Beyond Chunk-Local Extraction: Cross-Chunk Graph Augmentation for GraphRAG
Pith reviewed 2026-06-29 13:15 UTC · model grok-4.3
The pith
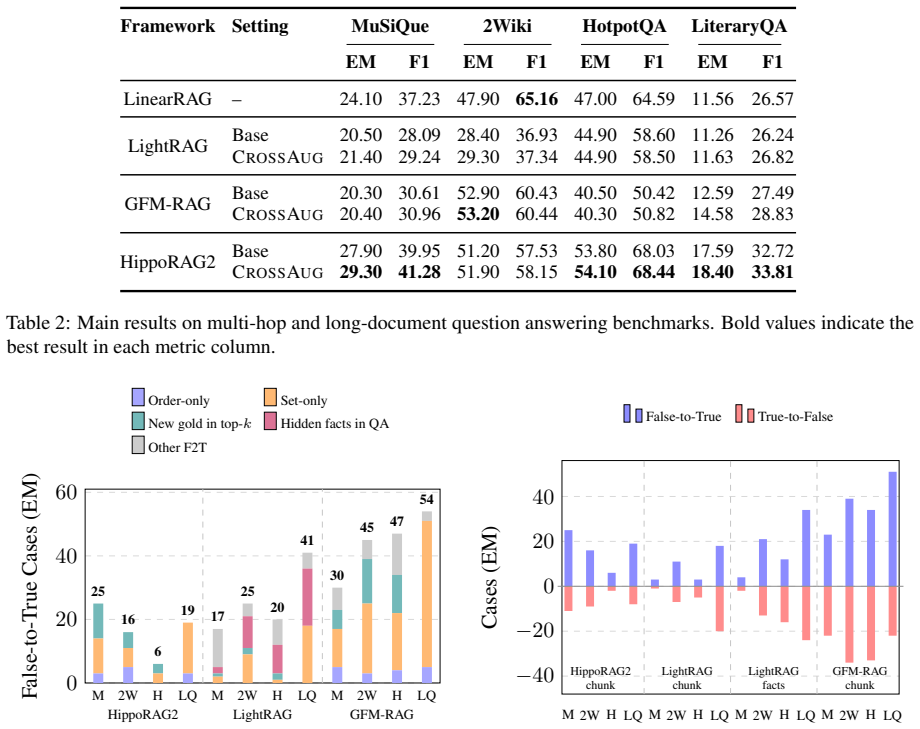
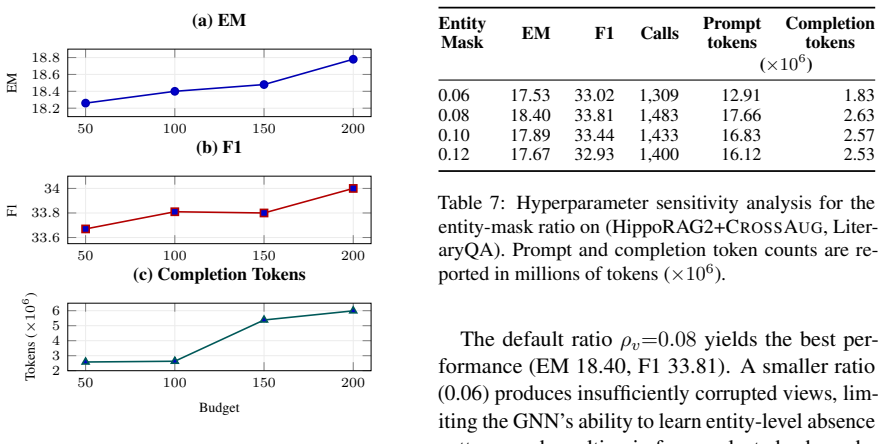
CrossAug augments GraphRAG indices with cross-chunk relations by using a GNN to select regions for targeted LLM completion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CrossAug performs offline cross-chunk graph augmentation by deriving supervision from self-supervised corruption, training a GNN to rank subgraphs for missing relations, and restricting expensive LLM completion to the top-scoring subgraphs; when this augmented index is used inside existing GraphRAG pipelines, retrieval quality and answer accuracy rise on multi-hop and long-document QA tasks.
What carries the argument
GNN-guided subgraph scoring on self-supervised corruptions that directs selective LLM completion to likely missing cross-chunk relations.
If this is right
- The augmented graphs remain usable by any downstream GraphRAG retriever without retraining.
- Offline augmentation cost is paid once and amortised over many queries.
- The method scales to corpora where exhaustive pairwise chunk checks would be intractable.
- Performance gains appear on both multi-hop and long-document tasks, suggesting the missing edges matter for different reasoning patterns.
Where Pith is reading between the lines
- If the GNN scoring generalises across domains, the same corruption-and-rank pipeline could be applied to other graph-construction tasks that currently rely on local extraction.
- Selective completion reduces token usage compared with exhaustive cross-chunk prompting, which may matter for very large corpora.
- The approach separates index enrichment from query-time retrieval, allowing the two stages to be optimised independently.
Load-bearing premise
The GNN trained on self-supervised corruption can rank subgraphs accurately enough that selective LLM completion recovers true cross-chunk relations without introducing too many false positives.
What would settle it
Run the same three GraphRAG frameworks on the four benchmarks with CrossAug disabled versus enabled and measure whether end-to-end QA metrics improve or stay flat.
Figures


read the original abstract
GraphRAG extends retrieval-augmented generation by organizing corpora as explicit knowledge graphs, enabling graph-based retrieval for complex question answering. However, existing frameworks extract entities and relations within individual chunks, leaving cross-chunk relations -- those whose evidence spans multiple passages -- systematically absent from the index. Exhaustive LLM-based recovery of such relations is impractical due to the combinatorial explosion of chunk combinations. We present CrossAug, a GNN-guided CROSS-Chunk Graph AUGmentation method that enriches GraphRAG indices with cross-chunk relational structure as an offline step before query-time retrieval. CrossAug derives training supervision through self-supervised graph corruption, uses a topology-aware GNN to score subgraphs for missingness, and applies evidence-grounded LLM completion only to selected high-scoring regions. Experiments on three LLM-based GraphRAG frameworks across four multi-hop and long-document QA benchmarks demonstrate that CrossAug consistently improves performance, confirming the benefit of cross-chunk graph augmentation for retrieval-based question answering. Our code is available at https://github.com/DonFinliani/CrossAug.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CrossAug, a GNN-guided method for offline cross-chunk graph augmentation in GraphRAG frameworks. It uses self-supervised graph corruption to train a topology-aware GNN that scores subgraphs for missingness, then applies selective evidence-grounded LLM completion only to high-scoring regions to recover cross-chunk relations that chunk-local extraction misses. The central claim is that this yields consistent performance gains on multi-hop and long-document QA tasks across three LLM-based GraphRAG systems and four benchmarks, with code released at the cited GitHub repository.
Significance. If the results hold, the work targets a genuine and practically important limitation of existing GraphRAG pipelines—the systematic absence of cross-chunk relations—while avoiding the combinatorial cost of exhaustive LLM completion. The self-supervised training plus selective augmentation approach is a plausible way to make augmentation tractable. Explicit release of code is a clear positive for reproducibility and follow-on work.
major comments (2)
- [Abstract and §3 (Method)] Abstract and §3 (Method): the central claim that the topology-aware GNN, trained only on self-supervised corruption, reliably ranks subgraphs containing true missing cross-chunk relations is load-bearing, yet the manuscript provides no direct evaluation of this ranking quality (AUC, precision@K, or correlation against held-out cross-chunk ground truth). Without such a diagnostic, observed QA gains could arise from incidental effects of added edges rather than targeted recovery of missing structure.
- [§4 (Experiments)] §4 (Experiments): the abstract states that CrossAug 'consistently improves performance' on three frameworks and four benchmarks, but the provided text contains no tables, baselines, statistical significance tests, or ablation results that would allow verification of the magnitude or robustness of the gains. This information is required to assess whether the augmentation step is the causal driver.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the evidence for our claims.
read point-by-point responses
-
Referee: [Abstract and §3 (Method)] Abstract and §3 (Method): the central claim that the topology-aware GNN, trained only on self-supervised corruption, reliably ranks subgraphs containing true missing cross-chunk relations is load-bearing, yet the manuscript provides no direct evaluation of this ranking quality (AUC, precision@K, or correlation against held-out cross-chunk ground truth). Without such a diagnostic, observed QA gains could arise from incidental effects of added edges rather than targeted recovery of missing structure.
Authors: We agree that a direct evaluation of the GNN ranking quality is important to substantiate the targeted nature of the augmentation. While the self-supervised corruption objective and downstream QA results provide indirect support, we will add a diagnostic evaluation (including AUC, precision@K, and correlation with held-out cross-chunk ground truth) to the revised manuscript, either as an extension of §3 or a new subsection in §4. revision: yes
-
Referee: [§4 (Experiments)] §4 (Experiments): the abstract states that CrossAug 'consistently improves performance' on three frameworks and four benchmarks, but the provided text contains no tables, baselines, statistical significance tests, or ablation results that would allow verification of the magnitude or robustness of the gains. This information is required to assess whether the augmentation step is the causal driver.
Authors: We acknowledge that the experimental presentation requires more explicit verification. We will revise §4 to include complete tables with all baselines, ablation studies, and statistical significance tests to demonstrate the magnitude, robustness, and causal role of the cross-chunk augmentation. revision: yes
Circularity Check
No circularity: method uses external benchmarks and standard self-supervision
full rationale
The paper trains a GNN via self-supervised corruption of chunk-local graphs to score subgraphs for missingness, then selectively applies LLM completion and evaluates on independent multi-hop QA benchmarks across three frameworks. No equations, fitted parameters, or self-citations are shown to reduce the reported QA gains to the training inputs by construction. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Literaryqa: Towards effective evaluation of long-document narrative qa. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 34074–34095. Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings throug...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
InEuropean semantic web confer- ence, pages 593–607
Modeling relational data with graph convolu- tional networks. InEuropean semantic web confer- ence, pages 593–607. Springer. Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2022. MuSiQue: Multi- hop questions via single-hop question composition. Transactions of the Association for Computational Linguistics. Yan Wang, Wenju Hou,...
2022
-
[3]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Chang Yang, Chuang Zhou, Yilin Xiao, Su Dong, Luyao Zhuang, Yujing Zhang, Zhu Wang, Zijin Hong, Zheng Yuan, Zhishang Xiang, and 1 others. 2026. Graph-based agent memory: Taxonomy, techniques, and applications.arXiv preprint arXiv:2602.05665. Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, Willia...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Summarize the current subgraph coverage
-
[5]
Identify likely missing relations, likely missing entities, or both
-
[6]
Prioritize deeper completions that connect multiple known triples, resolve references across multiple passages, or enrich the subgraph with important time, condition, prerequisite, ownership, role, sequence, or part-whole information
-
[7]
When a new triple depends on multiple passages, attach all relevant chunk_ids instead of citing only one chunk
-
[8]
new_triples
Keep only facts that are directly stated or unambiguously supported by the evidence passages. Required output schema: { "new_triples": [ { "triple": ["subject", "predicate", "object"], "chunk_ids": ["chunk-id"] } ] } Return JSON only. Subgraph Completion Prompt Figure 4: Prompt used by CROSSAUGfor GNN-guided LLM completion. The selected subgraph, known tr...
2009
-
[9]
The speed of the towing had fanned the smol- dering destruction . . . ‘We had better stop this towing’
These passages mention the shipJudeaand earlier accidents but do not identify the towing steamer. CROSSAUGinstead retrieves chunks 0020 and 0021, where the towing event is explicitly de- scribed: “When our skipper came back we learned that the steamer was the Sommerville, Captain Nash . . . and that the agreement was she should tow us to Anjer or Batavia,...
1979
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.