How Much Capacity Does EEG Denoising Need? Ultra-Compact Networks reveal Benchmark Saturation and Metric-Utility Gap
Pith reviewed 2026-06-27 18:55 UTC · model grok-4.3
The pith
EEG denoising reconstruction saturates at 3-6.5K parameters and can degrade BCI classification accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
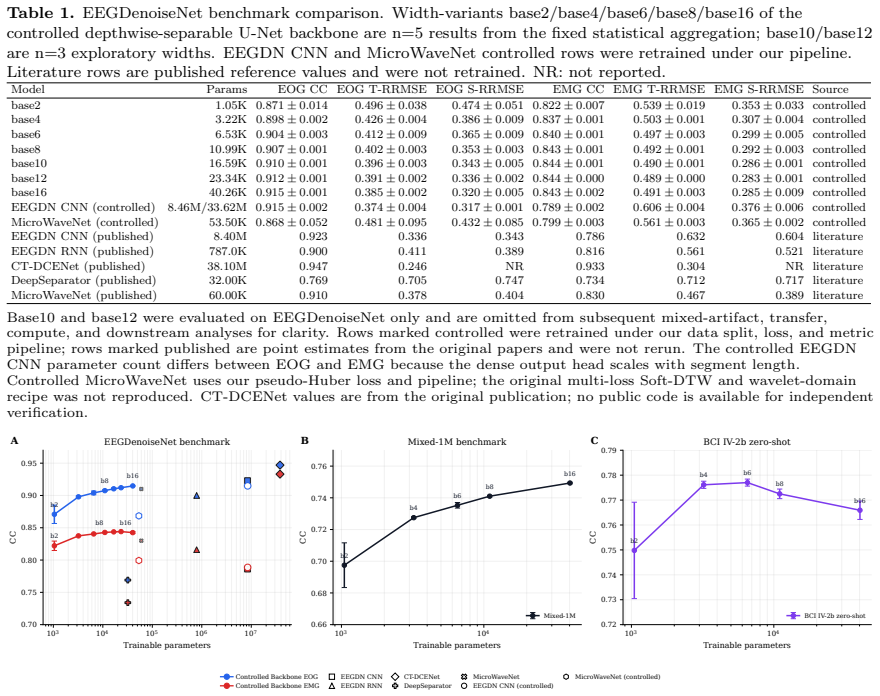
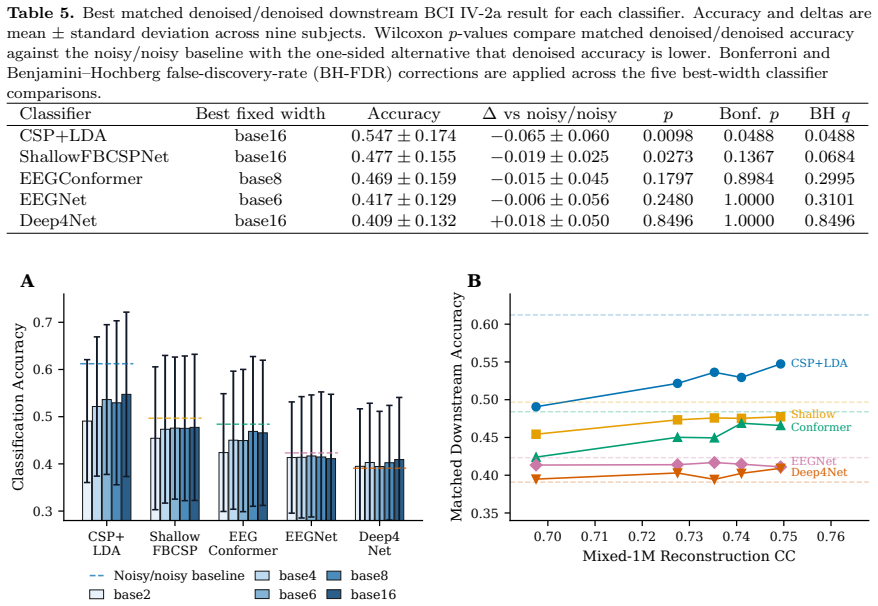
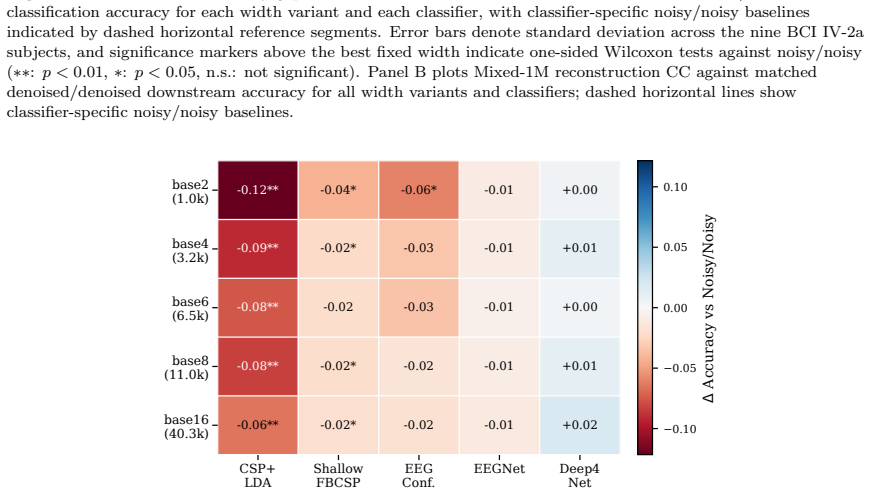
By holding architecture, loss, data split, and training fixed and sweeping only channel width in a minimal depthwise-separable convolutional U-Net, reconstruction performance on EEGDenoiseNet saturates by 3-6.5K parameters with post-elbow gains of at most 0.015 correlation coefficient per log10-parameter unit. An 8.46M-parameter baseline retrained identically matches the 40.26K model, while reconstruction-optimized denoising lowers CSP+LDA accuracy to 0.547 versus the 0.612 noisy baseline across all nine subjects and three artifact types.
What carries the argument
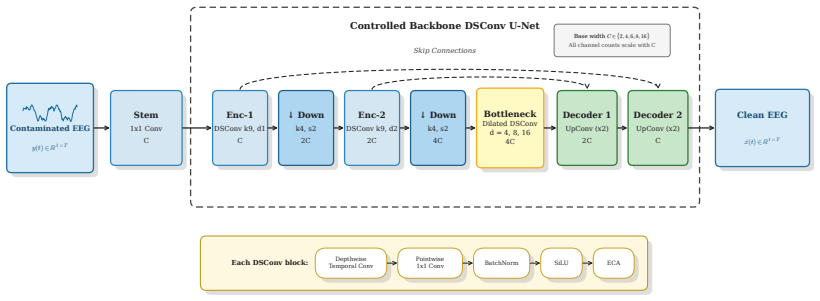
Capacity sweep of channel width in a fixed depthwise-separable convolutional U-Net evaluated on both reconstruction metrics and downstream motor-imagery classification.
If this is right
- Standard EEG denoising benchmarks are saturated far below current model capacity.
- Reconstruction metrics do not predict utility for BCI classification tasks.
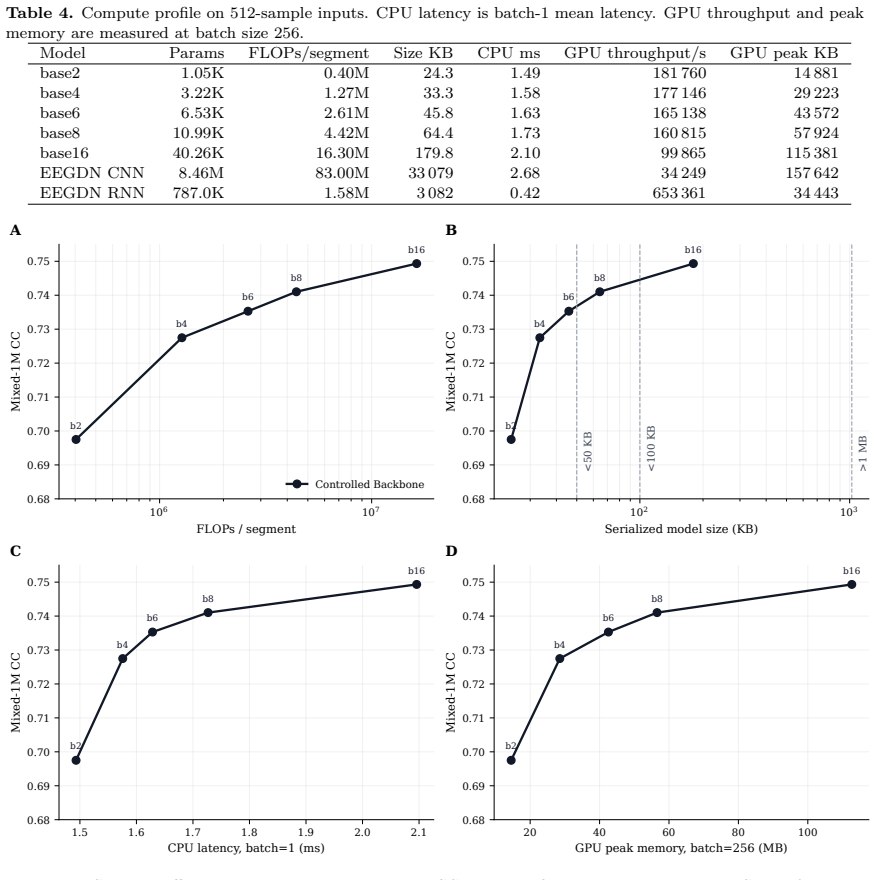
- Ultra-compact models at 33-46 KB and 1.27-2.61M FLOPs per segment suffice for edge deployment.
- Downstream validation with task-specific decoders is required beyond reconstruction quality alone.
- Capacity-controlled evaluation and harder task-aware benchmarks should replace uncontrolled scaling studies.
Where Pith is reading between the lines
- The observed early saturation may extend to denoising of other biosignals such as ECG or EMG under similar controlled sweeps.
- Training denoisers end-to-end with the downstream classifier objective could reduce or eliminate the observed metric-utility gap.
- Compact models may exhibit better cross-subject generalization than overparameterized ones in BCI transfer settings.
- Future work should test whether the same capacity elbow appears when the loss is replaced by a task-specific objective.
Load-bearing premise
The chosen depthwise-separable convolutional U-Net architecture together with the EEGDenoiseNet and BCI IV-2a datasets are representative for determining general capacity needs in EEG denoising.
What would settle it
Retraining models larger than 40K parameters under the identical fixed pipeline and observing correlation coefficients more than 0.015 above the elbow or CSP+LDA accuracies above the 0.612 noisy baseline would falsify the saturation and metric-utility gap claims.
Figures
read the original abstract
Deep learning EEG denoising architectures have scaled from tens of thousands to tens of millions of parameters, yet no prior study has isolated model capacity as the experimental variable or tested whether reconstruction metrics predict downstream neural-signal utility. We address both gaps by fixing architecture, loss, data split, and training recipe while sweeping only channel width from 1.05K to 40.26K parameters in a minimal depthwise-separable convolutional U-Net. Models were evaluated on the EEGDenoiseNet benchmark, cross-dataset BCI transfer tests, controlled baseline retraining, and downstream motor-imagery classification with five decoder families across all nine BCI Competition IV-2a subjects. Reconstruction performance saturated by 3-6.5K parameters, with post-elbow gains of at most 0.015 correlation coefficient per log10-parameter unit. An 8.46M-parameter baseline retrained under the same pipeline matched the 40.26K compact variant on EOG--a 200x parameter gap yielding no advantage--while a Patch-Transformer control reproduced the same diminishing-return shape. Downstream evaluation exposed a classifier-dependent metric-utility gap: reconstruction-optimized denoising significantly degraded CSP+LDA classification across all nine subjects and three artifact types (best denoised accuracy 0.547 vs. 0.612 noisy baseline; Bonferroni p=0.0488), persisting on naturally recorded trials (Delta=-0.047; BH-FDR q=0.0049). End-to-end neural decoders showed variable or neutral effects. Standard EEG denoising benchmarks are saturated far below current model capacity, and reconstruction metrics do not predict BCI utility. Ultra-compact models at 33-46 KB and 1.27-2.61M FLOPs/segment are practical for edge deployment. These findings argue for capacity-controlled evaluation, harder task-aware benchmarks, and mandatory downstream validation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that EEG denoising performance saturates at low model capacities (by 3-6.5K parameters) in a controlled sweep of a depthwise-separable convolutional U-Net on EEGDenoiseNet, with post-elbow gains ≤0.015 CC per log10-parameter unit; an 8.46M-parameter baseline matches the 40.26K model; reconstruction optimization degrades CSP+LDA classification (0.547 vs. 0.612 noisy baseline, Bonferroni p=0.0488) while effects are variable for other decoders; and therefore standard benchmarks are saturated far below current capacities and reconstruction metrics do not predict BCI utility. Experiments include cross-dataset transfer, baseline retraining, multiple decoder families, and a Patch-Transformer control.
Significance. If the results hold within their scope, the work provides quantitative evidence for benchmark saturation and a metric-utility gap, supporting calls for capacity-controlled evaluation, harder task-aware benchmarks, and mandatory downstream validation. The ultra-compact models (33-46 KB, 1.27-2.61M FLOPs) and controlled design with statistical corrections are practical strengths.
major comments (2)
- [Experimental setup and abstract] The headline claims that 'standard EEG denoising benchmarks are saturated far below current model capacity' and that 'reconstruction metrics do not predict BCI utility' are demonstrated only within the depthwise-separable convolutional U-Net family (plus one Patch-Transformer control) on EEGDenoiseNet and BCI IV-2a. Other common backbones (standard 1D-CNN U-Net, LSTM, full transformer) are not evaluated, so the saturation point and metric-utility relationship may not transfer; this is load-bearing for the broad conclusions in the abstract and discussion.
- [Downstream evaluation section] Table or figure reporting the CSP+LDA results (0.547 vs. 0.612): while the Bonferroni-corrected p=0.0488 is given and the effect is stated to hold across all nine subjects, per-subject variance or Cohen's d effect sizes are not provided, making it difficult to judge whether the degradation is uniform or driven by outliers.
minor comments (2)
- [Abstract] The abstract states 'five decoder families' without naming them; listing the families (e.g., CSP+LDA, end-to-end neural decoders) would improve immediate clarity.
- [Methods] The capacity sweep is described only by total parameter counts (1.05K to 40.26K); an equation or table relating channel width multiplier to parameter count would make the experimental variable fully reproducible.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope and presentation of our results. We respond to each major comment below and indicate revisions where they strengthen the manuscript without misrepresenting the controlled experimental design.
read point-by-point responses
-
Referee: [Experimental setup and abstract] The headline claims that 'standard EEG denoising benchmarks are saturated far below current model capacity' and that 'reconstruction metrics do not predict BCI utility' are demonstrated only within the depthwise-separable convolutional U-Net family (plus one Patch-Transformer control) on EEGDenoiseNet and BCI IV-2a. Other common backbones (standard 1D-CNN U-Net, LSTM, full transformer) are not evaluated, so the saturation point and metric-utility relationship may not transfer; this is load-bearing for the broad conclusions in the abstract and discussion.
Authors: The depthwise-separable convolutional U-Net was deliberately chosen to enable a fine-grained, topology-fixed sweep of capacity (channel width) while keeping all other factors constant, which is the central methodological contribution. The Patch-Transformer control was included specifically to probe whether the observed saturation shape and diminishing returns generalize beyond convolutional designs. We acknowledge that the claims are scoped to these architectures and datasets. We will revise the abstract and discussion to explicitly qualify the saturation and metric-utility findings as demonstrated for the tested families, while noting that extension to standard 1D-CNN U-Nets, LSTMs, and full transformers is an important direction for future work. This is a partial revision that preserves the paper's focus on controlled capacity isolation. revision: partial
-
Referee: [Downstream evaluation section] Table or figure reporting the CSP+LDA results (0.547 vs. 0.612): while the Bonferroni-corrected p=0.0488 is given and the effect is stated to hold across all nine subjects, per-subject variance or Cohen's d effect sizes are not provided, making it difficult to judge whether the degradation is uniform or driven by outliers.
Authors: We will add per-subject accuracies, standard deviations across the nine BCI IV-2a subjects, and Cohen's d effect sizes for the CSP+LDA comparison to the main table or a new supplementary figure. This will make the uniformity (or lack thereof) of the degradation transparent. The revision will be incorporated in the next manuscript version. revision: yes
Circularity Check
No circularity: claims rest on direct experimental sweeps and statistical tests
full rationale
The paper performs controlled capacity sweeps inside one fixed depthwise-separable U-Net (plus one Patch-Transformer control) on EEGDenoiseNet and BCI IV-2a, reporting measured reconstruction curves, downstream classifier accuracies, and statistical comparisons. No equations, fitted parameters renamed as predictions, self-citations used as uniqueness theorems, or ansatzes are invoked to derive the saturation or metric-utility conclusions; those conclusions are the measured outcomes themselves. The representativeness of the chosen backbone and corpora is a scope limitation, not a circular reduction. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The EEGDenoiseNet benchmark and BCI Competition IV-2a dataset are representative of typical EEG artifact conditions and downstream task utility.
Reference graph
Works this paper leans on
-
[1]
Zhang H, Zhao M, Wei C, Mantini D, Li Z and Liu Q 2021Journal of Neural Engineering18 056057
-
[2]
Chuang C H, Chang K Y, Huang C S and Jung T P 2022NeuroImage263119586
-
[3]
Dong Y, Tang X, Li Q, Wang Y, Jiang N, Tian L, Zheng Y, Li X, Zhao S, Li G and Fang P 2023IEEE Transactions on Neural Systems and Rehabilitation Engineering313524–3534
-
[4]
Tang Y, Huang W, Chen C and Chen D 2025IEEE Journal of Biomedical and Health Informatics294095–4108
-
[5]
Chen W, Li Y, Zheng N and Shi W 2025IEEE Journal of Biomedical and Health Informatics 296551–6564
-
[6]
Croft R J and Barry R J 2000Neurophysiologie Clinique/Clinical Neurophysiology305–19
-
[7]
Urig¨ uen J A and Garcia-Zapirain B 2015Journal of Neural Engineering12031001
-
[8]
Gratton G, Coles M G H and Donchin E 1983Electroencephalography and Clinical Neurophysiology55468–484
-
[9]
Makeig S, Bell A J, Jung T P and Sejnowski T J 1996 Independent component analysis of electroencephalographic dataAdvances in Neural Information Processing Systemsvol 8 pp 145–151
1996
-
[10]
Jung T P, Makeig S, Humphries C, Lee T W, McKeown M J, Iragui V and Sejnowski T J 2000 Psychophysiology37163–178 15
2000
-
[11]
Mullen T R, Kothe C A E, Chi Y M, Ojeda A, Kerth T, Makeig S, Jung T P and Cauwenberghs G 2015IEEE Transactions on Biomedical Engineering622553–2567
-
[12]
Chang C Y, Hsu S H, Pion-Tonachini L and Jung T P 2020IEEE Transactions on Biomedical Engineering671114–1121
-
[13]
Nolan H, Whelan R and Reilly R B 2010Journal of Neuroscience Methods192152–162
-
[14]
Mognon A, Jovicich J, Bruzzone L and Buiatti M 2011Psychophysiology48229–240
-
[15]
Roy Y, Banville H, Albuquerque I, Gramfort A, Falk T H and Faubert J 2019Journal of Neural Engineering16051001
-
[16]
Yue X, Lu L, Liu H and Zang Y 2025CNS Neuroscience & Therapeutics31e70632
-
[17]
Gao T, Chen D, Tang Y, Ming Z and Li X 2023IEEE Journal of Biomedical and Health Informatics271283–1294
-
[18]
Yin J, Liu A, Li C, Qian R and Chen X 2025IEEE Journal of Biomedical and Health Informatics293930–3941
-
[19]
Chen J, Pi D, Jiang X, Xu Y, Chen Y and Wang X 2024IEEE Transactions on Instrumentation and Measurement731–16
-
[20]
Yu J, Li C, Lou K, Wei C and Liu Q 2022Journal of Neural Engineering19026052
-
[21]
Lahiri J B, Kulkarni A and Panwar S 2025 MicroWaveNet: Lightweight CBAM-augmented wavelet-attentive networks for robust EEG denoising2025 IEEE 35th International Workshop on Machine Learning for Signal Processing (MLSP)pp 1–6
2025
-
[22]
Huang J, Wang C, Zhao W, Grau A, Xue X and Zhang F 2024IEEE Transactions on Consumer Electronics705561–5575
-
[23]
Lawhern V J, Solon A J, Waytowich N R, Gordon S M, Hung C P and Lance B J 2018 Journal of Neural Engineering15056013
2018
-
[24]
Chollet F 2017 Xception: Deep learning with depthwise separable convolutionsProceedings of the IEEE Conference on Computer Vision and Pattern Recognitionpp 1251–1258
2017
-
[25]
Howard A G, Zhu M, Chen B, Kalenichenko D, Wang W, Weyand T, Andreetto M and Adam H 2017arXiv preprint arXiv:1704.04861(Preprint1704.04861)
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Wang Q, Wu B, Zhu P, Li P, Zuo W and Hu Q 2020 ECA-Net: Efficient channel attention for deep convolutional neural networksProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognitionpp 11531–11539
2020
-
[27]
Han S, Mao H and Dally W J 2016 Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman codingInternational Conference on Learning Representations
2016
-
[28]
Bigdely-Shamlo N, Mullen T, Kothe C, Su K M and Robbins K A 2015Frontiers in Neuroinformatics916
-
[29]
Nagar S, Kumar A and Swamy M N S 2021Signal Processing188108225
-
[30]
Kaplan J, McCandlish S, Henighan T, Brown T B, Chess B, Child R, Gray S, Radford A, Wu J and Amodei D 2020arXiv preprint arXiv:2001.08361(Preprint2001.08361)
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[31]
Frankle J and Carbin M 2019 The lottery ticket hypothesis: Finding sparse, trainable neural networksInternational Conference on Learning Representations
2019
-
[32]
Delorme A and Makeig S 2004Journal of Neuroscience Methods1349–21
-
[33]
Obeid I and Picone J 2016Frontiers in Neuroscience10196
-
[34]
Tangermann M, M¨ uller K R, Aertsen A, Birbaumer N, Braun C, Brunner C, Leeb R, Mehring C, Miller K J, M¨ uller-Putz G R, Nolte G, Pfurtscheller G, Preissl H, Schalk G, Schl¨ ogl A, Vidaurre C, Waldert S and Blankertz B 2012Frontiers in Neuroscience655 16
-
[35]
Charbonnier P, Blanc-F´ eraud L, Aubert G and Barlaud M 1994 Two deterministic half-quadratic regularization algorithms for computed imagingProceedings of the IEEE International Conference on Image Processingvol 2 pp 168–172
1994
-
[36]
Pfurtscheller G and Neuper C 2001Proceedings of the IEEE891123–1134
-
[37]
Ramoser H, M¨ uller-Gerking J and Pfurtscheller G 2000IEEE Transactions on Rehabilitation Engineering8441–446
-
[38]
Blankertz B, Tomioka R, Lemm S, Kawanabe M and M¨ uller K R 2008IEEE Signal Processing Magazine2541–56
-
[39]
Lotte F, Bougrain L, Cichocki A, Clerc M, Congedo M, Rakotomamonjy A and Yger F 2018 Journal of Neural Engineering15031005
2018
-
[40]
Parra L C, Spence C D, Gerson A D and Sajda P 2005NeuroImage28326–341
-
[41]
Haufe S, Meinecke F, G¨ orgen K, D¨ ahne S, Haynes J D, Blankertz B and Bießmann F 2014 NeuroImage8796–110
2014
-
[42]
Schirrmeister R T, Springenberg J T, Fiederer L D J, Glasstetter M, Eggensperger K, Tangermann M, Hutter F, Burgard W and Ball T 2017Human Brain Mapping385391–5420
-
[43]
Song Y, Zheng Q, Liu B and Gao X 2023IEEE Transactions on Neural Systems and Rehabilitation Engineering31710–719
- [44]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.