Controlla: Learning Controllability via Graph-Constrained Latent Geometry
Pith reviewed 2026-05-20 18:34 UTC · model grok-4.3
The pith
Controlla structures latent geometry with graph priors so attributes evolve along consistent paths while identity stays fixed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
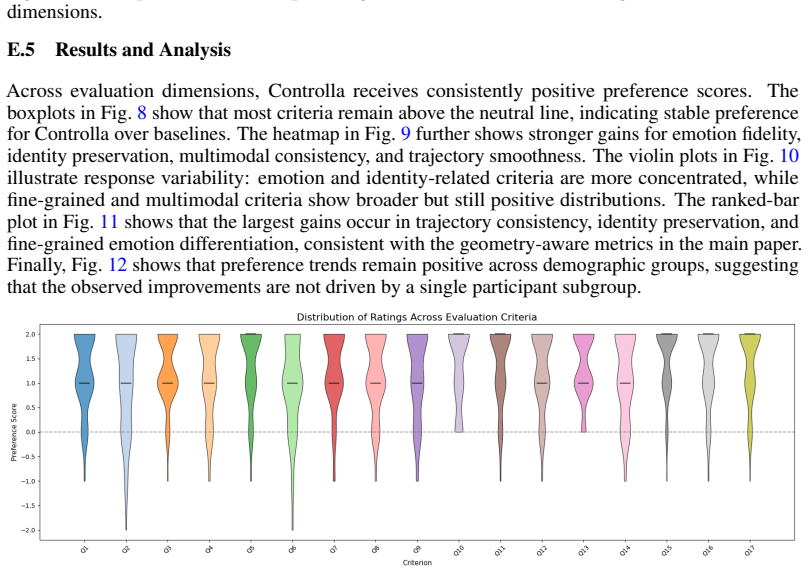
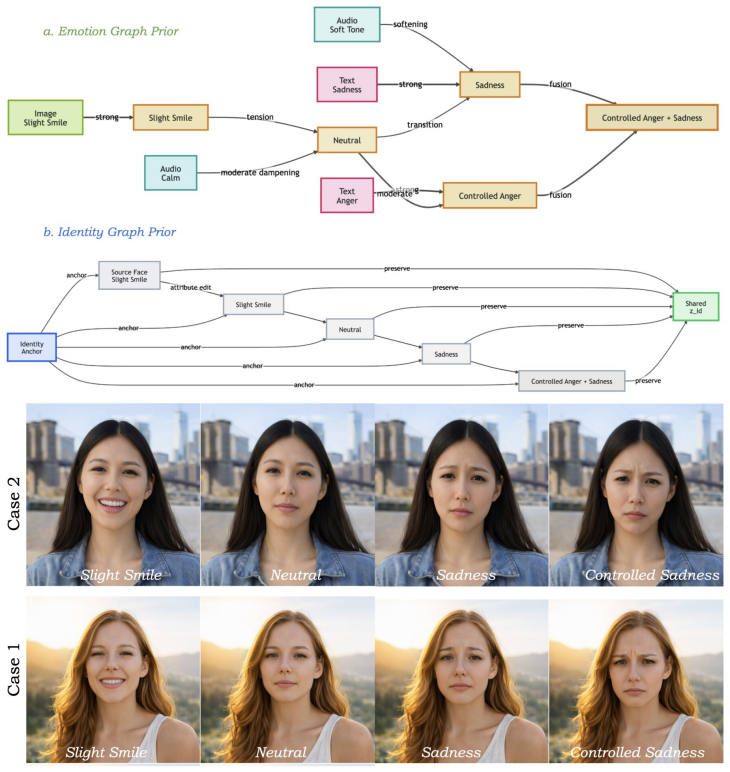
Controlla is a modular factorized-control framework that treats controllability as a property of structured latent geometry. It learns identity and attribute factors from multimodal inputs and aligns them with graph priors using graph-constrained optimal transport. This encourages attributes to follow graph-consistent trajectories while preserving reference identity. Experiments on the AffectHuman-43K benchmark demonstrate improvements in controllability, identity preservation, and cross-modal alignment.
What carries the argument
Graph-constrained optimal transport, which aligns learned identity and attribute factors with graph priors to enforce consistent trajectories in latent space.
If this is right
- Attributes follow graph-consistent trajectories across modalities.
- Identity is preserved better during control operations.
- Cross-modal alignment improves in generated outputs.
- The framework shows robustness and extensibility according to the reported analyses.
Where Pith is reading between the lines
- If similar graph priors can be defined for other attribute sets, the alignment step might transfer to tasks such as expression control in video or pose manipulation in 3D.
- The explicit separation of identity and attribute factors could support modular systems where one factor is held constant while another is adjusted independently.
- Geometry-aware evaluation metrics could be applied to test disentanglement in other generative models that operate on multimodal inputs.
Load-bearing premise
The graph priors correctly encode the semantic relationships and trajectories among attributes across modalities.
What would settle it
An observation that attribute trajectories in the latent space fail to match the graph structure or that identity preservation metrics show no gain over baseline conditioning methods on the AffectHuman-43K benchmark would disprove the claim.
Figures























read the original abstract
Controllable multimodal generation is commonly formulated as an inference-time conditioning problem using prompts, guidance, or auxiliary modules. While effective, such approaches do not explicitly structure how semantic attributes evolve, which can lead to identity drift and inconsistent cross-modal behavior. We propose Controlla, a modular factorized-control framework that treats controllability as a property of structured latent geometry. Controlla learns identity and attribute factors from multimodal inputs and aligns them with graph priors using graph-constrained optimal transport, encouraging attributes to follow graph-consistent trajectories while preserving reference identity. To evaluate this setting, we construct AffectHuman-43K, a leakage-aware multimodal benchmark for reference-grounded affective control, and introduce geometry-aware metrics for trajectory consistency and latent disentanglement. Experiments show consistent improvements in controllability, identity preservation, and cross-modal alignment, with additional analyses on graph sensitivity, extensibility, and robustness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Controlla, a modular factorized-control framework for controllable multimodal generation. It learns identity and attribute factors from multimodal inputs and aligns them with graph priors via graph-constrained optimal transport, with the goal of encouraging attributes to follow graph-consistent trajectories while preserving reference identity. The authors introduce the leakage-aware AffectHuman-43K benchmark for reference-grounded affective control along with geometry-aware metrics for trajectory consistency and latent disentanglement. Experiments are reported to show consistent improvements in controllability, identity preservation, and cross-modal alignment, with additional analyses on graph sensitivity and robustness.
Significance. If the central empirical claims hold and the graph priors are demonstrated to capture verifiable semantic structure rather than benchmark-specific artifacts, the work could meaningfully advance controllable generation by treating controllability as an intrinsic property of structured latent geometry instead of relying solely on inference-time conditioning. The introduction of a new multimodal affective benchmark and geometry-aware evaluation metrics constitutes a concrete contribution to the field.
major comments (2)
- [Section 3.2] Section 3.2 (Graph priors and OT alignment): The construction and validation of the graph priors for AffectHuman-43K is described at a high level only. It remains unclear whether the graphs are hand-crafted, derived from data statistics, or externally validated against cross-modal semantic trajectories (e.g., affective state transitions). This detail is load-bearing for the central claim that the method produces graph-consistent trajectories without identity drift; absent such validation, reported gains risk being attributable to fitting the specific benchmark rather than the latent-geometry mechanism.
- [Section 5] Section 5 (Experiments and ablations): The manuscript reports consistent improvements but provides insufficient quantitative detail on effect sizes, standard deviations, or ablations isolating the graph-constrained OT term versus the factorized representation alone. Without these, it is difficult to assess whether the geometry-aware metrics genuinely support the controllability claims or whether gains could arise from other modeling choices.
minor comments (2)
- [Abstract] Abstract: The phrase 'consistent improvements' would be strengthened by including one or two key numerical results (e.g., percentage gains on controllability or identity metrics) to give readers an immediate sense of effect magnitude.
- [Section 3] Notation: The distinction between the identity factor and attribute factor embeddings could be clarified with an explicit equation or diagram early in Section 3 to avoid ambiguity when discussing the OT alignment step.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback. The comments identify important areas where additional detail will strengthen the manuscript's support for the central claims regarding graph-constrained latent geometry. We address each major comment below and commit to the indicated revisions.
read point-by-point responses
-
Referee: [Section 3.2] Section 3.2 (Graph priors and OT alignment): The construction and validation of the graph priors for AffectHuman-43K is described at a high level only. It remains unclear whether the graphs are hand-crafted, derived from data statistics, or externally validated against cross-modal semantic trajectories (e.g., affective state transitions). This detail is load-bearing for the central claim that the method produces graph-consistent trajectories without identity drift; absent such validation, reported gains risk being attributable to fitting the specific benchmark rather than the latent-geometry mechanism.
Authors: We agree that the current description in Section 3.2 is high-level and requires expansion to substantiate the core claim. The graph priors are constructed in a data-driven manner by deriving transition probabilities from co-occurrence statistics of affective attribute labels across the multimodal samples in AffectHuman-43K. We will revise Section 3.2 to include the precise construction procedure (including the adjacency matrix computation and edge weighting), along with any steps taken to align the resulting graph with established affective transition patterns. This revision will clarify the distinction between benchmark-specific fitting and the intended latent-geometry mechanism. revision: yes
-
Referee: [Section 5] Section 5 (Experiments and ablations): The manuscript reports consistent improvements but provides insufficient quantitative detail on effect sizes, standard deviations, or ablations isolating the graph-constrained OT term versus the factorized representation alone. Without these, it is difficult to assess whether the geometry-aware metrics genuinely support the controllability claims or whether gains could arise from other modeling choices.
Authors: We acknowledge that the experimental reporting in Section 5 would benefit from greater quantitative rigor. While the manuscript already contains ablation variants that remove the OT alignment component, we agree that reporting effect sizes, standard deviations over multiple runs, and a more isolated comparison of the graph-constrained OT term versus the factorized representation alone would better isolate the contribution of the geometry mechanism. We will expand Section 5 with these details, including tables that report means and standard deviations for the key geometry-aware metrics and a dedicated ablation isolating the OT term. revision: yes
Circularity Check
No significant circularity; derivation uses standard optimal transport and graph priors as methodological choices
full rationale
The paper frames controllability as structured latent geometry and aligns identity/attribute factors to graph priors via graph-constrained optimal transport. This is presented as a modeling decision rather than a derivation whose outputs are forced by its own fitted parameters or self-citations. No equations, predictions, or uniqueness theorems are shown to reduce by construction to inputs (e.g., no fitted parameter renamed as prediction, no self-citation load-bearing the central claim). The AffectHuman-43K benchmark and geometry-aware metrics are introduced for evaluation, not as part of a self-referential loop. The approach remains self-contained against external benchmarks and standard techniques, yielding no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Graph priors accurately capture semantic relationships and consistent trajectories among attributes across modalities
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/README.md (headline theorem)reality_from_one_distinction (8-tick period) echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
normalized 8-class emotion taxonomy and fine-grained valence–arousal variation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35: 23716–23736, 2022
work page 2022
-
[2]
Loosecontrol: Lifting controlnet for generalized depth conditioning
Shariq Farooq Bhat, Niloy Mitra, and Peter Wonka. Loosecontrol: Lifting controlnet for generalized depth conditioning. InACM SIGGRAPH 2024 Conference Papers, pages 1–11, 2024
work page 2024
-
[3]
Instructpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18392–18402, 2023
work page 2023
-
[4]
Sven Buechel and Udo Hahn. Emobank: Studying the impact of annotation perspective and representation format on dimensional emotion analysis. InProceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers, pages 578–585, 2017
work page 2017
-
[5]
Carlos Busso, Murtaza Bulut, Chi-Chun Lee, Abe Kazemzadeh, Emily Mower, Samuel Kim, Jeannette N Chang, Sungbok Lee, and Shrikanth S Narayanan. Iemocap: Interactive emotional dyadic motion capture database.Language resources and evaluation, 42(4):335–359, 2008
work page 2008
-
[6]
PixArt-$\alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li. Pixart- α: Fast training of diffusion transformer for photorealistic text-to-image synthesis, 2023. URL https://arxiv.org/abs/ 2310.00426
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
PaLI: A Jointly-Scaled Multilingual Language-Image Model
Xi Chen, Xiao Wang, Soravit Changpinyo, Piotr Padlewski, Daniel Salz, Sebastian Goodman, Adam Grycner, Basil Mustafa, Lucas Beyer, et al. Pali: A jointly-scaled multilingual language- image model.arXiv preprint arXiv:2209.06794, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport.Advances in Neural Information Processing Systems (NeurIPS), 26, 2013
work page 2013
-
[9]
Emoticrafter: Text-to-emotional-image generation based on valence-arousal model,
Shengqi Dang, Yi He, Long Ling, Ziqing Qian, Nanxuan Zhao, and Nan Cao. Emoticrafter: Text-to-emotional-image generation based on valence-arousal model, 2025. URL https: //arxiv.org/abs/2501.05710
-
[10]
Diffusionrig: Learning personalized priors for facial appearance editing
Zeyu Ding, Xingang Zhang, Zhanjie Xia, Louis Jebe, Zhuowen Tu, and Xiangyu Zhang. Diffusionrig: Learning personalized priors for facial appearance editing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12736–12746, 2023
work page 2023
-
[11]
Emoportraits: Emotion-enhanced multimodal one-shot head avatars
Nikita Drobyshev, Adriana Bigata Casademunt, Konstantinos V ougioukas, Zoe Landgraf, Stavros Petridis, and Maja Pantic. Emoportraits: Emotion-enhanced multimodal one-shot head avatars. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8498–8507, 2024
work page 2024
-
[12]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lacey, Alex Goodwin, Yannik Marek, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis, 2024. URL https://arxiv.org/abs/ 2403.03206
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Gheorghe Comanici et. al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities, 2025. URL https: //arxiv.org/abs/2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
OpenAI et. al. Gpt-4o system card, 2024. URLhttps://arxiv.org/abs/2410.21276. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Imagebind: One embedding space to bind them all
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kaushal V Alwala, Armand Joulin, and Ishan Misra. Imagebind: One embedding space to bind them all. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15180–15190, 2023
work page 2023
-
[16]
Demystifying flux architecture.arXiv preprint arXiv:2507.09595, 2025
Or Greenberg. Demystifying flux architecture.arXiv preprint arXiv:2507.09595, 2025
-
[17]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Image generation from scene graphs
Justin Johnson, Agrim Gupta, and Li Fei-Fei. Image generation from scene graphs. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1219– 1228, 2018
work page 2018
-
[19]
Progressive Growing of GANs for Improved Quality, Stability, and Variation
Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. Progressive growing of gans for improved quality, stability, and variation.arXiv preprint arXiv:1710.10196, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
Progressive growing of gans for improved quality, stability, and variation, 2018
Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. Progressive growing of gans for improved quality, stability, and variation, 2018. URL https://arxiv.org/abs/1710. 10196
work page 2018
-
[21]
Mridul Khurana, Amin Karimi Monsefi, Justin Lee, Medha Sawhney, David Carlyn, Julia Chae, Jianyang Gu, Rajiv Ramnath, Sara Beery, Wei-Lun Chao, et al. Taxaadapter: Vision taxonomy models are key to fine-grained image generation over the tree of life.arXiv preprint arXiv:2603.26128, 2026
-
[22]
Gihyun Kim, Taehoon Kwon, and Jong Chul Ye. Diffusionclip: Text-guided diffusion models for robust image manipulation.arXiv preprint arXiv:2110.02711, 2022
-
[23]
Neural relational inference for interacting systems
Thomas Kipf, Ethan Fetaya, Kuan-Chieh Wang, Max Welling, and Richard Zemel. Neural relational inference for interacting systems. InInternational conference on machine learning, pages 2688–2697. Pmlr, 2018
work page 2018
-
[24]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Magicbrush: A manually annotated dataset for instruction-guided image editing
Chenlin Li, Ziyang Chen, Peiye Sun, et al. Magicbrush: A manually annotated dataset for instruction-guided image editing. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2023
work page 2023
-
[26]
Ming Li, Taojiannan Yang, Huafeng Kuang, Jie Wu, Zhaoning Wang, Xuefeng Xiao, and Chen Chen. Controlnet++: Improving conditional controls with efficient consistency feedback: Project page: liming-ai. github. io/controlnet_plus_plus. InEuropean Conference on Computer Vision, pages 129–147. Springer, 2024
work page 2024
-
[27]
Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild
Shan Li, Weihong Deng, and JunPing Du. Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2852–2861, 2017
work page 2017
-
[28]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. InProceedings of the IEEE international conference on computer vision, pages 3730–3738, 2015
work page 2015
-
[29]
Steven R Livingstone and Frank A Russo. The ryerson audio-visual database of emotional speech and song (ravdess): A dynamic, multimodal set of facial and vocal expressions in north american english.PloS one, 13(5):e0196391, 2018
work page 2018
-
[30]
Ace++: Instruction-based image creation and editing via context-aware content filling
Chaojie Mao, Jingfeng Zhang, Yulin Pan, Zeyinzi Jiang, Zhen Han, Yu Liu, and Jingren Zhou. Ace++: Instruction-based image creation and editing via context-aware content filling. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1958–1966, 2025. 11
work page 1958
-
[31]
Gromov-wasserstein averaging of kernel and distance matrices
Hrvoje Máreti´c, Sebastian Claici, Edward Chien, and Justin Solomon. Gromov-wasserstein averaging of kernel and distance matrices. InInternational Conference on Machine Learning (ICML), pages 4424–4433, 2019
work page 2019
-
[32]
Abolfazl Meyarian, Amin Karimi Monsefi, Rajiv Ramnath, and Ser-Nam Lim. Direct: Disen- tangled regularization of contrastive trajectories for physics-refined video generation.arXiv preprint arXiv:2603.25931, 2026
-
[33]
Null-text inversion for editing real images using guided diffusion models
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real images using guided diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6038–6047, 2023
work page 2023
-
[34]
Ali Mollahosseini, Behzad Hasani, and Mohammad H. Mahoor. Affectnet: A database for facial expression, valence, and arousal computing in the wild.IEEE Transactions on Affective Computing, 10(1):18–31, January 2019. ISSN 2371-9850. doi: 10.1109/taffc.2017.2740923. URLhttp://dx.doi.org/10.1109/TAFFC.2017.2740923
-
[35]
FS-DFM: Fast and Accurate Long Text Generation with Few-Step Diffusion Language Models
Amin Karimi Monsefi, Nikhil Bhendawade, Manuel Rafael Ciosici, Dominic Culver, Yizhe Zhang, and Irina Belousova. Fs-dfm: Fast and accurate long text generation with few-step diffusion language models.arXiv preprint arXiv:2509.20624, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Taxadiffusion: Progressively trained diffusion model for fine-grained species generation
Amin Karimi Monsefi, Mridul Khurana, Rajiv Ramnath, Anuj Karpatne, Wei-Lun Chao, and Cheng Zhang. Taxadiffusion: Progressively trained diffusion model for fine-grained species generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8579–8589, 2025
work page 2025
-
[37]
Knobgen: Controlling the sophistication of artwork in sketch-based diffusion models
Pouyan Navard, Amin Karimi Monsefi, Mengxi Zhou, Wei-Lun Chao, Alper Yilmaz, and Rajiv Ramnath. Knobgen: Controlling the sophistication of artwork in sketch-based diffusion models. arXiv preprint arXiv:2410.01595, 2024
-
[38]
Styleclip: Text-driven manipulation of stylegan imagery
Or Patashnik, Zongze Wu, Eli Shechtman, Daniel Cohen-Or, and Dani Lischinski. Styleclip: Text-driven manipulation of stylegan imagery. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 2085–2094, 2021
work page 2085
-
[39]
Flowchef: Steering of rectified flow models for controlled generations
Maitreya Patel, Song Wen, Dimitris N Metaxas, and Yezhou Yang. Flowchef: Steering of rectified flow models for controlled generations. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15308–15318, 2025
work page 2025
-
[40]
Scalable Diffusion Models with Transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers, 2023. URL https://arxiv.org/abs/2212.09748
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Kosmos-2: Grounding Multimodal Large Language Models to the World
Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Grounding multimodal large language models to the world, 2023. URL https://arxiv.org/abs/2306.14824
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Foundations and Trends in Machine Learning, 2019
Gabriel Peyré and Marco Cuturi.Computational Optimal Transport, volume 11. Foundations and Trends in Machine Learning, 2019
work page 2019
-
[43]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis, 2023. URLhttps://arxiv.org/abs/2307.01952
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamila Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning (ICML), pages 8748–8763. PMLR, 2021
work page 2021
-
[45]
Kevin Rojas, Yuchen Zhu, Sichen Zhu, Felix X-F Ye, and Molei Tao. Diffuse everything: Multimodal diffusion models on arbitrary state spaces.arXiv preprint arXiv:2506.07903, 2025
-
[46]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, 2022. 12
work page 2022
-
[47]
Dreambooth: Fine-tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine-tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22500–22510, 2023
work page 2023
-
[48]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, Sharif Mahdavi, Raphael Lopes, Tim Salimans, Jonathan Ho, David J. Fleet, and Mohammad Norouzi. Imagen: Photorealistic text-to-image diffusion models with deep language understanding. InAdvances in Neural Information Process...
work page 2022
-
[49]
Emu edit: Precise image editing via recognition and generation tasks
Shelly Sheynin, Adam Polyak, Uriel Singer, Yuval Kirstain, Amit Zohar, Oron Ashual, Devi Parikh, and Yaniv Taigman. Emu edit: Precise image editing via recognition and generation tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8871–8879, 2024
work page 2024
-
[50]
Plug-and-play diffusion features for text-driven image-to-image translation
Narek Tumanyan, Michal Geyer, Shai Bagon, and Tali Dekel. Plug-and-play diffusion features for text-driven image-to-image translation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1921–1930, 2023
work page 1921
-
[51]
Titouan Vayer, Laetitia Chapel, Rémi Flamary, Romain Tavenard, and Nicolas Courty. Optimal transport for structured data with application on graphs.Proceedings of the 37th International Conference on Machine Learning, 2020
work page 2020
-
[52]
Optimal transport: old and new.Grundlehren der Mathematischen Wis- senschaften, 338, 2008
Cédric Villani. Optimal transport: old and new.Grundlehren der Mathematischen Wis- senschaften, 338, 2008
work page 2008
-
[53]
Tam- ing rectified flow for inversion and editing
Jiangshan Wang, Junfu Pu, Zhongang Qi, Jiayi Guo, Yue Ma, Nisha Huang, Yuxin Chen, Xiu Li, and Ying Shan. Taming rectified flow for inversion and editing.arXiv preprint arXiv:2411.04746, 2024
-
[54]
Baao Xie, Qiuyu Chen, Yunnan Wang, Zequn Zhang, Xin Jin, and Wenjun Zeng. Graph-based unsupervised disentangled representation learning via multimodal large language models, 2024. URLhttps://arxiv.org/abs/2407.18999
-
[55]
Gromov-wasserstein learning for graph matching and node embedding
Hongteng Xu, Dixin Luo, and Lawrence Carin. Gromov-wasserstein learning for graph matching and node embedding. InInternational Conference on Machine Learning (ICML), pages 6932– 6941, 2019
work page 2019
-
[56]
Emogen: Emotional image content generation with text-to-image diffusion models
Jingyuan Yang, Jiashi Feng, and Hui Huang. Emogen: Emotional image content generation with text-to-image diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6358–6368, 2024
work page 2024
-
[57]
Emoedit: Evoking emotions through image manipulation
Jingyuan Yang, Jiashi Feng, Wei Luo, Dani Lischinski, Daniel Cohen-Or, and Hui Huang. Emoedit: Evoking emotions through image manipulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 24690–24699, 2025
work page 2025
-
[58]
Probability density geodesics in image diffusion latent space
Qingtao Yu, Jaskirat Singh, Zhaoyuan Yang, Peter Henry Tu, Jing Zhang, Hongdong Li, Richard Hartley, and Dylan Campbell. Probability density geodesics in image diffusion latent space. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 27989–27998, 2025
work page 2025
-
[59]
Chao Zhang, Chen Zhang, Meng Zhang, and In So Kweon. Dreamtalk: Diffusion-based realistic emotional audio-driven method for single image talking face generation.arXiv preprint arXiv:2312.13578, 2023
-
[60]
Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. Magicbrush: A manually annotated dataset for instruction-guided image editing.Advances in Neural Information Processing Systems, 36:31428–31449, 2023
work page 2023
-
[61]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 3836–3847, 2023. 13
work page 2023
-
[62]
Enabling instructional image editing with in-context generation in large scale diffusion transformer
Zechuan Zhang, Ji Xie, Yu Lu, Zongxin Yang, and Yi Yang. Enabling instructional image editing with in-context generation in large scale diffusion transformer. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[63]
Haozhe Zhao, Xiaojian Ma, Liang Chen, Shuzheng Si, Rujie Wu, Kaikai An, Peiyu Yu, Minjia Zhang, Qing Li, and Baobao Chang. Ultraedit: Instruction-based fine-grained image editing at scale.Advances in Neural Information Processing Systems, 37:3058–3093, 2024
work page 2024
-
[64]
Dewei Zhou, Mingwei Li, Zongxin Yang, Yu Lu, Yunqiu Xu, Zhizhong Wang, Zeyi Huang, and Yi Yang. Bidedpo: Conditional image generation with simultaneous text and condition alignment.arXiv preprint arXiv:2511.19268, 2025. 14 Appendix Appendix Contents A Theoretical Analysis of Controlla 17 A.1 Structured Controllability as Metric Preservation . . . . . . . ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.