Vision-Language Guided Hyperspectral Object Tracking via Semantics Fusion and Contextual Template Updating
Pith reviewed 2026-06-27 16:58 UTC · model grok-4.3
The pith
VLHTrack uses LLM descriptions to select useful spectral bands and dynamically update templates for hyperspectral tracking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
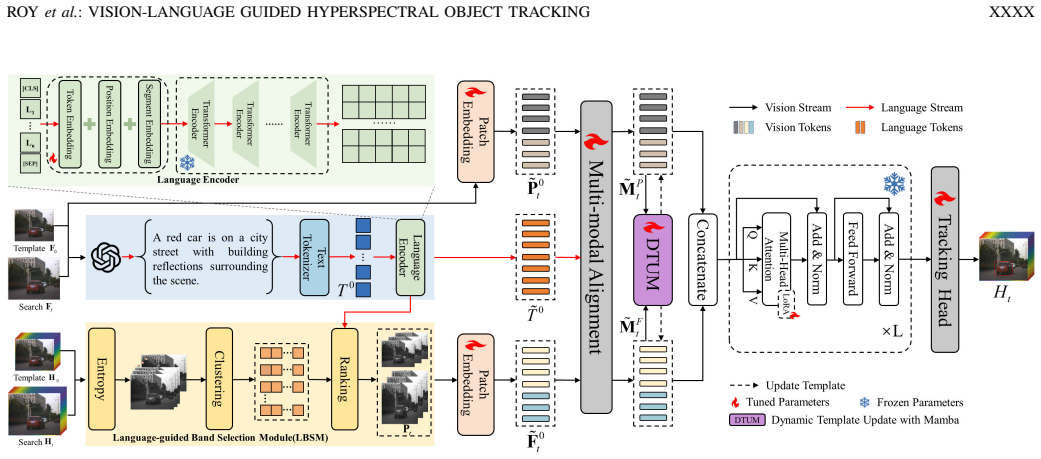
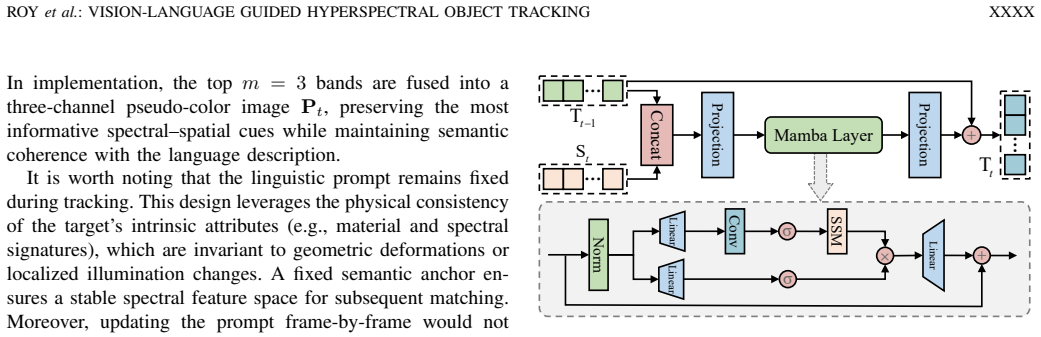
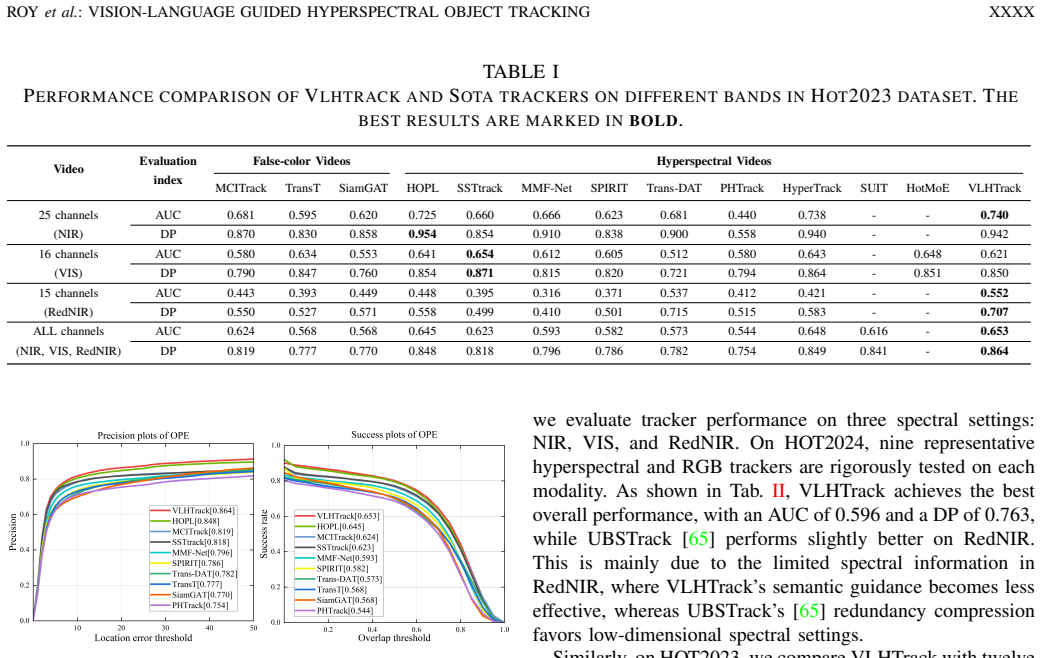
VLHTrack establishes a semantic-to-spectral mapping in the Language-Guided Band Selection Module that uses LLM-generated object descriptions to accentuate discriminative bands, integrates visual and linguistic embeddings through a Multi-Modal Vision-Language Fusion Module, and applies selective state-space modeling in the Dynamic Template Update with Mamba module to evolve template features according to temporal context, yielding higher tracking accuracy than existing approaches on HOT2023 and HOT2024.
What carries the argument
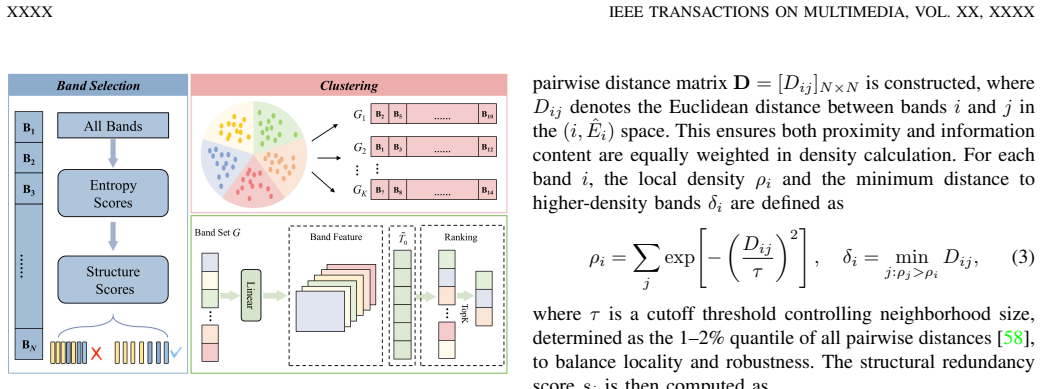
Language-Guided Band Selection Module that creates a semantic-to-spectral mapping from LLM descriptions to reduce spectral redundancy.
If this is right
- Spectral redundancy is reduced so that models generalize better across hyperspectral videos.
- Cross-modal representations become coherent enough to improve robustness under occlusion and illumination change.
- Template features evolve efficiently across long sequences without explicit deformation modeling.
- Performance gains appear on both HOT2023 and HOT2024 benchmarks relative to prior trackers.
Where Pith is reading between the lines
- The same language-to-band mapping idea could be tested on other spectral imaging tasks such as material classification.
- Replacing the Mamba component with a different temporal model would isolate how much the state-space update itself contributes.
- If the LLM descriptions contain systematic biases for certain object classes, tracking accuracy on those classes would degrade first.
Load-bearing premise
Large language model descriptions of objects can be mapped reliably onto the spectral bands that best distinguish the target without selection errors or dataset bias.
What would settle it
A controlled test in which the band-selection module is replaced by random or full-band input and tracking accuracy on HOT2023 or HOT2024 either stays the same or drops.
Figures


read the original abstract
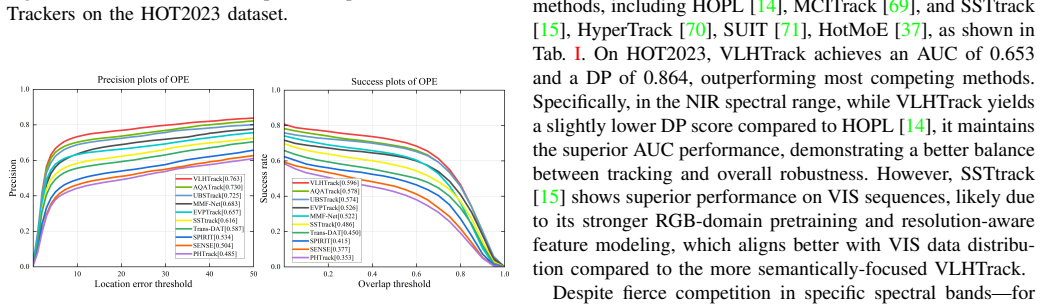
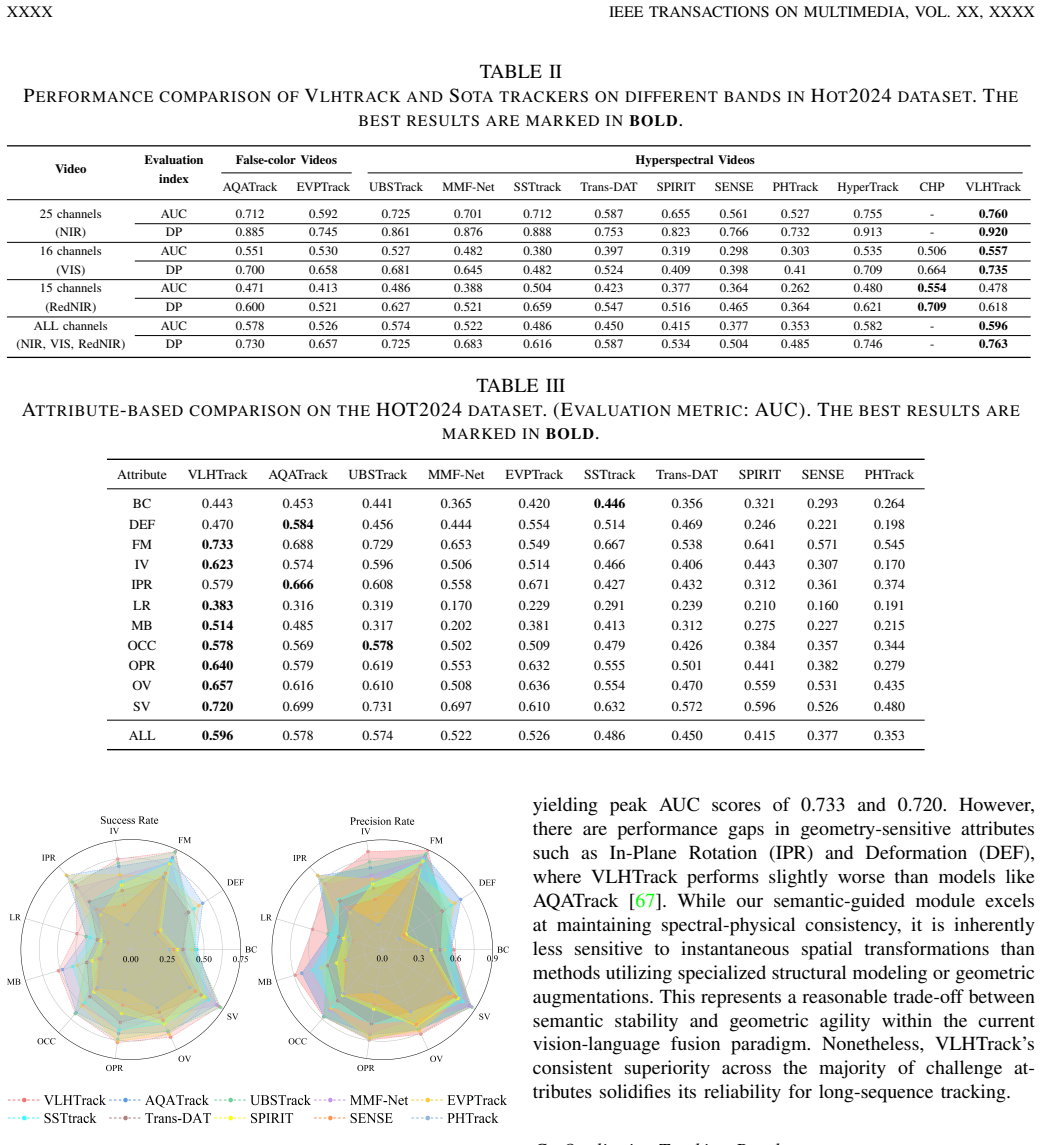
Hyperspectral object tracking (HOT) leverages the rich spectral information provided by hyperspectral videos (HSVs), offering substantial potential for object tracking. However, efficiently extracting and exploiting spectral information from redundant spectral bands remains a fundamental challenge, which severely limits model generalization and tracking performance. Moreover, in dynamic scenes, targets often experience drastic appearance variations due to factors such as occlusion and illumination changes. These variations lead to large deformations between the current frame and the template. Such discrepancies pose major challenges for existing temporal modeling approaches. In this work, we propose VLHTrack, a novel hyperspectral vision-language (VL) joint tracking framework. Specifically, we incorporate language priors to address the fundamental challenge of spectral redundancy by designing a Language-Guided Band Selection Module (LBSM). By leveraging Large Language Model (LLM) descriptions, LBSM establishes a semantic-to-spectral mapping that mitigates redundancy and accentuates discriminative spectral features. A Multi-Modal Vision-Language Fusion Module is then employed to seamlessly integrate visual and linguistic embeddings, harnessing their complementary advantages to learn coherent cross-modal representations. To address target deformation in long-term sequences, we propose a dynamic update template feature strategy implemented via the Dynamic Template Update with Mamba (DTUM) module. By leveraging selective state space modeling, DTUM learns inter-frame dependencies to update template feature, ensuring efficient template feature evolution guided by temporal context. Experiments on HOT2023 and HOT2024 demonstrate that VLHTrack outperforms state-of-the-art (SOTA) methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VLHTrack, a novel hyperspectral vision-language joint tracking framework. It introduces the Language-Guided Band Selection Module (LBSM) that leverages LLM descriptions to establish semantic-to-spectral mappings for mitigating spectral redundancy, a Multi-Modal Vision-Language Fusion Module for integrating visual and linguistic embeddings, and the Dynamic Template Update with Mamba (DTUM) module for updating template features using selective state space modeling to handle target deformations. The central claim is that VLHTrack outperforms state-of-the-art methods on the HOT2023 and HOT2024 datasets.
Significance. If the empirical results hold, this work would be significant for advancing hyperspectral object tracking by demonstrating how language priors from LLMs can guide band selection to reduce redundancy and how Mamba-based modeling can address long-term template updates. The approach combines timely elements from vision-language models and state space models in a domain where spectral information is underutilized.
major comments (1)
- [Abstract] Abstract: The assertion that 'Experiments on HOT2023 and HOT2024 demonstrate that VLHTrack outperforms state-of-the-art (SOTA) methods' is not supported by any quantitative scores, success/precision plots, ablation tables, or implementation details. This absence makes it impossible to verify the central claim or assess the contribution of the LBSM, fusion module, or DTUM.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'Experiments on HOT2023 and HOT2024 demonstrate that VLHTrack outperforms state-of-the-art (SOTA) methods' is not supported by any quantitative scores, success/precision plots, ablation tables, or implementation details. This absence makes it impossible to verify the central claim or assess the contribution of the LBSM, fusion module, or DTUM.
Authors: We agree that the abstract would be strengthened by including key quantitative results to directly support the performance claim. The full manuscript contains the requested elements (success/precision plots, ablation tables, and implementation details) in the Experiments section. To address this point, we will revise the abstract to incorporate representative metrics, such as success rate and precision scores on HOT2023 and HOT2024 along with the margin of improvement over prior SOTA methods. revision: yes
Circularity Check
No circularity: empirical architecture evaluated on public benchmarks
full rationale
The paper proposes VLHTrack as an empirical framework consisting of LBSM (using LLM descriptions for band selection), multi-modal fusion, and DTUM (Mamba-based template update). No equations, derivations, or predictions are presented that reduce to fitted parameters or self-definitions by construction. Central claims rest on experimental outperformance on HOT2023/HOT2024, which are external public benchmarks. No self-citation chains or uniqueness theorems are invoked as load-bearing in the provided text. This is a standard architecture proposal with independent empirical content.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network hyperparameters and learned weights
axioms (2)
- domain assumption LLM descriptions provide accurate and unbiased semantic information usable for spectral band selection
- domain assumption Mamba selective state-space modeling can capture useful inter-frame dependencies for template evolution
Reference graph
Works this paper leans on
-
[1]
Siamese local and global networks for robust face tracking,
Y . Qi, S. Zhang, F. Jiang, H. Zhou, D. Tao, and X. Li, “Siamese local and global networks for robust face tracking,”IEEE Transactions on Image Processing, vol. 29, pp. 9152–9164, 2020
2020
-
[2]
Multi- modality sensing and data fusion for multi-vehicle detection,
D. Roy, Y . Li, T. Jian, P. Tian, K. Chowdhury, and S. Ioannidis, “Multi- modality sensing and data fusion for multi-vehicle detection,”IEEE Transactions on Multimedia, vol. 25, pp. 2280–2295, 2023
2023
-
[3]
Adversarial geometric attacks for 3d point cloud object tracking,
R. Yao, A. Zhang, Y . Zhou, J. Zhao, B. Liu, and A. El Saddik, “Adversarial geometric attacks for 3d point cloud object tracking,”IEEE Transactions on Multimedia, 2025
2025
-
[4]
Deep learning for 3d point clouds: A survey,
Y . Guo, H. Wang, Q. Hu, H. Liu, L. Liu, and M. Bennamoun, “Deep learning for 3d point clouds: A survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 12, pp. 4338–4364, 2021
2021
-
[5]
Visual tracking: An experimental survey,
A. W. M. Smeulders, D. M. Chu, R. Cucchiara, S. Calderara, A. De- hghan, and M. Shah, “Visual tracking: An experimental survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 36, no. 7, pp. 1442–1468, 2014
2014
-
[6]
Deep feature-based hyperspectral object tracking: An experimental survey and outlook,
Y . Wang, X. Li, X. Yang, F. Ge, B. Wei, L. Li, and S. Yue, “Deep feature-based hyperspectral object tracking: An experimental survey and outlook,”Remote Sensing, vol. 17, no. 4, p. 645, 2025
2025
-
[7]
Ssf-net: Spatial-spectral fusion network with spectral angle awareness for hyperspectral object tracking,
H. Wang, W. Li, X.-G. Xia, Q. Du, and J. Tian, “Ssf-net: Spatial-spectral fusion network with spectral angle awareness for hyperspectral object tracking,”IEEE Transactions on Image Processing, 2025
2025
-
[8]
Tracking via object reflectance using a hyperspectral video camera,
H. V . Nguyen, A. Banerjee, and R. Chellappa, “Tracking via object reflectance using a hyperspectral video camera,” in2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition - Workshops, 2010, pp. 44–51
2010
-
[9]
Machine learning based hy- perspectral image analysis: a survey,
U. B. Gewali, S. T. Monteiro, and E. Saber, “Machine learning based hy- perspectral image analysis: a survey,”arXiv preprint arXiv:1802.08701, 2018
Pith/arXiv arXiv 2018
-
[10]
High-speed tracking with kernelized correlation filters,
J. F. Henriques, R. Caseiro, P. Martins, and J. Batista, “High-speed tracking with kernelized correlation filters,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 37, no. 3, pp. 583–596, 2015
2015
-
[11]
Spatial–spectral weighted and regularized tensor sparse correlation filter for object tracking in hyper- spectral videos,
Z. Hou, W. Li, J. Zhou, and R. Tao, “Spatial–spectral weighted and regularized tensor sparse correlation filter for object tracking in hyper- spectral videos,”IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–12, 2022
2022
-
[12]
Material based object tracking in hyperspectral videos,
F. Xiong, J. Zhou, and Y . Qian, “Material based object tracking in hyperspectral videos,”IEEE Transactions on Image Processing, vol. 29, pp. 3719–3733, 2020
2020
-
[13]
Hyper- spectral object tracking with dual-stream prompt,
R. Yao, L. Zhang, Y . Zhou, H. Zhu, J. Zhao, and Z. Shao, “Hyper- spectral object tracking with dual-stream prompt,”IEEE Transactions on Geoscience and Remote Sensing, vol. 63, pp. 1–12, 2025
2025
-
[14]
Historical object-aware prompt learning for universal hyperspectral object tracking,
L. Zhang, R. Yao, Y . Zhang, Y . Zhou, F. Hu, J. Zhao, and Z. Shao, “Historical object-aware prompt learning for universal hyperspectral object tracking,”ACM Transactions on Multimedia Computing, Com- munications and Applications, 2025
2025
-
[15]
Ssttrack: A unified hyperspectral video tracking framework via modeling spectral-spatial-temporal conditions,
Y . Chen, Q. Yuan, Y . Tang, Y . Xiao, J. He, T. Han, Z. Liu, and L. Zhang, “Ssttrack: A unified hyperspectral video tracking framework via modeling spectral-spatial-temporal conditions,”Information Fusion, vol. 114, p. 102658, 2025
2025
-
[16]
Learning a deep ensemble network with band importance for hyperspectral object tracking,
Z. Li, F. Xiong, J. Zhou, J. Lu, and Y . Qian, “Learning a deep ensemble network with band importance for hyperspectral object tracking,”IEEE Transactions on Image Processing, vol. 32, pp. 2901–2914, 2023
2023
-
[17]
Material- guided multiview fusion network for hyperspectral object tracking,
Z. Li, F. Xiong, J. Zhou, J. Lu, Z. Zhao, and Y . Qian, “Material- guided multiview fusion network for hyperspectral object tracking,” IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–15, 2024
2024
-
[18]
Siambag: Band attention grouping- based siamese object tracking network for hyperspectral videos,
W. Li, Z. Hou, J. Zhou, and R. Tao, “Siambag: Band attention grouping- based siamese object tracking network for hyperspectral videos,”IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–12, 2023. 12 XXXX IEEE TRANSACTIONS ON MULTIMEDIA, VOL. XX, XXXX
2023
-
[19]
Language-guided dual-modal local correspondence for single object tracking,
J. Yu, Z. Cai, Y . Li, L. Wang, F. Gao, and Y . Yu, “Language-guided dual-modal local correspondence for single object tracking,”IEEE Transactions on Multimedia, vol. 26, pp. 10 637–10 650, 2024
2024
-
[20]
One-stream vision-language memory network for object tracking,
H. Zhang, J. Wang, J. Zhang, T. Zhang, and B. Zhong, “One-stream vision-language memory network for object tracking,”IEEE Transac- tions on Multimedia, vol. 26, pp. 1720–1730, 2024
2024
-
[21]
Divert more attention to vision- language tracking,
M. Guo, Z. Zhang, H. Fan, and L. Jing, “Divert more attention to vision- language tracking,”Advances in Neural Information Processing Systems, vol. 35, pp. 4446–4460, 2022
2022
-
[22]
Siamese natural language tracker: Tracking by natural language descriptions with siamese track- ers,
Q. Feng, V . Ablavsky, Q. Bai, and S. Sclaroff, “Siamese natural language tracker: Tracking by natural language descriptions with siamese track- ers,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 5851–5860
2021
-
[23]
Hyperspectral object tracking with context-aware learning and category consistency,
Y . Wang, S. Mei, M. Ma, Y . Liu, T. Gao, and H. Han, “Hyperspectral object tracking with context-aware learning and category consistency,” IEEE Transactions on Geoscience and Remote Sensing, 2025
2025
-
[24]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[25]
Hyperspectral mamba for hyperspectral object tracking,
L. Gao, Y . Zhang, Y . Jiang, W. Xie, and Y . Li, “Hyperspectral mamba for hyperspectral object tracking,” 2025. [Online]. Available: https://arxiv.org/abs/2509.08265
arXiv 2025
-
[26]
Improving visual object tracking through visual prompting,
S.-F. Chen, J.-C. Chen, I.-H. Jhuo, and Y .-Y . Lin, “Improving visual object tracking through visual prompting,”IEEE Transactions on Mul- timedia, 2025
2025
-
[27]
Spirit: Spectral awareness interaction network with dynamic template for hyperspectral object tracking,
Y . Chen, Q. Yuan, Y . Tang, Y . Xiao, J. He, and L. Zhang, “Spirit: Spectral awareness interaction network with dynamic template for hyperspectral object tracking,”IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–16, 2024
2024
-
[28]
Object tracking in hyperspectral videos with convolutional features and kernelized correla- tion filter,
K. Qian, J. Zhou, F. Xiong, H. Zhou, and J. Du, “Object tracking in hyperspectral videos with convolutional features and kernelized correla- tion filter,” inInternational conference on smart multimedia. Springer, 2018, pp. 308–319
2018
-
[29]
Siamhyper: Learning a hyperspectral object tracker from an rgb-based tracker,
Z. Liu, X. Wang, Y . Zhong, M. Shu, and C. Sun, “Siamhyper: Learning a hyperspectral object tracker from an rgb-based tracker,”IEEE Trans- actions on Image Processing, vol. 31, pp. 7116–7129, 2022
2022
-
[30]
Bae-net: A band attention aware ensemble network for hyperspectral object tracking,
Z. Li, F. Xiong, J. Zhou, J. Wang, J. Lu, and Y . Qian, “Bae-net: A band attention aware ensemble network for hyperspectral object tracking,” in 2020 IEEE International Conference on Image Processing (ICIP), 2020, pp. 2106–2110
2020
-
[31]
Hy-tracker: A novel framework for enhancing efficiency and accuracy of object tracking in hyperspectral videos,
M. A. Islam, W. Xing, J. Zhou, Y . Gao, and K. K. Paliwal, “Hy-tracker: A novel framework for enhancing efficiency and accuracy of object tracking in hyperspectral videos,”IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–14, 2024
2024
-
[32]
Tmtnet: A transformer-based multimodality information transfer network for hyperspectral object tracking,
C. Zhao, H. Liu, N. Su, C. Xu, Y . Yan, and S. Feng, “Tmtnet: A transformer-based multimodality information transfer network for hyperspectral object tracking,”Remote Sensing, vol. 15, no. 4, p. 1107, 2023
2023
-
[33]
Tftn: A transformer-based fusion tracking framework of hyperspectral and rgb,
C. Zhao, H. Liu, N. Su, and Y . Yan, “Tftn: A transformer-based fusion tracking framework of hyperspectral and rgb,”IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–15, 2022
2022
-
[34]
Htacpe: A hybrid transformer with adaptive content and position embedding for sample learning efficiency of hyperspectral tracker,
Y . Wang, S. Mei, M. Ma, Y . Liu, and Y . Su, “Htacpe: A hybrid transformer with adaptive content and position embedding for sample learning efficiency of hyperspectral tracker,”IEEE Transactions on Multimedia, vol. 27, pp. 2384–2398, 2025
2025
-
[35]
Profit: A prompt-guided frequency-aware filtering and template- enhanced interaction framework for hyperspectral video tracking,
Y . Chen, Q. Yuan, Y . Tang, X. Wang, Y . Xiao, J. He, Z. Lihe, and X. Jin, “Profit: A prompt-guided frequency-aware filtering and template- enhanced interaction framework for hyperspectral video tracking,”IS- PRS Journal of Photogrammetry and Remote Sensing, vol. 226, pp. 164– 186, 2025
2025
-
[36]
Siamohot: A lightweight dual siamese network for onboard hyperspectral object tracking via joint spatial-spectral knowledge distillation,
C. Sun, X. Wang, Z. Liu, Y . Wan, L. Zhang, and Y . Zhong, “Siamohot: A lightweight dual siamese network for onboard hyperspectral object tracking via joint spatial-spectral knowledge distillation,”IEEE Trans- actions on Geoscience and Remote Sensing, vol. 61, pp. 1–12, 2023
2023
-
[37]
Hotmoe: Exploring sparse mixture-of-experts for hyperspectral object tracking,
W. Sun, Y . Tan, J. Li, S. Hou, X. Li, Y . Shao, Z. Wang, and B. Song, “Hotmoe: Exploring sparse mixture-of-experts for hyperspectral object tracking,”IEEE Transactions on Multimedia, vol. 27, pp. 4072–4083, 2025
2025
-
[38]
Hyperspectral object tracking via band and context refinement network,
J. Zhang, Z. Zheng, K. Ni, N. Huang, Q. Liu, and P. Liu, “Hyperspectral object tracking via band and context refinement network,”Remote Sensing, vol. 17, no. 22, 2025
2025
-
[39]
Supervised embedded methods for hyperspectral band selection,
Y . Zimmer, O. Lindenbaum, and O. Glickman, “Supervised embedded methods for hyperspectral band selection,” 2025. [Online]. Available: https://arxiv.org/abs/2401.11420
arXiv 2025
-
[40]
Enhancing vision-language tracking by effectively con- verting textual cues into visual cues,
X. Feng, D. Zhang, S. Hu, X. Li, M. Wu, J. Zhang, X. Chen, and K. Huang, “Enhancing vision-language tracking by effectively con- verting textual cues into visual cues,” inICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[41]
Vision-language tracking with clip and interactive prompt learning,
H. Zhu, Q. Lu, L. Xue, P. Zhang, and G. Yuan, “Vision-language tracking with clip and interactive prompt learning,”IEEE Transactions on Intelligent Transportation Systems, vol. 26, no. 3, pp. 3659–3670, 2025
2025
-
[42]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational Conference on Machine Learning. PmLR, 2021, pp. 8748–8763
2021
-
[43]
Memvlt: Vision-language tracking with adaptive memory-based prompts,
X. Feng, X. Li, S. Hu, D. Zhang, J. Zhang, X. Chen, K. Huang et al., “Memvlt: Vision-language tracking with adaptive memory-based prompts,”Advances in Neural Information Processing Systems, vol. 37, pp. 14 903–14 933, 2024
2024
-
[44]
Dtvlt: A multi-modal diverse text benchmark for visual language tracking based on llm,
X. Li, S. Hu, X. Feng, D. Zhang, M. Wu, J. Zhang, and K. Huang, “Dtvlt: A multi-modal diverse text benchmark for visual language tracking based on llm,”arXiv preprint arXiv:2410.02492, 2024
arXiv 2024
-
[45]
Li, Xuchen and Hu, Shiyu and Feng, Xiaokun and Zhang, Dailing and Wu, Meiqi and Zhang, Jing and Huang, Kaiqi, “How texts help? a fine- grained evaluation to reveal the role of language in vision-language tracking,”arXiv preprint arXiv:2411.15600, 2024
arXiv 2024
-
[46]
Citetracker: Correlating image and text for visual tracking,
X. Li, Y . Huang, Z. He, Y . Wang, H. Lu, and M.-H. Yang, “Citetracker: Correlating image and text for visual tracking,” in2023 IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 9940– 9949
2023
-
[47]
Mamba adapter: Efficient multi-modal fusion for vision-language tracking,
L. Shi, B. Zhong, Q. Liang, X. Hu, Z. Mo, and S. Song, “Mamba adapter: Efficient multi-modal fusion for vision-language tracking,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 35, no. 9, pp. 9300–9311, 2025
2025
-
[48]
Language-aware domain generalization network for cross-scene hyperspectral image classification,
Y . Zhang, M. Zhang, W. Li, S. Wang, and R. Tao, “Language-aware domain generalization network for cross-scene hyperspectral image classification,”IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–12, 2023
2023
-
[49]
Text-driven adaptive semantic alignment network for cross-scene hyperspectral image classification,
W. Wang, F. Liu, H. Zhu, and L. Xiao, “Text-driven adaptive semantic alignment network for cross-scene hyperspectral image classification,” IEEE Transactions on Geoscience and Remote Sensing, 2025
2025
-
[50]
Efficiently modeling long sequences with structured state spaces,
A. Gu, K. Goel, and C. R ´e, “Efficiently modeling long sequences with structured state spaces,”arXiv preprint arXiv:2111.00396, 2021
Pith/arXiv arXiv 2021
-
[51]
On the parameterization and initialization of diagonal state space models,
A. Gu, K. Goel, A. Gupta, and C. R ´e, “On the parameterization and initialization of diagonal state space models,”Advances in Neural Information Processing Systems, vol. 35, pp. 35 971–35 983, 2022
2022
-
[52]
Mamba: Linear-time sequence modeling with selective state spaces,
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,”arXiv preprint arXiv:2312.00752, 2023
Pith/arXiv arXiv 2023
-
[53]
Videomamba: State space model for efficient video understanding,
K. Li, X. Li, Y . Wang, Y . He, Y . Wang, L. Wang, and Y . Qiao, “Videomamba: State space model for efficient video understanding,” in European Conference on Computer Vision, 2024, pp. 237–255
2024
-
[54]
Localmamba: Visual state space model with windowed selective scan,
T. Huang, X. Pei, S. You, F. Wang, C. Qian, and C. Xu, “Localmamba: Visual state space model with windowed selective scan,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 12–22
2024
-
[55]
Vmamba: Visual state space model,
Y . Liu, Y . Tian, Y . Zhao, H. Yu, L. Xie, Y . Wang, Q. Ye, J. Jiao, and Y . Liu, “Vmamba: Visual state space model,”Advances in Neural Information Processing Systems, vol. 37, pp. 103 031–103 063, 2024
2024
-
[56]
Spectral-temporal token-guided prompt mamba for hyperspectral object tracking,
H. Wang, Y . Li, and W. Li, “Spectral-temporal token-guided prompt mamba for hyperspectral object tracking,” in2024 14th Workshop on Hyperspectral Imaging and Signal Processing: Evolution in Remote Sensing (WHISPERS), 2024, pp. 1–5
2024
-
[57]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inPro- ceedings of NAACL-HLT, pp. 4171–4186
-
[58]
Clustering by fast search and find of density peaks,
A. Rodriguez and A. Laio, “Clustering by fast search and find of density peaks,”science, vol. 344, no. 6191, pp. 1492–1496, 2014
2014
-
[59]
All in one: Exploring unified vision-language tracking with multi-modal alignment,
C. Zhang, X. Sun, Y . Yang, L. Liu, Q. Liu, X. Zhou, and Y . Wang, “All in one: Exploring unified vision-language tracking with multi-modal alignment,” inProceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 5552–5561
2023
-
[60]
Joint feature learning and relation modeling for tracking: A one-stream framework,
B. Ye, H. Chang, B. Ma, S. Shan, and X. Chen, “Joint feature learning and relation modeling for tracking: A one-stream framework,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 341– 357
2022
-
[61]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” ICLR, vol. 1, no. 2, p. 3, 2022
2022
-
[62]
Phtrack: Prompting for hyperspectral video tracking,
Y . Chen, Y . Tang, X. Su, J. Li, Y . Xiao, J. He, and Q. Yuan, “Phtrack: Prompting for hyperspectral video tracking,”IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–18, 2024. 13 ROYet al.: VISION-LANGUAGE GUIDED HYPERSPECTRAL OBJECT TRACKING XXXX
2024
-
[63]
Sense: Hyperspectral video object tracker via fusing material and motion cues,
Y . Chen, Q. Yuan, Y . Tang, Y . Xiao, J. He, and Z. Liu, “Sense: Hyperspectral video object tracker via fusing material and motion cues,” Information Fusion, vol. 109, p. 102395, 2024
2024
-
[64]
Domain adaptation- aware transformer for hyperspectral object tracking,
Y . Wu, L. Jiao, X. Liu, F. Liu, S. Yang, and L. Li, “Domain adaptation- aware transformer for hyperspectral object tracking,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 9, pp. 8041– 8052, 2024
2024
-
[65]
Ubstrack: Unified band selection and multimodel ensemble for hyperspectral object tracking,
M. A. Islam, J. Zhou, W. Xing, Y . Gao, and K. K. Paliwal, “Ubstrack: Unified band selection and multimodel ensemble for hyperspectral object tracking,”IEEE Transactions on Geoscience and Remote Sensing, vol. 63, pp. 1–15, 2025
2025
-
[66]
Causal hyperprompter: A framework for unbiased hyperspectral camouflaged object tracking,
H. Wang, W. Li, X.-G. Xia, and Q. Du, “Causal hyperprompter: A framework for unbiased hyperspectral camouflaged object tracking,” IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–18, 2025
2025
-
[67]
Autoregressive queries for adaptive tracking with spatio-temporal trans- formers,
J. Xie, B. Zhong, Z. Mo, S. Zhang, L. Shi, S. Song, and R. Ji, “Autoregressive queries for adaptive tracking with spatio-temporal trans- formers,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 19 300–19 309
2024
-
[68]
Explicit visual prompts for visual object tracking,
L. Shi, B. Zhong, Q. Liang, N. Li, S. Zhang, and X. Li, “Explicit visual prompts for visual object tracking,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 5, 2024, pp. 4838– 4846
2024
-
[69]
Exploring enhanced contextual information for video-level object tracking,
B. Kang, X. Chen, S. Lai, Y . Liu, Y . Liu, and D. Wang, “Exploring enhanced contextual information for video-level object tracking,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 4, 2025, pp. 4194–4202
2025
-
[70]
Hyper- track: A unified network for hyperspectral video object tracking,
Y . Tan, W. Sun, J. Li, S. Hou, X. Li, Z. Wang, and B. Song, “Hyper- track: A unified network for hyperspectral video object tracking,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 36, no. 1, pp. 1015–1028, 2026
2026
-
[71]
Suit: Spatial-spectral union-intersection interaction network for hyperspectral object tracking,
F. Xiong, Z. Wu, J. Zhou, S. Jia, and Y . Qian, “Suit: Spatial-spectral union-intersection interaction network for hyperspectral object tracking,” IEEE Transactions on Image Processing, vol. 34, pp. 7786–7800, 2025
2025
-
[72]
Squeeze-and-excitation networks,
J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” in2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 7132–7141
2018
-
[73]
Hyperspectral imagery band selection based on maximal standard deviation,
L. Zhao, L. Wang, and D. Liu, “Hyperspectral imagery band selection based on maximal standard deviation,” in2015 8th International Sympo- sium on Computational Intelligence and Design (ISCID), vol. 2, 2015, pp. 59–62. 14
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.