The Geometry of Sequential Learning: Lie-Bracket Prediction of Transfer Order
Pith reviewed 2026-06-26 00:09 UTC · model grok-4.3
The pith
The order effect in sequential learning is predicted by the Lie-bracket commutator of gradient update fields.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Lie-bracket commutator of gradient update fields governs the local order effect in sequential learning, providing a pairwise score for transfer direction that extends to an efficient many-domain scheduling algorithm via Hessian symmetry.
What carries the argument
The Lie-bracket commutator of gradient update fields, which computes a score for whether A precedes B or vice versa in a curriculum.
If this is right
- The method achieves 98.1 percent pairwise accuracy for instruction SFT at the first step.
- It recovers the best schedule among all 6 possible orders for three sources in 87.5 percent of cases.
- Source domains are ranked in the 99th percentile for a Python target among 85 options.
- Performance on 56 MMLU subjects reaches the 99th sampled percentile.
Where Pith is reading between the lines
- The same commutator idea might apply to choosing order in reinforcement learning curricula.
- It suggests viewing optimization trajectories as non-commuting vector fields in parameter space.
- One could test whether the method works for non-gradient methods like evolutionary strategies.
Load-bearing premise
That the Lie-bracket commutator computed from gradients accurately matches the empirically observed better transfer order between pairs of domains.
What would settle it
Finding a pair of source domains where the sign of the Lie bracket predicts one order but experiments show the opposite order yields better performance on the target.
Figures
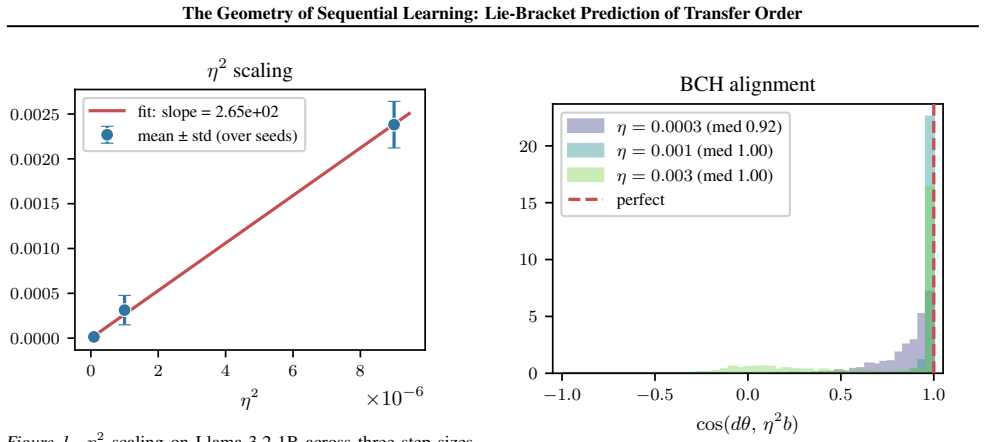
read the original abstract
Sequential learning is order-dependent: from Pile-style next-token domain adaptation to instruction-SFT and DPO, N candidate sources induce N! possible curricula. We show that the local order effect is governed by a computable geometric quantity, the Lie-bracket commutator of gradient update fields, yielding a pairwise score for whether A->B or B->A is better for a target domain. The pairwise bracket primitive also defines a Lie-Bracket Tournament: with a shared theta_0 target-gradient reference, Hessian symmetry gives Borda/row-sum scores from one Hessian-vector product per source, O(N) dot products, and an O(N log N) sort, without materializing the O(N^2) edge matrix. Empirically, the planner reaches 98.1%/98.9% pairwise accuracy at k=1 for instruction-SFT/DPO, remains at 73.1%/72.2% at k=20, and preserves the original pretraining-domain evidence with 82.4-92.0% accuracy across four LLMs and 91.1% on diffusion. At curriculum scale, it recovers the best of all 3! schedules in 87.5% of trials, ranks 85 Stack programming-language source domains for a Python target in the 99th sampled percentile, and reaches the 99.0-99.6th sampled percentile on 56 MMLU subjects, sharply above the reported descending gradient-norm baseline. These results reframe sequential learning as a geometric tournament problem: commutators provide both local pairwise order information and a scalable primitive for many-domain schedules.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that the local order effect in sequential learning is governed by the Lie-bracket commutator of gradient update fields, which yields a pairwise score for whether A->B or B->A is better for a target domain. It introduces a Lie-Bracket Tournament that computes Borda/row-sum rankings from one Hessian-vector product per source (via shared theta_0 and Hessian symmetry), achieving O(N) HVPs plus O(N log N) sort, and reports empirical pairwise accuracies of 98.1%/98.9% at k=1 (instruction-SFT/DPO), 73.1%/72.2% at k=20, 82.4-92.0% on pretraining domains across four LLMs, 91.1% on diffusion, plus strong recovery of optimal 3! schedules (87.5%) and high-percentile rankings on Stack and MMLU tasks, outperforming a descending gradient-norm baseline.
Significance. If the geometric claim holds, the work reframes curriculum design as a tournament problem solvable via a scalable, parameter-free primitive derived from the commutator, with direct applicability to efficient domain adaptation and fine-tuning pipelines; the O(N) scaling and outperformance over the reported baseline are notable strengths.
major comments (3)
- [Abstract, §3] Abstract and the derivation preceding Eq. (the score formula): the claim that the Lie-bracket commutator 'governs' the order effect (rather than correlates) rests on the construction from one HVP per source plus Hessian symmetry, yet the manuscript provides no explicit comparison showing that simpler quantities (e.g., gradient inner products or norm ratios evaluated at the same shared theta_0) yield strictly lower pairwise accuracy; without this, the uniqueness of the bracket as the governing object remains unestablished.
- [§4, Table reporting k=20 accuracies] §4 (empirical section) and the k=20 results: the drop from 98+% pairwise accuracy at k=1 to 73%/72% at k=20 indicates that the local commutator approximation degrades for longer sequences, which directly affects the central claim that the tournament primitive scales to realistic curricula; the manuscript does not quantify how many additional HVPs or higher-order terms would be needed to restore accuracy.
- [§5.1] §5.1 (tournament construction): the reduction to O(N) HVPs via Borda scores assumes the commutator is antisymmetric and that row-sum aggregation preserves the optimal global order; no sensitivity analysis is given for violations of the shared theta_0 reference or for cases where the Hessian is not symmetric in the relevant tangent space.
minor comments (2)
- [§2] Notation for the gradient update fields and the precise definition of the Lie bracket (including any truncation or approximation) should be stated explicitly in one place rather than distributed across the derivation.
- [§4] The diffusion-model experiment (91.1% accuracy) is reported without the corresponding baseline comparison or number of domains; adding this would strengthen the generality claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and the derivation preceding Eq. (the score formula): the claim that the Lie-bracket commutator 'governs' the order effect (rather than correlates) rests on the construction from one HVP per source plus Hessian symmetry, yet the manuscript provides no explicit comparison showing that simpler quantities (e.g., gradient inner products or norm ratios evaluated at the same shared theta_0) yield strictly lower pairwise accuracy; without this, the uniqueness of the bracket as the governing object remains unestablished.
Authors: Section 3 derives the bracket as the leading non-commutativity term in the expansion of the order effect between vector fields. We agree an explicit comparison would better support the governing claim over correlation. The revision will add an ablation in §4 comparing bracket scores to gradient inner products and norm ratios at the shared theta_0, showing superior pairwise accuracy. revision: yes
-
Referee: [§4, Table reporting k=20 accuracies] §4 (empirical section) and the k=20 results: the drop from 98+% pairwise accuracy at k=1 to 73%/72% at k=20 indicates that the local commutator approximation degrades for longer sequences, which directly affects the central claim that the tournament primitive scales to realistic curricula; the manuscript does not quantify how many additional HVPs or higher-order terms would be needed to restore accuracy.
Authors: The accuracy drop at k=20 is consistent with the first-order local nature of the approximation, which targets pairwise decisions; longer sequences involve accumulated higher-order effects. The method still outperforms the baseline at k=20. Exact quantification of additional HVPs for higher-order terms requires a new multi-commutator analysis beyond current scope. We will revise §4 to discuss this degradation explicitly as a limitation and future direction. revision: partial
-
Referee: [§5.1] §5.1 (tournament construction): the reduction to O(N) HVPs via Borda scores assumes the commutator is antisymmetric and that row-sum aggregation preserves the optimal global order; no sensitivity analysis is given for violations of the shared theta_0 reference or for cases where the Hessian is not symmetric in the relevant tangent space.
Authors: Antisymmetry follows from the Lie bracket definition, and Borda aggregation is standard for tournament rankings. The shared theta_0 is the canonical local reference point. We will expand §5.1 with discussion of these assumptions, including validity of Hessian symmetry under the Euclidean metric and a note on robustness to small theta_0 perturbations. revision: partial
Circularity Check
No circularity: commutator score derived independently of target order data
full rationale
The derivation computes a pairwise transfer score directly from the Lie bracket [∇_A, ∇_B] evaluated at shared θ_0 via one HVP per source plus Hessian symmetry and O(N) dot products. This construction uses only the gradient fields and their commutator; it does not fit any parameter to the empirical A→B vs B→A outcomes that are later used for validation. Reported accuracies (98.1 % at k=1, etc.) are post-hoc comparisons against held-out order effects, not inputs to the formula. No self-citations, self-definitional steps, or renaming of known results appear in the load-bearing equations. The central geometric claim therefore remains independent of the target performance data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Symmetry of the Hessian matrix
Reference graph
Works this paper leans on
-
[1]
Proceedings of the American Mathematical Society , volume=
On the product of semi-groups of operators , author=. Proceedings of the American Mathematical Society , volume=. 1959 , doi=
1959
-
[2]
International Conference on Machine Learning , pages=
Curriculum learning , author=. International Conference on Machine Learning , pages=
-
[3]
Proceedings of NAACL-HLT 2019 , pages=
Transfer learning in natural language processing , author=. Proceedings of NAACL-HLT 2019 , pages=
2019
-
[4]
Advances in Neural Information Processing Systems , volume=
Efficiently identifying task groupings for multi-task learning , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
Advances in Neural Information Processing Systems , volume=
Gradient surgery for multi-task learning , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
2006 , publisher=
Geometric numerical integration: structure-preserving algorithms for ordinary differential equations , author=. 2006 , publisher=
2006
-
[7]
Neural Computation , volume=
Fast exact multiplication by the Hessian , author=. Neural Computation , volume=. 1994 , publisher=
1994
-
[8]
Proceedings of the National Academy of Sciences , volume=
Overcoming catastrophic forgetting in neural networks , author=. Proceedings of the National Academy of Sciences , volume=. 2017 , publisher=
2017
-
[9]
Proceedings of the London Mathematical Society , volume=
Alternants and continuous groups , author=. Proceedings of the London Mathematical Society , volume=
-
[10]
Proceedings of the London Mathematical Society , volume=
On a law of combination of operators bearing on the theory of continuous transformation groups , author=. Proceedings of the London Mathematical Society , volume=. 1896 , month=
-
[11]
Berichte der S
Die symbolische Exponentialformel in der Gruppentheorie , author=. Berichte der S
-
[12]
Advances in Neural Information Processing Systems , volume=
Attention is all you need , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Advances in Neural Information Processing Systems , volume=
Denoising diffusion probabilistic models , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
International Conference on Learning Representations , year=
Decoupled weight decay regularization , author=. International Conference on Learning Representations , year=
-
[15]
International Conference on Learning Representations , year=
LoRA: Low-rank adaptation of large language models , author=. International Conference on Learning Representations , year=
-
[16]
arXiv preprint arXiv:2302.13971 , year=
LLaMA: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
-
[17]
2024 , eprint =
The Llama 3 Herd of Models , author =. 2024 , eprint =
2024
-
[18]
2024 , howpublished =
Llama 3.2: Revolutionizing edge. 2024 , howpublished =
2024
-
[19]
arXiv preprint arXiv:2407.10671 , year=
Qwen2 Technical Report , author=. arXiv preprint arXiv:2407.10671 , year=
-
[20]
2024 , eprint =
Qwen2.5 Technical Report , author =. 2024 , eprint =
2024
-
[21]
2025 , month=
SmolLM3: smol, multilingual, long-context reasoner , author=. 2025 , month=
2025
-
[22]
2025 , eprint=
HessFormer: Hessians at Foundation Scale , author=. 2025 , eprint=
2025
-
[23]
arXiv preprint arXiv:2501.15556 , year=
Commute Your Domains: Trajectory Optimality Criterion for Multi-Domain Learning , author=. arXiv preprint arXiv:2501.15556 , year=
-
[24]
Proceedings of the 35th International Conference on Machine Learning , series=
GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks , author=. Proceedings of the 35th International Conference on Machine Learning , series=. 2018 , publisher=
2018
-
[25]
Proceedings of the 39th International Conference on Machine Learning , series=
Multi-Task Learning as a Bargaining Game , author=. Proceedings of the 39th International Conference on Machine Learning , series=. 2022 , publisher=
2022
-
[26]
Proceedings of the 43rd International Conference on Machine Learning , series=
The Geometry of Updates: Fisher Alignment at Vocabulary Scale , author=. Proceedings of the 43rd International Conference on Machine Learning , series=. 2026 , publisher=
2026
-
[27]
International Conference on Learning Representations , year=
Gradient Vaccine: Investigating and Improving Multi-task Optimization in Massively Multilingual Models , author=. International Conference on Learning Representations , year=
-
[28]
International Conference on Learning Representations , year=
Sequential Reptile: Inter-Task Gradient Alignment for Multilingual Learning , author=. International Conference on Learning Representations , year=
-
[29]
Proceedings of the 37th International Conference on Machine Learning , series=
Understanding Self-Training for Gradual Domain Adaptation , author=. Proceedings of the 37th International Conference on Machine Learning , series=. 2020 , publisher=
2020
-
[30]
International Conference on Learning Representations , year=
Gradual Domain Adaptation via Gradient Flow , author=. International Conference on Learning Representations , year=
-
[31]
Proceedings of the 34th International Conference on Machine Learning , series=
Understanding Black-box Predictions via Influence Functions , author=. Proceedings of the 34th International Conference on Machine Learning , series=. 2017 , publisher=
2017
-
[32]
Advances in Neural Information Processing Systems , volume=
Estimating Training Data Influence by Tracing Gradient Descent , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
Advances in Neural Information Processing Systems , volume=
Order Matters in the Presence of Dataset Imbalance for Multilingual Learning , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
arXiv preprint arXiv:2101.00027 , year=
The Pile: An 800GB Dataset of Diverse Text for Language Modeling , author=. arXiv preprint arXiv:2101.00027 , year=
-
[35]
33rd British Machine Vision Conference (BMVC) , year=
Multi-task Curriculum Learning Based on Gradient Similarity , author=. 33rd British Machine Vision Conference (BMVC) , year=
-
[36]
2026 , eprint=
Mechanistic Analysis of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning , author=. 2026 , eprint=
2026
-
[37]
arXiv preprint arXiv:2502.06544 , year=
Sequence Transferability and Task Order Selection in Continual Learning , author=. arXiv preprint arXiv:2502.06544 , year=
-
[38]
de Borda, Jean-Charles , booktitle=. M\'. 1781 , pages=
-
[39]
Handbook of Computational Social Choice , editor=
-
[40]
2023 , howpublished=
Free Dolly: Introducing the World's First Truly Open Instruction-Tuned LLM , author=. 2023 , howpublished=
2023
-
[41]
Advances in Neural Information Processing Systems , volume=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
2023 , eprint=
UltraFeedback: Boosting Language Models with High-quality Feedback , author=. 2023 , eprint=
2023
-
[43]
International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.