ORACLE-CT: Anatomy-Aware Support Pooling for CT Classification
Pith reviewed 2026-06-28 06:23 UTC · model grok-4.3
The pith
Anatomy-aware support pooling using multi-organ segmentation improves abdominal CT disease classification over global average pooling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
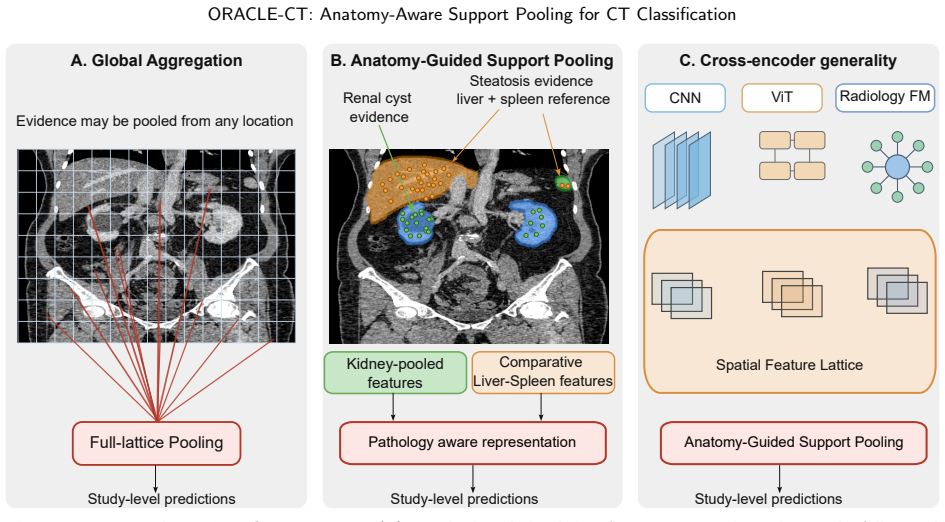
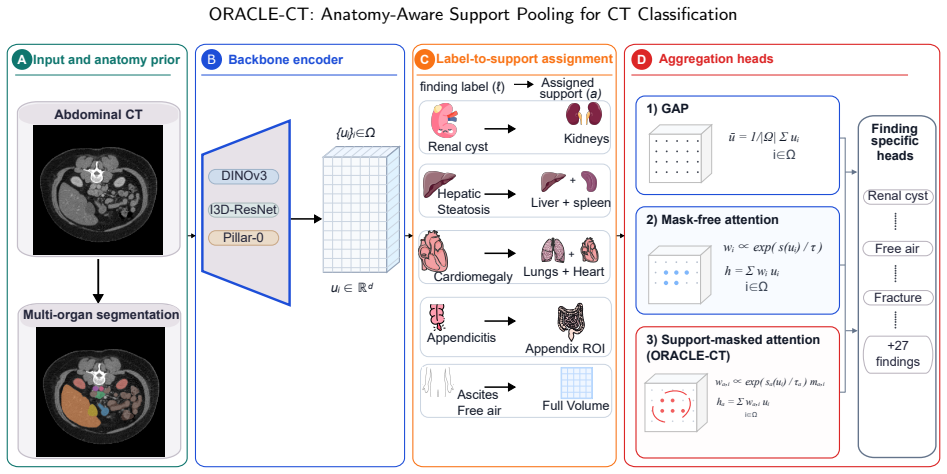
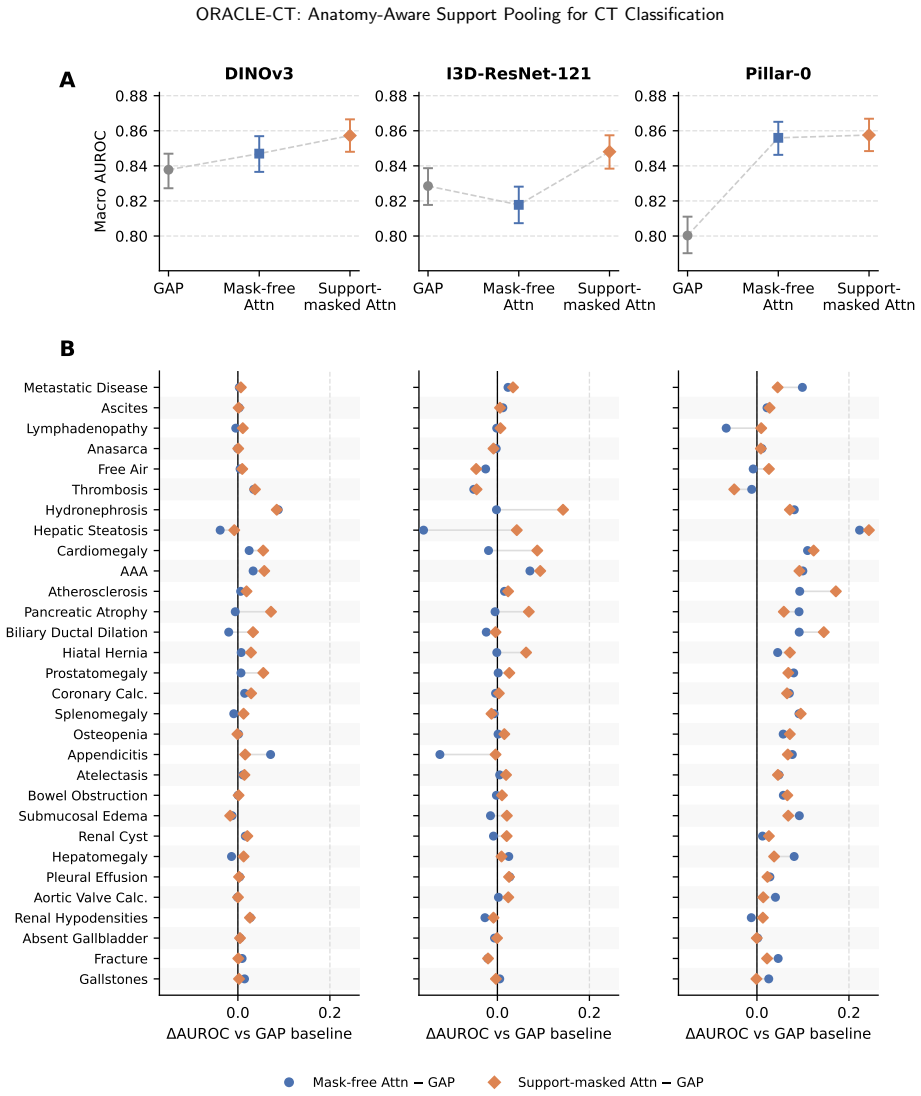
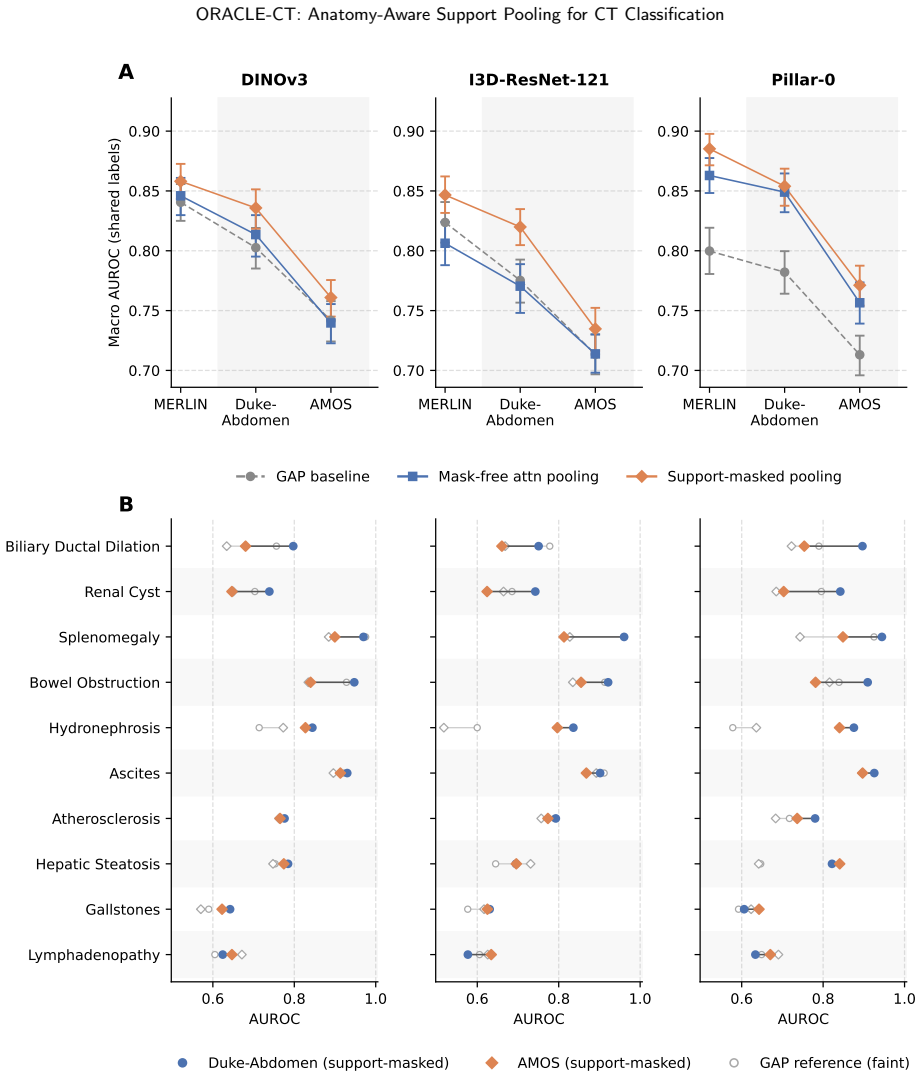
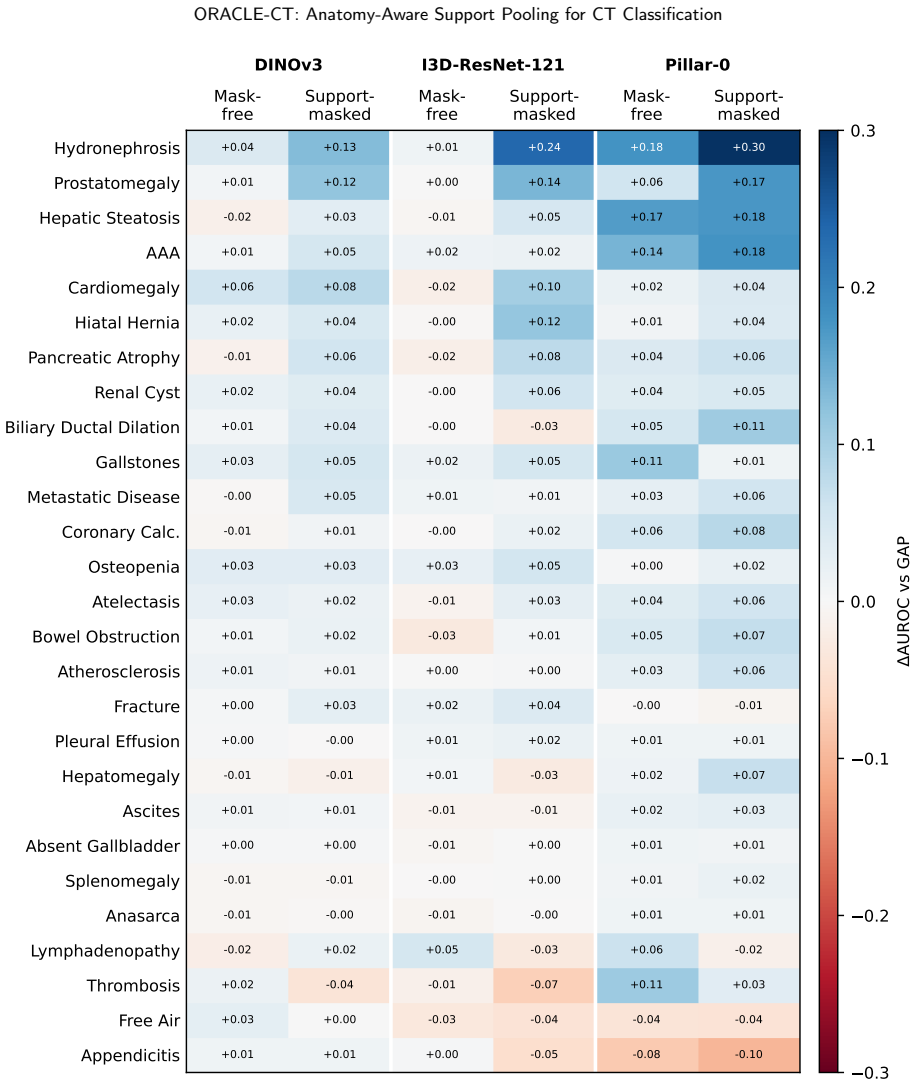
ORACLE-CT is an encoder-agnostic aggregation framework that uses multi-organ segmentation to create anatomical supports and applies support-masked pooling (single-organ, union, comparative, localized, or global) to restrict feature aggregation to relevant compartments, yielding higher macro-AUROC/AUPRC than global average pooling on MERLIN (DINOv3: 0.858/0.676 vs 0.838/0.638) and better external results on harmonized 10-label sets.
What carries the argument
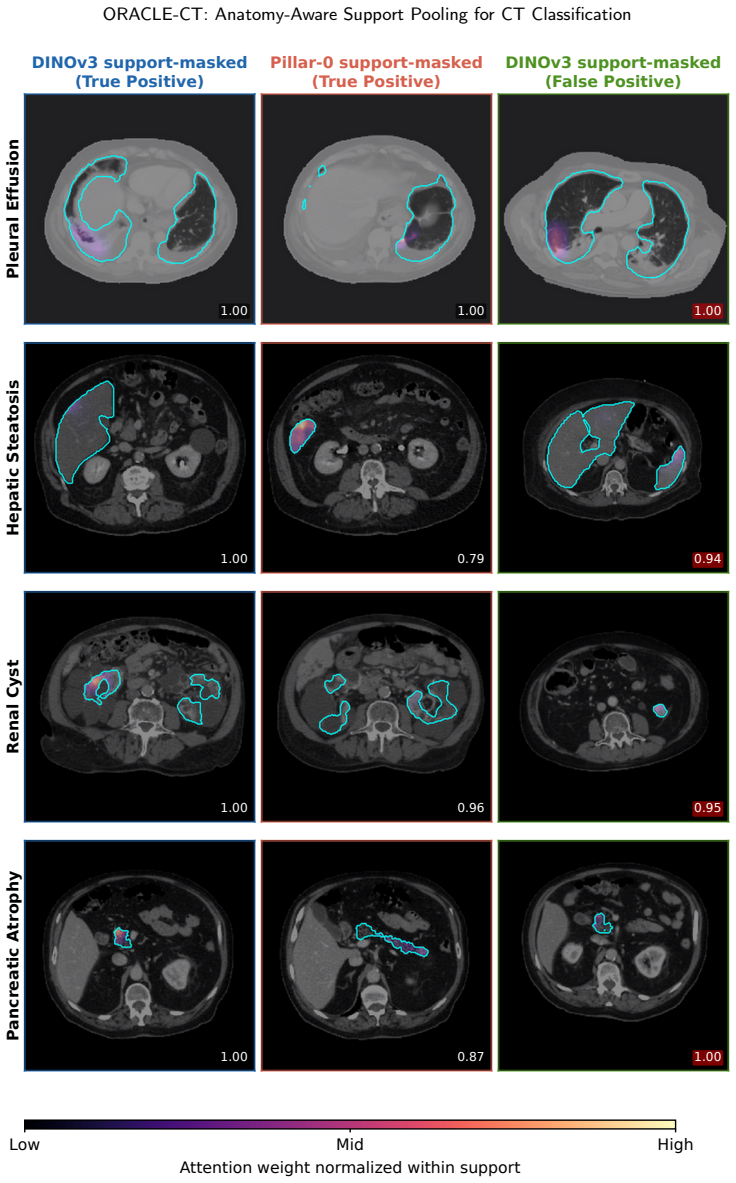
Support-masked pooling, which uses multi-organ segmentation to define label-specific anatomical supports and restricts attention pooling to those regions.
If this is right
- Support-masked pooling raises performance for DINOv3 and I3D-ResNet-121 on both internal MERLIN metrics and external Duke-Abdomen/AMOS transfer.
- For the Pillar-0 encoder, most improvement comes from learned attention with smaller added benefit from anatomical masking.
- The framework preserves an auditable link between each prediction and the specific anatomical supports used.
- Multiple support strategies (single-organ, multi-organ union, comparative) are compatible with the same encoder backbone.
Where Pith is reading between the lines
- The gains suggest that many CT findings are sufficiently localized that global pooling dilutes the signal even when attention is learned.
- If segmentation quality varies across sites, the method may require domain-specific fine-tuning of the segmenter before pooling is applied.
- The approach could be extended to other 3D modalities provided reliable organ masks exist, though the paper does not test this.
Load-bearing premise
Accurate multi-organ segmentation is available and the segmented regions contain all diagnostic evidence without missing important information elsewhere in the scan.
What would settle it
On a dataset where disease evidence lies outside the segmented organs, support-masked pooling produces equal or lower AUROC than global average pooling.
Figures
read the original abstract
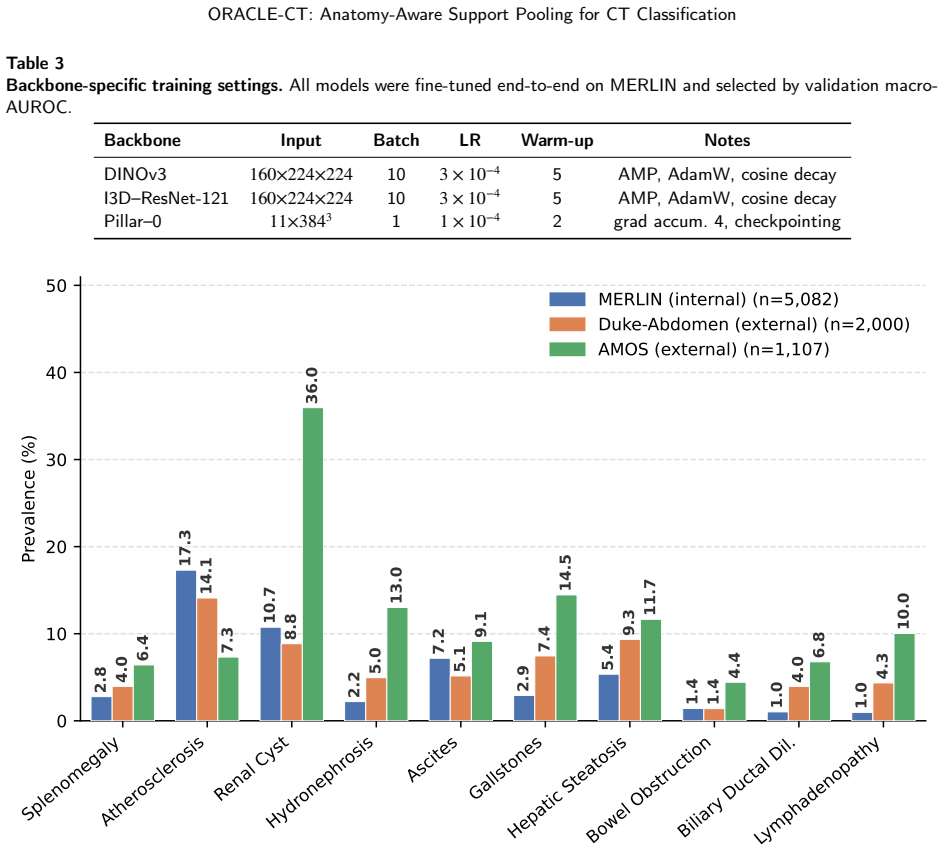
Abdominal CT disease classification is challenging because each scan is a large 3D volume with many possible findings, while diagnostic evidence is often confined to specific organs or anatomical compartments. Most study-level classifiers aggregate encoder features using anatomy-agnostic pooling or attention, creating a mismatch between localized disease evidence and global evidence aggregation. We propose ORACLE--CT, an encoder-agnostic anatomy-aware aggregation framework that uses multi-organ segmentation to define label-specific anatomical supports and restrict attention pooling to relevant regions. The framework supports single-organ, multi-organ union, comparative, localized, and global support strategies. We evaluate ORACLE--CT with three encoder families: DINOv3, I3D--ResNet-121, and the radiology-native Pillar--0 encoder. Models are trained end-to-end on MERLIN and evaluated internally and under frozen external transfer to Duke--Abdomen and AMOS. Compared with global average pooling, support-masked pooling improved MERLIN macro-AUROC/AUPRC from 0.838/0.638 to 0.858/0.676 for DINOv3 and from 0.829/0.617 to 0.848/0.659 for I3D--ResNet-121. On harmonized 10-label external evaluation, DINOv3 improved on Duke--Abdomen from 0.802/0.628 to 0.835/0.683 and on AMOS from 0.742/0.313 to 0.762/0.350, with similar gains for I3D--ResNet-121. For Pillar--0, most gains came from learned attention, with smaller additional benefit from anatomical masking. ORACLE--CT improves discrimination and external robustness while preserving an auditable link between predictions and anatomical evidence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ORACLE-CT, an encoder-agnostic framework for abdominal CT disease classification that defines label-specific anatomical supports via multi-organ segmentation and restricts pooling/attention to those regions using strategies such as single-organ, multi-organ union, and comparative supports. It evaluates the approach with DINOv3, I3D-ResNet-121, and Pillar-0 encoders trained on MERLIN, reporting AUROC/AUPRC gains over global average pooling both internally (e.g., DINOv3: 0.838/0.638 to 0.858/0.676) and on external transfer to Duke-Abdomen and AMOS (e.g., DINOv3 Duke: 0.802/0.628 to 0.835/0.683), while claiming improved discrimination, robustness, and auditability.
Significance. If the results hold after addressing segmentation validation, the work provides a concrete mechanism to align feature aggregation with localized anatomical evidence in volumetric CT, addressing a known mismatch in study-level classifiers. The consistent gains across encoders and the external-transfer setting are a strength; the auditable anatomical link is a secondary contribution that could aid clinical interpretability.
major comments (2)
- [Abstract / framework description] Abstract and framework description: The reported improvements depend on multi-organ segmentation accurately defining the supports without omitting diagnostic evidence outside segmented regions or introducing boundary errors. No Dice, Hausdorff, or other segmentation quality metrics are provided on MERLIN, Duke-Abdomen, or AMOS, and no ablation on segmentation noise is shown; this is load-bearing for the central claim that support-masked pooling yields the observed gains.
- [Evaluation] Evaluation: Performance deltas (e.g., DINOv3 MERLIN AUROC 0.838 o0.858) are presented as point estimates without error bars, standard deviations across runs, or statistical significance tests, making it impossible to determine whether the gains are robust or could arise from post-hoc choices in support strategy or hyperparameters.
minor comments (1)
- [Abstract] The abstract refers to a 'harmonized 10-label external evaluation' but provides no details on label mapping, harmonization procedure, or how the 10 labels align across datasets.
Simulated Author's Rebuttal
Thank you for the detailed review and the recommendation for major revision. We appreciate the focus on the dependence on segmentation quality and the need for statistical rigor in the reported results. Below we provide point-by-point responses and commit to revisions that address these concerns.
read point-by-point responses
-
Referee: [Abstract / framework description] Abstract and framework description: The reported improvements depend on multi-organ segmentation accurately defining the supports without omitting diagnostic evidence outside segmented regions or introducing boundary errors. No Dice, Hausdorff, or other segmentation quality metrics are provided on MERLIN, Duke-Abdomen, or AMOS, and no ablation on segmentation noise is shown; this is load-bearing for the central claim that support-masked pooling yields the observed gains.
Authors: We agree that the accuracy of the multi-organ segmentation is critical to the validity of our claims. The segmentation is performed using a pre-trained model, and while we did not include quantitative metrics in the initial submission, the framework's gains are demonstrated consistently across three different encoders and in external validation settings. To strengthen the manuscript, we will add Dice coefficient and other relevant metrics for the segmentation on the MERLIN dataset in a new section or appendix, along with a sensitivity analysis to simulated segmentation errors (e.g., boundary perturbations). This will directly address the load-bearing nature of this assumption. revision: yes
-
Referee: [Evaluation] Evaluation: Performance deltas (e.g., DINOv3 MERLIN AUROC 0.838 to 0.858) are presented as point estimates without error bars, standard deviations across runs, or statistical significance tests, making it impossible to determine whether the gains are robust or could arise from post-hoc choices in support strategy or hyperparameters.
Authors: We concur that providing measures of variability and statistical testing would improve the interpretability of the results. In the revised version, we will report mean and standard deviation of AUROC/AUPRC over at least three independent training runs with different random seeds for the key comparisons. Additionally, we will include p-values from appropriate statistical tests (such as the DeLong test for comparing AUROCs) to establish the significance of the observed improvements. revision: yes
Circularity Check
No significant circularity detected; empirical gains are measured, not constructed by definition.
full rationale
The paper describes an empirical framework that applies pre-existing multi-organ segmentation to mask pooling regions in encoder features, then reports measured AUROC/AUPRC improvements on held-out MERLIN data and external Duke/AMOS transfers. No derivation chain, equation, or first-principles claim reduces to its own inputs by construction. No self-citations are load-bearing for uniqueness or ansatz adoption, no fitted parameters are relabeled as predictions, and no renaming of known results occurs. The segmentation accuracy is an explicit modeling assumption whose validity is external to the reported performance deltas.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard definitions and computation of AUROC and AUPRC
Reference graph
Works this paper leans on
-
[1]
Pillar-0: A new frontier for radiology foundation models
Agrawal, K.K., Liu, L., Lian, L., Nercessian, M., Harguindeguy, N., Wu, Y., Mikhael, P., Lin, G., Sequist, L.V., Fintelmann, F., et al., 2025. Pillar-0: A new frontier for radiology foundation models. arXiv preprint arXiv:2511.17803
arXiv 2025
-
[2]
Neuralmachinetranslationbyjointlylearningtoalignandtranslate
Bahdanau,D.,Cho,K.,Bengio,Y.,2014. Neuralmachinetranslationbyjointlylearningtoalignandtranslate. arXivpreprintarXiv:1409.0473
Pith/arXiv arXiv 2014
-
[3]
A pan-organ vision-language model for generalizable 3d ct representations
Beeche, C., Kim, J., Tavolinejad, H., Zhao, B., Sharma, R., Duda, J., Gee, J., Dako, F., Verma, A., Morse, C., et al., 2025. A pan-organ vision-language model for generalizable 3d ct representations. medRxiv
2025
-
[4]
Abdomengen:Sequentialvolume-conditioneddiffusionframeworkforabdominalanatomy generation
Bhandari,Y.,Dahal,L.,Segars,P.,Lo,J.Y.,2026. Abdomengen:Sequentialvolume-conditioneddiffusionframeworkforabdominalanatomy generation. arXiv preprint arXiv:2604.12969
Pith/arXiv arXiv 2026
-
[5]
Blankemeier, L., Cohen, J.P., Kumar, A., Van Veen, D., Gardezi, S.J.S., Paschali, M., Chen, Z., Delbrouck, J.B., Reis, E., Truyts, C., et al.,
-
[6]
Research Square , rs–3
Merlin: A vision language foundation model for 3d computed tomography. Research Square , rs–3
-
[7]
Quovadis,actionrecognition?anewmodelandthekineticsdataset,in:proceedingsoftheIEEEConference on Computer Vision and Pattern Recognition, pp
Carreira,J.,Zisserman,A.,2017. Quovadis,actionrecognition?anewmodelandthekineticsdataset,in:proceedingsoftheIEEEConference on Computer Vision and Pattern Recognition, pp. 6299–6308
2017
-
[8]
Peritoneal carcinomatosis and its mimics: review of ct findings for differential diagnosis
Cho, J.H., Kim, S.S., 2020. Peritoneal carcinomatosis and its mimics: review of ct findings for differential diagnosis. Journal of the Belgian Society of Radiology 104, 8
2020
-
[9]
Foundation models for general ct image diagnosis challenge Accessed: 2026-05-02
CodaBench, 2026. Foundation models for general ct image diagnosis challenge Accessed: 2026-05-02
2026
-
[10]
Xcat 3.0: A comprehensive library of personalized digital twins derived from ct scans
Dahal, L., Ghojoghnejad, M., Vancoillie, L., Ghosh, D., Bhandari, Y., Kim, D., Ho, F.C., Tushar, F.I., Luo, S., Lafata, K.J., et al., 2025. Xcat 3.0: A comprehensive library of personalized digital twins derived from ct scans. Medical Image Analysis , 103636
2025
-
[11]
Solving the multiple instance problem with axis-parallel rectangles
Dietterich, T.G., Lathrop, R.H., Lozano-Pérez, T., 1997. Solving the multiple instance problem with axis-parallel rectangles. Artificial intelligence 89, 31–71. Lavsen Dahal et al.:Preprint submitted to ElsevierPage 19 of 25 ORACLE-CT: Anatomy-Aware Support Pooling for CT Classification
1997
-
[12]
An image is worth 16x16 words: Transformers for image recognition at scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al., 2020. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929
Pith/arXiv arXiv 2020
-
[13]
Machine-learning-based multiple abnormality prediction with large-scale chest computed tomography volumes
Draelos, R.L., Dov, D., Mazurowski, M.A., Lo, J.Y., Henao, R., Rubin, G.D., Carin, L., 2021. Machine-learning-based multiple abnormality prediction with large-scale chest computed tomography volumes. Medical image analysis 67, 101857
2021
-
[14]
Garcia-Alcoser, M.E., GhojoghNejad, M., Tushar, F.I., Kim, D., Lafata, K.J., Rubin, G.D., Lo, J.Y., 2025. Evaluating large language models for zero-shot disease labeling in ct radiology reports across organ systems. arXiv preprint arXiv:2506.03259
arXiv 2025
-
[15]
Diagnostic accuracy of ct for the detection of hepatic steatosis: a systematic review and meta-analysis
Haghshomar, M., Antonacci, D., Smith, A.D., Thaker, S., Miller, F.H., Borhani, A.A., 2024. Diagnostic accuracy of ct for the detection of hepatic steatosis: a systematic review and meta-analysis. Radiology 313, e241171
2024
-
[16]
Developing generalist foundation models from a multimodal dataset for 3d computed tomography
Hamamci, I.E., Er, S., Wang, C., Almas, F., Simsek, A.G., Esirgun, S.N., Doga, I., Durugol, O.F., Dai, W., Xu, M., et al., 2024. Developing generalist foundation models from a multimodal dataset for 3d computed tomography. arXiv preprint arXiv:2403.17834
arXiv 2024
-
[17]
Deep residual learning for image recognition, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp
He, K., Zhang, X., Ren, S., Sun, J., 2016. Deep residual learning for image recognition, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778
2016
-
[18]
Segmentation helps understanding: Mask-infused vision-language pre-training for 3d medical images
Hu, Y., Luo, X., Wang, Z., Li, D., Qiu, L., . Segmentation helps understanding: Mask-infused vision-language pre-training for 3d medical images
-
[19]
Attention-based deep multiple instance learning, in: International conference on machine learning, PMLR
Ilse, M., Tomczak, J., Welling, M., 2018. Attention-based deep multiple instance learning, in: International conference on machine learning, PMLR. pp. 2127–2136
2018
-
[20]
Le Guellec, B., Lefèvre, A., Geay, C., Shorten, L., Bruge, C., Hacein-Bey, L., Amouyel, P., Pruvo, J.P., Kuchcinski, G., Hamroun, A.,
-
[21]
Radiology: Artificial Intelligence 6, e230364
Performance of an open-source large language model in extracting information from free-text radiology reports. Radiology: Artificial Intelligence 6, e230364
-
[22]
Unified supervision for vision-language modeling in 3d computed tomography
Lee, H.C., Liu, Z., Ahmed, H., Kim, S., Huver, S., Nath, V., Fayad, Z.A., Deyer, T., Mei, X., 2025. Unified supervision for vision-language modeling in 3d computed tomography. arXiv preprint arXiv:2509.01554
arXiv 2025
-
[23]
Greenrfm: Toward a resource-efficient radiology foundation model
Li, Y., Ming, S., Zhao, M., Lai, H., Wang, R., Zhou, R., Wang, R., Li, Y., Wei, W., Zhou, S.K., 2026. Greenrfm: Toward a resource-efficient radiology foundation model. arXiv preprint arXiv:2603.06467
Pith/arXiv arXiv 2026
-
[24]
Lin, J., Xia, Y., Zhang, J., Yan, K., Lu, L., Luo, J., Zhang, L., 2024. Ct-glip: 3d grounded language-image pretraining with ct scans and radiology reports for full-body scenarios. arXiv preprint arXiv:2404.15272
arXiv 2024
-
[25]
Lin, M., Chen, Q., Yan, S., 2013. Network in network. arXiv preprint arXiv:1312.4400
Pith/arXiv arXiv 2013
-
[26]
Does dinov3 set a new medical vision standard? arXiv preprint arXiv:2509.06467
Liu, C., Chen, Y., Shi, H., Lu, J., Jian, B., Pan, J., Cai, L., Wang, J., Zhang, Y., Li, J., et al., 2025. Does dinov3 set a new medical vision standard? arXiv preprint arXiv:2509.06467
arXiv 2025
-
[27]
Effective approaches to attention-based neural machine translation
Luong, M.T., Pham, H., Manning, C.D., 2015. Effective approaches to attention-based neural machine translation. arXiv preprint arXiv:1508.04025
Pith/arXiv arXiv 2015
-
[28]
Distributionofintra-abdominalmalignantseeding:dependencyondynamicsofflowofasciticfluid
MEYERS,M.A.,1973. Distributionofintra-abdominalmalignantseeding:dependencyondynamicsofflowofasciticfluid. AmericanJournal of Roentgenology 119, 198–206
1973
-
[29]
Feasibility of using the privacy-preserving large language model vicuna for labeling radiology reports
Mukherjee, P., Hou, B., Lanfredi, R.B., Summers, R.M., 2023. Feasibility of using the privacy-preserving large language model vicuna for labeling radiology reports. Radiology 309, e231147
2023
-
[30]
Computed tomography (ct) exams URL:https://www.oecd.org/en/ data/indicators/computed-tomography-ct-exams.html
Organisation for Economic Co-operation and Development, 2025. Computed tomography (ct) exams URL:https://www.oecd.org/en/ data/indicators/computed-tomography-ct-exams.html. accessed: 2025-10-29
2025
-
[31]
Post-contrast ct liver attenuation alone is superior to the liver–spleen difference for identifying moderate hepatic steatosis
Pickhardt, P.J., Blake, G.M., Moeller, A., Garrett, J.W., Summers, R.M., 2024. Post-contrast ct liver attenuation alone is superior to the liver–spleen difference for identifying moderate hepatic steatosis. European Radiology 34, 7041–7052
2024
-
[32]
Imaging information overload: Quantifying the burden of interpretive and non-interpretive tasks for computed tomography angiography for aortic pathologies in emergency radiology
Pourvaziri,A.,Narayan,A.K.,Tso,D.,Baliyan,V.,GloverIV,M.,Bizzo,B.C.,Kako,B.,Succi,M.D.,Lev,M.H.,Flores,E.J.,2022. Imaging information overload: Quantifying the burden of interpretive and non-interpretive tasks for computed tomography angiography for aortic pathologies in emergency radiology. Current Problems in Diagnostic Radiology 51, 546–551
2022
-
[33]
Learning transferable visual models from natural language supervision, in: International conference on machine learning, PmLR
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al., 2021. Learning transferable visual models from natural language supervision, in: International conference on machine learning, PmLR. pp. 8748–8763
2021
-
[34]
A scoping review of large language model based approaches for information extraction from radiology reports
Reichenpfader, D., Müller, H., Denecke, K., 2024. A scoping review of large language model based approaches for information extraction from radiology reports. npj Digital Medicine 7, 222
2024
-
[35]
Sellergren, A., Kazemzadeh, S., Jaroensri, T., Kiraly, A., Traverse, M., Kohlberger, T., Xu, S., Jamil, F., Hughes, C., Lau, C., et al., 2025. Medgemma technical report. arXiv preprint arXiv:2507.05201
Pith/arXiv arXiv 2025
-
[36]
Large-scale and fine-grained vision-language pre-training for enhanced ct image understanding
Shui, Z., Zhang, J., Cao, W., Wang, S., Guo, R., Lu, L., Yang, L., Ye, X., Liang, T., Zhang, Q., et al., 2025. Large-scale and fine-grained vision-language pre-training for enhanced ct image understanding. arXiv preprint arXiv:2501.14548
arXiv 2025
-
[37]
syngo.via — get the full picture
Siemens Healthineers, . syngo.via — get the full picture. URL:https://www.siemens-healthineers.com/en-us/ molecular-imaging/pet-ct/syngo-via. siemens Healthineers USA
-
[38]
Bosniak classification of cystic renal masses, version 2019: an update proposal and needs assessment
Silverman, S.G., Pedrosa, I., Ellis, J.H., Hindman, N.M., Schieda, N., Smith, A.D., Remer, E.M., Shinagare, A.B., Curci, N.E., Raman, S.S., et al., 2019. Bosniak classification of cystic renal masses, version 2019: an update proposal and needs assessment. Radiology 292, 475–488
2019
-
[39]
Siméoni, O.,Vo, H.V.,Seitzer, M.,Baldassarre, F., Oquab,M., Jose,C., Khalidov,V., Szafraniec, M.,Yi, S.,Ramamonjisoa, M.,et al.,2025. Dinov3. arXiv preprint arXiv:2508.10104
Pith/arXiv arXiv 2025
-
[40]
Projectedlifetimecancerrisksfromcurrentcomputedtomographyimaging
Smith-Bindman, R., Chu, P.W., Firdaus, H.A., Stewart, C., Malekhedayat, M., Alber, S., Bolch, W.E., Mahendra, M., de González, A.B., Miglioretti,D.L.,2025. Projectedlifetimecancerrisksfromcurrentcomputedtomographyimaging. JAMAinternalmedicine185,710–719
2025
-
[41]
Simpleware auto segmentation tools
Synopsys, . Simpleware auto segmentation tools. URL:https://www.synopsys.com/simpleware/software/auto-segmentation. html. synopsys Simpleware
-
[42]
Classificationofmultiplediseases on body ct scans using weakly supervised deep learning
Tushar,F.I.,D’Anniballe,V.M.,Hou,R.,Mazurowski,M.A.,Fu,W.,Samei,E.,Rubin,G.D.,Lo,J.Y.,2021. Classificationofmultiplediseases on body ct scans using weakly supervised deep learning. Radiology: Artificial Intelligence 4, e210026
2021
-
[43]
Attention is all you need
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I., 2017. Attention is all you need. Advances in neural information processing systems 30. Lavsen Dahal et al.:Preprint submitted to ElsevierPage 20 of 25 ORACLE-CT: Anatomy-Aware Support Pooling for CT Classification
2017
-
[44]
Quantifying radiology resident fatigue: analysis of preliminary reports
Vosshenrich, J., Brantner, P., Cyriac, J., Boll, D.T., Merkle, E.M., Heye, T., 2021. Quantifying radiology resident fatigue: analysis of preliminary reports. Radiology 298, 632–639
2021
-
[45]
Wald, T., Hamamci, I.E., Gao, Y., Bond-Taylor, S., Sharma, H., Ilse, M., Lo, C., Melnichenko, O., Codella, N.C., Wetscherek, M.T., et al.,
-
[46]
arXiv preprint arXiv:2510.15042
Comprehensive language-image pre-training for 3d medical image understanding. arXiv preprint arXiv:2510.15042
-
[47]
Non-local neural networks, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp
Wang, X., Girshick, R., Gupta, A., He, K., 2018. Non-local neural networks, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 7794–7803
2018
-
[48]
Totalsegmentator: robust segmentation of 104 anatomic structures in ct images
Wasserthal, J., Breit, H.C., Meyer, M.T., Pradella, M., Hinck, D., Sauter, A.W., Heye, T., Boll, D.T., Cyriac, J., Yang, S., et al., 2023. Totalsegmentator: robust segmentation of 104 anatomic structures in ct images. Radiology: Artificial Intelligence 5, e230024
2023
-
[49]
Show, attend and tell: Neural image caption generation with visual attention, in: International conference on machine learning, PMLR
Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhudinov, R., Zemel, R., Bengio, Y., 2015. Show, attend and tell: Neural image caption generation with visual attention, in: International conference on machine learning, PMLR. pp. 2048–2057
2015
-
[50]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al., 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388
Pith/arXiv arXiv 2025
-
[51]
Deep sets
Zaheer, M., Kottur, S., Ravanbakhsh, S., Poczos, B., Salakhutdinov, R.R., Smola, A.J., 2017. Deep sets. Advances in neural information processing systems 30
2017
-
[52]
Metrics are computed over the full 30-label MERLIN test set
Supplementary Material Lavsen Dahal et al.:Preprint submitted to ElsevierPage 21 of 25 ORACLE-CT: Anatomy-Aware Support Pooling for CT Classification Table S7 MERLIN full 30-label performance with 95% bootstrap confidence intervals.Values are macro-averaged point estimates with 95% bootstrap confidence intervals in brackets. Metrics are computed over the ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.