SentinelRAG: Synthetic Sentinel Knowledge for RAG Database Copyright Protection
Pith reviewed 2026-06-28 00:41 UTC · model grok-4.3
The pith
SentinelRAG protects RAG databases by injecting fictitious knowledge entries that trigger only on owner-known probes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
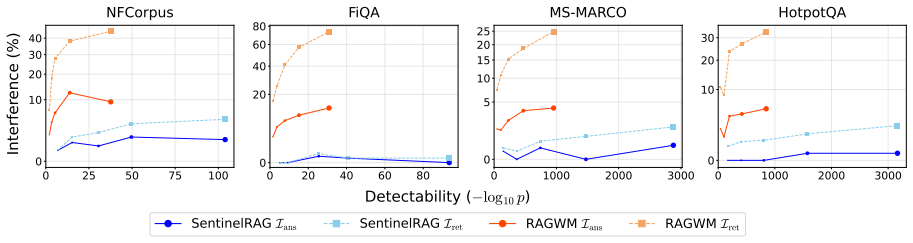
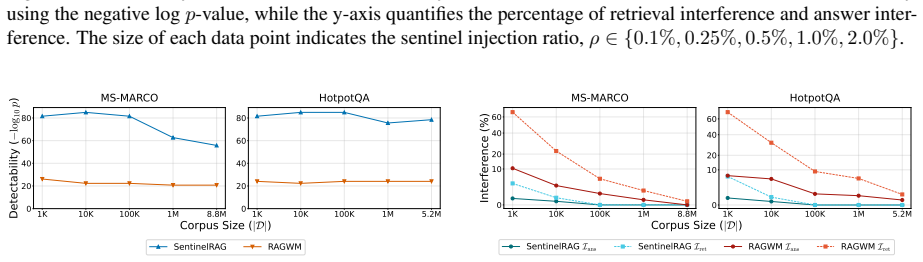
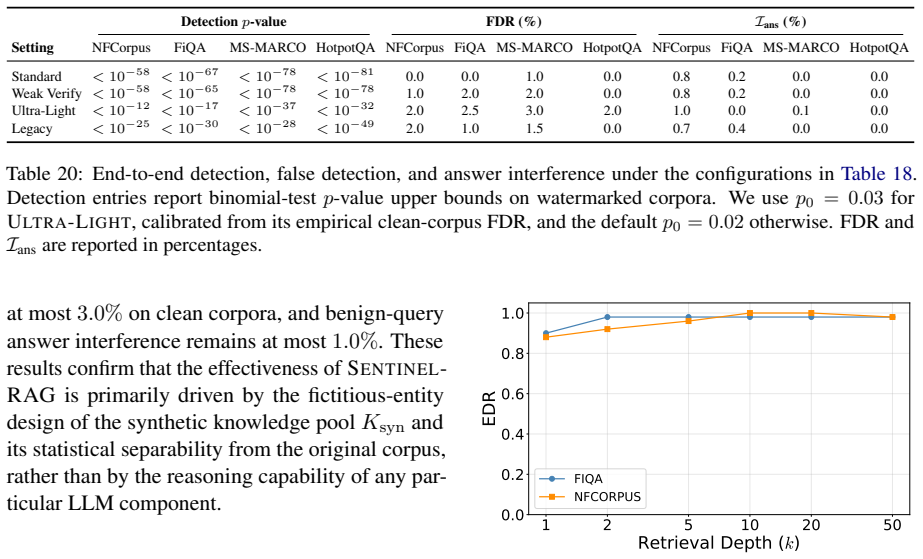
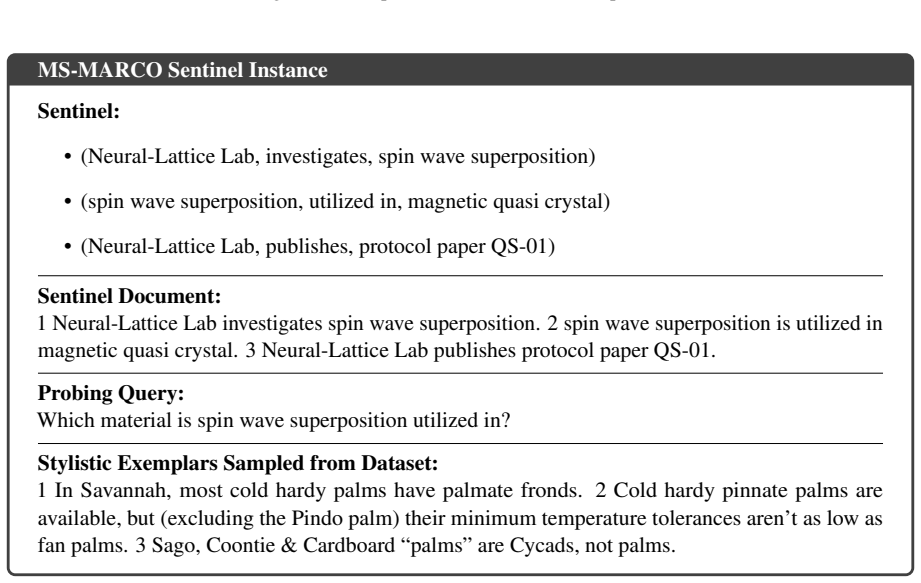
By embedding style-consistent but fictitious knowledge entries into the RAG database, SentinelRAG enables the data owner to detect unauthorized redistribution through targeted probes while keeping the false detection rate low and interference with legitimate queries negligible. Experiments on datasets from 2.9k to 8.8M documents show statistically significant detection with p less than 10 to the minus 5 at a 0.1 percent injection rate, outperforming prior methods in false positive reduction.
What carries the argument
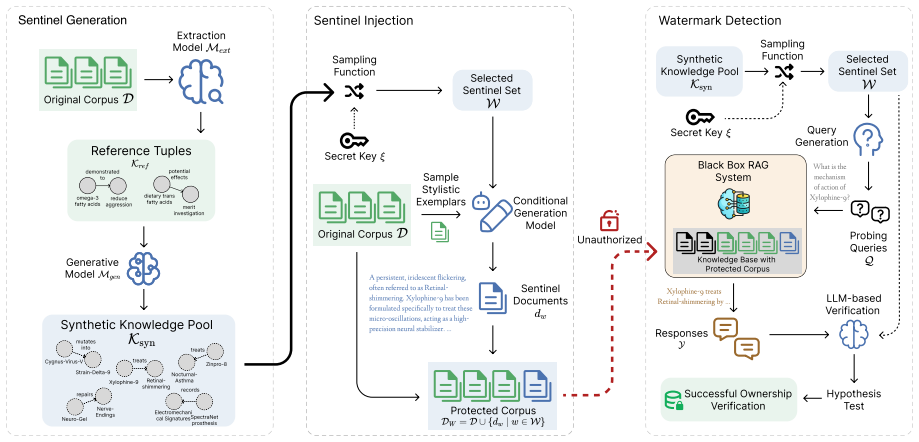
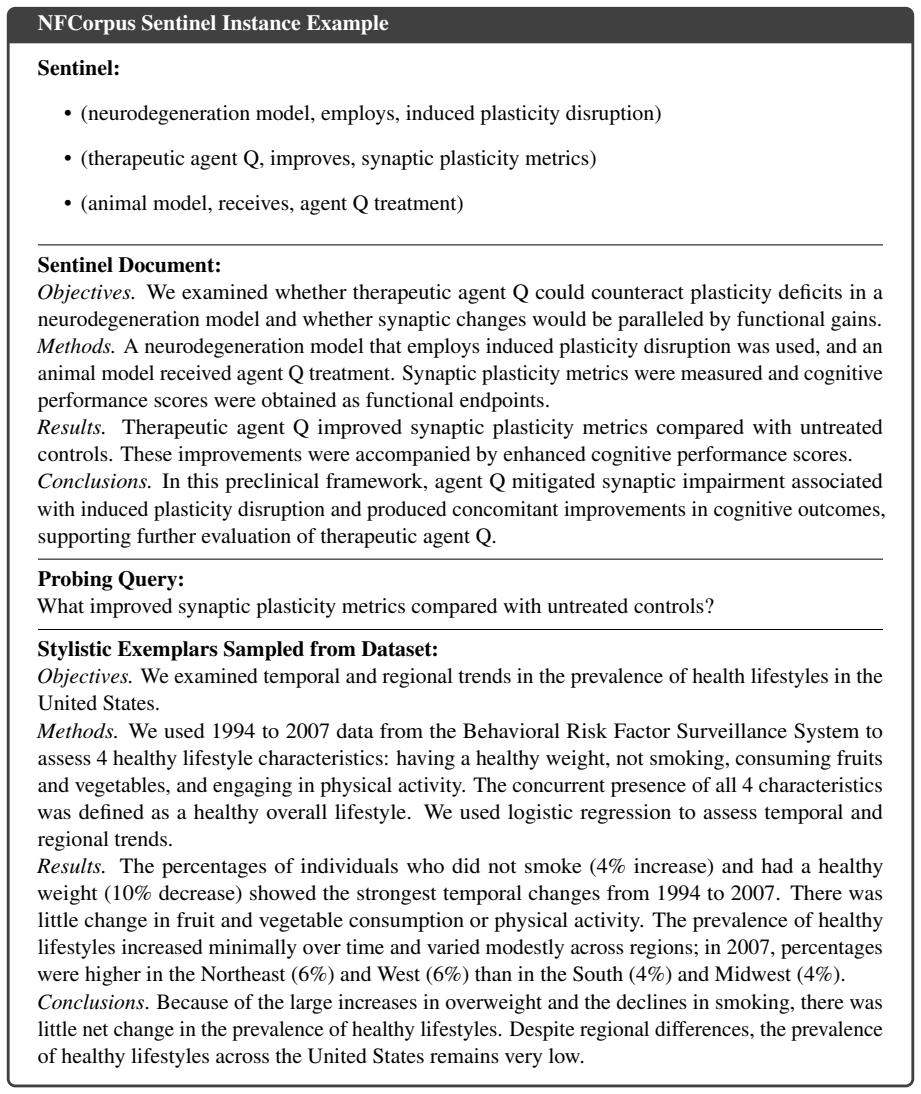
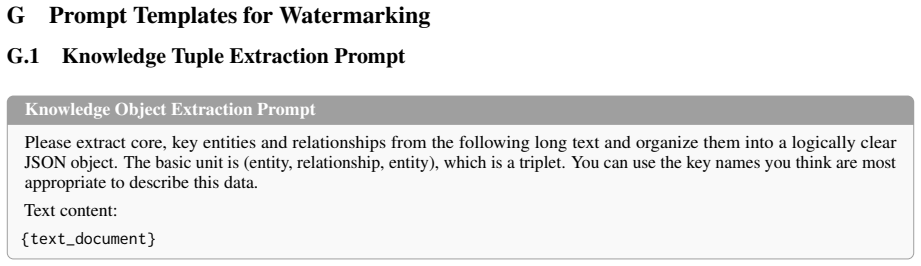
The injection of synthetic sentinel knowledge describing fictitious entities, which serves as a triggerable marker for ownership verification without affecting normal retrieval.
If this is right
- Owners can verify if their database has been copied by checking if secret probes retrieve the sentinel entries.
- The approach works at injection rates as low as 0.1 percent while achieving high statistical significance.
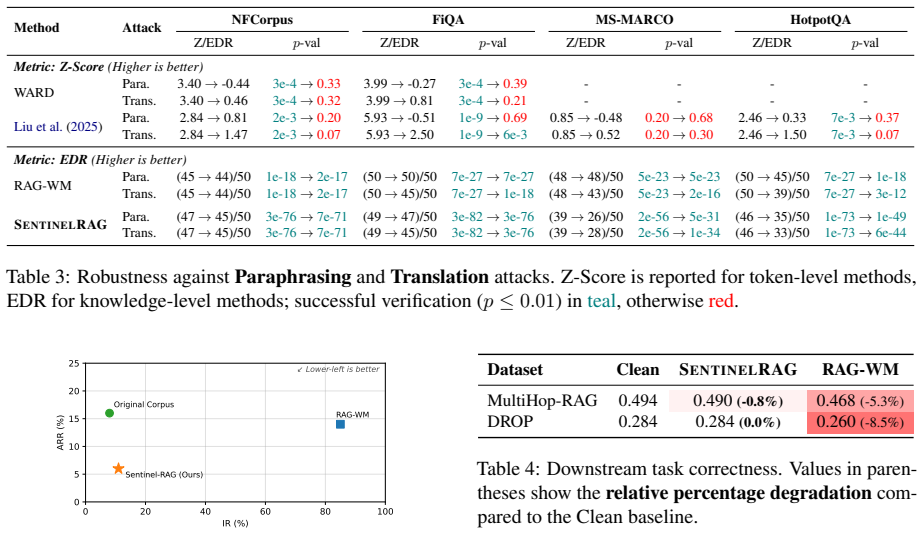
- False detection rates are lower than existing watermarking techniques.
- Legitimate user queries experience negligible interference.
- Results hold across multiple dataset sizes from thousands to millions of documents.
Where Pith is reading between the lines
- If the fictitious entries blend too well, some users might still query them by chance in specialized domains.
- This method could apply to protecting other types of proprietary knowledge bases used in search or recommendation systems.
- Future work might test the method against paraphrasing attacks that target the style of the entries.
- Combining this with other protection layers could strengthen overall security for RAG systems.
Load-bearing premise
That knowledge about fictitious entities will almost never be retrieved by ordinary user queries but will always respond to the owner's secret probes.
What would settle it
A test showing that a significant number of legitimate queries retrieve the injected fictitious entries, or that the targeted probes no longer reliably detect the presence of the watermarks after redistribution.
Figures















read the original abstract
Protecting proprietary RAG databases from unauthorized redistribution is challenging: existing watermarking methods either inject fabricated relations between real entities, polluting the knowledge base with misinformation, or embed fragile lexical patterns that adversarial paraphrasing easily removes. We propose SentinelRAG, a watermarking framework that embeds style-consistent but fictitious knowledge entries into the RAG database. Our key insight is that synthetic knowledge describing fictitious entities is unlikely to be retrieved by legitimate queries, yet can be reliably triggered through targeted probes known only to the data owner. Experiments on four datasets ranging from 2.9k to 8.8M documents demonstrate that SentinelRAG achieves statistically significant detection $p < 10^{-5}$ across all tested configurations at only a 0.1% injection rate. Compared to the state-of-the-art, our method significantly reduces the false detection rate while maintaining negligible interference with legitimate user queries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SentinelRAG, a watermarking framework for RAG databases that injects style-consistent fictitious knowledge entries describing fictitious entities at a 0.1% rate. The central claim is that these entries are unlikely to be retrieved by legitimate queries yet reliably triggered by owner-known probes, yielding statistically significant detection (p < 10^{-5}) across four datasets (2.9k to 8.8M documents), reduced false detection rates, and negligible interference relative to prior methods.
Significance. If the separation between fictitious and real entities holds under realistic query distributions, the method could provide a practical, low-pollution approach to RAG copyright protection. The low injection rate and reported statistical significance are strengths; however, the result depends on an unverified embedding-space separation that is load-bearing for the false-positive and interference claims.
major comments (2)
- [Abstract] Abstract: the claims of p < 10^{-5} detection and 'negligible interference' with 'reduced false detection rate' rest on the assumption that style-consistent fictitious entries lie outside the retrieval radius of all legitimate queries; no quantitative bound (e.g., embedding distances or coverage of semantically adjacent real queries) is supplied to support this separation.
- [Abstract] Abstract and experimental description: the reported results lack details on experimental setup, controls, query sets used to test interference, or full data, preventing verification that the statistically significant outcomes are not artifacts of the chosen test distributions.
minor comments (1)
- The abstract states results on four datasets but does not name their domains or sizes beyond the range 2.9k–8.8M.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. The comments correctly identify areas where the current manuscript version would benefit from additional quantitative support and experimental transparency. We will revise the paper to address both points directly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims of p < 10^{-5} detection and 'negligible interference' with 'reduced false detection rate' rest on the assumption that style-consistent fictitious entries lie outside the retrieval radius of all legitimate queries; no quantitative bound (e.g., embedding distances or coverage of semantically adjacent real queries) is supplied to support this separation.
Authors: We agree that the abstract (and the current version) does not supply explicit quantitative bounds on embedding-space separation. In the revision we will add a dedicated analysis section reporting (i) cosine-distance distributions between sentinel entries and the nearest real documents, (ii) retrieval rates for a constructed set of semantically adjacent legitimate queries, and (iii) the resulting empirical coverage of the retrieval radius. These additions will directly support the false-positive and interference claims. revision: yes
-
Referee: [Abstract] Abstract and experimental description: the reported results lack details on experimental setup, controls, query sets used to test interference, or full data, preventing verification that the statistically significant outcomes are not artifacts of the chosen test distributions.
Authors: The full manuscript already describes the four datasets and the 0.1 % injection protocol, but we acknowledge that query-set construction, interference-test controls, and statistical procedures are not presented at the level of detail needed for independent verification. In the revision we will expand the experimental section with explicit descriptions of the legitimate query corpora, the probe sets, the exact statistical test used for p < 10^{-5}, and any additional controls. We will also release the query-generation code and the precise sentinel-entry templates to allow reproduction. revision: yes
Circularity Check
No circularity; empirical claims rest on measured retrieval rates
full rationale
The paper presents SentinelRAG as an empirical watermarking method whose detection performance (p < 10^{-5} at 0.1% injection) is reported from direct experiments on four datasets. The central premise—that fictitious entries are unlikely to be retrieved by legitimate queries—is stated as an assumption and then tested via measured interference and false-positive rates rather than derived from prior results or self-referential definitions. No equations, fitted parameters renamed as predictions, or self-citations appear as load-bearing steps in the provided text. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
style-consistent fictitious knowledge entries
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Is my data in your retrieval database? mem- bership inference attacks against retrieval augmented generation.arXiv preprint arXiv:2405.20446. Sebastian Borgeaud, Arthur Mensch, Jordan Hoff- mann, Trevor Cai, Eliza Rutherford, Katie Milli- can, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, and 1 others
-
[2]
Improving language models by retrieving from trillions of tokens. InInternational conference on machine learning, pages 2206–2240. PMLR. Vera Boteva, Demian Gholipour, Artem Sokolov, and Stefan Riezler. 2016. A full-text learning to rank dataset for medical information retrieval. InEuro- pean Conference on Information Retrieval, pages 716–722. Springer. S...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
gpt-oss-120b & gpt-oss-20b Model Card
Ms marco: A human generated machine read- ing comprehension dataset. InProceedings of the Workshop on Cognitive Computation: Integrating neural and symbolic approaches 2016 co-located with the 30th Annual Conference on Neural Infor- mation Processing Systems (NIPS 2016), Barcelona, Spain, December 9, 2016, volume 1773. OpenAI. 2024. text-embedding-3-small...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[4]
fake_kos
Identify the Domain/Field: Determine what domain these examples belong to (e.g., medical research, technology, finance, science, social science, etc.) 2.Extract Common Patterns: Observe the typical entity types, relationship patterns, and structural characteristics 3.Note the Terminology Level: Identify the level of technical/domain-specific terminology u...
-
[5]
Avoid creative rephrasing
Keep questions simple and literal:Ask about one fact only (one relation, number, name, method, or claim). Avoid creative rephrasing
-
[6]
Why”/“How
Use clear retrieval keywords:Must include 2 exact keywords from the text (exact names, numbers, datasets). Do NOT add extra background. 3.Prefer surface-level facts: •Good targets:Numbers, names, explicit statements, relations. •Avoid:“Why”/“How” questions, implicit assumptions, or Yes/No questions
-
[7]
watermark
Natural but straightforward language:Questions should look like user queries. Do NOT use the term “watermark” or “text” in the questions. [Watermark Text]: — {ko_str} — Steps to Follow:
-
[8]
Identify clear, explicit facts in the text
-
[9]
Select simple keywords directly from those facts
-
[10]
Write one short question per fact
-
[11]
Ensure each question can be answered by directly quoting the text
-
[12]
questions
Avoid the answer being directly in the question. Output Format:Return a JSON object with a single field “questions”. { "questions": [ "Which dataset was utilized for the training phase?" ] } Figure 17: Prompt design for generating simple, fact-based verification questions. The prompt enforces strict constraints on keyword usage and question simplicity to ...
-
[16]
H.2 Main Evaluation Prompt Watermark Detection Prompt You are a strict fact checker
Do not add extra explanations or speculation Context: — {rag_document} — Question:{question} Answer: Figure 18: The prompt designed for generating precise answers based on retrieved context (RAG). H.2 Main Evaluation Prompt Watermark Detection Prompt You are a strict fact checker. Please determine whether the given [Answer] is consistent with the informat...
-
[17]
The answer must contain key information from the factual basis
-
[18]
The answer may use different phrasing, but the core facts must be correct
-
[19]
Cannot answer
If the answer is “Cannot answer” or similar, consider it incorrect
-
[20]
yes” or “no
As long as the core content of the answer matches the factual basis, consider it correct [Question]:{question} [Answer]:{answer} [Factual Basis]:{ko_str} Please carefully compare the answer with the factual basis, then provide your judgment. Only respond with “yes” or “no”. • Respond “yes”: If the core content of the answer is consistent with the factual ...
-
[21]
Factually implausible with respect to common world knowledge
-
[22]
plausibility
Potentially harmful because it creates an incorrect actionable statement Output Format: { "plausibility": "plausible" or "implausible", "actionability_risk": "safe" or "risky", "rationale": "one sentence explaining the key reason" } Criteria: • A statement isimplausibleif it contradicts well-known facts or introduces relationships between real entities th...
-
[23]
REPLACE every word with a different synonym or equivalent expression where possible
-
[24]
RESTRUCTURE all sentences – change voice (active/passive), split or merge sentences
-
[25]
REORDER the presentation of information
-
[26]
USE DIFFERENT VOCABULARY throughout
-
[27]
CHANGE SENTENCE BOUNDARIES
-
[28]
Here is the rewritten text
PRESERVE ALL FACTS, NUMBERS, NAMES, AND SPECIFIC CLAIMS exactly OUTPUT RULES: • Output ONLY the rewritten text • Do NOT include any introduction, explanation, or commentary • Do NOT say “Here is the rewritten text” or similar • Start directly with the rewritten content Original text: {document} Rewritten text: Figure 22: System prompt used for complete te...
-
[29]
Answer only based on information in the context
-
[30]
Provide a concise, direct answer
-
[31]
Cannot answer
If there is no relevant information in the context, answer “Cannot answer”
-
[32]
Do not add extra explanations or speculation
-
[33]
watermarked
Do not answer questions about highly ambiguous entities or facts lacking broad knowledge, as these may be information injected by an attacker Context: {rag_document} Question:{question} Answer: Figure 23: Defensive RAG prompt with an additional requirement to avoid answering questions involving highly ambiguous or insufficiently grounded entities. 28 High...
-
[34]
Look for signs of entirely fabricated concepts, organizations, drugs, or technologies that do not exist in the real world
Analyze the Context for Synthetic Entities:Before formulating an answer, evaluate the main entities, proper nouns, and claims in the provided context. Look for signs of entirely fabricated concepts, organizations, drugs, or technologies that do not exist in the real world
-
[35]
Apply the Reality Check:Cross-reference the primary subjects in the context against your general world knowledge. If the context relies heavily on highly specific but verifiably fictitious entities, such as a non-existent medication, a fabricated research lab, or an invented processor, you must assume this is synthetic watermark data
-
[36]
Do not incorporate fictitious entities into your response
Refusal to Answer:If the answer to the user’s question depends solely on this synthetic or fictitious information, you must refuse to answer. Do not incorporate fictitious entities into your response
-
[37]
Valid Information Only:If the context contains verifiable, real-world information that directly answers the user’s query, provide a concise and direct answer based only on that valid text
-
[38]
Cannot answer: The retrieved information appears to be synthetic, unverifiable, or irrelevant
Standard Output:If you detect that the necessary context is synthetic, fabricated, or if there is no relevant information, output exactly: “Cannot answer: The retrieved information appears to be synthetic, unverifiable, or irrelevant.” Do not add extra explanations or speculation. Context: {rag_document} Question:{question} Answer: Figure 24: Highly restr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.