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
Advances in neural information processing systems , volume=
Object-centric learning with slot attention , author=. Advances in neural information processing systems , volume=
-
[4]
Behavioral and brain sciences , volume=
Building machines that learn and think like people , author=. Behavioral and brain sciences , volume=. 2017 , publisher=
2017
-
[5]
IEEE transactions on pattern analysis and machine intelligence , volume=
Representation learning: A review and new perspectives , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2013 , publisher=
2013
-
[6]
Advances in Neural Information Processing Systems , volume=
Savi++: Towards end-to-end object-centric learning from real-world videos , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
arXiv preprint arXiv:2111.12594 , year=
Conditional object-centric learning from video , author=. arXiv preprint arXiv:2111.12594 , year=
-
[8]
Advances in neural information processing systems , volume=
Simple unsupervised object-centric learning for complex and naturalistic videos , author=. Advances in neural information processing systems , volume=
-
[9]
arXiv preprint arXiv:2210.05861 , year=
Slotformer: Unsupervised visual dynamics simulation with object-centric models , author=. arXiv preprint arXiv:2210.05861 , year=
-
[10]
Advances in neural information processing systems , volume=
Object-centric learning for real-world videos by predicting temporal feature similarities , author=. Advances in neural information processing systems , volume=
-
[11]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Temporally consistent object-centric learning by contrasting slots , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[12]
arXiv preprint arXiv:1807.03748 , year=
Representation learning with contrastive predictive coding , author=. arXiv preprint arXiv:1807.03748 , year=
-
[13]
Machine Learning , volume=
Learning global object-centric representations via disentangled slot attention , author=. Machine Learning , volume=. 2025 , publisher=
2025
-
[14]
arXiv preprint arXiv:1901.11390 , year=
Monet: Unsupervised scene decomposition and representation , author=. arXiv preprint arXiv:1901.11390 , year=
Pith/arXiv arXiv 1901
-
[15]
International conference on machine learning , pages=
Multi-object representation learning with iterative variational inference , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[16]
Advances in Neural Information Processing Systems , volume=
Self-supervised object-centric learning for videos , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
arXiv preprint arXiv:1910.02384 , year=
Scalor: Generative world models with scalable object representations , author=. arXiv preprint arXiv:1910.02384 , year=
arXiv 1910
-
[18]
arXiv preprint arXiv:2007.06245 , year=
Reconstruction bottlenecks in object-centric generative models , author=. arXiv preprint arXiv:2007.06245 , year=
arXiv 2007
-
[19]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Emerging properties in self-supervised vision transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[20]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Pay attention to the foreground in object-centric learning , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[21]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Spot: Self-training with patch-order permutation for object-centric learning with autoregressive transformers , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[22]
Advances in Neural Information Processing Systems , volume=
Henasy: Learning to assemble scene-entities for interpretable egocentric video-language model , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Self-supervised video object segmentation by motion grouping , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[24]
arXiv preprint arXiv:2408.09162 , year=
Zero-shot object-centric representation learning , author=. arXiv preprint arXiv:2408.09162 , year=
-
[25]
arXiv preprint arXiv:2107.00637 , year=
Generalization and robustness implications in object-centric learning , author=. arXiv preprint arXiv:2107.00637 , year=
-
[26]
arXiv preprint arXiv:2001.02407 , year=
Space: Unsupervised object-oriented scene representation via spatial attention and decomposition , author=. arXiv preprint arXiv:2001.02407 , year=
arXiv 2001
-
[27]
arXiv preprint arXiv:1910.01442 , year=
Clevrer: Collision events for video representation and reasoning , author=. arXiv preprint arXiv:1910.01442 , year=
Pith/arXiv arXiv 1910
-
[28]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Kubric: A scalable dataset generator , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[29]
The 3rd large-scale video object segmentation challenge-video instance segmentation track , author=. Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit.(CVPR) Workshop , year=
-
[30]
2025 , eprint=
Predicting Video Slot Attention Queries from Random Slot-Feature Pairs , author=. 2025 , eprint=
2025
-
[31]
arXiv preprint arXiv:2506.21734 , year=
Hierarchical reasoning model , author=. arXiv preprint arXiv:2506.21734 , year=
-
[32]
arXiv preprint arXiv:2304.07193 , year=
Dinov2: Learning robust visual features without supervision , author=. arXiv preprint arXiv:2304.07193 , year=
-
[33]
Zhao, Rongzhen and Li, Jian and Kannala, Juho and Pajarinen, Joni , journal=
-
[34]
Engelcke, Martin and Kosiorek, Adam R and Parker Jones, Oiwi and Posner, Ingmar , booktitle=
-
[35]
European conference on computer vision , pages=
Microsoft coco: Common objects in context , author=. European conference on computer vision , pages=. 2014 , organization=
2014
-
[36]
International journal of computer vision , volume=
The pascal visual object classes (voc) challenge , author=. International journal of computer vision , volume=. 2010 , publisher=
2010
-
[37]
ICCV , year =
Linjie Yang and Yuchen Fan and Ning Xu , title =. ICCV , year =
-
[38]
Neural computation , volume=
Slow feature analysis: Unsupervised learning of invariances , author=. Neural computation , volume=. 2002 , publisher=
2002
-
[39]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Slowfast networks for video recognition , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[40]
Zhao, Rongzhen and Zhao, Yi and Kannala, Juho and Pajarinen, Joni , journal=
-
[41]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Ctrl-o: language-controllable object-centric visual representation learning , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[42]
arXiv preprint arXiv:2407.15589 , year=
Exploring the effectiveness of object-centric representations in visual question answering: Comparative insights with foundation models , author=. arXiv preprint arXiv:2407.15589 , year=
-
[43]
arXiv preprint arXiv:2012.05208 , year=
On the binding problem in artificial neural networks , author=. arXiv preprint arXiv:2012.05208 , year=
arXiv 2012
-
[44]
arXiv preprint arXiv:2205.13349 , year=
Learning what and where: Disentangling location and identity tracking without supervision , author=. arXiv preprint arXiv:2205.13349 , year=
-
[45]
arXiv preprint arXiv:2302.04973 , year=
Invariant slot attention: Object discovery with slot-centric reference frames , author=. arXiv preprint arXiv:2302.04973 , year=
-
[46]
Advances in Neural Information Processing Systems , volume=
Simone: View-invariant, temporally-abstracted object representations via unsupervised video decomposition , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
arXiv preprint arXiv:2111.10265 , year=
Clevrtex: A texture-rich benchmark for unsupervised multi-object segmentation , author=. arXiv preprint arXiv:2111.10265 , year=
-
[48]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Unsupervised layered image decomposition into object prototypes , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.