Predicate Importance Estimation and Decoupled Rationale-Score Distillation for Entity Alignment
Pith reviewed 2026-06-26 08:18 UTC · model grok-4.3
The pith
Predicate Importance Estimation and Decoupled Rationale-Score Distillation improve entity alignment by creating better embeddings and enabling uncertainty detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By constructing a pairwise EA dataset and applying PIE to build predicate-aware embeddings and DRSD to distill reasoning from an LLM to an SLM with decoupled confidence signals, the approach improves EA classification accuracy and supports human-in-the-loop verification through score-rationale discrepancies.
What carries the argument
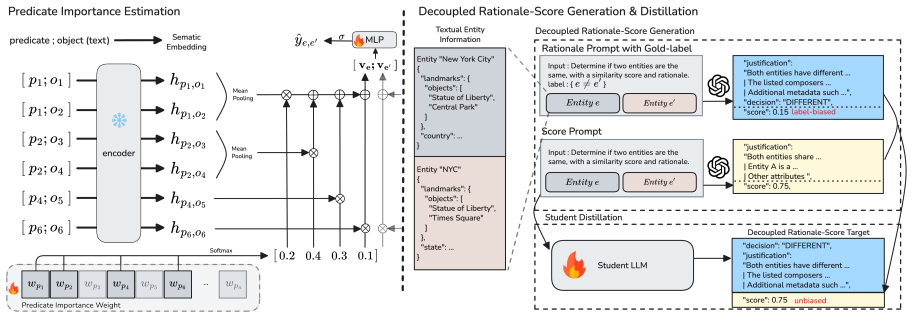
Predicate Importance Estimation (PIE) that encodes subjectless triples and aggregates with predicate-importance weights; Decoupled Rationale-Score Distillation (DRSD) that converts labels to text supervision and separates confidence estimation from rationales.
If this is right
- PIE generates entity embeddings that reflect the importance of different predicates in local neighborhoods.
- DRSD enables small language models to learn task-specific reasoning from large model pseudo-labels while maintaining less biased confidence scores.
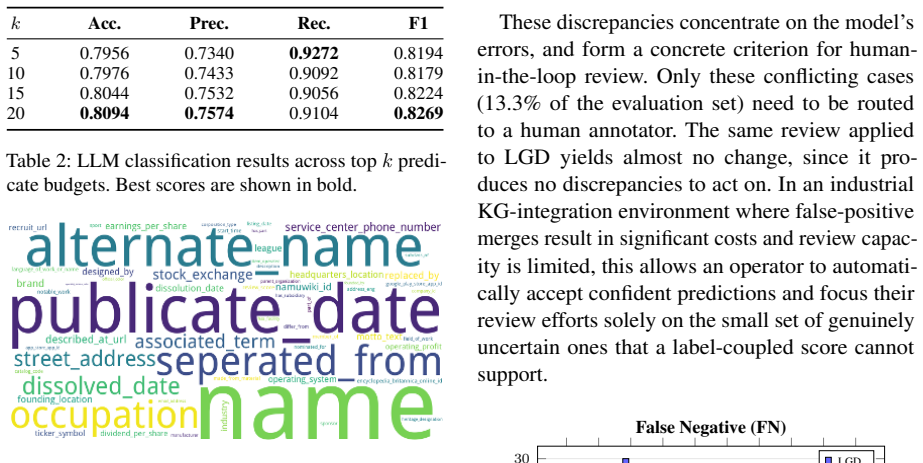
- Discrepancies between predicted rationales and confidence scores identify uncertain entity alignments for human verification.
- The combined method facilitates integration of public and domain-specific knowledge graphs in industrial systems.
Where Pith is reading between the lines
- Small models distilled this way could replace larger models in production entity alignment pipelines.
- The decoupling technique may apply to other classification tasks where both reasoning and confidence are needed.
- If the assumption on pseudo-label quality holds, it reduces reliance on manual labeling for EA datasets.
Load-bearing premise
The teacher large language model produces high-quality pseudo-answers and rationales that transfer useful reasoning without label bias that decoupling cannot mitigate.
What would settle it
A test showing that models trained with DRSD do not achieve higher EA accuracy than baselines or that rationale-score discrepancies fail to predict actual errors in alignment decisions.
Figures







read the original abstract
Knowledge graphs (KGs) are increasingly used as structured context for Large Language Models (LLMs), but industrial KG-RAG systems often need to integrate public and domain-specific KGs constructed from heterogeneous databases. This integration relies on Entity Alignment (EA), where lexical matching alone is insufficient under predicate-name variation and incomplete local neighborhoods. We address EA for KG integration by constructing a pairwise EA dataset and proposing two complementary modules: Predicate Importance Estimation (PIE) and Decoupled Rationale-Score Distillation (DRSD). PIE is a compact embedding-based approach that removes the subject information from each 1-hop triple, encodes the resulting subjectless triples, and aggregates them with learnable predicate-importance weights to build predicate-aware entity embeddings. DRSD trains a distilled small language model (SLM) with pseudo-answers produced by a teacher LLM through distinct prompts. By converting binary EA labels into text-based supervision and decoupling confidence-score estimation from label-consistent rationales, DRSD enables the SLM to learn task-specific reasoning while retaining a less label-biased confidence signal. Experiments show that PIE and DRSD improve EA classification. Moreover, because DRSD decouples confidence-score estimation from the decision, a discrepancy between the two flags an uncertain prediction for human review, thereby enabling a practical discrepancy between automatic acceptance and human-in-the-loop verification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to address Entity Alignment (EA) challenges in integrating heterogeneous KGs for KG-RAG by constructing a pairwise EA dataset and introducing two modules: Predicate Importance Estimation (PIE), which removes subject information from 1-hop triples, encodes the subjectless triples, and aggregates them using learnable predicate-importance weights to form predicate-aware embeddings; and Decoupled Rationale-Score Distillation (DRSD), which distills an SLM from a teacher LLM using distinct prompts to generate pseudo-answers, converts binary labels to text supervision, and separates rationale generation from confidence-score estimation to enable learning of task-specific reasoning with reduced label bias. Experiments are stated to show that PIE and DRSD improve EA classification, and the decoupling allows discrepancy between score and decision to flag uncertain predictions for human review.
Significance. If the results hold with proper validation, the work could contribute a compact embedding method for handling predicate variation in EA and a distillation approach with built-in uncertainty detection for human-in-the-loop verification, which would be useful for industrial KG integration scenarios. The internal consistency of the decoupling mechanism for flagging uncertainty is a positive design element.
major comments (1)
- [Abstract] Abstract (and full text as provided): The manuscript contains no experimental details, datasets, baselines, error bars, quantitative results, or derivation steps for PIE or DRSD. This makes it impossible to verify whether any reported improvements support the central claims.
Simulated Author's Rebuttal
We thank the referee for their review and for identifying the absence of experimental details. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (and full text as provided): The manuscript contains no experimental details, datasets, baselines, error bars, quantitative results, or derivation steps for PIE or DRSD. This makes it impossible to verify whether any reported improvements support the central claims.
Authors: We agree that the manuscript as provided lacks the experimental details, datasets, baselines, error bars, quantitative results, and derivation steps necessary to verify the claims. The revised manuscript will include a dedicated Experiments section that specifies the constructed pairwise EA dataset, the full set of baselines, quantitative results with error bars, and step-by-step derivations for both PIE and DRSD. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces PIE as a compact embedding aggregation that removes subject information from triples, encodes subjectless triples, and aggregates with learnable predicate-importance weights, and DRSD as converting binary labels to text supervision while decoupling confidence-score estimation from rationales. These are standard techniques in embedding models and knowledge distillation with no equations shown that reduce outputs to inputs by construction, no fitted parameters renamed as predictions, and no load-bearing self-citations or uniqueness theorems invoked. The claimed improvements follow directly from the described modules without self-referential definitions or ansatzes smuggled via prior work. The derivation is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
ACM Computing Surveys , volume =
Ziwei Ji and Nayeon Lee and Rita Frieske and Tiezheng Yu and Dan Su and Yan Xu and Etsuko Ishii and Ye Jin Bang and Andrea Madotto and Pascale Fung , title =. ACM Computing Surveys , volume =. 2023 , doi =
2023
-
[5]
Lei Huang and Weijiang Yu and Weitao Ma and Weihong Zhong and Zhangyin Feng and Haotian Wang and Qianglong Chen and Weihua Peng and Xiaocheng Feng and Bing Qin and Ting Liu , title =. ACM Transactions on Information Systems , year =. doi:10.1145/3703155 , url =
-
[6]
Unifying Large Language Models and Knowledge Graphs: A Roadmap , year=
Pan, Shirui and Luo, Linhao and Wang, Yufei and Chen, Chen and Wang, Jiapu and Wu, Xindong , journal=. Unifying Large Language Models and Knowledge Graphs: A Roadmap , year=
-
[7]
Language Models as Knowledge Bases? , booktitle =
Fabio Petroni and Tim Rockt. Language Models as Knowledge Bases? , booktitle =. 2019 , url =
2019
-
[8]
Ni and Heung-Yeung Shum and Jian Guo , title =
Jiashuo Sun and Chengjin Xu and Lumingyuan Tang and Saizhuo Wang and Chen Lin and Yeyun Gong and Lionel M. Ni and Heung-Yeung Shum and Jian Guo , title =. International Conference on Learning Representations (ICLR) , year =
-
[9]
International Conference on Learning Representations (ICLR) , year =
Linhao Luo and Yuan-Fang Li and Gholamreza Haffari and Shirui Pan , title =. International Conference on Learning Representations (ICLR) , year =
-
[10]
Findings of the Association for Computational Linguistics: ACL 2024 , pages =
Haoran Luo and Haihong E and Zichen Tang and Shiyao Peng and Yikai Guo and Wentai Zhang and Chenghao Ma and Guanting Dong and Meina Song and Wei Lin and Yifan Zhu and Anh Tuan Luu , title =. Findings of the Association for Computational Linguistics: ACL 2024 , pages =. 2024 , url =
2024
-
[11]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages =
Jiho Kim and Yeonsu Kwon and Yohan Jo and Edward Choi , title =. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages =. 2023 , url =
2023
-
[12]
Proceedings of WSDM , year =
Gaole He and Yunshi Lan and Jing Jiang and Wayne Xin Zhao and Ji-Rong Wen , title =. Proceedings of WSDM , year =
-
[13]
Proceedings of ACL-IJCNLP , pages =
Wen-tau Yih and Ming-Wei Chang and Xiaodong He and Jianfeng Gao , title =. Proceedings of ACL-IJCNLP , pages =. 2015 , url =
2015
-
[14]
2012 , url =
Souripriya Das and Seema Sundara and Richard Cyganiak , title =. 2012 , url =
2012
-
[15]
2012 , url =
Marcelo Arenas and Alexandre Bertails and Eric Prud'hommeaux and Juan Sequeda , title =. 2012 , url =
2012
-
[16]
and Miranker, Daniel P
Sequeda, Juan F. and Miranker, Daniel P. , journal=. A Pay-As-You-Go Methodology for Ontology-Based Data Access , year=
-
[17]
Knowledge Graphs , journal =
Aidan Hogan and Eva Blomqvist and Michael Cochez and Claudia D'amato and Gerard. Knowledge Graphs , journal =. 2021 , doi =
2021
-
[18]
Retrieval-Augmented Generation for Knowledge-Intensive
Patrick Lewis and Ethan Perez and Aleksandra Piktus and Fabio Petroni and Vladimir Karpukhin and Naman Goyal and Heinrich K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems (NeurIPS) , pages =. 2020 , url =
2020
-
[19]
Proceedings of ICML , year =
Kelvin Guu and Kenton Lee and Zora Tung and Panupong Pasupat and Ming-Wei Chang , title =. Proceedings of ICML , year =
-
[20]
Dense Passage Retrieval for Open-Domain Question Answering , booktitle =
Vladimir Karpukhin and Barlas O. Dense Passage Retrieval for Open-Domain Question Answering , booktitle =. 2020 , url =
2020
-
[21]
arXiv preprint arXiv:2404.16130 , year =
Darren Edge and Ha Trinh and Newman Cheng and Joshua Bradley and Alex Chao and Apurva Mody and Steven Truitt and Dasha Metropolitansky and Robert Osazuwa Ness and Jonathan Larson , title =. arXiv preprint arXiv:2404.16130 , year =
-
[22]
arXiv preprint arXiv:2312.10997 , year =
Yunfan Gao and Yun Xiong and Xinyu Gao and Kangxiang Jia and Jinliu Pan and Yuxi Bi and Yi Dai and Jiawei Sun and Qianyu Guo and Meng Wang and Haofen Wang , title =. arXiv preprint arXiv:2312.10997 , year =
-
[23]
Proceedings of EMNLP , pages =
Ledell Wu and Fabio Petroni and Martin Josifoski and Sebastian Riedel and Luke Zettlemoyer , title =. Proceedings of EMNLP , pages =. 2020 , url =
2020
-
[24]
International Conference on Learning Representations (ICLR) , year =
Nicola De Cao and Gautier Izacard and Sebastian Riedel and Fabio Petroni , title =. International Conference on Learning Representations (ICLR) , year =
-
[25]
Li and Sewon Min and Srinivasan Iyer and Yashar Mehdad and Wen-tau Yih , title =
Belinda Z. Li and Sewon Min and Srinivasan Iyer and Yashar Mehdad and Wen-tau Yih , title =. Proceedings of EMNLP , pages =. 2020 , url =
2020
-
[26]
2022 , doi =
Neural Entity Linking: A Survey of Models Based on Deep Learning , journal =. 2022 , doi =
2022
-
[27]
Sun, Zequn and Zhang, Qingheng and Hu, Wei and Wang, Chengming and Chen, Muhao and Akrami, Farahnaz and Li, Chengkai , title =. Proc. VLDB Endow. , month = jul, pages =. 2020 , issue_date =. doi:10.14778/3407790.3407828 , abstract =
-
[28]
The VLDB Journal , volume =
Rui Zhang and Bayu Distiawan Trisedya and Miao Li and Yong Jiang and Jianzhong Qi , title =. The VLDB Journal , volume =. 2022 , doi =
2022
-
[29]
Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence,
Muhao Chen and Yingtao Tian and Mohan Yang and Carlo Zaniolo , title =. Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence,. 2017 , doi =
2017
-
[30]
Cross-Lingual Entity Alignment via Joint Attribute-Preserving Embedding
Sun, Zequn and Hu, Wei and Li, Chengkai. Cross-Lingual Entity Alignment via Joint Attribute-Preserving Embedding. The Semantic Web -- ISWC 2017. 2017
2017
-
[31]
Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence,
Bootstrapping Entity Alignment with Knowledge Graph Embedding , author =. Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence,. 2018 , month =. doi:10.24963/ijcai.2018/611 , url =
-
[32]
Proceedings of EMNLP , pages =
Zhichun Wang and Qingsong Lv and Xiaohan Lan and Yu Zhang , title =. Proceedings of EMNLP , pages =. 2018 , url =
2018
-
[33]
Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence,
Relation-Aware Entity Alignment for Heterogeneous Knowledge Graphs , author =. Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence,. 2019 , month =. doi:10.24963/ijcai.2019/733 , url =
-
[34]
Proceedings of AAAI , pages =
Zequn Sun and Chengming Wang and Wei Hu and Muhao Chen and Jian Dai and Wei Zhang and Yuzhong Qu , title =. Proceedings of AAAI , pages =. 2020 , doi =
2020
-
[35]
Proceedings of AAAI , pages =
Bayu Distiawan Trisedya and Jianzhong Qi and Rui Zhang , title =. Proceedings of AAAI , pages =. 2019 , doi =
2019
-
[36]
Proceedings of ACL , pages =
Yixin Cao and Zhiyuan Liu and Chengjiang Li and Zhiyuan Liu and Juanzi Li and Tat-Seng Chua , title =. Proceedings of ACL , pages =. 2019 , url =
2019
-
[37]
Proceedings of the 13th International Conference on Web Search and Data Mining , pages =
Mao, Xin and Wang, Wenting and Xu, Huimin and Lan, Man and Wu, Yuanbin , title =. Proceedings of the 13th International Conference on Web Search and Data Mining , pages =. 2020 , isbn =. doi:10.1145/3336191.3371804 , abstract =
-
[38]
Cross-lingual Knowledge Graph Alignment via Graph Matching Neural Network
Xu, Kun and Wang, Liwei and Yu, Mo and Feng, Yansong and Song, Yan and Wang, Zhiguo and Yu, Dong. Cross-lingual Knowledge Graph Alignment via Graph Matching Neural Network. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1304
-
[39]
Unlocking the Power of Large Language Models for Entity Alignment
Jiang, Xuhui and Shen, Yinghan and Shi, Zhichao and Xu, Chengjin and Li, Wei and Li, Zixuan and Guo, Jian and Shen, Huawei and Wang, Yuanzhuo. Unlocking the Power of Large Language Models for Entity Alignment. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.408
-
[40]
AutoAlign: Fully Automatic and Effective Knowledge Graph Alignment Enabled by Large Language Models , year=
Zhang, Rui and Su, Yixin and Trisedya, Bayu Distiawan and Zhao, Xiaoyan and Yang, Min and Cheng, Hong and Qi, Jianzhong , journal=. AutoAlign: Fully Automatic and Effective Knowledge Graph Alignment Enabled by Large Language Models , year=
-
[41]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages =
Xuhui Jiang and Yinghan Shen and Zhichao Shi and Chengjin Xu and Wei Li and Zihe Huang and Jian Guo and Yuanzhuo Wang , title =. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages =. 2024 , url =
2024
-
[42]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Shengyuan Chen and Qinggang Zhang and Junnan Dong and Wen Hua and Qing Li and Xiao Huang , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[43]
arXiv preprint arXiv:2305.18703 , year =
Chen Ling and Xujiang Zhao and Jiaying Lu and Chengyuan Deng and Can Zheng and Junxiang Wang and Tanmoy Chowdhury and Yun Li and Hejie Cui and Tianjiao Zhao and Amit Panalkar and Wei Cheng and Haoyu Wang and Yanchi Liu and Zhengzhang Chen and Haifeng Chen and Chris White and Quanquan Gu and Carl Yang and Liang Zhao , title =. arXiv preprint arXiv:2305.187...
-
[45]
In: Findings of the Association for Computational Linguistics: ACL 2023
Hsieh, Cheng-Yu and Li, Chun-Liang and Yeh, Chih-kuan and Nakhost, Hootan and Fujii, Yasuhisa and Ratner, Alex and Krishna, Ranjay and Lee, Chen-Yu and Pfister, Tomas. Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi...
-
[46]
Magister, Lucie Charlotte and Mallinson, Jonathan and Adamek, Jakub and Malmi, Eric and Severyn, Aliaksei. Teaching Small Language Models to Reason. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2023. doi:10.18653/v1/2023.acl-short.151
-
[47]
Large Language Models Are Reasoning Teachers
Ho, Namgyu and Schmid, Laura and Yun, Se-Young. Large Language Models Are Reasoning Teachers. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.830
-
[48]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , url =
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and ichter, brian and Xia, Fei and Chi, Ed and Le, Quoc V and Zhou, Denny , booktitle =. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , url =
-
[49]
Weinberger , title =
Chuan Guo and Geoff Pleiss and Yu Sun and Kilian Q. Weinberger , title =. Proceedings of ICML , pages =. 2017 , url =
2017
-
[50]
arXiv preprint arXiv:2207.05221 , year =
Saurav Kadavath and Tom Conerly and Amanda Askell and Tom Henighan and Dawn Drain and Ethan Perez and Nicholas Schiefer and Zac Hatfield-Dodds and Nova DasSarma and Eli Tran-Johnson and others , title =. arXiv preprint arXiv:2207.05221 , year =
-
[51]
International Conference on Learning Representations (ICLR) , year =
Miao Xiong and Zhiyuan Hu and Xinyang Lu and Yifei Li and Jie Fu and Junxian He and Bryan Hooi , title =. International Conference on Learning Representations (ICLR) , year =
-
[52]
O'Connor and Kevin McGuinness , title =
Eric Arazo and Diego Ortego and Paul Albert and Noel E. O'Connor and Kevin McGuinness , title =. Proceedings of IJCNN , year =
-
[53]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Yonatan Geifman and Ran El-Yaniv , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[54]
2009 , url =
Burr Settles , title =. 2009 , url =
2009
-
[55]
Wang and Dongjin Choi and Shenyu Xu and Diyi Yang , title =
Zijie J. Wang and Dongjin Choi and Shenyu Xu and Diyi Yang , title =. Proceedings of the First Workshop on Bridging Human--Computer Interaction and Natural Language Processing , pages =. 2021 , url =
2021
-
[56]
Translating Embeddings for Modeling Multi-relational Data , booktitle =
Antoine Bordes and Nicolas Usunier and Alberto Garc. Translating Embeddings for Modeling Multi-relational Data , booktitle =. 2013 , url =
2013
-
[57]
Proceedings of AAAI , pages =
Yankai Lin and Zhiyuan Liu and Maosong Sun and Yang Liu and Xuan Zhu , title =. Proceedings of AAAI , pages =. 2015 , doi =
2015
-
[58]
Proceedings of ACL-IJCNLP , pages =
Guoliang Ji and Shizhu He and Liheng Xu and Kang Liu and Jun Zhao , title =. Proceedings of ACL-IJCNLP , pages =. 2015 , url =
2015
-
[59]
International Conference on Learning Representations (ICLR) , year =
Zhiqing Sun and Zhi-Hong Deng and Jian-Yun Nie and Jian Tang , title =. International Conference on Learning Representations (ICLR) , year =
-
[60]
Complex Embeddings for Simple Link Prediction , booktitle =
Th. Complex Embeddings for Simple Link Prediction , booktitle =. 2016 , url =
2016
-
[61]
Learning Attention-based Embeddings for Relation Prediction in Knowledge Graphs
Nathani, Deepak and Chauhan, Jatin and Sharma, Charu and Kaul, Manohar. Learning Attention-based Embeddings for Relation Prediction in Knowledge Graphs. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1466
-
[62]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[63]
Dan Gusfield , title =. 1997
1997
-
[64]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[65]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[66]
arXiv preprint arXiv:1503.02531 , year=
Distilling the Knowledge in a Neural Network , author=. arXiv preprint arXiv:1503.02531 , year=
-
[67]
arXiv preprint arXiv:2203.14465 , year=
STaR: Bootstrapping Reasoning With Reasoning , author=. arXiv preprint arXiv:2203.14465 , year=
-
[68]
Wang, Peifeng and Wang, Zhengyang and Li, Zheng and Gao, Yifan and Yin, Bing and Ren, Xiang. SCOTT : Self-Consistent Chain-of-Thought Distillation. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.304
-
[69]
arXiv preprint arXiv:2312.02179 , year=
Training Chain-of-Thought via Latent-Variable Inference , author=. arXiv preprint arXiv:2312.02179 , year=
-
[70]
Findings of the Association for Computational Linguistics: NAACL 2022 , pages=
Few-Shot Self-Rationalization with Natural Language Prompts , author=. Findings of the Association for Computational Linguistics: NAACL 2022 , pages=. 2022 , publisher=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.