An Improved Gradient Method with Approximately Optimal Stepsize Based on Conic model for Unconstrained Optimization
Pith reviewed 2026-05-24 18:09 UTC · model grok-4.3
The pith
A gradient method switches between conic and quadratic models to generate approximately optimal stepsizes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
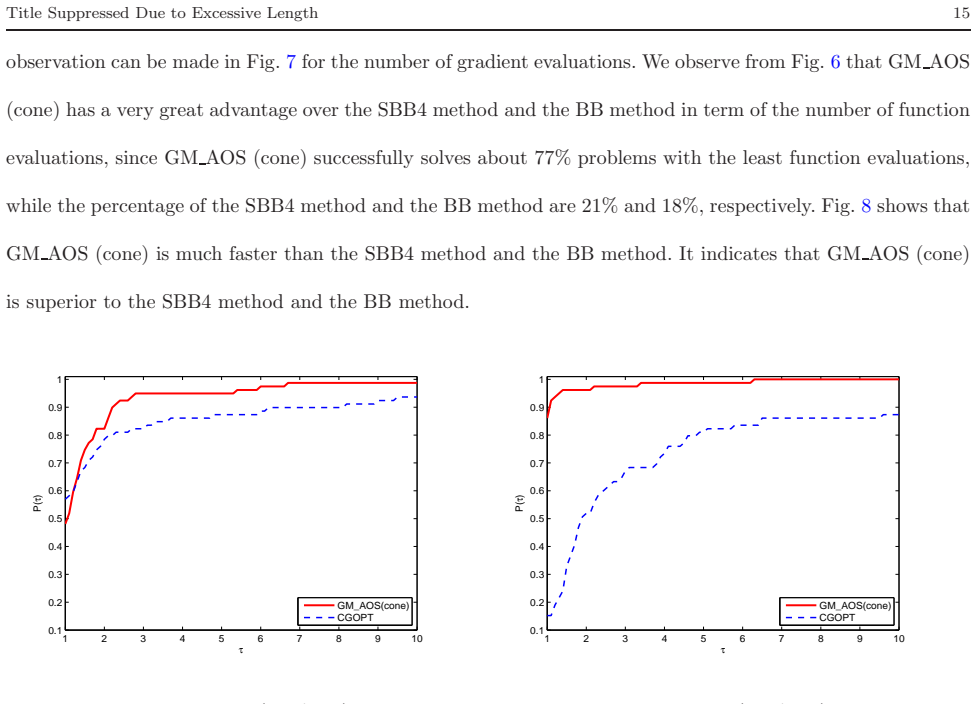
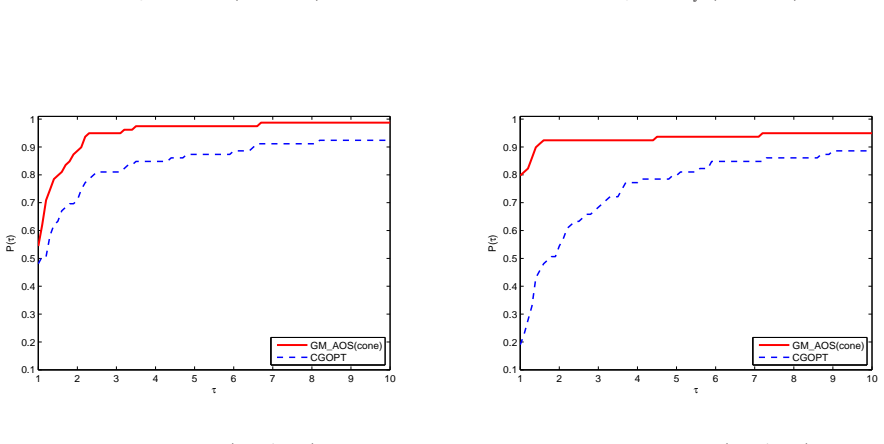
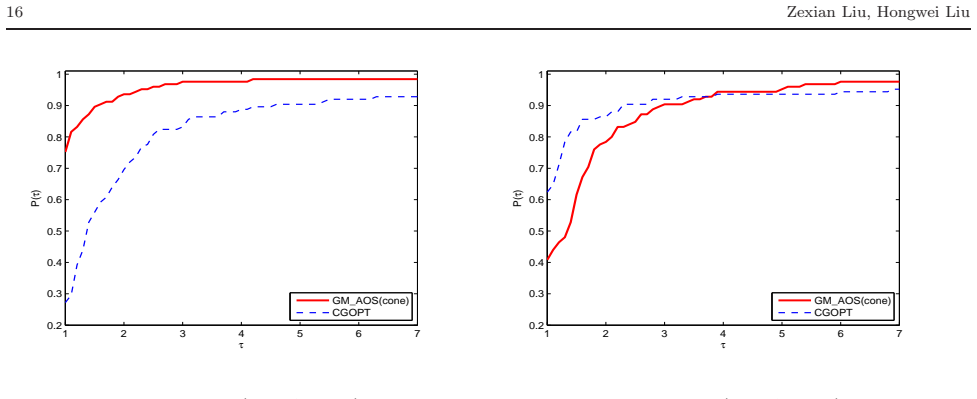
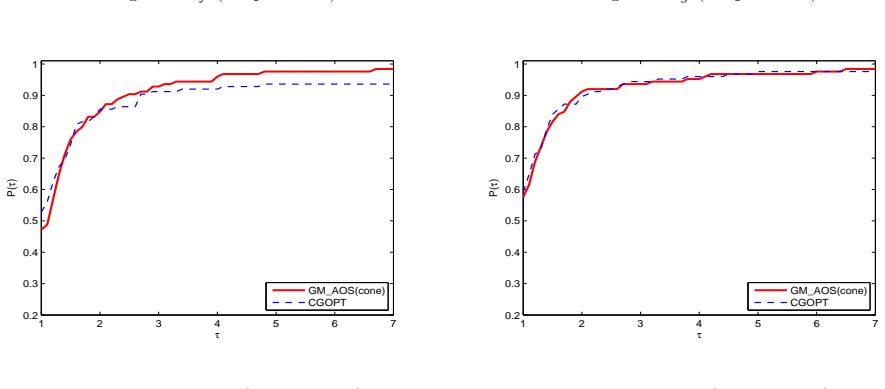
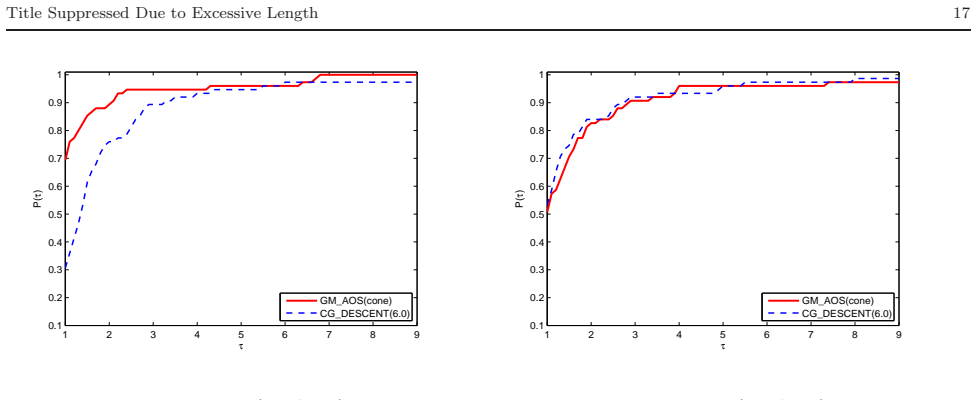
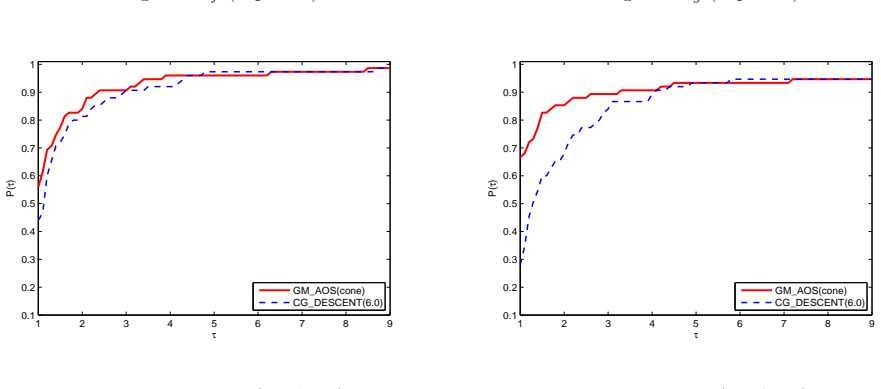
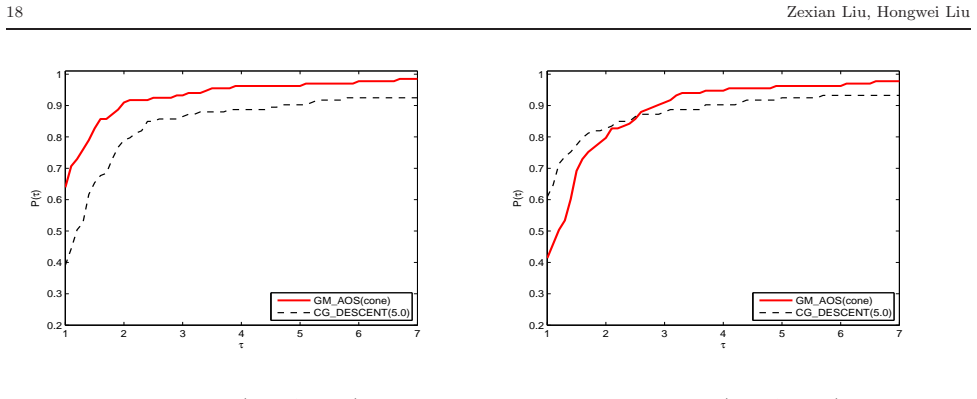
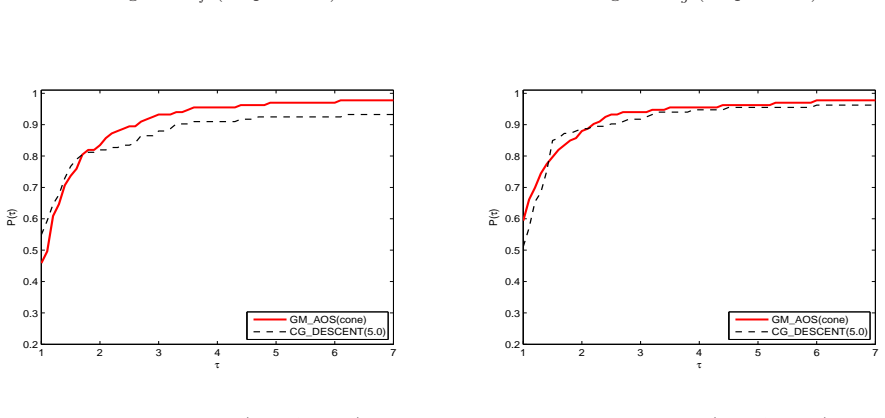
When the objective function is not close to quadratic on the line segment between the current and latest iterates, a conic model is constructed to generate an approximately optimal stepsize for the gradient method; otherwise quadratic models are used, yielding a convergent algorithm that performs well in numerical comparisons with CGDESCENT and CGOPT.
What carries the argument
The conic model that generates an approximately optimal stepsize for the gradient method when the objective deviates from quadratic behavior.
If this is right
- The algorithm converges under the stated conditions on the models and stepsizes.
- Numerical performance is competitive with established conjugate gradient solvers on the tested problems.
- Any gradient method can be interpreted as using approximately optimal stepsizes.
Where Pith is reading between the lines
- The switching rule between models could be applied to other first-order methods that rely on line searches.
- The approach may scale to larger problems if the conic model construction remains inexpensive.
- Further analysis could examine the frequency with which the conic model is actually invoked on typical test sets.
Load-bearing premise
A usable conic model can be constructed and will produce a reliable approximately optimal stepsize precisely when the objective is not close to quadratic on the line segment between iterates.
What would settle it
A collection of test problems where the objective is far from quadratic between iterates, yet the conic-model stepsize either prevents convergence or yields worse performance than standard quadratic-model choices.
Figures
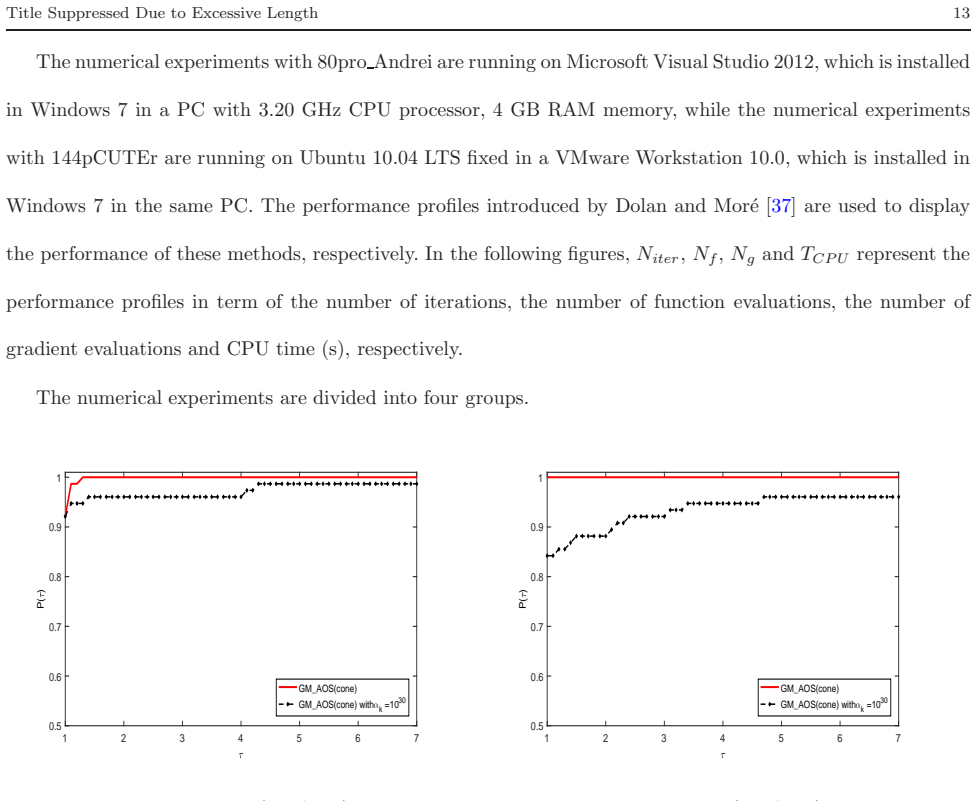
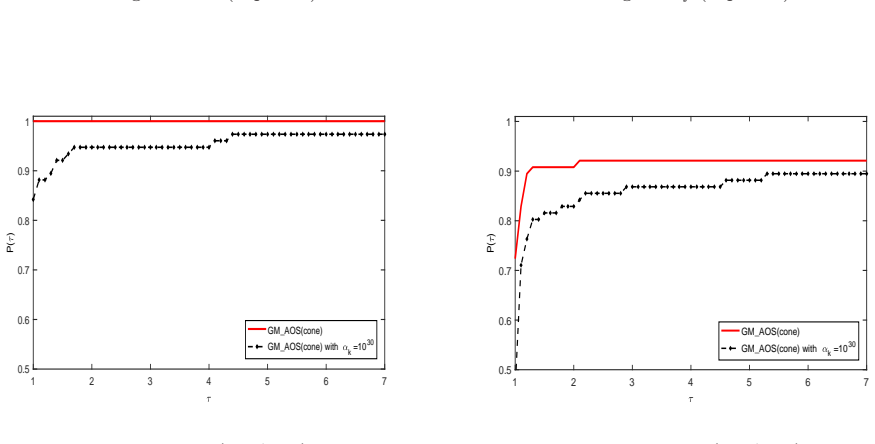
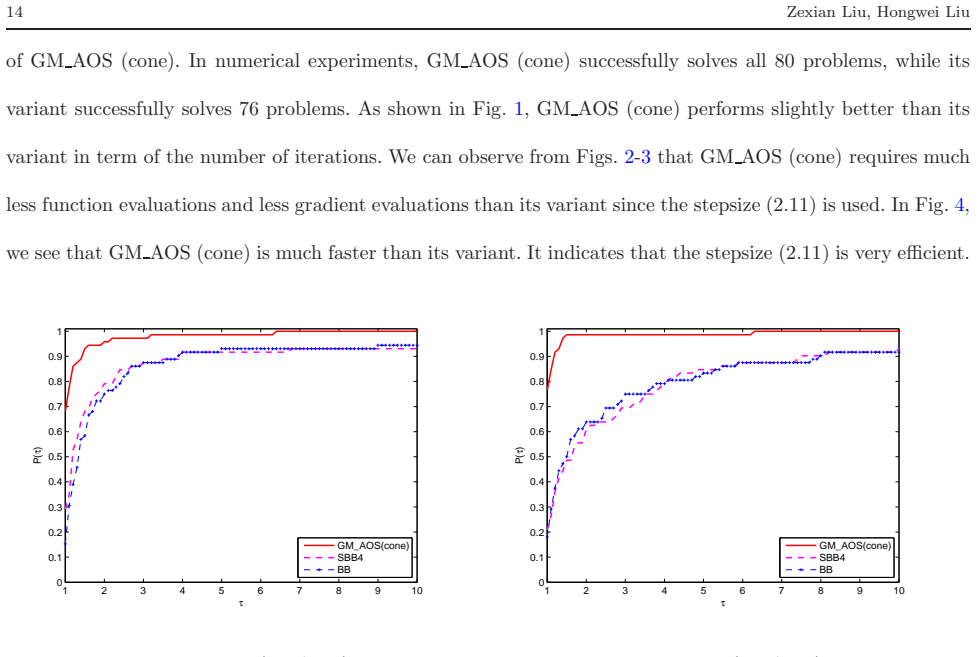
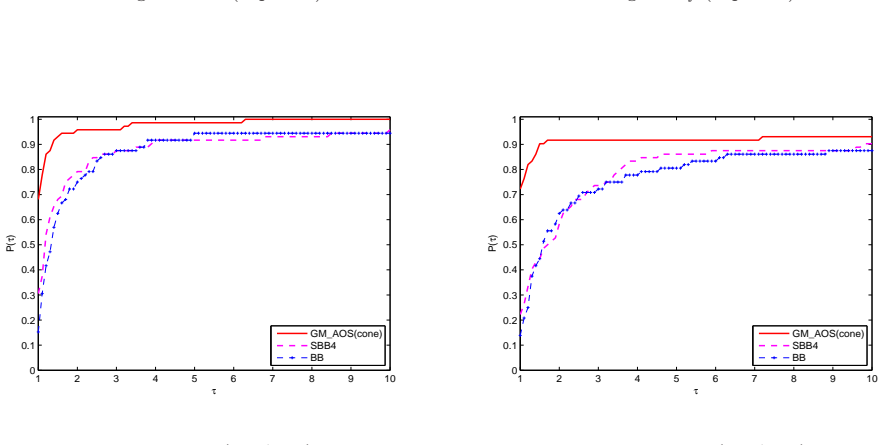
read the original abstract
A new type of stepsize, which was recently introduced by Liu and Liu (Optimization, 67(3), 427-440, 2018), is called approximately optimal stepsize and is quit efficient for gradient method. Interestingly, all gradient methods can be regarded as gradient methods with approximately optimal stepsizes. In this paper, based on the work (Numer. Algorithms 78(1), 21-39, 2018), we present an improved gradient method with approximately optimal stepsize based on conic model for unconstrained optimization. If the objective function $ f $ is not close to a quadratic on the line segment between the current and latest iterates, we construct a conic model to generate approximately optimal stepsize for gradient method if the conic model can be used; otherwise, we construct some quadratic models to generate approximately optimal stepsizes for gradient method. The convergence of the proposed method is analyzed under suitable conditions. Numerical comparisons with some well-known conjugate gradient software packages such as CG$ \_ $DESCENT (SIAM J. Optim. 16(1), 170-192, 2005) and CGOPT (SIAM J. Optim. 23(1), 296-320, 2013) indicate the proposed method is very promising.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an improved gradient method for unconstrained optimization that computes approximately optimal stepsizes. When the objective function is not close to quadratic on the line segment between the current and previous iterates, a conic model is constructed to generate the stepsize (provided the model can be used); otherwise quadratic models are used. Convergence is established under suitable conditions, and numerical experiments compare the method favorably to CGDESCENT and CGOPT.
Significance. If the central construction and convergence result hold, the adaptive choice between conic and quadratic models offers a principled way to improve stepsize selection in gradient methods beyond purely quadratic approximations. The explicit conditioning on deviation from quadratic behavior and the reported numerical comparisons against established CG packages constitute the main strengths.
major comments (1)
- [Method construction paragraph (abstract and §2–3)] Method construction paragraph (abstract and §2–3): the decision rule that determines whether 'the conic model can be used' is not stated explicitly. This criterion is load-bearing for the algorithm definition, the branch between conic and quadratic cases, and the subsequent convergence claim under suitable conditions.
minor comments (2)
- [Abstract] Abstract: 'quit efficient' should read 'quite efficient'.
- [Abstract] Abstract: the package name appears as 'CG$ _ $DESCENT'; consistent formatting (e.g., CG_DESCENT) is needed.
Simulated Author's Rebuttal
We thank the referee for the careful reading of the manuscript and for highlighting this important point regarding clarity of the algorithm. We address the major comment below.
read point-by-point responses
-
Referee: Method construction paragraph (abstract and §2–3): the decision rule that determines whether 'the conic model can be used' is not stated explicitly. This criterion is load-bearing for the algorithm definition, the branch between conic and quadratic cases, and the subsequent convergence claim under suitable conditions.
Authors: We agree that the decision rule determining whether the conic model can be used is not stated with sufficient explicitness. This affects the precise definition of the algorithm and the conditions under which the convergence result applies. In the revised manuscript we will add an explicit statement of this criterion (including any thresholds or computable conditions) in the method description of Sections 2 and 3, and we will ensure the convergence analysis is stated with direct reference to the same rule. revision: yes
Circularity Check
Minor self-citation to prior same-author work; central construction remains independent
full rationale
The paper cites Liu and Liu (Optimization 2018) for the approximately optimal stepsize concept and a Numer. Algorithms 2018 paper (same group) for the conic-model framework. However, the load-bearing algorithmic decision—construct conic model to generate stepsize precisely when f is not close to quadratic on the line segment (and model usable), else quadratic fallback—is stated as a new synthesis in this manuscript. No equation reduces a claimed prediction to a fitted parameter from the cited works by algebraic identity, and no uniqueness theorem is imported from self-citation to force the choice. Convergence is proved under explicitly stated conditions; numerical tests are presented as supporting evidence rather than definitional. This yields only a minor self-citation flag without circular reduction of the central claim.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cauchy, A.: M´ ethode g´ en´ erale pour la r´ esolution des syst´ ems d´ equations simultan´ ees. Comp. Rend. Sci. Paris,25, 46-89(1847)
-
[2]
Barzilai, J., Borwein, J.M.: Two-point step size gradien t methods. IMA J. Numer. Anal. 8, 141-148(1988)
work page 1988
-
[3]
Asmundis, R. D., Serafino, D. D, Riccio, F., et al.: On spect ral properties of steepest descent methods . IMA J. Numer. An al. 33(4), 1416-1435(2013)
work page 2013
-
[4]
Raydan, M.: On the Barzilai and Borwein choice of stepleng th for the gradient method. IMA J. Numer. Anal. 13, 321-326(1993)
work page 1993
-
[5]
Dai, Y. H., Liao, L. Z.: R-linear convergence of the Barzilai and Borwein gradient me thod. IMA J. Numer. Anal. 22(1), 1- 10(2002)
work page 2002
-
[6]
Raydan, M.: The Barzilai and Borwein gradient method for t he large scale unconstrained minimization problem. SIAM J. Optim. 7, 26-33(1997)
work page 1997
-
[7]
Grippo, L., Lampariello, F., Lucidi,S.: A nonmonotone li ne search technique for Newton’s method. SIAM J. Numer. Anal . 23, 707-716(1986)
work page 1986
-
[8]
Biglari, F., Solimanpur, M.: Scaling on the spectral grad ient method. J. Optim. Theory Appl. 158(2), 626-635(2013)
work page 2013
-
[9]
Dai, Y. H., Yuan, J. Y., Yuan, Y.X.: Modified two-point step size gradient methods for unconstrained optimization prob lems. Comput. Optim. Appl. 22, 103-109(2002)
work page 2002
-
[10]
Yuan Y.X., Stoer J.: A subspace study on conjugate gradie nt algorithms. Z. Angew. Math. Mech. 75(1), 69-77(1995)
work page 1995
-
[11]
Dai. Y. H., Hager, W. W., Schittkowski, K., et al.: The cyc lic Barzilai-Borwein method for unconstrained optimizati on. IMA J. Numer. Anal. 26(3), 604-627(2006)
work page 2006
-
[12]
Xiao, Y. H., W ang, Q. Y., W ang, D., et al.: Notes on the Dai- Yuan-Yuan modified spectral gradient method. J. Comput. App l. Math. 234(10), 2986-2992(2010)
work page 2010
-
[13]
Miladinovi´ c, M., Stanimirovi´ c, P., Miljkovi´ c, S.: Scalar correction method for solving large scale unconstrai ned minimization problems. J. Optim. Theory Appl. 151(2), 304-320(2011)
work page 2011
-
[14]
H.: Gradient methods with adapt ive stepsizes
Zhou, B., Gao, L., Dai, Y. H.: Gradient methods with adapt ive stepsizes. Comput. Optim. Appl. 35(1), 69-86 (2006)
work page 2006
-
[15]
Hager, W. W., Zhang, H. C.: A new conjugate gradient metho d with guaranteed descent and an efficient line search. SIAM J. Optim. 16(1), 170-192(2005)
work page 2005
-
[16]
Han, Q. M., Sun, W. Y., Han, J. Y., et al.: An adaptive conic trust-region method for unconstrained optimization. Opti m. Methods Softw. 20(6), 665-677(2005). 22 Zexian Liu, Hongwei Liu
work page 2005
-
[17]
Sun, W.Y., Xu, D.: A filter-trust-region method based on c onic model for unconstrained optimization (in Chinese). Sc i. Sin. Math 55(5), 527-543 (2012)
work page 2012
-
[18]
Yuan, Y. X., Sun, W. Y.: Theory and methods of optimizatio n. Science Press of China (1999)
work page 1999
- [19]
-
[20]
C.: Conic Approximations and Collinear Scal ings for Optimizers
Davidon, W. C.: Conic Approximations and Collinear Scal ings for Optimizers. SIAM J. Numer. Anal. 17(2), 268-281(1980)
work page 1980
-
[21]
C.: The Q-Superlinear Convergence of a Coll inear Scaling Algorithm for Unconstrained Optimization
Sorensen, D. C.: The Q-Superlinear Convergence of a Coll inear Scaling Algorithm for Unconstrained Optimization. S IAM J. Numer. Anal. 17(17), 84-114(1980)
work page 1980
-
[22]
Zhang, J. Z., Deng, N. Y., Chen, L. H.: New quasi-Newton eq uation and related methods for unconstrained optimization . J. Optim. Theory Appl. 102, 147-167 (1999)
work page 1999
-
[23]
Friedlander, A., Martinez, J. M., Molina, B., et al. Grad ient Method with Retards and Generalizations. SIAM J. Numer . Anal. 36(1), 275-289(1998)
work page 1998
-
[24]
Zhang, H. C., Hager, W. W.: A nonmonotone line search tech nique and its application to unconstrained optimization. S IAM J. Optim. 14, 1043-1056(2004)
work page 2004
-
[25]
Birgin, E. G., Mart ´ ınez, J. M., Raydan, M.: Nonmonotone spectral projected gradient methods for convex sets. SIAM J . Optim. 10(4), 1196-1211(2000)
work page 2000
-
[26]
Dai, Y. H., Kou, C. X.: A nonlinear conjugate gradient alg orithm with an optimal property and an improved W olfe line se arch. SIAM J. Optim. 23(1), 296-320(2013)
work page 2013
-
[27]
Andrei, N.: An unconstrained optimization test functio ns collection. Adv. Model. Optim. 10, 147-161(2008)
work page 2008
-
[28]
Gould, N. I. M., Orban, D., Toint, Ph.L.: CUTEr and SifDec : A constrained and unconstrained testing environment, rev isited. ACM Trans. Math. Softw. 29(4), 373-394(2003)
work page 2003
-
[29]
C.: The limited memory conjugate g radient method
Hager, W.W., Zhang, H. C.: The limited memory conjugate g radient method. SIAM J. Optim. 23(4), 2150-2168(2013)
work page 2013
-
[30]
Liu, Z. X., Liu, H. W., Dong, X. L.: An efficient gradient met hod with approximate optimal stepsize for the strictly conv ex quadratic minimization problem. Optimization 67(3), 427-440(2018)
work page 2018
-
[31]
Liu, Z. X., Liu, H. W.: An efficient gradient method with app roximate optimal stepsize for large-scale unconstrained o ptimiza- tion. Numer. Algorithms 78(1), 21-39(2018)
work page 2018
-
[32]
Liu, Z. X., Liu, H. W.: Several efficient gradient methods w ith approximate optimal stepsizes for large scale unconstr ained optimization. J. Comput. Appl. Math. 328, 400-413(2018)
work page 2018
-
[33]
Liu, Z. X., Liu, H. W.: An efficient gradient methods with ap proximately optimal stepsizes based on tensor model for unc on- strained optimization. J. Optim. Theory Appl. 181(2), 608-633(2019)
work page 2019
-
[34]
Liu, H. W., Liu, Z. X., Dong, X. L.: A new adaptive Barzilai and Borwein method for unconstrained optimization. Optim. Lett. 12(4), 845-873(2018)
work page 2018
-
[35]
Some unconstrained optimization methods, In Applied Mathematics
Snezana S Djordjevic. Some unconstrained optimization methods, In Applied Mathematics. DOI:10.5772/intechopen .83679, 2019
-
[36]
Liu, H. W., Liu, H. X.: An efficient Barzilai-Borwein conju gate gradient method for unconstrained optimization. J. Op tim. Theory Appl. 180(3), 879-906(2019)
work page 2019
-
[37]
Dolan, E. D., Mor´ e, J. J.: Benchmarking optimization so ftware with performance profiles. Math. Program. 91, 201-213(2002)
work page 2002
-
[38]
W., Zhang, H.C.: Algorithm 851:CG DESCENT, a conjugate gradient method with guaranteed desce nt
Hager, W. W., Zhang, H.C.: Algorithm 851:CG DESCENT, a conjugate gradient method with guaranteed desce nt. ACM Trans. Math. Softw. 32(1), 113-137(2006)
work page 2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.