LoRA vs. Full Fine-Tuning: A Theoretical Perspective
Pith reviewed 2026-05-20 12:10 UTC · model grok-4.3
The pith
LoRA can achieve lower excess risk than full fine-tuning when the difference between pretraining and downstream tasks is low-rank.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In a linear regression setting, LoRA achieves lower excess risk than full fine-tuning in both overdetermined and underdetermined regimes when the difference between the pretraining parameters and the optimal downstream parameters is effectively low-rank. The theory further shows that the LoRA rank controls a bias-variance tradeoff, so that a very small rank can improve generalization by limiting expressivity even though it reduces the model's capacity to fit the downstream data.
What carries the argument
The low-rank parameterization of the parameter difference between pretraining and downstream tasks, used to derive explicit excess-risk bounds that are compared against the bounds for updating every weight.
If this is right
- When the pretraining-to-downstream difference has low rank, LoRA with matching rank produces lower excess risk than updating all parameters.
- A small LoRA rank functions as regularization and can raise test accuracy by preventing the model from fitting noise.
- The identified advantage of LoRA holds in both overdetermined and underdetermined linear regression settings.
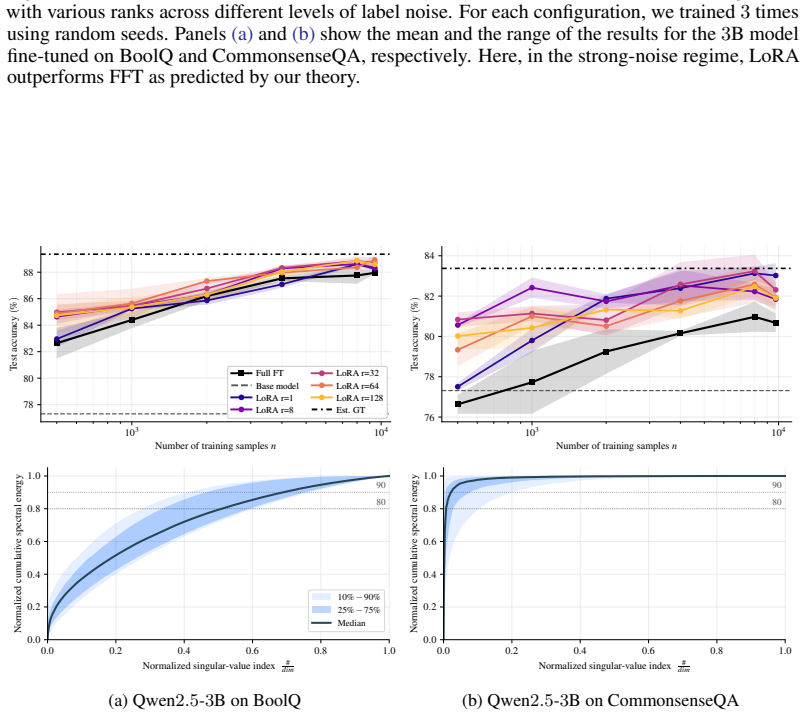
- Experiments on practical tasks indicate that the same tradeoffs appear outside the linear case.
Where Pith is reading between the lines
- Estimating the effective rank of a task difference before fine-tuning could guide the choice between LoRA and full updates.
- The low-rank shift idea may motivate hybrid adapters that apply full updates only on directions outside the low-rank subspace.
- Similar analysis could be tested on nonlinear networks by measuring the rank of activation differences or gradient updates between pretraining and downstream.
Load-bearing premise
The difference between pretraining and downstream tasks can be modeled as effectively low-rank.
What would settle it
In a controlled linear regression experiment where the optimal parameter shift is known to be low-rank, full fine-tuning shows lower test error than LoRA across multiple random seeds.
Figures











read the original abstract
Fine-tuning adapts a pre-trained model to downstream tasks using a small amount of labeled data. Low-Rank Adaptation (LoRA) is an efficient fine-tuning method that reduces memory and computation costs while often achieving performance close to full fine-tuning. Despite its widespread use, the theoretical behavior of LoRA is not yet well understood. In this paper, we study LoRA in a simple linear regression setting and compare its excess risk with that of full fine-tuning. Our analysis identifies regimes in which LoRA achieves lower excess risk than full fine-tuning in both overdetermined and underdetermined settings. Specifically, our theory predicts that LoRA can outperform full fine-tuning when the difference between the pretraining and the downstream tasks is effectively low-rank. We further show how the choice of LoRA rank affects generalization performance, explaining why using a very small rank can improve test accuracy in certain settings, even though it limits model expressivity. Finally, we support our theoretical results with experiments on practical tasks, suggesting that the identified tradeoffs and insights extend beyond linear regression.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes LoRA versus full fine-tuning in a linear regression setting, deriving closed-form excess-risk expressions for both methods in overdetermined and underdetermined regimes. It claims that LoRA achieves lower excess risk than full fine-tuning when the difference between pretraining and downstream tasks is low-rank, examines how LoRA rank affects generalization, and supports the theory with experiments on practical tasks.
Significance. If the derivations hold, the work supplies a concrete theoretical account of when and why parameter-efficient methods can outperform full fine-tuning, including an explanation for the benefit of small ranks in certain regimes. The identification of explicit low-rank conditions and the accompanying risk formulas constitute a useful step toward understanding fine-tuning trade-offs beyond empirical observation.
major comments (2)
- [Section 3] Section 3 (main theoretical derivations): the excess-risk comparison between LoRA and full fine-tuning is derived under the assumption that the task difference Δ is exactly (or effectively) rank-r. The risk expressions separate cleanly only when the sample covariance aligns with the column space of Δ; the manuscript does not bound the operator-norm distance between the covariance and this subspace or quantify the resulting additive bias term that LoRA would incur. This omission is load-bearing for the central claim that LoRA outperforms full fine-tuning in the stated regimes.
- [Theorem statements] Theorem statements (around the over- and under-determined cases): the low-rank modeling choice for Δ is presented as sufficient for the superiority result, yet no independent verification or sensitivity analysis is provided to show that the assumption is not chosen post-hoc to match the desired regime. Without such checks, the predicted advantage remains conditional on an untested modeling premise.
minor comments (2)
- [Notation] The notation for the pretraining weights and the downstream target could be introduced earlier and used consistently when defining excess risk.
- [Experiments] In the experimental section, it would help to report how closely the real-task weight differences approximate the low-rank assumption (e.g., via singular-value spectra).
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. The feedback identifies key assumptions in our theoretical analysis that warrant further clarification and strengthening. We respond to each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Section 3] Section 3 (main theoretical derivations): the excess-risk comparison between LoRA and full fine-tuning is derived under the assumption that the task difference Δ is exactly (or effectively) rank-r. The risk expressions separate cleanly only when the sample covariance aligns with the column space of Δ; the manuscript does not bound the operator-norm distance between the covariance and this subspace or quantify the resulting additive bias term that LoRA would incur. This omission is load-bearing for the central claim that LoRA outperforms full fine-tuning in the stated regimes.
Authors: We agree that the clean separation of risk expressions in Section 3 relies on alignment between the sample covariance and the column space of Δ. Our analysis isolates the low-rank effect under this condition, which is a standard modeling choice to derive explicit comparisons. To strengthen the result, we will revise the section to include a bound on the operator-norm distance between the covariance and the subspace, along with a quantification of the resulting additive bias in the excess-risk difference. This addition will demonstrate that LoRA retains an advantage under bounded misalignment, consistent with practical feature distributions. revision: yes
-
Referee: [Theorem statements] Theorem statements (around the over- and under-determined cases): the low-rank modeling choice for Δ is presented as sufficient for the superiority result, yet no independent verification or sensitivity analysis is provided to show that the assumption is not chosen post-hoc to match the desired regime. Without such checks, the predicted advantage remains conditional on an untested modeling premise.
Authors: The low-rank modeling of Δ is motivated by the structure of task differences observed in transfer learning and is explicitly stated as a condition in the theorems rather than presented as always true. Our experiments on practical tasks provide supporting evidence that effective rank is often low. To directly address the concern, we will add a sensitivity analysis consisting of additional simulations that vary the rank of Δ and report the resulting excess-risk comparisons, confirming that the predicted advantage is observed primarily in the low-rank regime. revision: yes
Circularity Check
No significant circularity; derivation self-contained under explicit assumptions
full rationale
The paper sets up a linear regression model with pretraining and downstream tasks, assumes the task difference Δ is low-rank (or effectively so), and derives closed-form excess risk expressions for full fine-tuning versus LoRA under that condition. The low-rank property is stated as the modeling choice that identifies the outperforming regime rather than being derived from or defined in terms of the risk expressions themselves. No equations reduce the claimed predictions to fitted parameters or prior self-citations by construction. Standard linear algebra steps for excess risk (involving covariance and projection) are used without requiring the covariance to commute with the subspace as an unstated hidden assumption that collapses the result. Experiments provide separate empirical support. The derivation chain is therefore independent of its inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- LoRA rank r
axioms (1)
- domain assumption The difference between pretraining and downstream tasks is effectively low-rank
Reference graph
Works this paper leans on
- [1]
-
[2]
Peter L Bartlett, Philip M Long, Gábor Lugosi, and Alexander Tsigler. Benign overfitting in linear regression.Proceedings of the National Academy of Sciences, 117(48):30063–30070, 2020
work page 2020
-
[3]
LoRA learns less and forgets less.Transactions on Machine Learning Research, 2024
Dan Biderman, Jacob Portes, Jose Javier Gonzalez Ortiz, Mansheej Paul, Philip Greengard, Connor Jennings, Daniel King, Sam Havens, Vitaliy Chiley, Jonathan Frankle, Cody Blakeney, and John Patrick Cunningham. LoRA learns less and forgets less.Transactions on Machine Learning Research, 2024. ISSN 2835-8856
work page 2024
-
[4]
Oxford University Press, Oxford, UK, 1 edition, 2013
Stéphane Boucheron, Gábor Lugosi, and Pascal Massart.Concentration Inequalities: A Nonasymptotic Theory of Independence. Oxford University Press, Oxford, UK, 1 edition, 2013. ISBN 978-0-19-953525-5
work page 2013
-
[5]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems. Curran Associates, Inc., 2020
work page 2020
-
[6]
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. PaLM: Scaling language modeling with pathways.Journal of Machine Learning Research, 24(240): 1–113, 2023
work page 2023
-
[7]
BoolQ: Exploring the surprising difficulty of natural yes/no questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. BoolQ: Exploring the surprising difficulty of natural yes/no questions. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long and Short Papers)....
work page 2019
-
[8]
QLoRA: Efficient finetuning of quantized LLMs
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA: Efficient finetuning of quantized LLMs. InAdvances in Neural Information Processing Systems. Curran Associates, Inc., 2023
work page 2023
-
[9]
BERT: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Confer- ence of the North American Chapter of the Association for Computational Linguistics: Human 10 Language Technologies (Volume 1: Long and Short Papers). Association for Computat...
work page 2019
-
[10]
Jesse Dodge, Gabriel Ilharco, Roy Schwartz, Ali Farhadi, Hannaneh Hajishirzi, and Noah Smith. Fine-tuning pretrained language models: Weight initializations, data orders, and early stopping. arXiv preprint arXiv:2002.06305, 2020
-
[11]
Generalized rank-constrained matrix approximations
Shmuel Friedland and Anatoli Torokhti. Generalized rank-constrained matrix approximations. SIAM Journal on Matrix Analysis and Applications, 29(2):656–659, 2007
work page 2007
-
[12]
Christophe Giraud.Introduction to High-Dimensional Statistics. Chapman and Hall/CRC, 2021
work page 2021
-
[13]
Yehoram Gordon. Some inequalities for Gaussian processes and applications.Israel Journal of Mathematics, 50(4):265–289, 1985
work page 1985
-
[14]
Trevor Hastie, Andrea Montanari, Saharon Rosset, and Ryan J Tibshirani. Surprises in high- dimensional ridgeless least squares interpolation.Annals of Statistics, 50(2):949–986, 2022
work page 2022
-
[15]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InThe Tenth International Conference on Learning Representations, 2022
work page 2022
-
[16]
Camels in a changing climate: Enhancing lm adaptation with tulu 2,
Hamish Ivison, Yizhong Wang, Valentina Pyatkin, Nathan Lambert, Matthew Peters, Pradeep Dasigi, Joel Jang, David Wadden, Noah A Smith, Iz Beltagy, et al. Camels in a changing climate: Enhancing LM adaptation with Tulu 2.arXiv preprint arXiv:2311.10702, 2023
-
[17]
Junsu Kim, Jaeyeon Kim, and Ernest K Ryu. LoRA training provably converges to a low-rank global minimum or it fails loudly (but it probably won’t fail). InProceedings of the 42nd International Conference on Machine Learning. PMLR, 2025
work page 2025
-
[18]
Sharp Generalization Bounds for Foundation Models with Asymmetric Ran- domized Low-Rank Adapters
Anastasis Kratsios, Tin Sum Cheng, Aurelien Lucchi, and Haitz Sáez de Ocáriz Borde. Sharp generalization bounds for foundation models with asymmetric randomized low-rank adapters. arXiv preprint arXiv:2506.14530, 2025
-
[19]
Philippe Rigollet and Jan-Christian Hütter. High-dimensional statistics.arXiv preprint arXiv:2310.19244, 2023
-
[20]
LoRA vs full fine-tuning: An illusion of equivalence
Reece Shuttleworth, Jacob Andreas, Antonio Torralba, and Pratyusha Sharma. LoRA vs full fine-tuning: An illusion of equivalence. InAdvances in Neural Information Processing Systems. Curran Associates, Inc., 2025
work page 2025
-
[21]
Jack W Silverstein. The smallest eigenvalue of a large dimensional Wishart matrix.The Annals of Probability, 13(4):1364–1368, 1985
work page 1985
-
[22]
Best approximate solutions to matrix equations under rank restrictions
Dieter Sondermann. Best approximate solutions to matrix equations under rank restrictions. Statistische Hefte, 27(1):57–66, 1986
work page 1986
-
[23]
CommonsenseQA: A question answering challenge targeting commonsense knowledge
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. CommonsenseQA: A question answering challenge targeting commonsense knowledge. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Lin- guistics: Human Language Technologies (Volume 1: Long and Short Papers). Association for Computationa...
work page 2019
-
[24]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. LLaMA: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Madeleine Udell and Alex Townsend. Why are big data matrices approximately low rank? SIAM Journal on Mathematics of Data Science, 1(1):144–160, 2019. 11
work page 2019
-
[26]
Qwen2.5 technical report, 2025
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tianyi T...
work page 2025
-
[27]
The expressive power of low-rank adaptation
Yuchen Zeng and Kangwook Lee. The expressive power of low-rank adaptation. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[28]
Yuanhe Zhang, Fanghui Liu, and Yudong Chen. LoRA-one: One-step full gradient could suffice for fine-tuning large language models, provably and efficiently. InProceedings of the 42nd International Conference on Machine Learning. PMLR, 2025
work page 2025
-
[29]
Terry Yue Zhuo, Armel Zebaze, Nitchakarn Suppattarachai, Leandro von Werra, Harm de Vries, Qian Liu, and Niklas Muennighoff. Astraios: Parameter-efficient instruction tuning code large language models.arXiv preprint arXiv:2401.00788, 2024
-
[30]
Fine-Tuning Language Models from Human Preferences
Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019. 12 Appendix I Summary of Notation Table 1: Summary of notation used in the paper Symbol Definition Mathematical definition / short note xi,x ...
work page internal anchor Pith review Pith/arXiv arXiv 1909
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.