Prefill/Decode-Aware Evaluation of LLM Inference on Emerging AI Accelerators
Pith reviewed 2026-06-27 04:07 UTC · model grok-4.3
The pith
GPUs lead the compute-heavy prefill phase of LLM inference while GroqRack leads decode at small batch sizes, with GPUs regaining the decode edge as batches grow.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
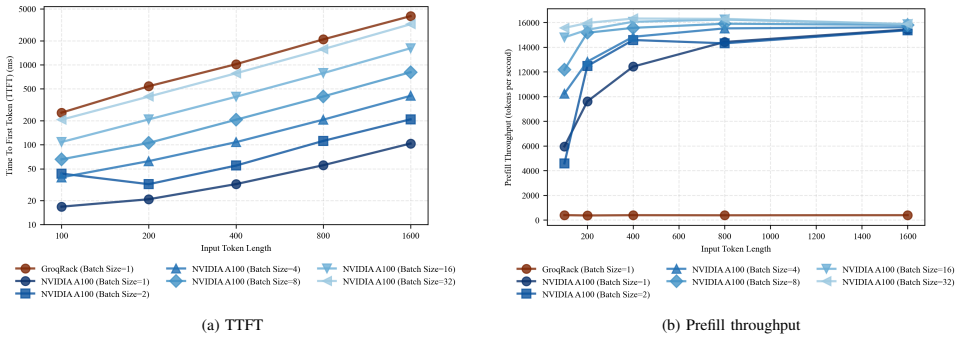
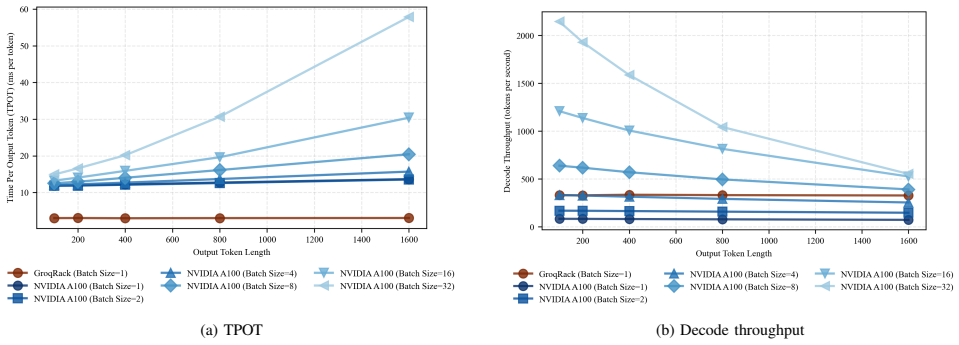
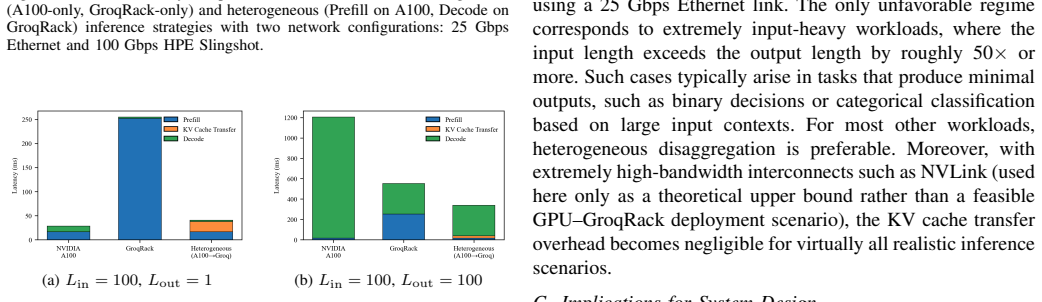
Separate measurements of prefill and decode on Llama2-7B demonstrate that GPUs consistently outperform in the compute-intensive prefill phase, GroqRack achieves significantly lower TPOT in decode when batching is not supported, and GPUs regain a decode throughput advantage as batch size increases. The same phase separation is used to evaluate heterogeneous disaggregation across accelerator platforms and to identify the conditions under which disaggregation improves end-to-end performance.
What carries the argument
phase-aware evaluation that isolates prefill (TTFT) and decode (TPOT) metrics and tests heterogeneous disaggregation across platforms
If this is right
- GPUs remain the default choice for prefill-dominant workloads.
- GroqRack offers a decode advantage only while batch sizes stay small and batching support is absent.
- Decode throughput leadership shifts back to GPUs once batch size increases.
- Heterogeneous prefill/decode disaggregation yields measurable gains only under specific workload sizes and network latencies.
Where Pith is reading between the lines
- Inference schedulers could route prefill and decode requests to different hardware types within the same cluster.
- Accelerator vendors might prioritize either high prefill throughput or low-latency decode depending on target use cases.
- Network bandwidth between disaggregated nodes becomes a first-order limit once phase separation is adopted at scale.
Load-bearing premise
Results from Llama2-7B on particular but unspecified hardware, batch sizes, and network setups are assumed to generalize to other models and real deployments.
What would settle it
Re-running the same prefill-versus-decode comparison on a second model family or at batch sizes where GroqRack maintains its decode lead without reversal would show the claimed phase-dependent platform strengths do not hold.
Figures

read the original abstract
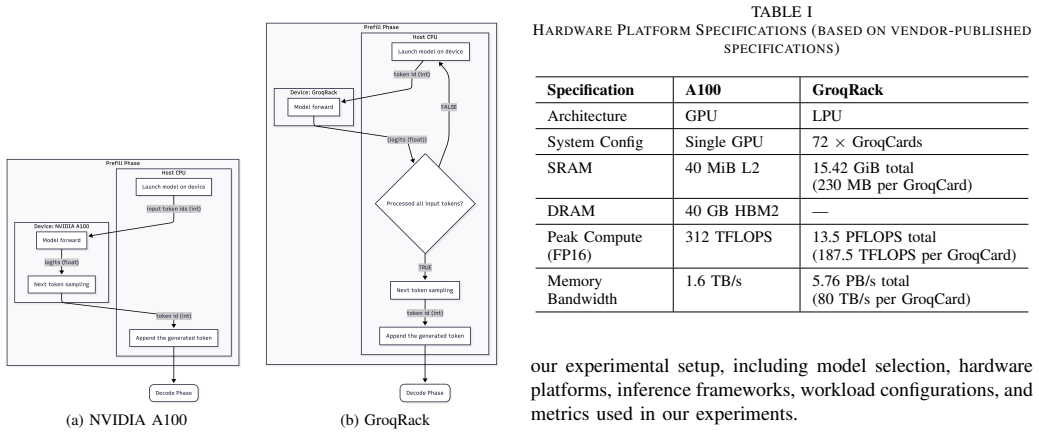
As large language models (LLMs) are increasingly deployed in latency- and cost-sensitive settings, inference efficiency has become a central systems challenge. While GPUs dominate current deployments, a growing number of AI accelerators claim advantages for LLM inference, yet it remains unclear under which conditions such accelerators outperform GPUs in practice. Recent inference systems decompose execution into Prefill and Decode phases, which exhibit distinct computational characteristics and latency metrics, commonly captured by time to first token (TTFT) and time per output token (TPOT). This paper presents a phase-aware evaluation of LLM inference performance across GPUs and emerging AI accelerators using a common model, Llama2-7B. By separately measuring Prefill and Decode performance, we reveal that accelerator advantages differ by phase and metric. Our results show that GPUs consistently excel in the compute-intensive Prefill phase, while GroqRack achieves significantly lower TPOT during Decode (batching not currently supported). However, GPUs regain an advantage in Decode throughput as batch size increases. These findings demonstrate that each platform exhibits distinct phase-dependent strengths. We further analyze heterogeneous Prefill/Decode disaggregation across different accelerator platforms, identifying performance gains and the workload and network conditions under which such gains are realized.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a phase-aware empirical evaluation of LLM inference performance on GPUs versus emerging accelerators (e.g., GroqRack) using Llama2-7B. It measures Prefill (TTFT) and Decode (TPOT/throughput) separately, claiming GPUs excel in compute-intensive Prefill while GroqRack shows lower Decode TPOT (noting no batching support on Groq), with GPUs regaining Decode throughput advantage at larger batches. It further examines heterogeneous Prefill/Decode disaggregation across platforms and identifies conditions for performance gains.
Significance. If the empirical measurements are representative and reproducible, the work offers practical guidance on phase-dependent hardware strengths and disaggregation trade-offs for latency-sensitive LLM serving, which could inform system design choices beyond current GPU-centric deployments.
major comments (3)
- [Abstract] Abstract and evaluation methodology: Batch sizes used for the reported Decode TPOT and throughput numbers are not stated. The central claim that 'GPUs regain an advantage in Decode throughput as batch size increases' cannot be assessed without explicit batch sizes, hardware SKUs, and measurement configurations.
- [Abstract] Abstract and disaggregation analysis: Hardware SKUs, interconnects, network latency/bandwidth, and exact configurations for the heterogeneous Prefill/Decode experiments are unspecified. This makes the identified 'workload and network conditions' under which disaggregation yields gains impossible to verify or generalize.
- [Abstract] Abstract: The evaluation is restricted to a single model (Llama2-7B). The phase-dependent advantage claims and disaggregation benefits rest on the assumption that this model's prefill/decode compute ratio is representative; no discussion or sensitivity analysis addresses transfer to other models.
minor comments (1)
- [Abstract] The abstract states directional results without error bars, statistical tests, or raw data tables; adding these would strengthen verifiability even if the central claims remain unchanged.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on clarity and generalizability. We will revise the manuscript to incorporate explicit details from the evaluation sections into the abstract and add discussion on model representativeness. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation methodology: Batch sizes used for the reported Decode TPOT and throughput numbers are not stated. The central claim that 'GPUs regain an advantage in Decode throughput as batch size increases' cannot be assessed without explicit batch sizes, hardware SKUs, and measurement configurations.
Authors: We agree the abstract omits these parameters. The full evaluation section details batch sizes (1-32), SKUs (e.g., specific GPU and GroqRack models), and measurement setups supporting the throughput crossover claim. We will revise the abstract to state the batch sizes and SKUs explicitly, with a pointer to the methods for full configurations. revision: yes
-
Referee: [Abstract] Abstract and disaggregation analysis: Hardware SKUs, interconnects, network latency/bandwidth, and exact configurations for the heterogeneous Prefill/Decode experiments are unspecified. This makes the identified 'workload and network conditions' under which disaggregation yields gains impossible to verify or generalize.
Authors: We acknowledge the abstract does not summarize these parameters. The manuscript's evaluation describes the SKUs, interconnects, and network conditions used. We will update the abstract to include a concise summary of hardware, interconnect, and network details for the disaggregation experiments. revision: yes
-
Referee: [Abstract] Abstract: The evaluation is restricted to a single model (Llama2-7B). The phase-dependent advantage claims and disaggregation benefits rest on the assumption that this model's prefill/decode compute ratio is representative; no discussion or sensitivity analysis addresses transfer to other models.
Authors: This is a fair observation on scope. We will add a discussion paragraph noting that Llama2-7B's prefill/decode characteristics are typical for decoder-only models and explicitly state the single-model limitation, recommending future multi-model validation. No new experiments will be added in this revision. revision: partial
Circularity Check
No circularity: purely empirical benchmarking with direct measurements
full rationale
The paper reports hardware measurements of TTFT and TPOT for Llama2-7B prefill and decode phases across GPUs and GroqRack, plus disaggregation experiments. No equations, fitted parameters, derivations, or self-referential claims appear in the abstract or described content. All central claims reduce to observed benchmark numbers rather than any constructed equivalence or self-citation chain. This is a standard empirical evaluation self-contained against external hardware runs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A survey of techniques for optimizing transformer inference,
K. T. Chitty-Venkata, S. Mittal, M. Emani, V . Vishwanath, and A. K. Somani, “A survey of techniques for optimizing transformer inference,” Journal of Systems Architecture, p. 102990, 2023
2023
-
[2]
A survey on efficient inference for large language models,
Z. Zhou, X. Ning, K. Hong, T. Fu, J. Xu, S. Li, Y . Lou, L. Wang, Z. Yuan, X. Liet al., “A survey on efficient inference for large language models,” arXiv preprint arXiv:2404.14294, 2024
Pith/arXiv arXiv 2024
-
[3]
{DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving,
Y . Zhong, S. Liu, J. Chen, J. Hu, Y . Zhu, X. Liu, X. Jin, and H. Zhang, “{DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving,” in18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), 2024, pp. 193–210
2024
-
[4]
Mlperf inference benchmark,
V . J. Reddi, C. Cheng, D. Kanter, P. Mattson, G. Schmuelling, C.-J. Wu, B. Anderson, M. Breughe, M. Charlebois, W. Chouet al., “Mlperf inference benchmark,” in2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2020, pp. 446– 459
2020
-
[5]
Efficient memory management for large language model serving with pagedattention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” inProceedings of the 29th symposium on operating systems principles, 2023, pp. 611–626
2023
-
[6]
Llm-inference- bench: Inference benchmarking of large language models on ai acceler- ators,
K. T. Chitty-Venkata, S. Raskar, B. Kale, F. Ferdaus, A. Tanikanti, K. Raffenetti, V . Taylor, M. Emani, and V . Vishwanath, “Llm-inference- bench: Inference benchmarking of large language models on ai acceler- ators,” inSC24-W: Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2024, pp. 1362–1379
2024
-
[7]
Think fast: A tensor streaming processor (tsp) for accelerating deep learning workloads,
D. Abts, J. Ross, J. Sparling, M. Wong-VanHaren, M. Baker, T. Hawkins, A. Bell, J. Thompson, T. Kahsai, G. Kimmellet al., “Think fast: A tensor streaming processor (tsp) for accelerating deep learning workloads,” in 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2020, pp. 145–158
2020
-
[8]
A software-defined tensor stream- ing multiprocessor for large-scale machine learning,
D. Abts, G. Kimmell, A. Ling, J. Kim, M. Boyd, A. Bitar, S. Parmar, I. Ahmed, R. DiCecco, D. Hanet al., “A software-defined tensor stream- ing multiprocessor for large-scale machine learning,” inProceedings of the 49th Annual International Symposium on Computer Architecture, 2022, pp. 567–580
2022
-
[9]
Llama 2: Open foundation and fine-tuned chat models,
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosaleet al., “Llama 2: Open foundation and fine-tuned chat models,”arXiv preprint arXiv:2307.09288, 2023
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.