Towards Efficient LLMs Annealing with Principled Sample Selection
Pith reviewed 2026-06-28 22:34 UTC · model grok-4.3
The pith
DiReCT selects LLM annealing samples by aligning per-sample gradients with Hessian eigen-direction constraints for optimal convergence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
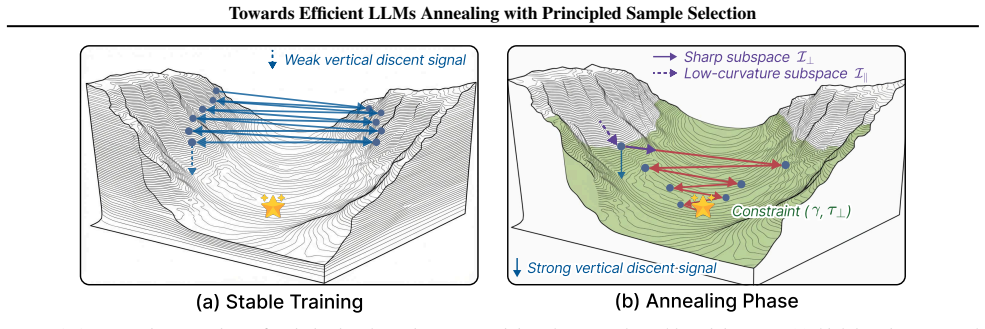
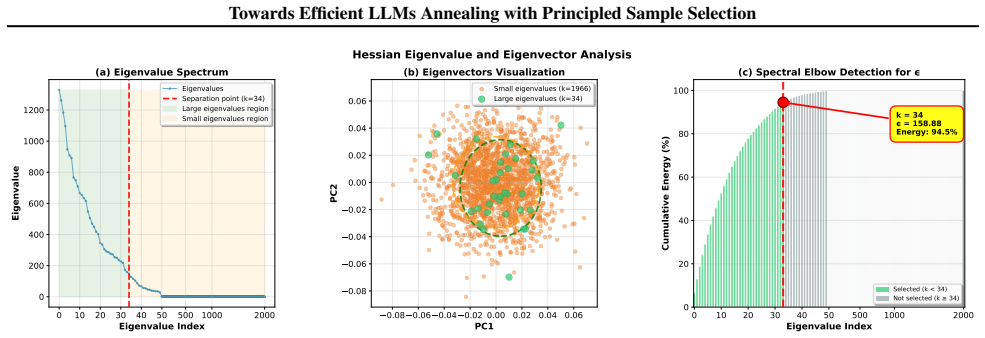
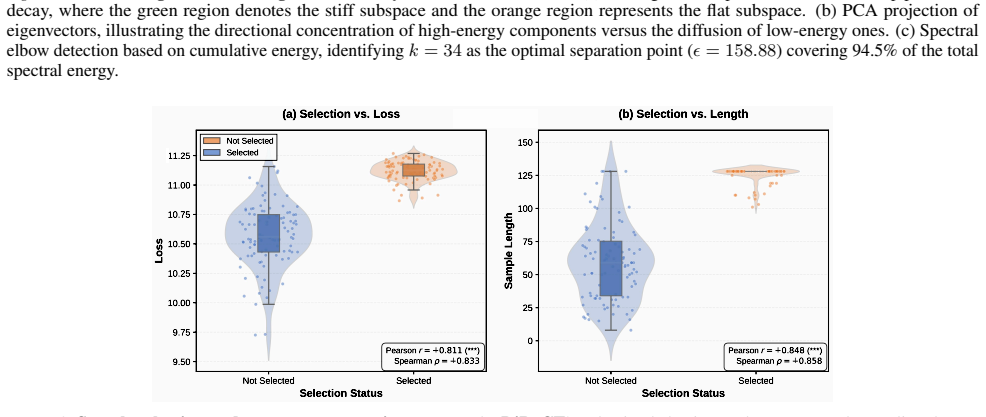
DiReCT reformulates sample selection in the annealing stage as a constrained optimization problem. By imposing explicit directional constraints on per-sample gradients based on the spectral properties of the Hessian, DiReCT identifies samples that align with the optimal curvature-aware descent path. Extensive experiments across various model scales demonstrate that DiReCT consistently achieves state-of-the-art performance.
What carries the argument
DiReCT (Directionally-Restrained Constrained Training), a framework that reformulates data selection by imposing directional constraints on per-sample gradients drawn from the Hessian's eigen-directions.
Load-bearing premise
Optimal convergence in the annealing phase requires gradient updates to satisfy heterogeneous directional constraints across eigen-directions of the loss landscape.
What would settle it
A controlled run on the same models and annealing data where random or heuristic selection matches or exceeds DiReCT performance on final model quality metrics would falsify the central claim.
Figures
read the original abstract
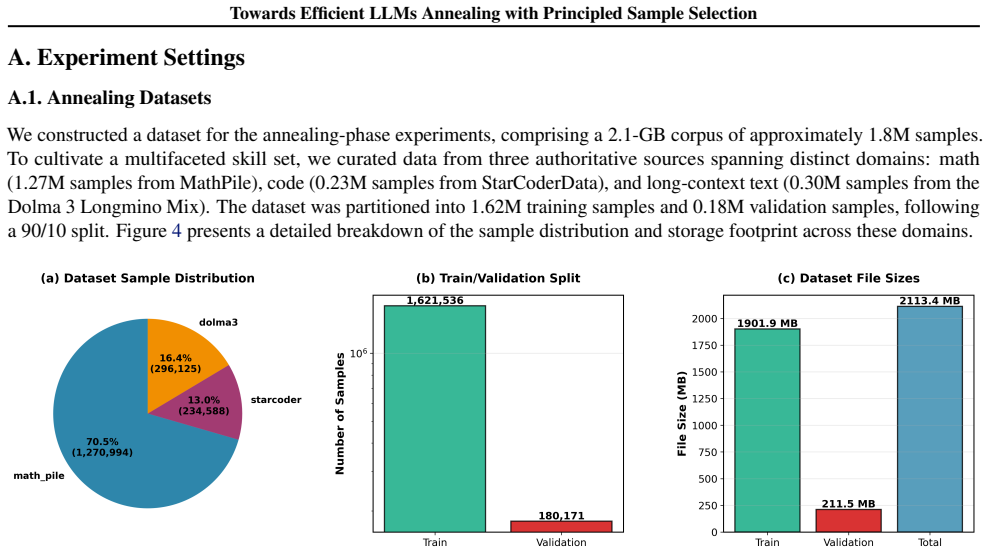
The annealing phase is a pivotal convergence stage in LLM pre-training that ultimately determines final model quality. However, effectively selecting training data during this phase remains a key challenge. Current strategies rely on empirical heuristics, such as domain filtering or context extension, which lack a principled grounding in optimization theory. In this work, we characterize the annealing phase through the lens of the loss landscape's spectral geometry. We argue that optimal convergence requires gradient updates to satisfy heterogeneous constraints across different eigen-directions. Building on this insight, we formulate data selection as a problem of satisfying these directional constraints. To this end, we propose DiReCT (Directionally-Restrained Constrained Training), a novel framework that reformulates sample selection in the annealing stage as a constrained optimization problem. By imposing explicit directional constraints on per-sample gradients based on the spectral properties of the Hessian, DiReCT identifies samples that align with the optimal curvature-aware descent path. Extensive experiments across various model scales demonstrate that DiReCT consistently achieves state-of-the-art performance. For future research, code is available at https://github.com/xuyj233/Direct.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript characterizes the LLM annealing phase via the loss landscape's spectral geometry and argues that optimal convergence requires gradient updates satisfying heterogeneous directional constraints across eigen-directions. It formulates sample selection as a constrained optimization problem and introduces DiReCT, which imposes explicit directional constraints on per-sample gradients derived from Hessian spectral properties to identify samples aligning with an optimal curvature-aware descent path. Experiments across model scales are reported to show consistent state-of-the-art performance, with code released.
Significance. If the mapping from spectral geometry to the specific constrained formulation can be rigorously derived and the empirical gains hold under controlled comparisons, the work would supply a theory-grounded alternative to heuristic data-selection practices in the critical annealing stage, with potential impact on training efficiency and final model quality. The public code release supports reproducibility.
major comments (2)
- [Abstract] Abstract (paragraph beginning 'We argue that optimal convergence...'): The central premise that optimal convergence requires gradient updates to satisfy heterogeneous directional constraints across eigen-directions is asserted without a derivation from loss-landscape geometry or a theorem establishing necessity or sufficiency of per-eigen-direction constraints in the annealing regime. This step is load-bearing for the subsequent constrained-optimization formulation and the claim that DiReCT identifies the 'optimal curvature-aware descent path'.
- [Abstract] Abstract (final experimental claim): The statement that DiReCT 'consistently achieves state-of-the-art performance' across model scales is presented without reference to specific baselines, metrics, ablation controls, or statistical significance tests in the provided text, preventing assessment of whether gains are attributable to the directional constraints rather than implementation details.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph beginning 'We argue that optimal convergence...'): The central premise that optimal convergence requires gradient updates to satisfy heterogeneous directional constraints across eigen-directions is asserted without a derivation from loss-landscape geometry or a theorem establishing necessity or sufficiency of per-eigen-direction constraints in the annealing regime. This step is load-bearing for the subsequent constrained-optimization formulation and the claim that DiReCT identifies the 'optimal curvature-aware descent path'.
Authors: We acknowledge that the abstract asserts the premise without an explicit derivation. The full manuscript motivates the constraints via the loss landscape's spectral geometry, but a formal step-by-step derivation from the Hessian eigenspectrum to the per-eigen-direction constraints is not present. In the revision we will add a short derivation subsection (or paragraph in the introduction) establishing necessity under standard smoothness and curvature assumptions for the annealing regime. revision: yes
-
Referee: [Abstract] Abstract (final experimental claim): The statement that DiReCT 'consistently achieves state-of-the-art performance' across model scales is presented without reference to specific baselines, metrics, ablation controls, or statistical significance tests in the provided text, preventing assessment of whether gains are attributable to the directional constraints rather than implementation details.
Authors: The abstract is intentionally concise. The full paper reports comparisons against standard baselines (random, perplexity, domain filtering), metrics (validation perplexity and downstream tasks), ablations on constraint parameters, and results from multiple random seeds with significance testing. We will revise the abstract to include a brief parenthetical reference to these elements and the relevant experimental section. revision: yes
Circularity Check
Optimal descent path defined by the directional constraints that DiReCT itself imposes
specific steps
-
self definitional
[Abstract]
"We argue that optimal convergence requires gradient updates to satisfy heterogeneous constraints across different eigen-directions. Building on this insight, we formulate data selection as a problem of satisfying these directional constraints. [...] By imposing explicit directional constraints on per-sample gradients based on the spectral properties of the Hessian, DiReCT identifies samples that align with the optimal curvature-aware descent path."
The 'optimal' path is defined as the trajectory obeying the heterogeneous directional constraints; DiReCT is then presented as identifying samples that satisfy those same constraints, rendering the alignment claim true by construction rather than by independent derivation from spectral geometry.
full rationale
The paper's central theoretical step asserts without derivation that optimal convergence in annealing requires gradient updates to obey heterogeneous eigen-direction constraints, then defines DiReCT as the method that enforces exactly those constraints and therefore aligns with the 'optimal curvature-aware descent path.' This reduces the claim of principled grounding to a self-definitional equivalence: the target optimality is characterized by the same per-sample Hessian-based directional restrictions the algorithm applies. No independent theorem or external loss-landscape result is shown to establish necessity or sufficiency of those constraints.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
GPT-NeoX-20B: An Open-Source Autoregressive Language Model
Black, S., Biderman, S., Hallahan, E., Anthony, Q., Gao, L., Golding, L., He, H., Leahy, C., McDonell, K., Phang, J., et al. GPT-NeoX-20B: An Open-Source Autoregres- sive Language Model.arXiv preprint arXiv:2204.06745,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Evaluating Large Language Models Trained on Code
Chen, M., Tworek, J., et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think You Have Solved Question Answering? Try ARC, the AI2 Reasoning Chal- lenge.arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
DeepSeek-AI, Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., et al. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Gao, L., Biderman, S., Black, S., Golding, L., Hoppe, T., Foster, C., Phang, J., He, H., Thite, A., Nabeshima, N., Presser, S., and Leahy, C. The pile: An 800gb dataset of diverse text for language modeling.arXiv preprint arXiv:2101.00027,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
Goyal, P., Doll ´ar, P., Girshick, R., Noordhuis, P., Wesolowski, L., Kyrola, A., Tulloch, A., Jia, Y ., and He, K. Accurate, large minibatch sgd: Training imagenet in 1 hour.arXiv preprint arXiv:1706.02677,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Hu, Y ., Song, H., Deng, J., Wang, J., Chen, J., Zhou, K., Zhu, Y ., Jiang, J., Dong, Z., Zhao, W. X., and Wen, J. Yulan- mini: An open data-efficient language model.arXiv preprint arXiv:2412.17743,
-
[10]
StarCoder: may the source be with you!
Li, R., Allal, L. B., Zi, Y ., Muennighoff, N., Kocetkov, D., Mou, C., Marone, M., Akiki, C., Li, J., Chim, J., et al. Starcoder: may the source be with you!arXiv preprint arXiv:2305.06161,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
Mihaylov, T., Clark, P., Khot, T., and Sabharwal, A. Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering.arXiv preprint arXiv:1809.02789,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Team, K., Du, A., Gao, B., Xing, B., et al. Kimi k1.5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Crowdsourcing Multiple Choice Science Questions
Welbl, J., Liu, N. F., and Gardner, M. Crowdsourcing Multiple Choice Science Questions.arXiv preprint arXiv:1707.06209,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Yang, A., Li, A., Yang, B., Zhang, B., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
HellaSwag: Can a Machine Really Finish Your Sentence?
Zellers, R., Holtzman, A., Bisk, Y ., Farhadi, A., and Choi, Y . HellaSwag: Can a Machine Really Finish Your Sentence? arXiv preprint arXiv:1905.07830,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[16]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Zeng, A., Xu, B., Wang, B., et al. Chatglm: A family of large language models from GLM-130B to GLM-4 all tools.arXiv preprint arXiv:2406.12793,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
is run with maximum iteration countT max = 20and convergence toleranceδ= 10 −4. B. Successive Convex Approximation Solver Our goal is to learn a continuous selection vector w∈[0,1] N such that the selected samples produce a strong aggregate gradient in the flat subspace while remaining within a budget in the stiff subspace. Because the flat-subspace objec...
1995
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.