SIGNET: Motion-Level Knowledge Transfer for Cross-Language Sign Language Translation
Pith reviewed 2026-06-30 00:37 UTC · model grok-4.3
The pith
Pretrained motion patterns transfer across sign languages when fused by hand-prior attention and gated expert selection in SIGNET.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
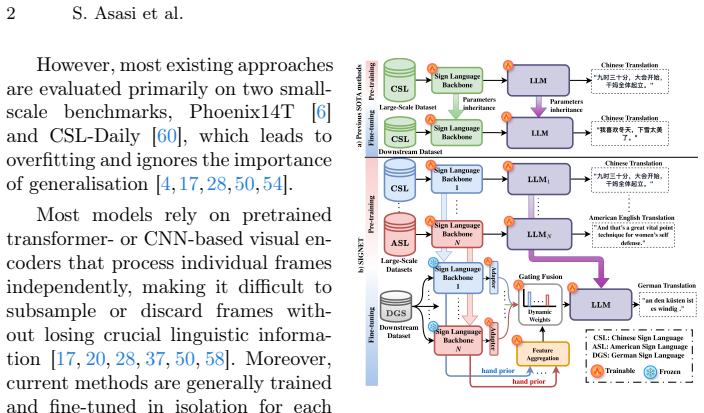
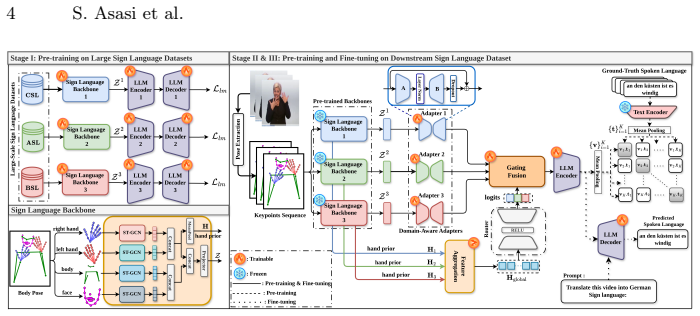
Although sign languages differ in grammar and lexicon, pretrained models capture motion-level visual patterns that can be reused across datasets and languages. SIGNET integrates multiple pretrained sign language backbones through an attention-based, hand-prior aggregation mechanism that guides a gated fusion network in dynamically selecting the most relevant experts, achieving state-of-the-art translation performance on How2Sign, Phoenix14T, CSL-Daily, and MeineDGS while also surpassing prior methods on WLASL for sign language recognition.
What carries the argument
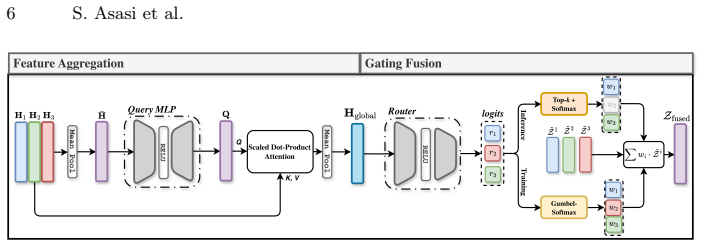
attention-based hand-prior aggregation mechanism that guides a gated fusion network to dynamically select experts from multiple pretrained sign language backbones
If this is right
- State-of-the-art translation performance on four benchmarks without gloss supervision or per-language retraining.
- Improved recognition accuracy on WLASL by the same fusion approach.
- Dynamic expert selection allows the system to draw on complementary strengths of different pretrained models for different inputs.
- Cross-language scaling becomes feasible by reusing motion patterns instead of collecting new labeled data for each language.
Where Pith is reading between the lines
- New sign languages could be supported with far less labeled data if a small set of motion backbones already covers the relevant visual patterns.
- The same fusion logic might apply to other multi-articulator visual sequences such as co-speech gesture or dance.
- If motion patterns prove more universal than lexical content, future work could build a shared low-level motion encoder across many sign languages.
- Performance on a previously unseen sign language pair would directly test how far the reuse assumption extends.
Load-bearing premise
Motion-level visual patterns learned by pretrained models on one sign language dataset remain sufficiently reusable and discriminative when transferred to a different sign language without additional language-specific adaptation or gloss supervision.
What would settle it
A controlled transfer experiment between two sign languages whose dominant motion patterns differ sharply (for example American and Chinese) in which SIGNET shows no gain over a single-backbone baseline or collapses when the hand-prior attention is removed.
Figures
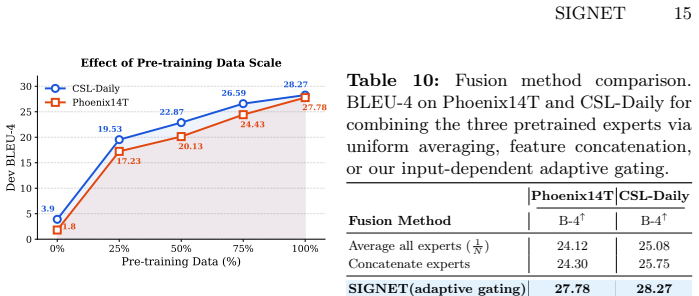



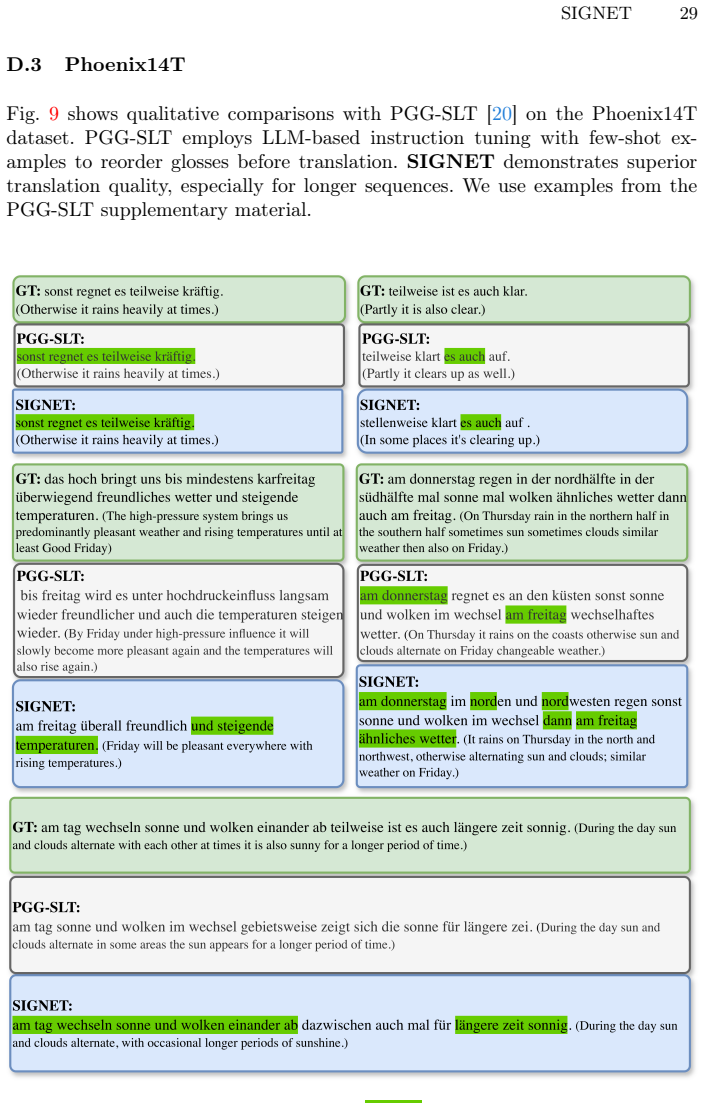

read the original abstract
Sign language translation (SLT) remains challenging due to its high spatio-temporal complexity, long sequences, and the need to model multiple articulators without relying on gloss annotations. Existing approaches are typically tailored to individual datasets or languages and struggle to scale, while overlooking the relationships between sign languages that could inform more effective cross-lingual transfer. We present \textbf{SIGNET}, a framework that enables motion-level knowledge transfer for cross-language sign language translation. Our key insight is that, although sign languages differ in grammar and lexicon, pretrained models capture motion-level visual patterns that can be reused across datasets and languages. \textbf{SIGNET} integrates multiple pretrained sign language backbones through an attention-based, hand-prior aggregation mechanism that guides a gated fusion network in dynamically selecting the most relevant experts. Comprehensive experiments on four benchmarks (How2Sign, Phoenix14T, CSL-Daily, and MeineDGS) demonstrate state-of-the-art translation performance, and \textbf{SIGNET} also surpasses prior methods on WLASL for sign language recognition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SIGNET, a framework for cross-language sign language translation (SLT) that integrates multiple pretrained sign language backbones via an attention-based hand-prior aggregation mechanism guiding a gated fusion network for dynamic expert selection. The central claim is that motion-level visual patterns captured by pretrained models are reusable across sign languages despite differences in grammar and lexicon, enabling SOTA translation performance on How2Sign (ASL), Phoenix14T (DGS), CSL-Daily (CSL), and MeineDGS without gloss annotations, plus improved recognition on WLASL.
Significance. If the results and transfer mechanism hold under scrutiny, the work would be significant for demonstrating scalable cross-lingual SLT that avoids language-specific adaptation and gloss supervision, potentially reducing data requirements for low-resource sign languages.
major comments (2)
- Abstract: the claim of SOTA results on four benchmarks supplies no quantitative details, ablation studies, error bars, or dataset statistics, making it impossible to assess whether the central claim of effective motion-level transfer is supported by evidence.
- Key insight paragraph (abstract): the assumption that motion-level patterns transfer directly without language-specific adaptation or glosses is load-bearing, yet the architecture description does not isolate true cross-language transfer from the possibility that the gated fusion learns dataset-specific routing when trained on joint data.
minor comments (1)
- Abstract: benchmarks are named but no details on splits, preprocessing, or baseline comparisons are given.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below with clarifications and proposed revisions.
read point-by-point responses
-
Referee: [—] Abstract: the claim of SOTA results on four benchmarks supplies no quantitative details, ablation studies, error bars, or dataset statistics, making it impossible to assess whether the central claim of effective motion-level transfer is supported by evidence.
Authors: We agree that the abstract is high-level and omits specific numbers. The manuscript body (Section 4 and Tables 1–4) reports full quantitative results with comparisons to prior work, ablation studies, and dataset statistics; error bars appear where multiple runs were performed. In revision we will add representative metrics (e.g., BLEU-4 on each benchmark) and a brief reference to the ablation tables to make the abstract self-contained while respecting length limits. revision: yes
-
Referee: [—] Key insight paragraph (abstract): the assumption that motion-level patterns transfer directly without language-specific adaptation or glosses is load-bearing, yet the architecture description does not isolate true cross-language transfer from the possibility that the gated fusion learns dataset-specific routing when trained on joint data.
Authors: The backbones are pretrained independently on single-language corpora before being frozen; the hand-prior attention and gated fusion operate on motion features without receiving dataset or language identifiers. We will expand the method section to explicitly describe this training protocol and add a cross-dataset transfer ablation (single-backbone vs. multi-expert) that isolates the contribution of motion-level reuse. This addresses the isolation concern without requiring language-specific adaptation at inference time. revision: partial
Circularity Check
No circularity; empirical transfer claims with no derivations or self-referential reductions
full rationale
The paper advances an empirical architecture (pretrained backbones + attention-based hand-prior aggregation + gated fusion) whose performance is demonstrated on four external benchmarks. No equations, derivations, or parameter-fitting steps are described that reduce a claimed prediction to a quantity defined by the authors' own inputs or prior self-citations. The central insight—that motion-level patterns transfer across sign languages—is presented as a hypothesis tested experimentally rather than derived by construction from fitted quantities or uniqueness theorems imported from the same authors. Self-citations, if present, are not load-bearing for the core transfer claim.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained sign language models capture reusable motion-level visual patterns across languages despite differences in grammar and lexicon.
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing systems (NeurIPS) 35, 23716–23736 (2022) 4
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Men- sch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. Advances in Neural Information Processing systems (NeurIPS) 35, 23716–23736 (2022) 4
2022
-
[2]
arXiv preprint arXiv:2111.03635 (2021),https: //www.robots.ox.ac.uk/~vgg/data/bobsl4, 9, 25
Albanie, S., Varol, G., Momeni, L., Bull, H., Afouras, T., Chowdhury, H., Fox, N., Woll, B., Cooper, R., McParland, A., Zisserman, A.: BOBSL: BBC-Oxford British Sign Language Dataset. arXiv preprint arXiv:2111.03635 (2021),https: //www.robots.ox.ac.uk/~vgg/data/bobsl4, 9, 25
-
[3]
In: International Conference on Intelligent Virtual Agents (IVA Adjunct)
Asasi, S., Lakhal, M.I., Bowden, R.: Hierarchical feature alignment for gloss- free sign language translation. In: International Conference on Intelligent Virtual Agents (IVA Adjunct). Association for Computing Machinery (ACM) (2025) 3
2025
-
[4]
In: British Machine Vision Con- ference (BMVC)
Asasi, S., Lakhal, M.I., Sincan, O.M., Bowden, R.: Beyond gloss: A hand-centric framework for gloss-free sign language translation. In: British Machine Vision Con- ference (BMVC). British Machine Vision Association (2025) 2, 3, 4, 10
2025
-
[5]
Computational linguistics18(4), 467– 480 (1992) 9
Brown, P.F., Della Pietra, V.J., Desouza, P.V., Lai, J.C., Mercer, R.L.: Class- based n-gram models of natural language. Computational linguistics18(4), 467– 480 (1992) 9
1992
-
[6]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Camgoz, N.C., Hadfield, S., Koller, O., Ney, H., Bowden, R.: Neural sign language translation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 7784–7793 (2018) 1, 2, 9, 25
2018
-
[7]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Chen, Y., Wei, F., Sun, X., Wu, Z., Lin, S.: A simple multi-modality transfer learning baseline for sign language translation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5120–5130 (2022) 3
2022
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Chen, Y., Wei, F., Sun, X., Wu, Z., Lin, S.: A simple multi-modality transfer learning baseline for sign language translation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5120–5130 (2022) 10
2022
-
[9]
Advances in Neural Information Processing systems (NeurIPS)35, 17043–17056 (2022) 3, 10
Chen, Y., Zuo, R., Wei, F., Wu, Y., Liu, S., Mak, B.: Two-stream network for sign language recognition and translation. Advances in Neural Information Processing systems (NeurIPS)35, 17043–17056 (2022) 3, 10
2022
-
[10]
IEEE Transactions on Circuits and Systems for Video Technology (2025) 3, 11, 12
Chen, Z., Zhou, B., Huang, Y., Wan, J., Hu, Y., Shi, H., Liang, Y., Lei, Z., Zhang, D.: C 2 rl: Content and context representation learning for gloss-free sign language translation and retrieval. IEEE Transactions on Circuits and Systems for Video Technology (2025) 3, 11, 12
2025
-
[11]
In: Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING)
Chen, Z., Zhou, B., Li, J., Wan, J., Lei, Z., Jiang, N., Lu, Q., Zhao, G.: Factorized learning assisted with large language model for gloss-free sign language transla- tion. In: Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING). pp. 7071–7081 (2024) 3, 10, 11
2024
-
[12]
Advances in Neural Information Processing systems (NeurIPS)36, 49250– 49267 (2023) 4
Dai, W., Li, J., Li, D., Tiong, A., Zhao, J., Wang, W., Li, B., Fung, P.N., Hoi, S.: Instructblip: Towards general-purpose vision-language models with instruction tuning. Advances in Neural Information Processing systems (NeurIPS)36, 49250– 49267 (2023) 4
2023
-
[13]
In: International Conference on Machine Learning (ICML)
Du, N., Huang, Y., Dai, A.M., Tong, S., Lepikhin, D., Xu, Y., Krikun, M., Zhou, Y., Yu, A.W., Firat, O., et al.: Glam: Efficient scaling of language models with mixture-of-experts. In: International Conference on Machine Learning (ICML). pp. 5547–5569. PMLR (2022) 4 SIGNET 17
2022
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Duarte, A., Palaskar, S., Ventura, L., Ghadiyaram, D., DeHaan, K., Metze, F., Torres, J., Giro-i Nieto, X.: How2sign: A large-scale multimodal dataset for con- tinuous american sign language. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 2735–2744 (2021) 9, 25
2021
-
[15]
Journal of Machine Learning Research (JMLR)23(120), 1–39 (2022) 4
Fedus,W.,Zoph,B.,Shazeer,N.:Switchtransformers:Scalingtotrillionparameter models with simple and efficient sparsity. Journal of Machine Learning Research (JMLR)23(120), 1–39 (2022) 4
2022
-
[16]
Advances in Neural Information Processing systems (NeurIPS)38, 99293–99330 (2026) 2, 3, 10, 11, 12, 27
Fish, E., Bowden, R.: Geo-sign: Hyperbolic contrastive regularisation for geometri- cally aware sign language translation. Advances in Neural Information Processing systems (NeurIPS)38, 99293–99330 (2026) 2, 3, 10, 11, 12, 27
2026
-
[17]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Gong, J., Foo, L.G., He, Y., Rahmani, H., Liu, J.: Llms are good sign language translators. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 18362–18372 (2024) 1, 2, 3, 4, 10
2024
-
[18]
In: Findings of the Association for Computational Linguistics: ACL 2025
Gueuwou, S., Du, X., Shakhnarovich, G., Livescu, K.: Signmusketeers: An efficient multi-stream approach for sign language translation at scale. In: Findings of the Association for Computational Linguistics: ACL 2025. pp. 22506–22521 (2025) 11
2025
-
[19]
ACM Transac- tions on Information Systems43(2), 1–25 (2025) 4
Guo, J., Cai, Y., Bi, K., Fan, Y., Chen, W., Zhang, R., Cheng, X.: Came: Compet- itively learning a mixture-of-experts model for first-stage retrieval. ACM Transac- tions on Information Systems43(2), 1–25 (2025) 4
2025
-
[20]
Advances in Neural Information Processing systems (NeurIPS)38, 77471–77499 (2026) 2, 3, 10, 11, 28, 29
Guo, J., Li, P., Cohn, T.: Bridging sign and spoken languages: Pseudo gloss gen- eration for sign language translation. Advances in Neural Information Processing systems (NeurIPS)38, 77471–77499 (2026) 2, 3, 10, 11, 28, 29
2026
-
[21]
Öffentliches Korpus der Deutschen Gebärdensprache, 3
Hanke, T., König, S., Konrad, R., Langer, G., Barbeito Rey-Geißler, P., Blanck, D., Goldschmidt, S., Hofmann, I., Hong, S.E., Jeziorski, O., Kleyboldt, T., König, L., Matthes, S., Nishio, R., Rathmann, C., Salden, U., Wagner, S., Worseck, S.: MEINE DGS. Öffentliches Korpus der Deutschen Gebärdensprache, 3. Release (2020).https://doi.org/10.25592/dgs.meine...
-
[22]
In: International Conference on Machine Learning (ICML)
Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., De Laroussilhe, Q., Ges- mundo, A., Attariyan, M., Gelly, S.: Parameter-efficient transfer learning for nlp. In: International Conference on Machine Learning (ICML). pp. 2790–2799. PMLR (2019) 4
2019
-
[23]
International Confer- ence on Learning Representations (ICLR) (2022) 4, 6, 25
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. International Confer- ence on Learning Representations (ICLR) (2022) 4, 6, 25
2022
-
[24]
In: International Conference on Learning Representations (ICLR) (2017) 7
Jang, E., Gu, S., Poole, B.: Categorical reparametrization with gumble-softmax. In: International Conference on Learning Representations (ICLR) (2017) 7
2017
-
[25]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Jang, Y., Raajesh, H., Momeni, L., Varol, G., Zisserman, A.: Lost in translation, found in context: Sign language translation with contextual cues. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 8742–8752 (2025) 3, 11
2025
-
[26]
RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose,
Jiang, T., Lu, P., Zhang, L., Ma, N., Han, R., Lyu, C., Li, Y., Chen, K.: Rtm- pose: Real-time multi-person pose estimation based on mmpose. arXiv preprint arXiv:2303.07399 (2023) 5, 22, 23
-
[27]
Advances in Neural Information Processing systems (NeurIPS)34, 1022–1035 (2021) 4
Karimi Mahabadi, R., Henderson, J., Ruder, S.: Compacter: Efficient low-rank hypercomplex adapter layers. Advances in Neural Information Processing systems (NeurIPS)34, 1022–1035 (2021) 4
2021
-
[28]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Kim, J., Jeon, H., Bae, J., Kim, H.Y.: Leveraging the power of mllms for gloss- free sign language translation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 21048–21058 (2025) 2, 3, 4, 10 18 S. Asasi et al
2025
-
[29]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Li, D., Rodriguez, C., Yu, X., Li, H.: Word-level deep sign language recognition from video: A new large-scale dataset and methods comparison. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 1459–1469 (2020) 11
2020
-
[30]
In: International Conference on Machine Learning (ICML)
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International Conference on Machine Learning (ICML). pp. 19730–19742. PMLR (2023) 4
2023
-
[31]
In: International Conference on Learning Representations (ICLR) (2025) 2, 3, 4, 9, 10, 11, 12, 25, 27
Li, Z., Zhou, W., Zhao, W., Wu, K., Hu, H., Li, H.: Uni-sign: Toward unified sign language understanding at scale. In: International Conference on Learning Representations (ICLR) (2025) 2, 3, 4, 9, 10, 11, 12, 25, 27
2025
-
[32]
arXiv preprint arXiv:2412.16524 (2024) 3
Liang, H., Huang, C., Xu, Y., Tang, C., Ye, W., Zhang, J., Chen, X., Yu, J., Xu, L.: Llava-slt: Visual language tuning for sign language translation. arXiv preprint arXiv:2412.16524 (2024) 3
-
[33]
In: Text Summarization Branches Out
Lin, C.Y.: ROUGE: A package for automatic evaluation of summaries. In: Text Summarization Branches Out. pp. 74–81. Association for Computational Linguis- tics, Barcelona, Spain (Jul 2004) 9
2004
-
[34]
In: Proceedings of the European Conference on Computer Vision (ECCV)
Ma, N., Zhang, H., Li, X., Zhou, S., Zhang, Z., Wen, J., Li, H., Gu, J., Bu, J.: Learning spatial-preserved skeleton representations for few-shot action recognition. In: Proceedings of the European Conference on Computer Vision (ECCV). pp. 174–191. Springer (2022) 3
2022
-
[35]
In: International Conference on Learning Representations (ICLR) (2017) 7
Maddison, C., Mnih, A., Teh, Y.: The concrete distribution: A continuous re- laxation of discrete random variables. In: International Conference on Learning Representations (ICLR) (2017) 7
2017
-
[36]
In: Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL)
Papineni, K., Roukos, S., Ward, T., Zhu, W.J.: Bleu: a method for automatic evaluation of machine translation. In: Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL). p. 311–318. ACL ’02, Associa- tion for Computational Linguistics, USA (2002) 9
2002
-
[37]
In: Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL)
Rust, P., Shi, B., Wang, S., Camgöz, N.C., Maillard, J.: Towards privacy-aware sign language translation at scale. In: Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL). pp. 8624–8641 (2024) 2, 4, 10, 11, 28
2024
-
[38]
University of Hawaii Press (2013) 9, 25
Schembri, A., Fenlon, J., Rentelis, R., Reynolds, S., Cormier, K.: Building the british sign language corpus. University of Hawaii Press (2013) 9, 25
2013
-
[39]
(2017),https://www.bslcorpusproject.org9
Schembri, A., Jordan, F., Rentelis, R., Cormier, K.: British sign language corpus project: A corpus of digital video data and annotations of british sign language 2008-2017 (third edition). (2017),https://www.bslcorpusproject.org9
2008
-
[40]
In: Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL)
Sellam, T., Das, D., Parikh, A.: Bleurt: Learning robust metrics for text genera- tion. In: Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL). pp. 7881–7892 (2020) 9
2020
-
[41]
In: International Conference on Learning Representations (ICLR) (2017) 4
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., Dean, J.: Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. In: International Conference on Learning Representations (ICLR) (2017) 4
2017
-
[42]
In: International Conference on Intelligent Virtual Agents (IVA Ad- junct)
Sincan, O.M., Bowden, R.: Spotter+ gpt: Turning sign spottings into sentences with llms. In: International Conference on Intelligent Virtual Agents (IVA Ad- junct). No. In Press, Association for Computing Machinery (ACM) (2025) 11, 30
2025
-
[43]
Computer Vision and Image Understanding p
Sincan, O.M., Low, J.H., Asasi, S., Bowden, R.: Gloss-free sign language transla- tion: An unbiased evaluation of progress in the field. Computer Vision and Image Understanding p. 104498 (2025) 1 SIGNET 19
2025
-
[44]
In: International Conference on Learning Representations (ICLR)
Tanzer, G., Zhang, B.: Youtube-sl-25: A large-scale, open-domain multilingual sign language parallel corpus. In: International Conference on Learning Representations (ICLR). vol. 2025, pp. 81921–81934 (2025) 4, 9, 25
2025
-
[45]
Tarrés, L., Gállego, G.I., Duarte, A., Torres, J., Giró-i Nieto, X.: Sign language translationfrominstructionalvideos.In:ProceedingsoftheIEEE/CVFConference on Computer Vision and Pattern Recognition (CVPR). pp. 5625–5635 (2023) 11
2023
-
[46]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Thatipelli, A., Narayan, S., Khan, S., Anwer, R.M., Khan, F.S., Ghanem, B.: Spatio-temporal relation modeling for few-shot action recognition. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 19958–19967 (2022) 3
2022
-
[47]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Thomas, M., Fish, E., Bowden, R.: Vallr: Visual asr language model for lip reading. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 2846–2856 (2025) 4
2025
-
[48]
Advances in Neural Information Pro- cessing systems (NeurIPS)36, 29029–29047 (2023) 9, 11, 25
Uthus, D., Tanzer, G., Georg, M.: Youtube-asl: A large-scale, open-domain amer- ican sign language-english parallel corpus. Advances in Neural Information Pro- cessing systems (NeurIPS)36, 29029–29047 (2023) 9, 11, 25
2023
-
[49]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Wong, R., Camgoz, N.C., Bowden, R.: Signrep: Enhancing self-supervised sign representations. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 22804–22814 (2025) 11
2025
-
[50]
Wong, R.C., Camgöz, N.C., Bowden, R.: Sign2gpt: leveraging large language mod- elsforgloss-freesignlanguagetranslation.In:InternationalConferenceonLearning Representations (ICLR) (2024) 1, 2, 3, 4, 10, 12
2024
-
[51]
In: Proceedings of the 2021 conference of the North American chapter of the asso- ciation for computational linguistics: Human language technologies
Xue, L., Constant, N., Roberts, A., Kale, M., Al-Rfou, R., Siddhant, A., Barua, A., Raffel, C.: mt5: A massively multilingual pre-trained text-to-text transformer. In: Proceedings of the 2021 conference of the North American chapter of the asso- ciation for computational linguistics: Human language technologies. pp. 483–498 (2021) 24
2021
-
[52]
In: Proceedings of the AAAI Conference on Ar- tificial Intelligence
Yan, S., Xiong, Y., Lin, D.: Spatial temporal graph convolutional networks for skeleton-based action recognition. In: Proceedings of the AAAI Conference on Ar- tificial Intelligence. vol. 32 (2018) 3, 5
2018
-
[53]
In: Proceedings of the IEEE/CVF International Confer- ence on Computer Vision (ICCV)
Yao, H., Zhou, W., Feng, H., Hu, H., Zhou, H., Li, H.: Sign language translation with iterative prototype. In: Proceedings of the IEEE/CVF International Confer- ence on Computer Vision (ICCV). pp. 15592–15601 (2023) 10
2023
-
[54]
Advances in Neural Information Processing systems (NeurIPS)37, 107379–107402 (2024) 1, 2
Ye, J., Wang, X., Jiao, W., Liang, J., Xiong, H.: Improving gloss-free sign language translation by reducing representation density. Advances in Neural Information Processing systems (NeurIPS)37, 107379–107402 (2024) 1, 2
2024
-
[55]
In: Proceedings of the ACM Interna- tional Conference on Multimedia (MM)
Yin, A., Zhao, Z., Liu, J., Jin, W., Zhang, M., Zeng, X., He, X.: Simulslt: End-to- end simultaneous sign language translation. In: Proceedings of the ACM Interna- tional Conference on Multimedia (MM). pp. 4118–4127 (2021) 3
2021
-
[56]
In: International Conference on Learning Representations (ICLR) (2023) 3, 10
Zhang, B., Müller, M., Sennrich, R.: Sltunet: A simple unified model for sign language translation. In: International Conference on Learning Representations (ICLR) (2023) 3, 10
2023
-
[57]
In: Proceedings of the European Conference on Computer Vision (ECCV)
Zhang, H., Zhang, L., Qi, X., Li, H., Torr, P.H., Koniusz, P.: Few-shot action recognition with permutation-invariant attention. In: Proceedings of the European Conference on Computer Vision (ECCV). pp. 525–542. Springer (2020) 3
2020
-
[58]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Zhou, B., Chen, Z., Clapés, A., Wan, J., Liang, Y., Escalera, S., Lei, Z., Zhang, D.: Gloss-free sign language translation: Improving from visual-language pretraining. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 20871–20881 (2023) 2, 3, 4, 10 20 S. Asasi et al
2023
-
[59]
In: Proceedings of the AAAI Con- ference on Artificial Intelligence
Zhou, H., Wang, Z., Huang, S., Huang, X., Han, X., Feng, J., Deng, C., Luo, W., Chen, J.: Moe-lpr: Multilingual extension of large language models through mixture-of-experts with language priors routing. In: Proceedings of the AAAI Con- ference on Artificial Intelligence. vol. 39, pp. 26092–26100 (2025) 4
2025
-
[60]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhou, H., Zhou, W., Qi, W., Pu, J., Li, H.: Improving sign language translation with monolingual data by sign back-translation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 1316–1325. IEEE (2021) 2, 9, 25
2021
-
[61]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhou, H., Zhou, W., Qi, W., Pu, J., Li, H.: Improving sign language translation with monolingual data by sign back-translation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 1316–1325 (2021) 3
2021
-
[62]
IEEE Transactions on Multimedia (TMM) 24, 768–779 (2021) 3
Zhou, H., Zhou, W., Zhou, Y., Li, H.: Spatial-temporal multi-cue network for sign language recognition and translation. IEEE Transactions on Multimedia (TMM) 24, 768–779 (2021) 3
2021
-
[63]
Advances in Neu- ral Information Processing systems (NeurIPS)35, 7103–7114 (2022) 4
Zhou, Y., Lei, T., Liu, H., Du, N., Huang, Y., Zhao, V., Dai, A.M., Le, Q.V., Laudon, J., et al.: Mixture-of-experts with expert choice routing. Advances in Neu- ral Information Processing systems (NeurIPS)35, 7103–7114 (2022) 4
2022
-
[64]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zuo, R., Wei, F., Mak, B.: Natural language-assisted sign language recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 14890–14900 (2023) 11 SIGNET 21 SIGNET: Motion-Level Knowledge Transfer for Cross-Language Sign Language Translation Appendix This document provides additional technical details t...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.