Stage-Transition Dense Reward Modeling for Reinforcement Learning
Pith reviewed 2026-07-01 05:08 UTC · model grok-4.3
The pith
Stage-Transition Dense Reward converts expert videos into dense signals that guide RL agents on long-horizon robotic manipulation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
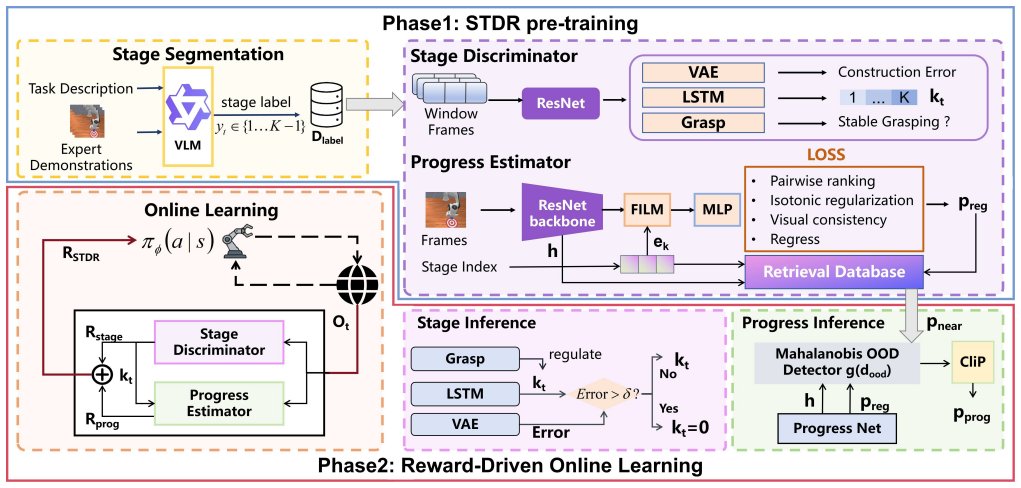
STDR converts unstructured expert videos into logically grounded dense rewards by inferring a task's stage structure from demonstrations and delivering stage-transition feedback plus within-stage progress feedback during online RL training.
What carries the argument
Stage structure inferred from semantic understanding of demonstrations, which produces both stage-transition rewards for goal-directed guidance and within-stage progress rewards for fine-grained direction.
If this is right
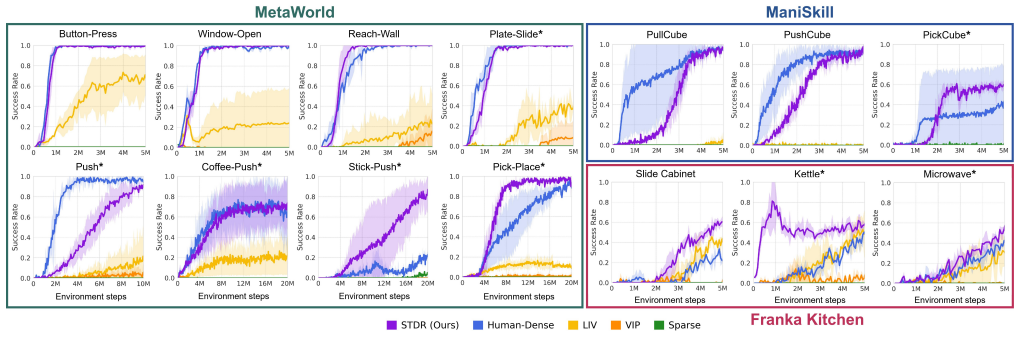
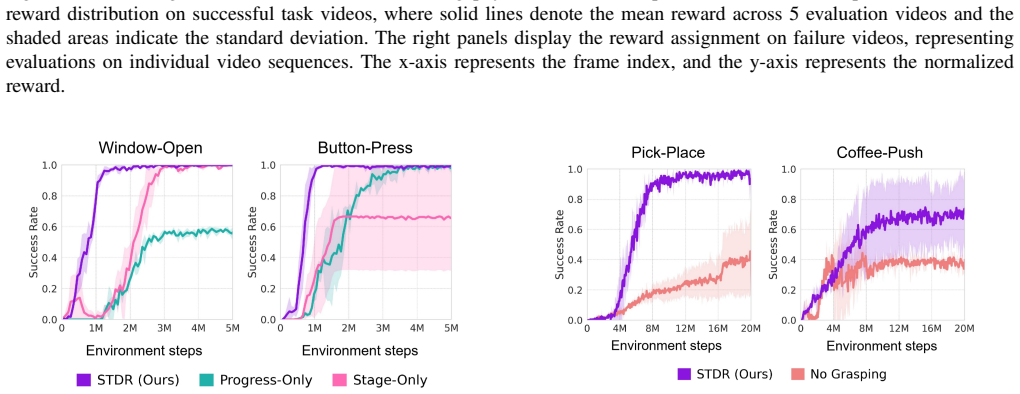
- Agents reach higher success rates with fewer environment samples on manipulation tasks from three different benchmarks.
- STDR matches or exceeds the performance of manually designed dense rewards on several challenging tasks.
- The added OOD detection and grasping regulation reduce reward hacking and maintain reward stability.
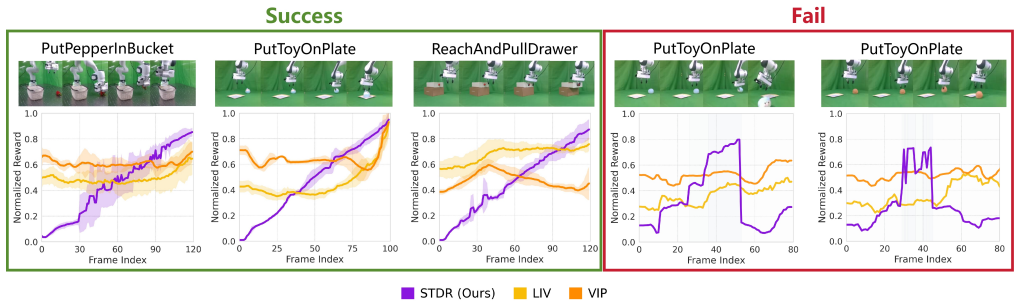
- Real-robot executions receive progress-aligned rewards that drop appropriately on failures.
Where Pith is reading between the lines
- The same video-to-stage-reward pipeline could be tested on non-manipulation sequential tasks such as navigation or assembly planning.
- Performance may vary with the accuracy of the vision-language model used to extract stages from video.
- Tasks whose natural stage boundaries are ambiguous would serve as a direct test of the inference step.
Load-bearing premise
Semantic understanding from demonstrations can reliably infer a task's stage structure without introducing errors that misalign the reward signals.
What would settle it
Demonstration videos on which the inferred stages produce misaligned rewards, causing trained agents to show lower success rates than a sparse-reward baseline despite the presence of the OOD and grasping modules.
Figures

read the original abstract
Reinforcement learning for long-horizon robotic manipulation is often limited by sparse and delayed rewards, while manually designing dense shaping signals is costly and brittle to changes in environments and object configurations. This work proposes Stage-Transition Dense Reward (STDR), a visual reward-learning framework that converts unstructured expert videos into logically grounded dense rewards for training RL agents from scratch. STDR leverages semantic understanding to infer a task's stage structure from demonstrations, and delivers two complementary learning signals during online training: (i) stage-transition feedback that provides goal-directed reward, and (ii) within-stage progress feedback that supplies fine-grained guidance toward completing each stage. Furthermore, an out-of-distribution (OOD) detection mechanism and a grasping regulation module are integrated to enhance robustness and prevent reward hacking. Experiments on 14 manipulation tasks across MetaWorld, ManiSkill, and Franka Kitchen show that STDR consistently improves sample efficiency and success rates over multiple baselines, and matches or surpasses handcrafted dense rewards on several challenging tasks. Real-robot evaluations further indicate that STDR assigns stable, progress-aligned rewards on successful executions while producing appropriately low rewards for failures, suggesting robustness to visual noise and better-calibrated reward assignment across settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Stage-Transition Dense Reward (STDR), a visual reward-learning framework that converts unstructured expert videos into dense rewards for RL in long-horizon robotic manipulation. It infers task stage structure via semantic understanding, then supplies stage-transition feedback for goal-directed signals and within-stage progress feedback for fine-grained guidance during online training. OOD detection and a grasping regulation module are added for robustness. Experiments on 14 tasks across MetaWorld, ManiSkill, and Franka Kitchen report consistent gains in sample efficiency and success rates over baselines, matching or exceeding handcrafted dense rewards on several tasks, with real-robot results indicating stable, progress-aligned reward assignment.
Significance. If the stage-inference step proves reliable and the empirical gains survive rigorous statistical evaluation, STDR would address a persistent bottleneck in robotic RL by automating the construction of logically grounded dense rewards from demonstrations, reducing dependence on brittle manual shaping and potentially enabling broader application to complex, long-horizon tasks.
major comments (2)
- [Experiments section] The central empirical claims rest on the premise that semantic stage inference from videos is sufficiently accurate; however, the manuscript supplies no quantitative bound on stage-boundary or transition-detection error rates, no ablation on noisy or mislabeled stages, and no analysis of how OOD detection or grasping regulation mitigates upstream inference failures (Experiments section describing the 14-task evaluation).
- [Results] Reported improvements in sample efficiency and success rates are presented without error bars, statistical significance tests, or explicit data-exclusion rules, preventing assessment of whether the gains over baselines and handcrafted rewards are reliable (results tables and associated text).
minor comments (1)
- [Abstract] Notation for the two reward components (stage-transition and within-stage progress) is introduced in the abstract but would benefit from an explicit equation or pseudocode example in the methods.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and commit to revisions that strengthen the empirical presentation without altering the core contributions.
read point-by-point responses
-
Referee: [Experiments section] The central empirical claims rest on the premise that semantic stage inference from videos is sufficiently accurate; however, the manuscript supplies no quantitative bound on stage-boundary or transition-detection error rates, no ablation on noisy or mislabeled stages, and no analysis of how OOD detection or grasping regulation mitigates upstream inference failures (Experiments section describing the 14-task evaluation).
Authors: We agree that quantitative evaluation of the stage-inference step would strengthen the claims. In the revised manuscript we will report stage-boundary detection accuracy (precision/recall) on the expert videos used for all 14 tasks. We will also add an ablation that injects controlled label noise into the inferred stages and measures downstream RL performance. Finally, we will include a targeted analysis showing how the OOD detector and grasping regulation module reduce the impact of inference errors by filtering unreliable frames and preventing reward exploitation during online training. revision: yes
-
Referee: [Results] Reported improvements in sample efficiency and success rates are presented without error bars, statistical significance tests, or explicit data-exclusion rules, preventing assessment of whether the gains over baselines and handcrafted rewards are reliable (results tables and associated text).
Authors: We acknowledge that the current results lack the statistical detail needed for rigorous assessment. The revised manuscript will add error bars (standard deviation across five random seeds) to all tables and learning curves. We will also report paired t-test p-values comparing STDR against each baseline and handcrafted reward, and we will explicitly document the seed count, episode termination criteria, and any data-exclusion rules applied during evaluation. revision: yes
Circularity Check
No circularity in derivation; method is self-contained
full rationale
The abstract and claims describe a visual reward-learning framework that infers stage structure from expert videos via semantic understanding, then supplies stage-transition and within-stage progress signals plus OOD/grasping modules. No equations, fitted parameters, or self-citations are shown that reduce any prediction or central result to its own inputs by construction. Experimental improvements are presented as empirical outcomes on 14 tasks rather than statistical artifacts of the fitting process. The derivation chain therefore retains independent content from the inference and robustness components.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
End-to-end training of deep visuomotor policies,
S. Levine, C. Finn, T. Darrell, and P. Abbeel, “End-to-end training of deep visuomotor policies,”Journal of Machine Learning Research, vol. 17, no. 39, pp. 1–40, 2016
2016
-
[2]
Precise and dexterous robotic manipulation via human-in-the-loop reinforcement learning,
J. Luo, C. Xu, J. Wu, and S. Levine, “Precise and dexterous robotic manipulation via human-in-the-loop reinforcement learning,” 2024
2024
-
[3]
Overcoming exploration in reinforcement learning with demonstra- tions,
A. Nair, B. McGrew, M. Andrychowicz, W. Zaremba, and P. Abbeel, “Overcoming exploration in reinforcement learning with demonstra- tions,” in2018 IEEE international conference on robotics and automa- tion (ICRA). IEEE, 2018, pp. 6292–6299
2018
-
[4]
Learning by playing solving sparse reward tasks from scratch,
M. Riedmiller, R. Hafner, T. Lampe, M. Neunert, J. Degrave, T. Wiele, V . Mnih, N. Heess, and J. T. Springenberg, “Learning by playing solving sparse reward tasks from scratch,” inInternational conference on machine learning. PMLR, 2018, pp. 4344–4353
2018
-
[5]
Policy invariance under reward transformations: Theory and application to reward shaping,
A. Y . Ng, D. Harada, and S. Russell, “Policy invariance under reward transformations: Theory and application to reward shaping,” inIcml, vol. 99. Citeseer, 1999, pp. 278–287
1999
-
[6]
Apprenticeship learning via inverse rein- forcement learning,
P. Abbeel and A. Y . Ng, “Apprenticeship learning via inverse rein- forcement learning,” inProceedings of the twenty-first international conference on Machine learning, 2004, p. 1
2004
-
[7]
Inferring human-robot performance objectives during locomotion using inverse reinforcement learning and inverse optimal control,
W. Liu, J. Zhong, R. Wu, B. L. Fylstra, J. Si, and H. H. Huang, “Inferring human-robot performance objectives during locomotion using inverse reinforcement learning and inverse optimal control,” IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 2549–2556, 2022
2022
-
[8]
Fast lifelong adaptive inverse reinforcement learning from demonstrations,
L. Chen, S. Jayanthi, R. R. Paleja, D. Martin, V . Zakharov, and M. Gombolay, “Fast lifelong adaptive inverse reinforcement learning from demonstrations,” inConference on Robot Learning. PMLR, 2023, pp. 2083–2094
2023
-
[9]
VIP: Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training
Y . J. Ma, S. Sodhani, D. Jayaraman, O. Bastani, V . Kumar, and A. Zhang, “VIP: Towards universal visual reward and representa- tion via value-implicit pre-training,”arXiv preprint arXiv:2210.00030, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
LIV: Language-image representations and rewards for robotic control,
Y . J. Ma, W. Liang, V . Som, V . Kumar, A. Zhang, O. Bastani, and D. Jayaraman, “LIV: Language-image representations and rewards for robotic control,”arXiv preprint arXiv:2306.00958, 2023
-
[11]
Concrete Problems in AI Safety
D. Amodei, C. Olah, J. Steinhardt, P. Christiano, J. Schulman, and D. Man ´e, “Concrete problems in ai safety,”arXiv preprint arXiv:1606.06565, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[12]
Extrapolating beyond suboptimal demonstrations via inverse reinforcement learning from observations,
D. Brown, W. Goo, P. Nagarajan, and S. Niekum, “Extrapolating beyond suboptimal demonstrations via inverse reinforcement learning from observations,” inInternational conference on machine learning. PMLR, 2019, pp. 783–792
2019
-
[13]
Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations
A. Rajeswaran, V . Kumar, A. Gupta, G. Vezzani, J. Schulman, E. Todorov, and S. Levine, “Learning complex dexterous manipulation with deep reinforcement learning and demonstrations,”arXiv preprint arXiv:1709.10087, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[14]
Multi-stage manipulation with demonstration-augmented reward, policy, and world model learning,
A. L. Escoriza, N. Hansen, S. Tao, T. Mu, and H. Su, “Multi-stage manipulation with demonstration-augmented reward, policy, and world model learning,” 2025
2025
-
[15]
A markovian decision process,
R. Bellman, “A markovian decision process,”Journal of mathematics and mechanics, pp. 679–684, 1957
1957
-
[16]
A. Yang, A. Li, B. Yanget al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Long short-term memory,
S. Hochreiter and J. Schmidhuber, “Long short-term memory,”Neural computation, vol. 9, no. 8, pp. 1735–1780, 1997
1997
-
[18]
Auto-encoding variational bayes,
D. P. Kingma and M. Welling, “Auto-encoding variational bayes,”
-
[19]
Auto-Encoding Variational Bayes
[Online]. Available: https://arxiv.org/abs/1312.6114
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778
2016
-
[21]
RewiND: Language-guided rewards teach robot policies without new demonstrations,
J. Zhang, Y . Luo, A. Anwar, S. A. Sontakke, J. J. Lim, J. Thomason, E. Biyik, and J. Zhang, “RewiND: Language-guided rewards teach robot policies without new demonstrations,” in9th Annual Conference on Robot Learning, 2025. [Online]. Available: https://openreview.net/forum?id=XjjXLxfPou
2025
-
[22]
Film: Visual reasoning with a general conditioning layer,
E. Perez, F. Strub, H. de Vries, V . Dumoulin, and A. C. Courville, “Film: Visual reasoning with a general conditioning layer,” inAAAI, 2018
2018
-
[23]
On the generalized distance in statistics,
P. C. Mahalanobis, “On the generalized distance in statistics,” Sankhy¯a: The Indian Journal of Statistics, Series A (2008-), vol. 80, pp. S1–S7, 2018
2008
-
[24]
Meta-world+: An improved, standardized, RL benchmark,
R. McLean, E. Chatzaroulas, L. McCutcheon, F. R ¨oder, T. Yu, Z. He, K. Zentner, R. Julian, J. K. Terry, I. Woungang, N. Farsad, and P. S. Castro, “Meta-world+: An improved, standardized, RL benchmark,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025. [Online]. Available: https://openreview...
2025
-
[25]
Maniskill2: A unified benchmark for generalizable manipulation skills,
J. Gu, F. Xiang, X. Li, Z. Ling, X. Liu, T. Mu, Y . Tang, S. Tao, X. Wei, Y . Yao, X. Yuan, P. Xie, Z. Huang, R. Chen, and H. Su, “Maniskill2: A unified benchmark for generalizable manipulation skills,” inInter- national Conference on Learning Representations, 2023
2023
-
[26]
Gymnasium robotics,
R. de Lazcano, K. Andreas, J. J. Tai, S. R. Lee, and J. Terry, “Gymnasium robotics,” 2024. [Online]. Available: http://github.com/ Farama-Foundation/Gymnasium-Robotics
2024
-
[27]
D4rl: Datasets for deep data-driven reinforcement learning,
J. Fu, A. Kumar, O. Nachum, G. Tucker, and S. Levine, “D4rl: Datasets for deep data-driven reinforcement learning,” 2020
2020
-
[28]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Stable-baselines3: Reliable reinforcement learning implementations,
A. Raffin, A. Hill, A. Gleave, A. Kanervisto, M. Ernestus, and N. Dormann, “Stable-baselines3: Reliable reinforcement learning implementations,”Journal of Machine Learning Research, vol. 22, no. 268, pp. 1–8, 2021. [Online]. Available: http://jmlr.org/papers/ v22/20-1364.html
2021
-
[30]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,”The International Journal of Robotics Research, 2024
2024
-
[31]
Time-contrastive networks: Self-supervised learning from video,
P. Sermanet, C. Lynch, Y . Chebotar, J. Hsu, E. Jang, S. Schaal, S. Levine, and G. Brain, “Time-contrastive networks: Self-supervised learning from video,” in2018 IEEE international conference on robotics and automation (ICRA). IEEE, 2018, pp. 1134–1141
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.