Towards Distributed Inference of LLMs on a P2P Network
Pith reviewed 2026-06-30 23:12 UTC · model grok-4.3
The pith
Decentralized routing to the node with the longest estimated prefix match reduces LLM inference latency in a P2P network without centralized coordination or KV-cache transfers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
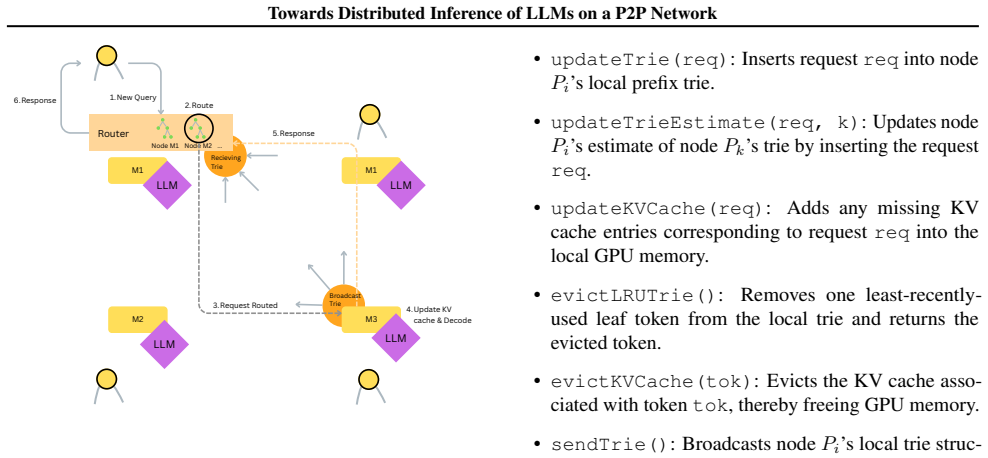
A decentralized, prefix-cache-aware routing scheme for peer-to-peer LLM serving in which each node maintains a local radix tree of its cached prefixes, obtains asynchronously refreshed estimates of peer caches via periodic anti-entropy, and routes requests to the node offering the longest estimated prefix match; stale metadata produces only cache misses, so weak consistency suffices for correctness.
What carries the argument
Decentralized routing to the node with the longest estimated prefix match, supported by local radix trees and periodic anti-entropy cache estimates.
If this is right
- No KV-cache transfer between nodes is required.
- Weak consistency is sufficient because incorrect routing decisions cause only misses.
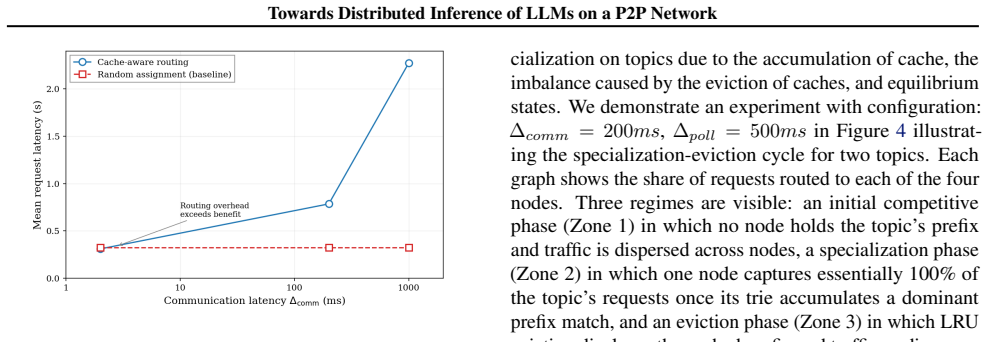
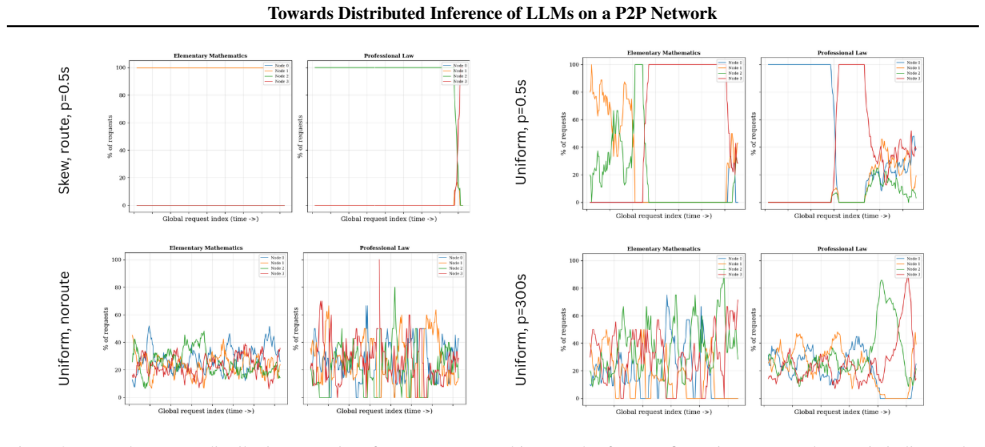
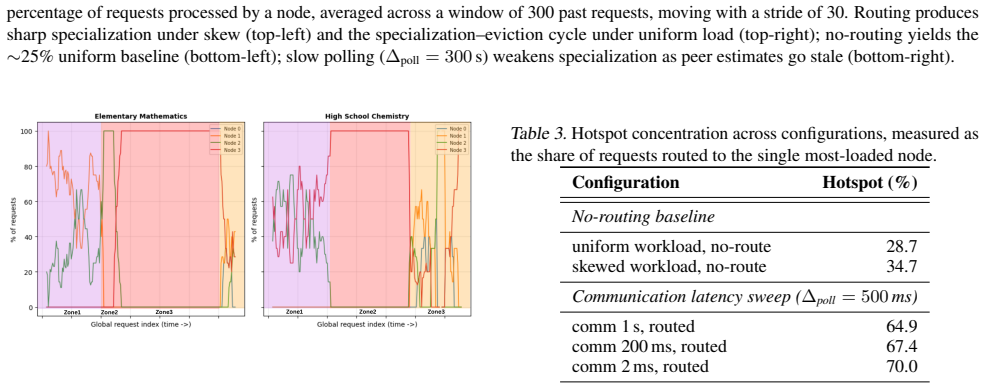
- Latency gains appear under low communication delay and skewed prefix distributions.
- High network latency and affinity-induced hotspots reduce or eliminate the benefit.
- The scheme works without any central coordinator.
Where Pith is reading between the lines
- The same longest-estimate routing could be applied to other distributed cache-sharing problems whose correctness tolerates misses.
- In dynamic networks where nodes frequently join or leave, the anti-entropy mechanism would need to be augmented with node-discovery updates.
- If prefix distributions in production are less skewed than the simulated MMLU workloads, the observed gains would shrink.
Load-bearing premise
Periodic anti-entropy exchanges keep the cache-size estimates accurate enough that the latency savings from correct longest-match routing exceed the overhead of the exchanges themselves.
What would settle it
A measurement, on a real deployment with the same prefix distribution, showing that average end-to-end inference latency under the decentralized longest-estimate router is no lower than under random routing.
Figures
read the original abstract
Prefix caching can reduce LLM inference latency by reusing KV caches across requests with shared prompts, but cluster-scale reuse is challenging because caches are partitioned across nodes. We propose a decentralized, prefix-cache-aware routing scheme for peer-to-peer LLM serving. Each node maintains a local radix tree of its own cached prefixes and asynchronously refreshed estimates of peer caches using periodic anti-entropy. Requests are routed to the node with the longest estimated prefix match, without centralized coordination or KV-cache transfer. Stale metadata only causes cache misses, not incorrect outputs, making weak consistency sufficient for correctness. Evaluation on simulated MMLU workloads show that decentralized routing improves latency under low communication delay and skewed prefix distributions, while high network latency and affinity-induced hotspots limit its benefits.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a decentralized prefix-cache-aware routing scheme for P2P LLM serving. Nodes maintain local radix trees of their own cached prefixes and use periodic anti-entropy to asynchronously refresh estimates of peer caches. Requests are routed to the node offering the longest estimated prefix match, without centralized coordination or KV-cache movement. Stale metadata produces only cache misses (preserving correctness under weak consistency). Simulations on MMLU workloads report latency reductions under low communication delay and skewed prefix distributions, while high latency and affinity hotspots limit gains.
Significance. If the simulation results generalize, the work would demonstrate a scalable mechanism for cross-node KV-cache reuse in distributed LLM inference that requires neither central state nor data transfer. The observation that weak consistency suffices for correctness is a clear strength. The evaluation remains simulation-only with no hardware measurements, prototype, or error-bar analysis, so the practical significance is conditional on the unverified workload and delay assumptions.
major comments (2)
- [Evaluation section] Evaluation section (and abstract): the reported latency improvements rest on the assumption that periodic anti-entropy keeps prefix estimates accurate enough to produce net cache-hit gains; no sensitivity analysis, error-rate measurements, or experiments under varying churn or non-MMLU prefix distributions are provided, which directly bears on whether the performance claim holds outside the simulated regimes.
- [Abstract and evaluation] Abstract and evaluation: benefits are shown only for the chosen MMLU workloads and low-delay regimes; the manuscript supplies no bounds or additional workloads demonstrating when anti-entropy estimates remain sufficiently fresh to deliver the claimed latency reduction versus alternatives.
minor comments (1)
- The abstract could explicitly note that all results are simulation-based and list the key workload and delay assumptions.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important aspects of the evaluation that warrant clarification and potential strengthening. We respond to each major comment below.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section (and abstract): the reported latency improvements rest on the assumption that periodic anti-entropy keeps prefix estimates accurate enough to produce net cache-hit gains; no sensitivity analysis, error-rate measurements, or experiments under varying churn or non-MMLU prefix distributions are provided, which directly bears on whether the performance claim holds outside the simulated regimes.
Authors: We agree that the current evaluation would benefit from explicit sensitivity analysis on anti-entropy parameters and prefix-distribution variation. In the revised version we will add (i) measurements of prefix-estimate error rate as a function of anti-entropy interval, (ii) results under controlled node churn, and (iii) additional synthetic workloads whose prefix skew differs from MMLU. These experiments remain within the existing simulation framework and directly test the robustness of the latency gains. revision: yes
-
Referee: [Abstract and evaluation] Abstract and evaluation: benefits are shown only for the chosen MMLU workloads and low-delay regimes; the manuscript supplies no bounds or additional workloads demonstrating when anti-entropy estimates remain sufficiently fresh to deliver the claimed latency reduction versus alternatives.
Authors: The manuscript already notes that gains diminish under high delay and hotspot affinity; we will expand this discussion with a simple analytic bound relating anti-entropy period, request arrival rate, and expected staleness, together with simulation results for two additional prefix distributions. This will clarify the operating regime in which the decentralized scheme outperforms centralized or non-cache-aware baselines. revision: partial
Circularity Check
No significant circularity; proposal and simulations are self-contained
full rationale
The paper proposes a decentralized prefix-cache routing scheme using local radix trees and periodic anti-entropy for peer estimates, routing to longest estimated match. Evaluation uses simulated MMLU workloads under varying delays and prefix skews. No load-bearing equations, predictions, or uniqueness claims reduce by construction to fitted inputs or self-citations; the latency benefits are presented as outcomes of the described mechanisms and simulation parameters, with correctness insulated by the weak-consistency property. This is the common case of an independent systems proposal.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Stale metadata from periodic anti-entropy only produces cache misses and never incorrect outputs
- domain assumption Simulated MMLU workloads and network delay distributions are representative of real usage
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Attention is All You Need , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[2]
Efficient Memory Management for Large Language Model Serving with
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph and Zhang, Hao and Stoica, Ion , booktitle=. Efficient Memory Management for Large Language Model Serving with
-
[3]
2024 , note=
Zheng, Lianmin and Yin, Liangsheng and Xie, Zhiqiang and Sun, Chuyue and Huang, Jeff and Yu, Cody Hao and Cao, Shiyi and Kozyrakis, Christos and Stoica, Ion and Gonzalez, Joseph E and Barrett, Clark and Sheng, Ying , booktitle=. 2024 , note=
2024
-
[4]
Ye, Lu and Tao, Ze and Huang, Yong and Li, Yang , booktitle=
-
[5]
arXiv preprint arXiv:2402.05099 , year=
Juravsky, Jordan and Brown, Bradley and Ehrlich, Ryan and Fu, Daniel Y and R. arXiv preprint arXiv:2402.05099 , year=
-
[6]
Proceedings of Machine Learning and Systems (MLSys) , year=
Prompt Cache: Modular Attention Reuse for Low-Latency Inference , author=. Proceedings of Machine Learning and Systems (MLSys) , year=
-
[7]
Gao, Bin and He, Zhuomin and Sharma, Puru and Kang, Qingxuan and Jevdjic, Djordje and Deng, Junbo and Yang, Xingkun and Yu, Zhou and Zuo, Pengfei , journal=
-
[8]
Pan, Rui and Siriwardhana, Shamane and Patel, Tushar and Ren, Zhen and Kim, Ciby Mathew and Ousterhout, John and Tumanov, Alexey , booktitle=
-
[9]
Zheng, Zhen and Ji, Xin and Fang, Taosong and Zhou, Fanghao and Liu, Chuanjie and Peng, Gang , journal=
-
[10]
2025 , note=
Yao, Jiayi and Li, Hanchen and Liu, Yuhan and Ray, Siddhant and Cheng, Yihua and Zhang, Qizheng and Du, Kuntai and Lu, Shan and Jiang, Junchen , booktitle=. 2025 , note=
2025
-
[11]
2025 , note=
Hu, Junhao and Huang, Wenrui and Wang, Weidong and Peng, Hao and Feng, Haoyi and Chen, Xusheng and Shan, Yizhou and Xie, Tao , booktitle=. 2025 , note=
2025
-
[12]
Yang, Jingbo and Hou, Bairu and Wei, Wei and Bao, Yujia and Chang, Shiyu , journal=
-
[13]
Wang, Qian and others , journal=
-
[14]
Wang, others , journal=
-
[15]
2025 , note=
Agarwal, Shubham and others , booktitle=. 2025 , note=
2025
-
[16]
2025 , note=
Srivatsa, Vikranth and He, Zijian and Abhyankar, Reyna and Li, Dongming and Zhang, Yiying , booktitle=. 2025 , note=
2025
-
[17]
2025 , note=
Qin, Ruoyu and Li, Zheming and He, Weiran and Cui, Jialei and Ren, Feng and Zhang, Mingxing and Wu, Yongwei and Zheng, Weimin and Xu, Xinran , booktitle=. 2025 , note=
2025
-
[18]
Hu, Cunchen and Huang, Heyang and Hu, Junhao and Xu, Jiang and Chen, Xusheng and Xie, Tao and Wang, Chenxi and Wang, Sa and Bao, Yungang and Sun, Ninghui and Shan, Yizhou , journal=
-
[19]
Liu, Yuhan and Yao, Jiayi and Cheng, Yihua and An, Yuwei and Chen, Xiaokun and Feng, Shaoting and Huang, Yuyang and Shen, Samuel and Zhang, Rui and Du, Kuntai and Jiang, Junchen , journal=
-
[20]
2024 , note=
Sun, Biao and Huang, Ziming and Zhao, Hanyu and Xiao, Wencong and Zhang, Xinyi and Li, Yong and Lin, Wei , booktitle=. 2024 , note=
2024
-
[21]
2024 , note=
Zhong, Yinmin and Liu, Shengyu and Chen, Junda and Hu, Jianbo and Zhu, Yibo and Liu, Xuanzhe and Jin, Xin and Zhang, Hao , booktitle=. 2024 , note=
2024
-
[22]
Proceedings of the 51st International Symposium on Computer Architecture (ISCA) , year=
Patel, Pratyush and Choukse, Esha and Zhang, Chaojie and Shah, Aashaka and Goiri,. Proceedings of the 51st International Symposium on Computer Architecture (ISCA) , year=
-
[23]
2024 , note=
Strati, Foteini and McAllister, Sara and Phanishayee, Amar and Tarnawski, Jakub and Klimovic, Ana , booktitle=. 2024 , note=
2024
-
[24]
2024 , note=
Liu, Yuhan and Li, Hanchen and Cheng, Yihua and Ray, Siddhant and Huang, Yuyang and Zhang, Qizheng and Du, Kuntai and Yao, Jiayi and Lu, Shan and Ananthanarayanan, Ganesh and Maire, Michael and Hoffmann, Henry and Holtzman, Ari and Jiang, Junchen , booktitle=. 2024 , note=
2024
-
[25]
Chen, Shiyang and others , journal=
-
[26]
Li, Weiqing and Jiang, Guochao and others , journal=
-
[27]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Ring Attention with Blockwise Transformers for Near-Infinite Context , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[28]
arXiv preprint arXiv:2311.09431 , year=
Striped Attention: Faster Ring Attention for Causal Transformers , author=. arXiv preprint arXiv:2311.09431 , year=
-
[29]
2024 , note=
Wu, Bingyang and Liu, Shengyu and Zhong, Yinmin and Sun, Peng and Liu, Xuanzhe and Jin, Xin , booktitle=. 2024 , note=
2024
-
[30]
arXiv preprint arXiv:2411.01783 , year=
Context Parallelism for Scalable Million-Token Inference , author=. arXiv preprint arXiv:2411.01783 , year=
-
[31]
Fang, Jiarui and Zhao, Shangchun , journal=
-
[32]
Mnemosyne: Parallelization Strategies for Efficiently Serving Multi-Million Context Length
Agrawal, Amey and Chen, Junda and Goiri,. Mnemosyne: Parallelization Strategies for Efficiently Serving Multi-Million Context Length. arXiv preprint arXiv:2409.17264 , year=
-
[33]
Star Attention: Efficient
Acharya, Shantanu and Fernandez, Jared and Ginsburg, Boris , journal=. Star Attention: Efficient. 2025 , note=
2025
-
[34]
Lin, Bin and Peng, Tao and Zhang, Chen and Sun, Minmin and Li, Lanbo and Zhao, Hanyu and Xiao, Wencong and Xu, Qi and Qiu, Xiafei and Li, Shen and Ji, Zhigang and Li, Yong and Lin, Wei , journal=
-
[35]
Selective
Chu, Kexin and others , journal=. Selective
-
[36]
Learned Prefix Caching for Efficient
Anonymous , booktitle=. Learned Prefix Caching for Efficient
-
[37]
Anonymous , journal=
-
[38]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Dao, Tri and Fu, Dan and Ermon, Stefano and Rudra, Atri and R. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[39]
Accelerating Self-Attentions for
Ye, Zihao and Chen, Lequn and Lai, Ruihang and Zhao, Yilong and Zheng, Size and Shao, Junru and Hou, Bohan and Jin, Hongyi and Zuo, Yifei and Yin, Liangsheng and Chen, Tianqi and Ceze, Luis , howpublished=. Accelerating Self-Attentions for
-
[40]
Yu, Gyeong-In and Jeong, Joo Seong and Kim, Geon-Woo and Kim, Soojeong and Chun, Byung-Gon , booktitle=
-
[41]
ACM Transactions on Storage , year=
Mooncake: A kvcache-centric disaggregated architecture for llm serving , author=. ACM Transactions on Storage , year=
-
[42]
ACM SIGOPS Operating Systems Review , volume=
Managing update conflicts in Bayou, a weakly connected replicated storage system , author=. ACM SIGOPS Operating Systems Review , volume=. 1995 , publisher=
1995
-
[43]
Proceedings of the VLDB Endowment , volume=
Coordination avoidance in database systems , author=. Proceedings of the VLDB Endowment , volume=. 2014 , publisher=
2014
-
[44]
2022 USENIX Annual Technical Conference (USENIX ATC 22) , pages=
Amazon \ DynamoDB \ : A scalable, predictably performant, and fully managed \ NoSQL \ database service , author=. 2022 USENIX Annual Technical Conference (USENIX ATC 22) , pages=
2022
-
[45]
ACM SIGOPS operating systems review , volume=
Dynamo: Amazon's highly available key-value store , author=. ACM SIGOPS operating systems review , volume=. 2007 , publisher=
2007
-
[46]
Journal of the ACM (JACM) , volume=
Consensus in the presence of partial synchrony , author=. Journal of the ACM (JACM) , volume=. 1988 , publisher=
1988
-
[47]
Implementing pushback: Router-based defense against DDoS attacks , author=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.