Expected Gain-based Escalation in Vertical Federated Learning
Pith reviewed 2026-07-01 06:07 UTC · model grok-4.3
The pith
An expected-gain analytical score enables selective escalation in vertical federated learning to balance accuracy and communication.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an interpretable router based on an expected-gain score, which merges a calibrated pooled posterior with classwise reliability estimates from calibration data, can decide escalation in a two-round VFL protocol such that communication is used only when it is expected to improve the final decision, yielding superior communication-accuracy trade-offs on multi-view benchmarks compared to baselines.
What carries the argument
the expected-gain score estimation that combines a calibrated pooled posterior with classwise reliability estimates of the VFL model from held-out calibration data
If this is right
- The proposed router improves the communication-accuracy trade-off over confidence-, learned-gain-, and deferral-based baselines.
- It requires no separately trained routing network.
- It performs well in settings with test-time view degradation.
- It applies to multi-view classification tasks in VFL.
Where Pith is reading between the lines
- This calibration-based approach might reduce the need for additional training in other selective inference systems.
- The score could be extended to incorporate more complex gain estimates beyond classwise reliability.
- The method highlights the value of held-out data for routing in distributed learning without extra models.
Load-bearing premise
Held-out calibration data is representative of the deployment distribution so that classwise reliability estimates accurately predict the correctness improvement from second-round fusion.
What would settle it
A test showing that on data from a shifted distribution, the escalation decisions based on the score lead to worse accuracy-communication trade-off than always escalating or using a learned router.
Figures
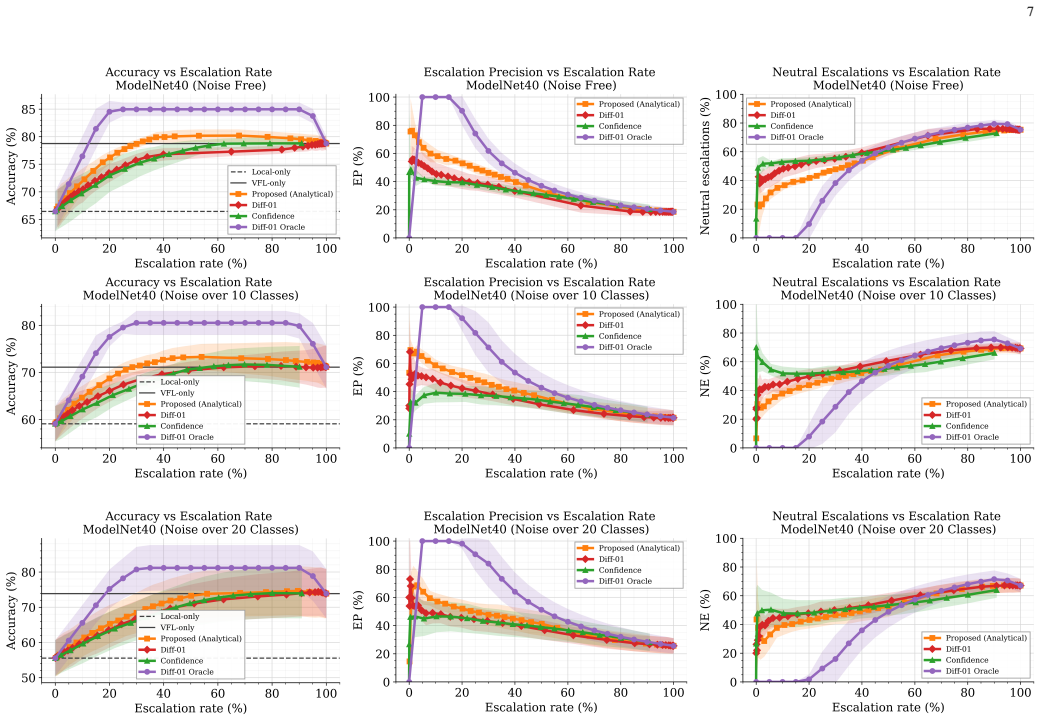
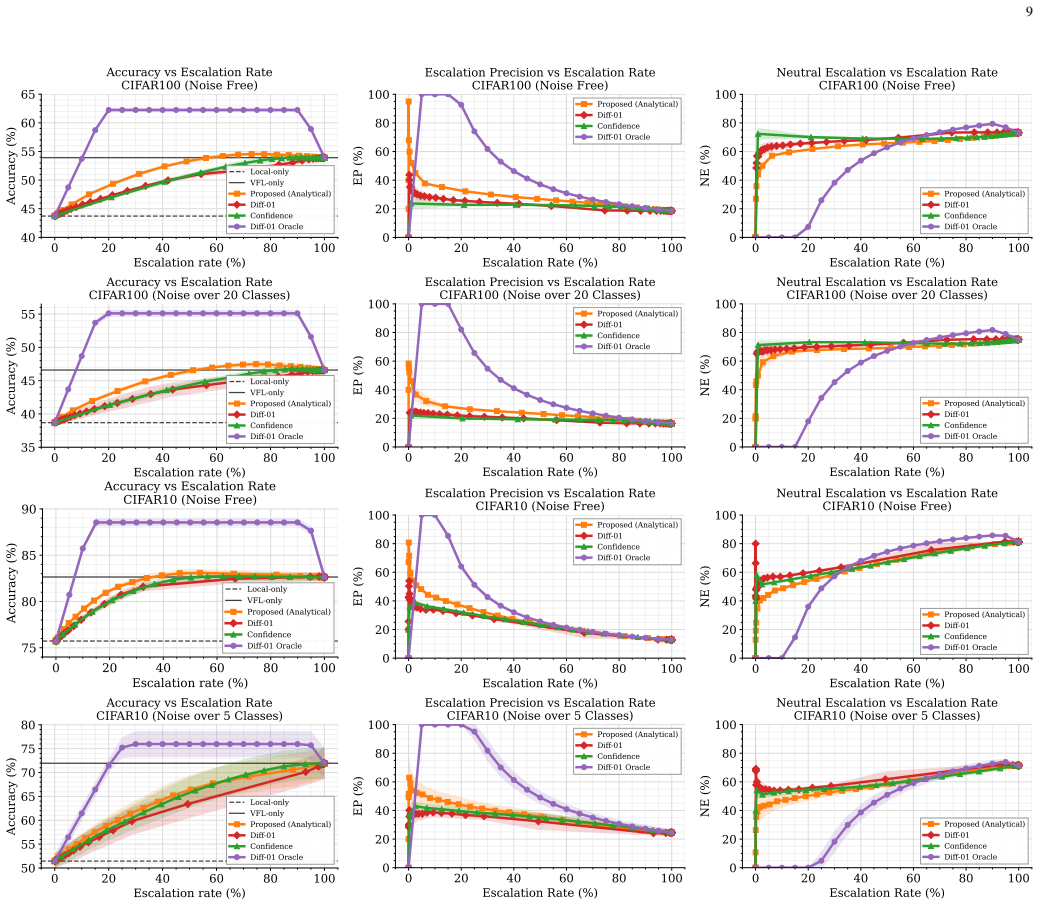
read the original abstract
Collaborative inference can improve predictive performance by integrating complementary information across agents, but applying collaborative fusion to every sample can incur unnecessary communication and computational overhead. This trade-off is particularly relevant in vertical federated learning (VFL), where clients observe different views of the same sample and fusion typically requires transmitting intermediate representations to a server. We study selective escalation in a two-round VFL inference protocol, in which a low-cost first round produces a prediction from client posteriors and a second embedding-fusion round is invoked only when it is expected to improve the final decision. We formulate routing as expected-gain score estimation: a sample is escalated when a predicted improvement in correctness justifies the additional communication. The proposed analytical score combines a calibrated pooled posterior with classwise reliability estimates of the VFL model, both obtained from held-out calibration data, yielding an interpretable router that requires no separately trained routing network. Experiments on multi-view classification benchmarks, including controlled test--time view degradation settings, show that the proposed router improves the communication-accuracy trade-off over confidence-, learned-gain-, and deferral-based baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an expected-gain score for selective escalation in a two-round VFL inference protocol. A sample is escalated to embedding fusion only when the analytically computed expected improvement in correctness (from a calibrated pooled posterior combined with classwise reliability estimates, both derived from held-out calibration data) justifies the added communication cost. This yields an interpretable router without a separately trained routing network. Experiments on multi-view classification benchmarks, including test-time view degradation, claim improved communication-accuracy trade-offs over confidence-, learned-gain-, and deferral-based baselines.
Significance. If the calibration-based estimates reliably predict per-sample gains, the work offers a lightweight, interpretable alternative to learned routers in VFL that could meaningfully reduce unnecessary communication in collaborative inference without sacrificing accuracy. The parameter-free nature of the router (no additional training) is a clear strength relative to learned baselines.
major comments (2)
- [Method / Experiments] The central claim that the expected-gain router improves the communication-accuracy trade-off rests on the assumption that classwise reliability estimates from held-out calibration data accurately forecast per-sample correctness improvements from second-round fusion. The manuscript should include direct evidence for this mapping (e.g., a plot or table correlating estimated gains against observed accuracy deltas on held-out test samples) to substantiate the router's decisions.
- [Abstract / Experiments] The abstract states improvements over three baseline classes on multi-view benchmarks but supplies no quantitative results, error bars, or details on expected-gain computation and calibration procedure. The experiments section must report these metrics (including statistical significance) to allow verification of the claimed trade-off gains.
minor comments (1)
- [Method] Clarify whether the pooled posterior calibration and classwise reliability estimates share the same held-out set or use separate splits, and state any assumptions about distribution shift between calibration and deployment.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate additional evidence and reporting as outlined.
read point-by-point responses
-
Referee: [Method / Experiments] The central claim that the expected-gain router improves the communication-accuracy trade-off rests on the assumption that classwise reliability estimates from held-out calibration data accurately forecast per-sample correctness improvements from second-round fusion. The manuscript should include direct evidence for this mapping (e.g., a plot or table correlating estimated gains against observed accuracy deltas on held-out test samples) to substantiate the router's decisions.
Authors: We agree that direct validation of the mapping between estimated gains and observed improvements would strengthen the central claim. We will add a new figure (or table) in the experiments section that plots or tabulates the correlation between the analytically computed expected-gain scores (from calibration data) and the actual per-sample accuracy deltas observed when escalation is performed on a separate held-out test set. This will provide the requested empirical support for the router's decisions. revision: yes
-
Referee: [Abstract / Experiments] The abstract states improvements over three baseline classes on multi-view benchmarks but supplies no quantitative results, error bars, or details on expected-gain computation and calibration procedure. The experiments section must report these metrics (including statistical significance) to allow verification of the claimed trade-off gains.
Authors: We acknowledge the need for quantitative detail. We will expand the experiments section to report specific trade-off metrics (e.g., accuracy at given communication budgets), error bars from repeated runs with different random seeds, full details of the expected-gain formula and calibration procedure, and statistical significance tests (e.g., paired t-tests or Wilcoxon tests) against the confidence, learned-gain, and deferral baselines. Key quantitative highlights will also be added to the abstract if space allows. revision: yes
Circularity Check
No circularity: expected-gain router derived from external held-out calibration data
full rationale
The paper formulates the routing score from a calibrated pooled posterior and classwise reliability estimates, both explicitly obtained from held-out calibration data treated as external to the router. No equations, self-citations, or fitted parameters are shown that reduce the gain score to its own inputs by construction. The central claim therefore retains independent content from the calibration step and does not match any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Held-out calibration data is drawn from the same distribution as test data and is sufficient to estimate classwise reliability.
Reference graph
Works this paper leans on
-
[2]
Available: http://arxiv.org/abs/1912.04977
[Online]. Available: http://arxiv.org/abs/1912.04977
-
[3]
Vertical federated learning: A structured literature review,
A. Khan, M. ten Thij, and A. Wilbik, “Vertical federated learning: A structured literature review,” 2023. [Online]. Available: https: //arxiv.org/abs/2212.00622
-
[4]
Communication-efficient vertical federated learning,
——, “Communication-efficient vertical federated learning,”Algorithms, vol. 15, no. 8, 2022. [Online]. Available: https://www.mdpi.com/ 1999-4893/15/8/273
2022
-
[5]
Less-vfl: Communication-efficient feature selection for vertical federated learning,
T. Castiglia, Y . Zhou, S. Wang, S. Kadhe, N. Baracaldo, and S. Patterson, “Less-vfl: Communication-efficient feature selection for vertical federated learning,” 2023. [Online]. Available: https: //arxiv.org/abs/2305.02219
-
[6]
SparseVFL: Communication-efficient vertical federated learning based on sparsification of embeddings and gradients,
Y . Inoue, H. Moriya, Q. Zhang, and K. Skrinak, “SparseVFL: Communication-efficient vertical federated learning based on sparsification of embeddings and gradients,” 2023. [Online]. Available: https://openreview.net/forum?id=BVH3-XCRoN3
2023
-
[7]
Communication-efficient vertical federated learning with limited overlapping samples,
J. Sun, Z. Xu, D. Yang, V . Nath, W. Li, C. Zhao, D. Xu, Y . Chen, and H. R. Roth, “Communication-efficient vertical federated learning with limited overlapping samples,” 2023. [Online]. Available: https://arxiv.org/abs/2303.16270
-
[8]
Vfl-cafe: Communication-efficient vertical federated learning via dynamic caching and feature selection,
J. Zhou, H. Liang, T. Wu, X. Zhang, J. Yu, and C. Tan, “Vfl-cafe: Communication-efficient vertical federated learning via dynamic caching and feature selection,”Entropy, vol. 27, p. 66, 01 2025
2025
-
[9]
Optimal strategies for reject option classifiers,
V . Franc, D. Prusa, and V . V oracek, “Optimal strategies for reject option classifiers,”Journal of Machine Learning Research, vol. 24, no. 11, pp. 1–49, 2023. [Online]. Available: http://jmlr.org/papers/v24/21-0048.html
2023
-
[10]
Machine learning with a reject option: A survey,
K. Hendrickx, L. Perini, D. V . der Plas, W. Meert, and J. Davis, “Machine learning with a reject option: A survey,” 2024. [Online]. 10 Available: https://arxiv.org/abs/2107.11277
-
[11]
Predict Responsibly: Improving Fairness and Accuracy by Learning to Defer
D. Madras, T. Pitassi, and R. Zemel, “Predict responsibly: Improving fairness and accuracy by learning to defer,” 2018. [Online]. Available: https://arxiv.org/abs/1711.06664
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[12]
Consistent estimators for learning to defer to an expert,
H. Mozannar and D. A. Sontag, “Consistent estimators for learning to defer to an expert,”CoRR, vol. abs/2006.01862, 2020. [Online]. Available: https://arxiv.org/abs/2006.01862
-
[13]
Two-stage learning to defer with multiple experts,
A. Mao, C. Mohri, M. Mohri, and Y . Zhong, “Two-stage learning to defer with multiple experts,” inThirty-seventh Conference on Neural Information Processing Systems, 2023. [Online]. Available: https://openreview.net/forum?id=GIlsH0T4b2
2023
-
[14]
Mitigating underfitting in learning to defer with consistent losses,
S. Liu, Y . Cao, Q. Zhang, L. Feng, and B. An, “Mitigating underfitting in learning to defer with consistent losses,” inProceedings of The 27th International Conference on Artificial Intelligence and Statistics, ser. Proceedings of Machine Learning Research, S. Dasgupta, S. Mandt, and Y . Li, Eds., vol. 238. PMLR, 02–04 May 2024, pp. 4816–4824. [Online]. ...
2024
-
[15]
Active classification based on value of classifier,
T. Gao and D. Koller, “Active classification based on value of classifier,” inProceedings of the 25th International Conference on Neural Informa- tion Processing Systems, ser. NIPS’11. Red Hook, NY , USA: Curran Associates Inc., 2011, p. 1062–1070
2011
-
[16]
When does confidence-based cascade deferral suffice?
W. Jitkrittum, N. Gupta, A. K. Menon, H. Narasimhan, A. S. Rawat, and S. Kumar, “When does confidence-based cascade deferral suffice?”
-
[17]
Available: https://arxiv.org/abs/2307.02764
[Online]. Available: https://arxiv.org/abs/2307.02764
-
[18]
M. Kull, M. Perell ´o-Nieto, M. K ¨angsepp, T. de Menezes e Silva Filho, H. Song, and P. A. Flach, “Beyond temperature scaling: Obtaining well-calibrated multiclass probabilities with dirichlet calibration,”CoRR, vol. abs/1910.12656, 2019. [Online]. Available: http://arxiv.org/abs/1910.12656
-
[19]
On Calibration of Modern Neural Networks
C. Guo, G. Pleiss, Y . Sun, and K. Q. Weinberger, “On calibration of modern neural networks,”CoRR, vol. abs/1706.04599, 2017. [Online]. Available: http://arxiv.org/abs/1706.04599
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
Learning multiple layers of features from tiny images,
A. Krizhevsky, “Learning multiple layers of features from tiny images,”
-
[21]
Available: https://api.semanticscholar.org/CorpusID: 18268744
[Online]. Available: https://api.semanticscholar.org/CorpusID: 18268744
-
[22]
Deep Residual Learning for Image Recognition
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,”CoRR, vol. abs/1512.03385, 2015. [Online]. Available: http://arxiv.org/abs/1512.03385 BIOGRAPHY Mohamad Mestoukirdi(Member, IEEE) was born in Tyre, Lebanon, in 1995. He received a double degree in engineering from the Politecnico di Torino (Polito), Turin, Italy, and the L...
work page internal anchor Pith review Pith/arXiv arXiv 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.