Exploring LLMs for South Asian Music Understanding and Generation
Pith reviewed 2026-06-28 04:18 UTC · model grok-4.3
The pith
Frontier LLMs achieve 85-90% accuracy on South Asian classical music understanding but only 40% stylistic faithfulness in generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
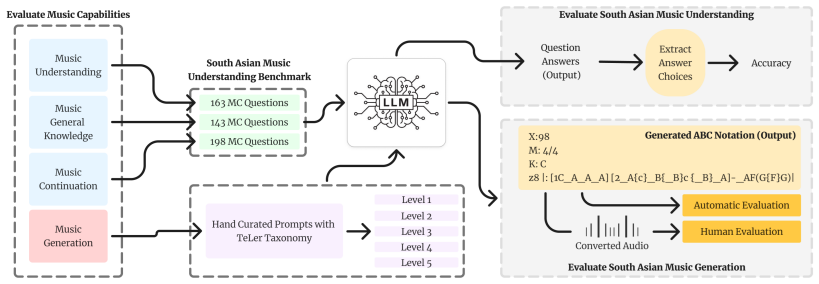
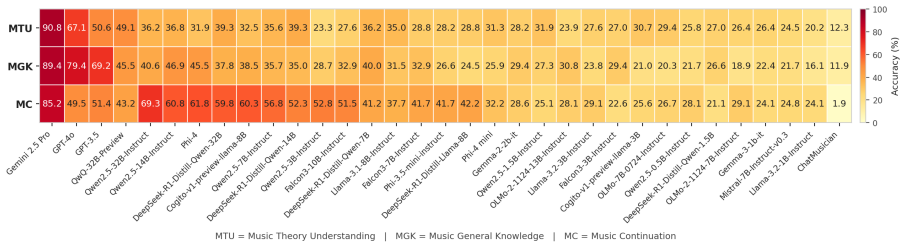
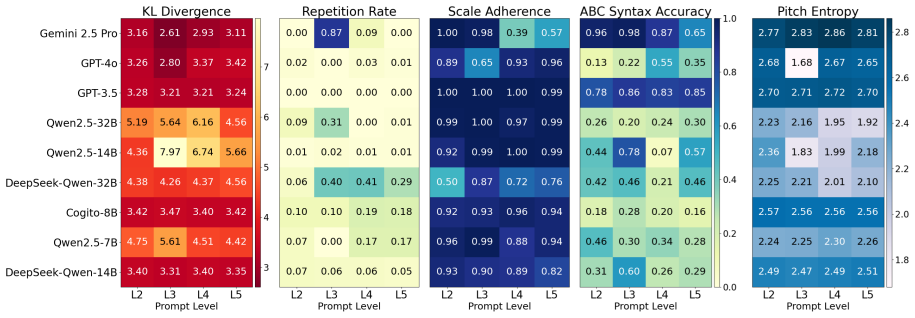
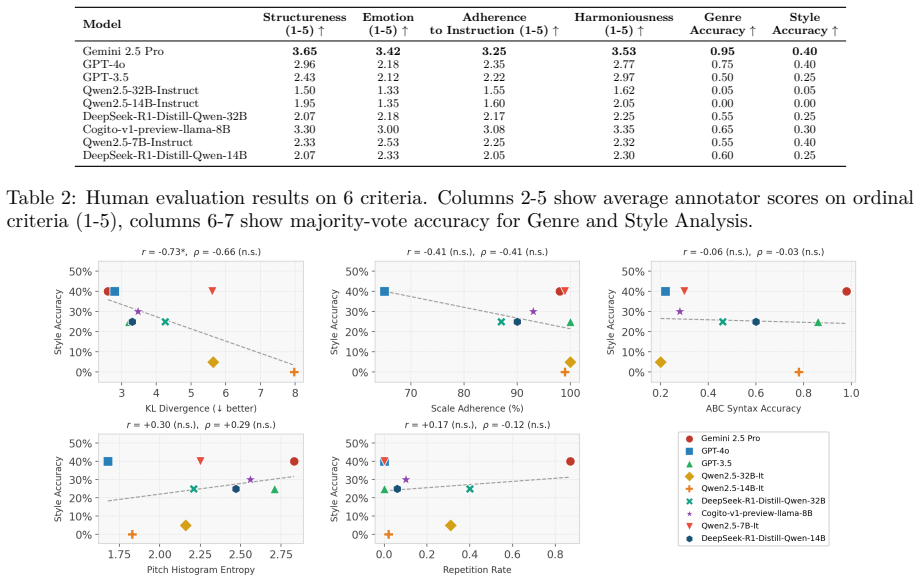
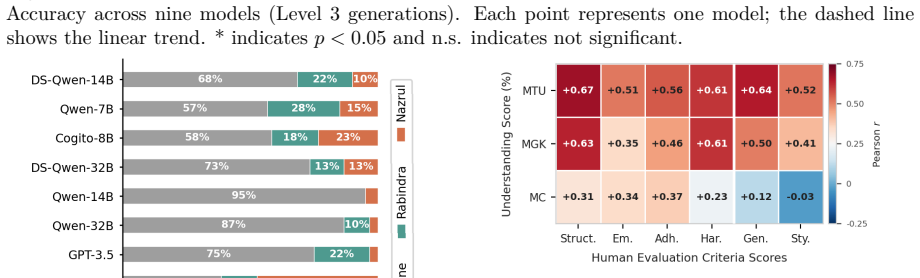
We present the first systematic evaluation of LLM competence in South Asian classical music, a tradition governed by raga, tala-based melodic constraints that impose fundamentally different structural principles from Western harmony-driven music. For music understanding evaluation, we introduce a 504-question-answer benchmark spanning raga grammar, cultural knowledge, and symbolic notation reasoning, evaluating 33 LLMs where frontier models such as Gemini 2.5 Pro achieve 85-90% accuracy, while most open-source models remain in the 23-40% range. For music generation, we design a five-level controlled prompting framework and find that even the strongest model produces stylistically faithful ou
What carries the argument
504-question benchmark for understanding and five-level controlled prompting framework for generation, grounded in Hindustani classical theory and Bengali classical forms.
If this is right
- Frontier models significantly outperform open-source models on South Asian music understanding tasks.
- Stylistic faithfulness in music generation remains a distinct and harder objective than structural validity.
- Current LLMs face an open challenge in culturally grounded music modeling for low-resource traditions.
Where Pith is reading between the lines
- LLM training data likely underrepresents South Asian musical traditions compared to Western ones.
- The benchmark and prompting methods could be extended to assess other regional music systems.
Load-bearing premise
The 504-question benchmark and five-level prompting framework accurately measure competence in raga- and tala-based traditions without cultural bias or incomplete coverage of the musical grammar.
What would settle it
If a new benchmark with broader coverage shows open-source models performing closer to frontier ones or if generation faithfulness exceeds 60% for top models, the performance gap and distinct objectives claim would be weakened.
Figures
read the original abstract
Recent advancements in Large Language Models (LLMs) have shown promising results in music understanding and generation tasks. However, existing works remain confined to Western tonal traditions, offering little insight into whether current LLMs can handle structurally distinct low-resource musical traditions. We present the first systematic evaluation of LLM competence in South Asian classical music, a tradition governed by raga, tala-based melodic constraints that impose fundamentally different structural principles from Western harmony-driven music. We ground our evaluation in Hindustani classical theory and Bengali classical forms, including Rabindra and Nazrul Sangeet -- representative low-resource traditions within South Asian classical music. For music understanding evaluation, we introduce a 504-question-answer benchmark spanning raga grammar, cultural knowledge, and symbolic notation reasoning, evaluating 33 LLMs where frontier models such as Gemini 2.5 Pro achieve 85-90% accuracy, while most open-source models remain in the 23-40% range. For music generation, we design a five-level controlled prompting framework and find that even the strongest model produces stylistically faithful outputs only 40% of the time. These results reveal that structural validity and stylistic faithfulness in music generation are distinct objectives and highlight an open challenge for culturally grounded music modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to deliver the first systematic evaluation of LLMs on South Asian classical music (Hindustani and Bengali traditions including Rabindra and Nazrul Sangeet). It introduces a 504-question benchmark spanning raga grammar, cultural knowledge, and symbolic notation, reports that frontier models (e.g., Gemini 2.5 Pro) reach 85-90% accuracy while most open-source models score 23-40%, and uses a five-level controlled prompting framework for generation that yields only 40% stylistically faithful outputs even for the strongest model, concluding that structural validity and stylistic faithfulness are distinct objectives.
Significance. If the benchmark and scoring protocols prove robust, the work supplies the first quantitative baseline for LLM performance on raga- and tala-governed traditions, exposing a clear performance gap between frontier and open-source models and isolating an open modeling challenge for culturally grounded music generation.
major comments (2)
- [Abstract and evaluation-design paragraphs] Abstract and evaluation-design paragraphs: the headline accuracy figures (85-90% frontier vs. 23-40% open-source) and the 40% faithfulness rate are load-bearing for the central claims, yet the manuscript supplies no description of question sourcing, coverage audit of raga grammar (swara rules, pakad, vadi-samvadi), tala cycles, inter-rater agreement, or leakage checks; without these the measured competence cannot be distinguished from benchmark artifacts.
- [Generation framework section] Generation framework section: the claim that structural validity and stylistic faithfulness are distinct objectives rests on the five-level prompting results, but the manuscript does not define the scoring rubric for 'stylistically faithful,' report expert validation process, or provide statistical comparison between the two metrics; this leaves the distinction unsupported.
minor comments (1)
- [Abstract] The abstract states the benchmark is 'grounded in Hindustani classical theory and Bengali classical forms' without indicating how this grounding shaped question selection or answer keys.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper to incorporate additional methodological details where needed to strengthen the presentation of our benchmark and results.
read point-by-point responses
-
Referee: [Abstract and evaluation-design paragraphs] Abstract and evaluation-design paragraphs: the headline accuracy figures (85-90% frontier vs. 23-40% open-source) and the 40% faithfulness rate are load-bearing for the central claims, yet the manuscript supplies no description of question sourcing, coverage audit of raga grammar (swara rules, pakad, vadi-samvadi), tala cycles, inter-rater agreement, or leakage checks; without these the measured competence cannot be distinguished from benchmark artifacts.
Authors: We agree that the current manuscript would benefit from expanded methodological transparency on the benchmark construction. In the revised version, we will add a dedicated subsection under the evaluation design that details: question sourcing from standard references in Hindustani and Bengali music theory; a coverage audit confirming inclusion of swara rules, pakad, vadi-samvadi relations, and tala structures; inter-rater agreement metrics obtained from expert reviewers; and leakage checks performed via manual curation to avoid overlap with common training corpora. These additions will directly address the concern without changing the reported accuracy figures. revision: yes
-
Referee: [Generation framework section] Generation framework section: the claim that structural validity and stylistic faithfulness are distinct objectives rests on the five-level prompting results, but the manuscript does not define the scoring rubric for 'stylistically faithful,' report expert validation process, or provide statistical comparison between the two metrics; this leaves the distinction unsupported.
Authors: We acknowledge the need for greater precision in defining and validating the stylistic faithfulness metric. The revised generation framework section will include: an explicit scoring rubric for stylistic faithfulness (covering raga-specific melodic adherence, tala alignment, and idiomatic phrasing); a description of the expert validation process involving domain specialists in Hindustani and Bengali traditions; and statistical comparisons (such as agreement rates or correlation coefficients) between structural validity and stylistic faithfulness scores. This will provide stronger empirical support for the distinction between the two objectives. revision: yes
Circularity Check
Empirical benchmark study with no derivations or self-referential predictions
full rationale
The paper is an empirical evaluation introducing a 504-question benchmark and five-level prompting framework for assessing LLMs on South Asian classical music. No mathematical derivations, equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text or abstract. Central claims rest on direct model accuracy measurements (85-90% for frontier models) and generation faithfulness rates rather than any chain that reduces to its own inputs by construction. The work is therefore self-contained as a benchmark study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A comparative study of indian and west- ern music forms. In ISMIR, pages 29–34. Andrea Agostinelli, Timo I Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, and 1 others. 2023. Mu- siclm: Generating music from text. arXiv preprint arXiv:2301.11325. Yogesh Agrawal, Aniruddha Dut...
Pith/arXiv arXiv 2023
-
[2]
Omnitom: Benchmarking theory of mind in llms via explicit belief modeling . Preprint, arXiv:2605.26322. Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, and 1 others. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107....
Pith/arXiv arXiv 2021
-
[3]
arXiv preprint arXiv:2407.21783
The llama 3 herd of models. arXiv preprint arXiv:2407.21783. Dirk Groeneveld, Iz Beltagy, Evan Walsh, Ak- shita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, and 1 others. 2024. Olmo: Accelerating the science of language models. In Proceedings of the 62nd annual meeting of the association for computational ...
Pith/arXiv arXiv 2024
-
[4]
arXiv preprint arXiv:2209.15352
Audiogen: Textually guided audio gen- eration. arXiv preprint arXiv:2209.15352. Klaus Krippendorff. 2011. Computing krippen- dorff’s alpha-reliability. Solomon Kullback. 1951. Kullback-leibler diver- gence. Winston E. Langley. 2009. Kazi Nazrul Islam: The Voice of Poetry and the Struggle for Human Wholeness. Nazrul Institute, Dhaka, Bangladesh. Jean-Marie...
arXiv 2011
-
[5]
Advances in neural information processing systems, 35:3843–3857
Solving quantitative reasoning problems with language models. Advances in neural information processing systems, 35:3843–3857. Jiajia Li, Lu Yang, Mingni Tang, Cong Chen, Zuchao Li, Ping Wang, and Hai Zhao. 2024. The music maestro or the musically challenged, a massive music evaluation benchmark for large language models . Preprint, arXiv:2406.15885. Jiaw...
arXiv 2024
-
[6]
Teler: A general taxonomy of llm prompts for benchmarking complex tasks . Preprint, arXiv:2305.11430. Pasin Sawaengsawangarom, Suparoek Phongoen, and Papis Wongchaisuwat. 2025. Deep learn- ing for music genre classification: A case study of thai music. In Proceedings of the 2025 9th International Conference on Control Engineering and Artificial Intelligen...
arXiv 2025
-
[7]
arXiv preprint arXiv:2503.08638
Yue: Scaling open foundation models for long-form music generation. arXiv preprint arXiv:2503.08638. Ruibin Yuan, Hanfeng Lin, Yi Wang, Zeyue Tian, Shangda Wu, Tianhao Shen, Ge Zhang, Yuhang Wu, Cong Liu, Ziya Zhou, and 1 others. 2024. Chatmusician: Understanding and generating music intrinsically with llm. arXiv preprint arXiv:2402.16153. Ruibin Yuan, Yi...
arXiv 2024
-
[8]
[[Answer: C]]
for music generation in ABC notation. The meta-data that was provided were lyrics, theme, time signature from the original songs. Since the official Bengali Swaralipi notation system represents pitches using solfège sylla- bles (সা, ের, গা, মা, পা, ধা, িন) relative to a tonic without specifying an absolute pitch, a mapping convention was required during th...
-
[9]
Ensure the melody adheres to a Indian classical music style
-
[10]
It should sound like a [Rabindra/Nazrul] Song
-
[11]
Use Scale C and [time signature] time signature
-
[12]
Strictly generate just notations, avoid any comments and extra line
-
[13]
Cover the lyrical theme: [theme], ensuring the output spans ∼2–3 minutes in play length
-
[14]
Audio files
The music should feature instruments used in indian classical music. [Lyrics] Level 4 – Significant Details + User Ex- pectation Level 3 prompt + A good output should: • Be musically coherent and playable. • Clearly reflect the theme [theme]. • Maintain stylistic authenticity of Indian classical music. • Be structured in valid ABC notation syntax. Lyrics:...
-
[15]
Audio files
F older structure: Inside the “Audio files” folder, there are 9 subfolders. Each sub- folder corresponds to a different large language model (LLM) and contains 20 audio files gen- erated by that model. The names of these 9 subfolders exactly match the sheet names in the Excel file
-
[16]
Folder 1
Matching folders and sheets: In an- notator#.xlsx, there are 9 sheets, each named after one of the subfolders. When you work on a specific folder, make sure you are also filling out the sheet with the same name. Example: If you are annotating audios from the folder “Folder 1”, fill in the sheet named “Folder 1”
-
[17]
song no
Understanding the Excel file: Each row in a sheet represents one audio file. The “song no. ” column specifies the exact file name you need to work on. The full file path is shown as: folder_name/song_name.wav. Ex- ample: “Folder 1/5.wav” means the file is in- side “Folder 1”
-
[18]
song no
Annotation procedure: Find the audio file mentioned in the “song no. ” column. Read the prompt in the same row of the Excel sheet, this describes what the model was asked to generate. Listen carefully to the correspond- ing audio file. Fill in the remaining columns in that row based on the instructions given be- low. Note: Even if the lyrics are well-know...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.